Standard ECMA-262
9th Edition / March 2023
ECMAScript® 2018 Language Specification
![]()
关于与贡献
该规范是 ECMAScript 规范的中文翻译。当前版本对应 0d37f42 版本,我们的愿景是对该规范中文版本提供长期维护。目前翻译进度到第七章,有大量的 Pull Requests 需要校对,也希望有兴趣各路大神可参与该翻译的校对和审校工作。以下是一些参与贡献的渠道。
- GitHub 仓库: https://github.com/docschina/ecma262
- Issues: 全部 Issues, 提 Issue
- Pull Requests: 全部 Pull Requests, 提交 Pull Request
- 网站: 中文正式版 中文参考版 英文版
- 维护者: realywithoutname (邮箱, GitHub)
- 团队:印记中文(GitHub,网站)
- 支持:腾讯云
- 主要贡献者:hijiangtao soulhat haowen737 lizhihua lcxfs1991
介绍
此标准定义了 ECMAScript 2018 语言,是 ECMAScript 语言规范的第九版。自从 1997 年第一版发布以来,ECMAScript 已经成为世界上应用最广泛的编程语言之一。他最为认知的是作为嵌入在 Web 浏览器中的语言,但也被广泛应用于服务器和嵌入式应用程序。
ECMAScript 基于几种始发技术,最著名的是 Netscape 的 JavaScript 以及 Microsoft 的 JScript。该语言由 Netscape 的 Brendan Eich 发明,并首次出现在该公司的 Navigator2.0 浏览器中。它已经出现在 Netscape 的所有后续浏览器以及 Microsoft 自 Internet Explorer3.0 开始的所有浏览器中。
ECMAScript 语言规范的制定始于 1996 年 11 月。第一版的Ecma标准在 1997 年 6 月通过 Ecma 联合大会。
该(第一版) Ecma 标准为了采用快速通道通过,被提交给 ISO/IEC JIC 1,于 1998 年 4 月被批准为国际标准 ISO/IEC16262。在 1998 年 Ecma 联合大会通过了第二版 ECMA-262,以保证完全符合 ISO/IEC 16262。第一版和第二版的变化是编辑层面的。
第三版标准引入了强大的正则表达式,更好的字符串处理,新的控制语句,try/catch 异常处理,更严格的错误定义,数字输出的格式化以及预期未来语言发展的微小变化。第三版 ECMAScript 标准于1999年12月被 Ecma 联合大会采纳,于 2002 年 6 月作为 ISO/IEC 16262:2002 发布。
在第三版发布后,ECMAScript 在万维网上被大量使用,它成为所有Web浏览器支持的编程语言。为了开发第四版 ECMAScript,做了大量有意义的工作,然而这项工作未能完成,也没能作为第四版 ECMAScript 发布,不过其中一些被纳入第六版开发(工作)中。
第五版 ECMAScript(以 ECMA-262 5th 版本发布)为那些已经被浏览器广泛实现的语言规范编纂了实质的解释,同时增加了对第三版发布以来出现的新功能的支持。 这些功能包括
第五版为了采用快速通道通过,被提交给 ISO/IEC JIC 1,被批准为国际标准 ISO/IEC 16262:2011。第 5.1 版 ECMAScript 标准包含较少的更正,并与 ISO/IEC 16262:2011 保持一致。于2011年6月 Ecma 联合大会被采纳。
第六版于 2009 年开始作为重点开发,当时第五版正在准备出版。然而,这之前的重点实验以及语言增强设计工作可以追溯到 1999 年第三版发布。实际上,第六版的完成是十五年努力的结果。 这个版本中增加了包括对大型应用程序,库创建, 以及以 ECMAScript 作为其他语言的编译目标提供更好的支持。其中主要的增强功能包括模块化,类声明,词法块作用域,迭代器以及生成器,异步编程的promise,解构模式,以及正确的尾部调用。 ECMAScript内置库扩展支持了额外的数据抽象,包括Map,Set,二进制值的数组, 同时也支持Unicode补充字符在字符串及正则表达式中使用。内置库也通过子类进行了扩展。第六版为正则,渐进式语言以及库增强提供了基础。第六版于 2015 年 6 月被Ecma联合大会采纳。
ECMAScript2016使用 Ecma TC39 委员会新的年度发布策略以及公开开发流程的首个 ECMAScript 版本。从 ECMAScript2015 源文档作为基础构建一个纯文本的源文档,以支持完全在 GitHub 上进一步开发。在这个标准的发展的这一年,数百个pull requests和issues被提交,代表着成千上万的错误修复,编辑修复和其他改进。另外,许多软件工具被开发用来帮助这一工作,包括Ecmarkup,Ecmarkdown和Grammarkdown。ES2016还包括支持一个新的求幂运算符,以及为 Array.prototype 添加了一个名为include的新方法。
ECMAScript 2017 的规范引入了Async函数,共享内存, 以及更小语言和库增强的原子,错误修复,编辑更新。Async函数通过提供promise-returning函数语法来提高异步编程体验。共享内存和原子引入了一种新的内存模型,允许多个代理程序使用原子操作进行通信,以确保即便在并行 CPU 上程序也能有明确定义的执行顺序。此规范还包括 Object 新的静态方法:Object.values,Object.entries和Object.getOwnPropertyDescriptors。
本规范,第 9 版本通过引入异步迭代器协议和异步生成器支持异步迭代。该规范还包括四个新的正则表达式特性:dotAll 标志、命名的捕获组、Unicode 属性转义和后视断言。还包括REST参数和扩展运算符支持对象属性。也有许多小的更新,编辑和规范,贡献来自我们的社区。
许多个人和组织在 Ecma TC39 为当前版本以及以前的版本做出了非常重要的贡献。此外,有了一个充满活力的社区支持 TC39 为 ECMAScript 所做的努力。这个社区审查了许多草案,提交了大量的错误报告,执行实施实验,提供测试套件,全世界的 ECMAScript 的开发者都可以从中受益。然而遗憾的是,不能一一鸣谢为此做出贡献的每个人和组织。
Allen Wirfs-Brock
ECMA-262, 6th版本 项目编辑
Brian Terlson
ECMA-262, 7th版本 项目编辑
1 范围
本标准定义了ECMAScript 2018通用编程语言。
2 一致性
一个符合ECMAScript标准的实现应该符合以下提议:
必须提供和支持本规范中描述的所有的类型,值,对象,属性,函数以及程序语法及语义。
解释源文本的输入必须与最新版本的Unicode标准和ISO/IEC 10646标准保持一致。
提供的应用程序接口的程序,需要适应使用不同自然语言的国家的语言和文化习惯,且最新版本的ECMA-402的实现必须与本规范的接口兼容。
应该提供那些超出该规范描述的额外类型,值,对象,属性以及方法。尤其对于该文档有提到但没描述其属性的那些对象,应该提供那些属性以及属性对应的值。
应该支持一些没有在规范中提及的程序或者正则表达式语法。尤其应该实现在
绝对不能实现在
3 引用标准
为了实现符合本规范的应用程序,下列引用文档是不可或缺的。对于标注了日期的文档,仅适用标注的那个版本。 对于未标注日期的文档,以文档的最新版为准(包括任何修订版)。
ISO/IEC 10646:2003: 信息技术 –通用多八位编码字符集(UCS)以及修订 1:2005, 修订 2:2006, 修订 3:2008, 和修订 4:2008, 以及其他修订,更正,后继标准
ECMA-402, ECMAScript 2015 国际化API规范.
http://www.ecma-international.org/publications/standards/Ecma-402.htm
ECMA-404, JSON 数据交换格式化.
http://www.ecma-international.org/publications/standards/Ecma-404.htm
4 概述
本节包含对 ECMAScript 语言非规范性的概述。
ECMAScript 是一门在宿主环境执行计算以及操作可计算对象的面向对象编程语言。这里定义的ECMAScript并不打算有自给自足的计算;事实上,该规范并没有规定外部数据的输入或者计算结果的输出。相反,我们期望 ECMAScript 程序的计算环境不仅提供本规范中描述的对象和能力,还包括特定的环境对象,本规范除了说明这些对象应该提供可被 ECMAScript 程序访问的某些属性,调用的某些方法外,关于它的其他描述和行为不在本规范涉及的范围。
ECMAScript 最初被设计为一门脚本语言,但是现在已经作为一门通用的编程语言被广泛应用。脚本语言是指一种用于操作,定制,自动化现有系统能力的编程语言。在这样的系统中,通过用户界面已经可以使用有用的功能,而脚本语言是将这些功能暴露给程序控制的机制。 通过这种方式,现有的系统被称为提供对象和能力的宿主环境,从而完成了脚本语言的功能。 脚本语言是供专业和非专业程序员使用的。
ECMAScript 最初被设计为 Web 脚本语言,提供了一种让网页更加富有生机的机制,并能够进行部分基于Web B/S架构的服务器端计算。ECMAScript 现在被用于在多种宿主中提供核心脚本能力。因此该文档描述的是除特定宿主环境外的语言核心。
ECMAScript 用法已经远超出了简单脚本,现在被用于很多不同的环境和规模的全方位编程任务。随着 ECMAScript 使用范围的扩大使,其功能和能力也得到了扩展。ECMAScript 现在成为了一个功能齐全的通用编程语言。
ECMAScript 的一些能力类似于其他编程语言中,特别是 C, Java™, Self, 如以及下所述的 Scheme:
ISO/IEC 9899:1996, Programming Languages – C.
Gosling, James, Bill Joy and Guy Steele. The Java™ Language Specification. Addison Wesley Publishing Co., 1996.
Ungar, David, and Smith, Randall B. Self: The Power of Simplicity. OOPSLA '87 Conference Proceedings, pp. 227-241,Orlando, FL, October 1987.
IEEE Standard for the Scheme Programming Language. IEEE Std 1178-1990.
4.1 Web 脚本
web 浏览器提供用于客户端计算的 ECMAScript 宿主环境,包括如代表窗口,菜单,弹出窗口,对话框,文本域,锚点,框架,历史记录,cookies以及输入/输出的实例对象。此外,宿主环境还提供了脚本代码处理如焦点改变、页面和图片的加载、卸载、错误和中断,选择,表单提交和鼠标交互等等事件的能力。通过 HTML 中的脚本代码组合用户接口元素,固定及计算文本,图片来显示页面。脚本代码不需要一个主程序即可对用户交互进行响应。
WEB 服务器提供一个不同于客户端的如代表请求,客户端,文件等的对象,以及数据锁定和分享的机制。为基于 Web 的应用程序提供一个定制的用户界面,通过浏览器端脚本及服务端脚本的配合使用,可以在客户端和服务端之间进行分布式计算。
支持 ECMAScript 的 WEB 浏览器和服务器都将它们自身的宿主环境作为 ECMAScript 的补充,以使得 ECMAScript 的执行环境变得完整。
4.2 ECMAScript 概述
以下是 ECMAScript— 的非正式概述 —— 描述的只是该语言的一部分。这个概述不是标准的一部分。
ECMAScript 是基于对象的:基础语言以及主要能力都是通过对象提供,一个 ECMAScript 程序是一组可通信对象。在 ECMAScript 中,一个对象是零个或多个属性的的集合。每个属性都有确定其如何被使用的特性, 如当一个属性的 Writable 特性设置为
ECMAScript 定义了一组内置对象,从而勾勒出 ECMAScript 实体的定义。这些内置对象包括全局对象;基本的语言Object, Function, Boolean, Symbol,各种 Error 对象;代表和操作的数值对象,包括 Math, Number, Date;文本处理对象,String,RegExp;索引值集合的 Array 对象,以及九种值具有特定数字数据表示的 Typed Array 对象;泛型对象 Map, Set;支持结构化数据的 JSON, ArrayBuffer, SharedArrayBuffer,DataView 等对象;支持控制抽象的 generator 函数,Promise 对象;以及反射对象 Proxy,Reflect。
ECMAScript 还定义了一组内置运算符。ECMAScript 运算符包括各种一元运算,乘法运算符,加法运算符,位移运算符,关系运算符,等式运算符,二进制运算符,二进制逻辑运算符,赋值运算符和逗号运算符。
大型 ECMAScript 程序通过模块被支持,其允许程序可以被分化为多个语句和定义序列。每个模块明确地标识它所使用的其他模块提供的声明,哪些声明可供其他模块使用。
ECMAScript 语法有意地类似于 Java 语法。ECMAScript 语法是松散的,使其能够成为易于使用的脚本语言。例如,一个变量不需要声明其具体类型,也不需要与声明相关联属性类型,在调用定义的函数之前也不需要以文本方式显示的声明。
4.2.1 Objects
尽管 ECMAScript 包含了定义类的语法,但是 ECMAScript 对象从根本上来说并不是像 C++,Smalltalk,Java 那样基于类的。相反,对象可以通过各种方式创建,包括字面符号,或通过"prototype" 的属性的函数,此属性用于实现基于原型的继承 和共享属性。new Date(2009, 11) 创建一个新 Date 对象。不使用new调用一个Date()产生一个表示当前日期时间的字符串,而不是一个对象。
每个由"prototype" 属性值。再者,一个原型可能有一个非空隐式引用链接到它的原型,以此类推,这叫做原型链。当向对象的一个属性提出引用时,引用会指向原型链中包含此属性名的第一个对象的属性。换句话说,首先检查直接提及的对象的同名属性,如果对象包含同名的属性,引用即指向此属性,如果该对象不包含同名的属性,则下一步检查对象的原型;以此类推。
一般情况下基于类的面向对象语言的实例拥有状态,类拥有方法,并且只能继承结构和行为。在 ECMAScript 中,对象拥有状态和方法,并且结构,行为,状态全都可继承。
所有不直接包含特定属性的对象会共享他们原型中包含的此属性及属性值。图 1 说明了这一点:
CF 是一个new 表达式创建: cf1, cf2, cf3, cf4, cf5。每个对象都有名为 q1 和 q2 的属性。虚线表示隐式原型关系;例如:cf3 的原型是 CFp。P1 和 P2 的两个属性, 这对 CFp,cf1, cf2, cf3, cf4, cf5 是不可见的。CFp 的名为 CFP1 的属性共享给 cf1, cf2,cf3, cf4, 以及 cf5 ( 没有CF), 以及在 CFp 的隐式原型链中找不到任何名为 q1, q2,或 CFP1 的属性。请注意,CF 和 CFp 之间没有隐式原型链接。
不同于基于类的对象语言,属性可以通过赋值的方式动态添加给对象。也就是说,
尽管 ECMAScript 对象本质上不是基于类,但是基于构造函数,原型对象和方法通用模式来实现类似于类的抽象是很方便的。ECMAScript 内置对象本身即遵循这样的类模式。从 ECMAScript 2015 开始,ECMAScript 语言包含了类定义语法,允许程序员像内置对象那样简洁的定义对象。
4.2.2 ECMAScript 严格变体
ECMAScript 语言认识到有的开发者可能希望限制使用语言中的新特性。他们这样做可能是为了安全考虑,避免他们认为是容易出错的功能,获得增强的错误检查,或其他原因。因此,ECMAScript 中定义了语言的严格变体。语言的严格变体,排除了 ECMAScript 语言的某些特定的语法和语义特征,还修改了某些功能的详细语义。严格变体还指定了必须抛出错误异常报告的额外错误条件,即使在非严格的语言形式下这些条件不属于错误。
ECMAScript 的严格变体通常被称为语言的严格模式。严格模式选择和使用明确地适用于独特 ECMAScript 代码单元级别的,ECMAScript 严格模式语法和语义。由于语法代码单元级别的严格模式被选择,严格模式仅在这个代码单元内施加有局部效果的限制。严格模式不限制或修改任何层面的 ECMAScript 语义,必须一致地操作跨多个代码单元。一个 ECMAScript 程序可同时包含严格模式和非严格模式的代码单元。在这种情况下,严格的模式只适用于严格模式代码单元内实际执行的代码。
要符合这一规范,ECMAScript 的实现必须同时实现未限制的 ECMAScript 语言和按照这个规范定义的 ECMAScript 的严格模式变体。此外,实现还必须支持未限制的和严格模式代码单元的在同一个程序中混用。
4.3 术语与定义
本文档将使用下列术语和定义。
4.3.1 类型
在本规范
4.3.2 原始值
指在
一个原始值直接代表语言实现的最低层次的数据
4.3.3 对象
Object 类型的成员
对象是属性的集合,并且具有单个原型对象。原型可能是空值。
4.3.4 构造函数
创建和初始化对象的
prototype 属性值是用来实现继承和共享的一个原型对象。
4.3.5 原型
为其他对象提供共享属性的对象
4.3.6 普通对象
默认行为拥有如那些所有对象都必须支持的内部方法的对象
4.3.7 异常对象
默认行为缺少一个或多个必要内部方法的对象
任何对象不是
4.3.8 标准对象
其语义由本规范定义的对象
4.3.9 内置对象
ECMAScript 实现指定和提供的对象
4.3.10 未定义的值
一个在变量没有被赋值时就被使用的原始值
4.3.11 Undefined 类型
值只有
4.3.12 空值
表示故意缺省任何对象值的原始值
4.3.13 Null 类型
值只有
4.3.14 Boolean 值
Boolean 类型的成员
只有两个值,
4.3.15 Boolean 类型
由原始值
4.3.16 Boolean 对象
标准内置构造函数
通过使用 new 表达式,以一个 Boolean 值作为参数调用 Boolean
4.3.17 String 值
由零个或多个16位无符号整数组成的有限有序序列原始值
一个 String 值是 String 类型的成员。通常序列中的每个整数值代表 UTF-16 文本的单个 16 位单元。然而,对于其值,ECMAScript 只要求必须是 16 位无符号整数,除此之外没有任何限制或要求。
4.3.18 String 类型
所有可能的 String 值的集合
4.3.19 String 对象
标准内置String 实例,Object 类型成员之一
4.3.20 Number 值
IEEE 754-2008 格式的 64 位双精度二进制的原始值
一个数字值是数字类型的成员,直接代表一个数字。
4.3.21 Number 类型
所有可能的 Number 值的集合,包括特殊 “Not-a-Number” (NaN) 值, 正无穷, 负无穷
4.3.22 Number 对象
标准内置Number 的一个实例,Object 类型成员之一
4.3.23 无穷
正无穷数值
4.3.24 NaN
值 IEEE 754-2008 “Not-a-Number” 的数值
4.3.25 Symbol 值
表示一个唯一的,非字符串的属性键对象的原始值
4.3.26 Symbol 类型
所有可能的 Symbol 值集合
4.3.27 Symbol 对象
标准内置Symbol 的一个实例,Object 类型成员之一
4.3.28 函数
可作为子程序调用的 Object 类型成员之一
函数除了其属性,还包含可执行代码、状态,用来确定被调用时的行为。函数的代码不限于 ECMAScript。
4.3.29 内置函数
作为函数的内置对象
如 parseInt 和 Math.exp 就是内置函数。一个实现可以提供本规范没有描述的依赖于实现的内置函数。
4.3.30 属性
将一个键(一个 String 值或 Symbor 值)和值相关联的对象的一部分
属性可能根据属性值的不同表现为直接的数据值(原始值,对象,或一个
4.3.31 方法
作为属性值的函数
当一个函数被作为一个对象的方法调用,此对象将作为
4.3.32 内置方法
作为内置函数的方法
标准内置方法由本规范定义,ECMAScript 实现可指定,提供其他额外的内置方法。
4.3.33 特性
定义一个属性的一些特性的内部值
4.3.34 自身属性
对象直接拥有的属性
4.3.35 继承属性
不是对象的自身属性,但是是对象原型的属性(原型的自身属性或继承属性)
4.4 本规范的结构
本规范的剩余部分章节组织如下:
第 5 章定义了在本规范中使用的一些符号或者语法的约定。
第 6-9 章定义了 ECMAScript 程序操作包含的执行环境。
第 10-16 章定义了实际的 ECMAScript 语言,包括它的语法编码以及语言特性的执行语义。
第 17-26 章定义了 ECMAScript 标准库。它们包括所有当 ECMAScript 程序执行时可用的标准对象的定义。
第 27 章描述了访问备用数组缓冲区内存和原子对象的内存一致性模型。
5 符号约定
5.1 语法与词法
5.1.1 上下文无关文法
上下文无关文法由多个产生式组成。每个产生式左侧有一个称为非终结符的抽象符号的左值,右侧有一个或多个非终结符和终结符号组成的序列的右值。任何文法,它的终结符都来自指定的字母集。
一个产生式链是一个只含有一个非终结符以及 0 个或多个终结符作为其右值的产生式。
句子中单一可区分的非终结符——目标符,给定一个语言上下文无关文法。换句话说,重复用产生式右值替换序列中任何左值为非终结符所组成的终结符序列集合(可能是无限个)。
5.1.2 词法与正则文法
ECMAScript 词法文法在
空白和注释之外的输入元素构成 ECMAScript 语法文法的终结符,它们被称为 ECMAScript tokens。这些 tokens 是,ECMAScript 语言的保留字,标识符,字面量,标点符号。此外,行结束符虽然不被视为 tokens,但会成为输入元素流的一部分,用于引导处理自动插入分号(/*…*/ 的注释,不管是否跨越多行)不包含行结束符也会直接地丢弃,但如果一个
两个冒号 "::" 作为分隔符分割词法和正则的文法产生式。词法和正则的文法共享某些产生式。
5.1.3 数字字符串文法
用于转换字符串为数字值的一种文法。此文法与数字字面量词法文法的一部分类似,并且有终结符
三个冒号 ":::" 作为分隔符分割数字字符串文法的产生式。
5.1.4 语法文法
第 11,12,13,14,15 章给出了 ECMAScript 的语法文法。词法文法定义的 ECMAScript tokens 是此文法的终结符(
当一个码点流解析成一个 ECMAScript 的
当一个解析成功的时候,它会构造一颗解析树,一颗根树结构是它的每个节点都是一个 Parse Node。每个 Parse Node 都是文法中的一个符号的一个实例。它代表了从这样的符号中派生出来的源代码文本的一个跨度。解析树的根节点代表着整个的源代码文本,是解析的
新的 Parse Nodes 在每次调用解析器时都会被重新实例化,也就是说解析相同源文本也永远不会重用。当且仅当它们表示相同的源文本范围,是相同语法符号的实例,并且是由调用相同的解析器产生的解析节点时被认为是相同的 Parse Node
多次解析同一字符串会得到不同的 Parse Nodes,例如:
eval(str); eval(str);只用一个冒号 “:” 作为分隔符分割语法词法的产生式。
语法文法在条款 12,13,14,15 中提出。但是对于哪些 token 序列是正确被 ECMAScript
在某些情况下,为了避免歧义,语法文法使用广义的产生式,允许 token 序列形成一个不合法的 ECMAScript
5.1.5 文法标记法
不管是在文法的产生式,还是在本规范中,词法文法,正则文法以及数字字符串文法的终结符都用等宽字体展示。这些将以的脚本形式出现。所有通过这种方式指定的终结符码点都被当作合适的基本拉丁语 Unicode 码点理解,而不是来自其他任何类似 Unicode 范围的码点。
非终结符以斜体显示。非终结符(也叫产生式)的定义由非终结符名称和其后定义的一个或多个冒号给出。(冒号的数量表示产生式所属的文法。)非终结符的一个或多个替代右值紧跟在下一行。例如,语法定义:
表示这个非终结符 while token,其后跟左括号 token,其后跟 token,其后跟
表示这个
终结符或非终结符可能会出现后缀下标 “opt”,表示它是可选符号。包含可选符号实际指定了包含两个右值,一个是省略可选元素的,另一个是包含可选元素的。这意味着:
是以下的一种简便的缩写:
以及:
是以下的一种简便的缩写:
也是下面的一种缩写:
所以在这个例子中,非终结符
产生式可以通过形如 “[parameters]” 这样的下标注释被参数化,会以后缀的形式出现在产生式定义的非终结符中。“parameters” 可以是单独的名称,也可以是一个逗号分隔的名称列表。被参数化的产生式是一系列定义参数名称以下划线开头,追加到参数化的非终结符后面的所有组合的产生式的缩写。这就意味着:
是下面的缩写:
以及:
是下面的缩写:
多个参数产生数个产生式的组合,在一个完整语法中不必引用所有。
对生产式的非终结符右值的引用也可以被参数化,例如:
是下面的缩写:
又如:
是下面的缩写:
非终结符引用可能同时具有参数列表和一个 “opt” 后缀。例如:
是下面的缩写:
在右侧非终结符引用参数名称前置以 “?”,使该参数值取决于当前产生式的左侧符号引用的参数名称是否出现。例如:
是下面的缩写:
如果右值选择是以 “[+parameter]” 作为前缀,则表示选择只有命名参数用于引用产生式的非终结符时可用。如果右值选择是以 “[~parameter]” 作为前缀,则表示选择只有命名参数不是用于引用产生式的非终结符时可用。这意味着:
是下面的缩写:
另外一个例子:
是下面的缩写:
在文法定义中当单词 “one of” 跟随一个或多个分号后的时候,表示随后的一行或多行的终结符是一个可选的定义。例如,ECMAScript的词法文法包含下列的产生式:
它仅仅是下面的缩写:
如果 “[empty]” 出现在一个产生式的右值,它暗示着这个产生式的右值不包含终结符或者非终结符。
如果 “[lookahead ∉ set]” 出现在一个产生式的右值,它暗示着如果随后立即的输入的token序列是给出的集合(set)的成员,那么这个产生式也许不会被使用。这个集合可以用一个逗号分割的由一到两个被花括号包裹的元素终结序列的列表表示。为了方便,这个集合也可以用非终结符表示,在这种情况下,它代表所有能由非终结符展开得到的终结符的集合。如果这个集合包含一个单独的终结符,那么短语 “[lookahead ≠ terminal]” 也许会被使用。
例如,给出定义:
则定义:
能匹配字母 n 后跟随由偶数起始的一个或多个十进制数字,或一个十进制数字后面跟随一个非十进制数字。
类似的,如果产生式的右值出现 “[lookahead ∈ set]”,则表示产生式只有在随后立即的输入的token序列是给出的集合(set)的成员才能使用。如果集合只包含一个单一的终结符,则可以使用 “[lookahead == terminal]”。
如果产生式的右侧出现 “[no
如果一个 throw token 和
除非通过一个受限的产生式禁止一个
当一个词法文法或者数字字符串文法的产生式中可选部分出现多码点的 token 时,意味着码点序列将会组成一个 token。
一个产生式的右值也许会通过 “but not” 指定某些不被允许的扩展,然后暗示这个扩展将是被排除在外的。例如,产生式:
意味着非终结符
最后,一些非终结符通过 sans-serif 字体书写的描述性的短语来描述, 在这样的案例中,列出所有的可选部分是不切实际的。
5.2 算法约定
此规范通常使用带编号的列表来指定算法的步骤。这些算法是用来精确地指定 ECMAScript 语言结构所需的语义。该算法无意暗示任何具体实现使用的技术。在实践中,也许可用更有效的算法实现一个给定功能。
算法可能被显式参数化,在这种情况下,参数名和用法必须作为算法定义的一部分提供。
算法步骤可以细分为多个连续的子步骤。子步骤需要用缩进表示,可以进一步被划分成缩进的子步骤。大纲编号约定用作标识子步骤,第一级子步骤使用小写字母字符标记,第二级小步骤用小写罗马数字标记。如果步骤超过三级,那么这些规则从第四级开始从数字重复进行标记。例如:
- Top-level step
- Substep.
- Substep.
- Subsubstep.
- Subsubsubstep
- Subsubsubsubstep
- Subsubsubsubsubstep
- Subsubsubsubstep
- Subsubsubstep
- Subsubstep.
一个步骤或者子步骤也许会使用 “if” 去断言它的子步骤的条件。在这样的案例中,这些子步骤只能适用于 “if” 断言为真的情况。如果一个步骤或者子步骤以 “else” 开始,那么表示这是之前的 “if” 断言的同一级的否定断言。
一个步骤也许会指定它的子步骤的迭代程序。
一个以 “Assert:” 开头的步骤断言一个它的算法里不变的条件。这样的断言被用作使算法不变量显式地展示,否则它将是隐式的。这样的断言不增加额外的语义需求,因此实现不必检查。它们被使用只是为了使算法更清晰。
对于任意形如 “Let x be someValue” 的值,算法步骤也许会声明命名别名。这些别名都是类似类型的,即 x 和 someValue 指向同样的基础数据,对它们的修改是互相可见的。那些想避免这样的类似引用的算法步骤需要显式地复制一份右值:即 “Let_x_ be a copy of someValue” 创建了一个 someValue 的浅复制。
一旦声明完毕,别名可以在任何后续步骤中引用,而不能在别名声明前的步骤中使用。别名也许会通过形如 “Set x to someOtherValue” 这样的形式被修改。
5.2.1 抽象操作
为了便于它们在本规范的多个地方使用,一些算法,我们称之为抽象操作,以参数化函数形式命名和书写,以便它们能够在其它算法中通过名称来引用。抽象操作通常使用函数应用风格被引用,如 OperationName(arg1, arg2)。一些抽象操作被当作像类规范里抽象的多态发送一样。这样的类似类的方法抽象操作通常通过一个方法应用风格被引用,如 someValue.OperationName(arg1, arg2)。
5.2.2 语法导向操作
一个语法导向操作是一个具名操作,它的定义包含了一系列算法,每个算法与一个或者多个 ECMAScript 文法的产生式相关联。一个有多个可选定义的产生式通常对于每个可选部分都有一个独立的算法。当一个算法与一个文法产生式相关联的时候,它也许会引用这个产生式可选部分的终结符或者非终结符,就好像它们是这个算法的参数一样。当出现这种情况时,非终结符指向实际的源代码中与之匹配的可选部分的定义。
当一个算法与一个产生式的可选部分关联的时候,这个可选部分通常不会带上 “[ ]” 文法注释。这样的注释只应该影响可选部分的语法识别,不应该对相关的可选部分的语义有影响。
语法导向操作同一个解析节点一起被调用,还可以在以下算法步骤 1,3,4 中使用这个约定的其它参数:
- Let status be the result of performing SyntaxDirectedOperation of
SomeNonTerminal . - Let someParseNode be the parse of some source text.
- Perform SyntaxDirectedOperation of someParseNode.
- Perform SyntaxDirectedOperation of someParseNode passing
"value"as the argument.
除非另有明确说明,否则,所有相关联的产生式对于每个也许会被应用到这个产生式左值的非终结符的操作都有一个隐式的定义。如果存在的话,这个隐式的定义简单地再次对同样的参数运用这个相同的定义,对于这些相关联的产生式唯一的右值非终结符,随后返回处理结果。例如,假设一些算法有如下形式的步骤: “Return the result of evaluating
但是解析操作并没有关联这个产生式的算法。那么在这样的案例中,解析操作隐式地包含了下面形式的关联:
- Return the result of evaluating
StatementList .
5.2.3 运行时语义
必须在运行时被调用的指定语义的算法就叫运行时语义。 运行时语义通过
5.2.3.1 隐式完成值
本规范的算法常常隐式地返回一个 [[Type]] 值为
- Return
"Infinity".
与下面的是同一个含义:
- Return
NormalCompletion ("Infinity").
然而,如果一个 “return” 语句的值表达式是一个
Assert : completionRecord is aCompletion Record .- Return completionRecord as the
Completion Record of this abstract operation.
一个在算法步骤中没有值的 “return” 语句与下面的是同样的意思:
- Return
NormalCompletion (undefined).
对于任意的在一个上下文中没有显示地需要一个完整的
5.2.3.2 抛出一个异常
描述抛出一个异常的算法步骤,例如:
- Throw a
TypeErrorexception.
与下面的是同一个含义:
- Return
ThrowCompletion (a newly createdTypeError object).
5.2.3.3 ReturnIfAbrupt
算法步骤说明或者等同于:
ReturnIfAbrupt (argument).
意思就是:
- If argument is an
abrupt completion , return argument. - Else if argument is a
Completion Record , let argument be argument.[[Value]].
算法步骤说明或者等同于:
ReturnIfAbrupt (AbstractOperation()).
与下面的是同一个含义:
- Let hygienicTemp be AbstractOperation().
- If hygienicTemp is an
abrupt completion , return hygienicTemp. - Else if hygienicTemp is a
Completion Record , let hygienicTemp be hygienicTemp.[[Value]].
这里的 hygienicTemp 是临时的,并且只在 ReturnIfAbrupt 有关的步骤中中可见。
算法步骤说明或者等同于:
- Let result be AbstractOperation(
ReturnIfAbrupt (argument)).
与下面的是同一个含义:
- If argument is an
abrupt completion , return argument. - If argument is a
Completion Record , let argument be argument.[[Value]]. - Let result be AbstractOperation(argument).
5.2.3.4 ReturnIfAbrupt 缩写
对? 为前缀的指定语法操作的调用暗示着
- ? OperationName().
等价于下面的步骤:
ReturnIfAbrupt (OperationName()).
相似的,对于程序方法的风格,步骤:
- ? someValue.OperationName().
等价于:
ReturnIfAbrupt (someValue.OperationName()).
相似的,前缀 ! 被用作暗示下列的对于抽象或者指定语法操作的调用将不会返回一个打断的完成值, 并且作为结果的
- Let val be ! OperationName().
等价于下面的步骤:
- Let val be OperationName().
Assert : val is never anabrupt completion .- If val is a
Completion Record , set val to val.[[Value]].
对于! 或者 ? 来利用这个缩写。
- Perform ! SyntaxDirectedOperation of
NonTerminal .
5.2.4 静态语义
上下文无关文法不能足够好的去表达所有定义的规则,不管是一个输入元素的流形成的一个合法的将被解析的 ECMAScript
静态语义规则拥有名称,并且通常用一个算法来定义。具有名称的静态语义规则与文法产生式相关联,对于每个可采用的具有名称的静态语义规则, 一个包含多个可选部分定义的产生式通常会对每个可选部分定义一个独有的算法。
除非在本规范中其它指定的文法产生式可选部分隐式地包含一个叫做 Contains 的接收一个值为包含相关产生式的文法的终结符或者非终结符的 symbol 参数静态语义规则的定义。 默认的包含定义为:
- For each child node child of this
Parse Node , do- If child is an instance of symbol, return
true . - If child is an instance of a nonterminal, then
- Let contained be the result of child Contains symbol.
- If contained is
true , returntrue .
- If child is an instance of symbol, return
- Return
false .
上面的定义是显式地重写了规范的产生式。
一个特殊的静态语义规则是早期(提前)错误规则。早期错误规则定了早期错误条件(见
5.2.5 数学操作
除非其它地方特别注明不包括无限并且不包括负 0(为了与正 0 区分),数学操作,例如加,减,否定(逻辑非),乘,除以及随后在条款中定义的数学函数应总是被当作是对于数学中所有真实数字计算出来的准确的结果。本规范算法中的浮点运算包含显式地的步骤,它们对于处理无穷,有符号的0,以及舍入是必要的。如果一个数学操作或者函数被应用在一个浮点数上,那么它必须被当作应用到用浮点数表示的具体的数学值;这样的浮点数必须是有限的,并且如果它是
数学函数
数学函数
符号 “
��学函数
6 ECMAScript 数据类型和值
本规范中算法控制每个具有相关类型的值。可能的值类型直接定义在本章节中。这些类型进一步分为 ECMAScript 语言类型与规范类型。
在本规范中,“Type(x)”表示法是“the type of x”的简写, 其中“type”指的是在本章节中定义的 ECMAScript 语言类型与规范类型。当一个值使用术语“empty”命名值时,它相当于说“没有任何类型的值”。
6.1 ECMAScript 语言类型
一个 ECMAScript 语言类型对应那些 ECMAScript 程序员在 ECMAScript 语言中直接使用的值。 ECMAScript 语言类型有 Undefined, Null, Boolean, String,Symbol, Number, Object。 一个ECMAScript 语言值是指拥有一个 ECMAScript 语言类型特点的值。
6.1.1 Undefined 类型
Undefined 类型仅仅只有一个值,undefined。 任何尚未分配值的变量值都为 undefined。
6.1.2 Null 类型
Null 类型只有一个值, null.
6.1.3 Boolean 类型
Boolean 类型表示具有 true 和 false 两个值的一个逻辑实体。
6.1.4 String 类型
String 类型是零个或多个 16 位无符号整数值(“元素”)的所有有序序列的集合,最大长度为 253-1 个元素。字符串类型通常用于表示正在运行的 ECMAScript 程序中的文本数据,在这种情况下,String中的每个元素都被视为一个 UTF-16 码元。 每个元素被认为占据该序列内的一个位置。 这些位置用非负整数索引。 第一个元素(如果有)在索引 0 处,下一个元素(如果有的话)在索引 1 处,以此类推。 String 的长度是序列中的元素个数(例如,十六位值)。空字符串的长度为零,因此不包含元素。
ECMAScript 操作符不应用不同的语义解释字符串内容。操作符把字符串的每个元素视为单个 UTF-16 代码单元进行解释。但是,ECMAScript 并不约束这些代码单元的值或这些代码单元之间的关系,因此进一步将字符串内容解释为 UTF-16 中编码的 Unicode 代码点序列的操作必须考虑格式不对的子序列。此类操作使用如下规则对每个代码单元特殊处理,使其数值范围在 0xD800 到 0xDBFF(Unicode 标准定义为 首代理,或者更正式的 高代理码元)或范围 0xDC00 到 0xDFFF(定义为尾代理,或者更正式的低代理码元):
-
不是
首代理 也不是尾代理 的码元被解释为具有相同值的码点。 -
两个码元序列,其第一个码元 c1 是一个
首代理 ,第二个码元 c2 是一个尾代理 , 这样的两个码元,被称为代理对 , 被解释为一个值为 (c1 - 0xD800) × 0x400 + (c2 - 0xDC00) + 0x10000 的码点。(见10.1.2 ) -
一个
首代理 或者尾代理 ,但不是一个代理对 的一部分的码元被解释为具有相同值的码点。
函数 String.prototype.normalize (see String.prototype.localeCompare (see
这种设计背后的理由是尽可能的保持 String 的实现简单和高效。 如果 ECMAScript 源文本符合 Normalized Form C,只要它们不包含任何 Unicode 转义序列,则字符串字面量保证也是标准化的。
在本规范中,短语"the string-concatenation of A,B,..."表示字符串代码单元的序列是每个参数的代码单元的连接。
6.1.5 Symbol 类型
Symbol 类型是所有可以用于作为 Object 属性 key 值的非字符串值的集合。(
每个可能的 Symbol 值都是唯一的和不可变的。
每个 Symbol 值永远地保持一个与之关联的叫做 [[Description]] 的值(它要么是
6.1.5.1 总所周知的 Symbol
总所周知的 Symbol 是那些被本规范中算法明确引用的内置 Symbol 值。它们通常被用作属性的 key,这些 key 的值作为规范的算法扩展点。除非另有说明,总所周知的 Symbol 的值被所有域(
在本规范内,一个总所周知的 Symbol 值通过形如 @@name 的形式被引用,这里的 “name” 是表
| 规范名称 | [[Description]] | 值和目的 |
|---|---|---|
| @@asyncIterator |
"Symbol.asyncIterator"
|
返回对象的默认 AsyncIterator 的方法。 由 for-await-of 语句的语义调用。
|
| @@hasInstance |
"Symbol.hasInstance"
|
确定构造instanceof 运算符语义来调用。
|
| @@isConcatSpreadable |
"Symbol.isConcatSpreadable"
|
一个 Boolean 值,如果为 true, 表示一个对象应该被 Array.prototype.concat |
| @@iterator |
"Symbol.iterator"
|
返回一个对象的默认 Iterator 的方法。由 for-of 声明的语义来调用。 |
| @@match |
"Symbol.match"
|
将字符串与正则表达式匹配的正则表达式方法。 由 String.prototype.match |
| @@replace |
"Symbol.replace"
|
替换匹配字符串子串的正则表达式方法。 由 String.prototype.replace |
| @@search |
"Symbol.search"
|
一个正则表达式方法,它返回正则表达式匹配到的内容在字符串中的索引。 由String.prototype.search |
| @@species |
"Symbol.species"
|
作为构造函数的函数值属性,用来创建派生对象。 |
| @@split |
"Symbol.split"
|
一个正则表达式方法,它在正则表达式匹配的索引位置拆分字符串。 由 String.prototype.split |
| @@toPrimitive |
"Symbol.toPrimitive"
|
将一个对象转换为相应原始值的方法。由 |
| @@toStringTag |
"Symbol.toStringTag"
|
用于创建对象的默认字符串描述的 String 值属性。通过内置方法 Object.prototype.toString |
| @@unscopables |
"Symbol.unscopables"
|
一个对象值属性,其自身和继承的属性名是从相关对象的 with 环境绑定中排除的属性名。 |
6.1.6 Number 类型
Number 类型有 18437736874454810627 (即,
还有另外两个特殊的值,叫做
其他 18437736874454810624(即,
注意其中有一个
18437736874454810622(即
其中 18428729675200069632 (即
其中 s 为 +1 或 -1,m 是一个小于 253 但大于等于 252 的整数,e 是从 -1074 到 971 的整数。
其余 9007199254740990 (即
其中 s 是 +1 或 -1 ,m 是小于 2 的 52 次方的正整数,e 是 -1074。
注意,大小不大于 253 的所有正整数和负整数可以在 Number 类型中表示(实际上,整数 0 具有两个表示,
如果一个有限的数值非零且用来表达它(上文两种形式之一)的整数 m 是奇数,则该数值有奇数意义。否则,它有偶数意义。
在本规范中,当 x 表示一个精确的非零实数数学量(甚至可以是无理数,比如π)时,“the
某些 ECMAScript 运算符仅处理闭区间
6.1.7 Object 类型
对象在逻辑上是属性的集合。每个属性都是一个数据属性或一个访问器属性:
- 数据属性关联 key 值和一个 ECMAScript 语言值以及一组值为 Boolean 类型的特性。
- 访问器属性关联 key 值和一个或两个访问器函数以及一组值为 Boolean 类型的特性。访问器函数用于存储或检索与该属性相关联的 ECMAScript 语言值。
属性使用 key 值来标识。一个属性的 key 值是 ECMAScript String 值或 Symbol 值。所有 String 值(包括空字符串) 和 Symbol 值作为属性的 key 都是有效的。属性名称是指属性的 key,其值为字符串。
一个值为 +0 或者一个 ≤ 253-1 的整数作为属性 key 字符串值的数字索引是一个以典型的数字 String(见
属性的 key 用来访问属性以及其值。属性有两种访问方式:get 和 set ,分别对应值的检索和赋值。通过 get 和 set 可访问的属性既包括直接属于的自身属性,也包括通过继承关系由其它相关对象提供的继承属性。继承属性也可能是另一个对象的自身属性或者继承属性。对象的每个自身属性必须有一个与对象的其他自身属性 key 值不同 key 值。
所有的对象都是逻辑上的属性集合,但是在用于访问和操纵它们的属性的语义中存在多种形式的对象。普通对象是对象的最常见形式,拥有默认的对象语义。奇异对象是指其属性语义与默认语义的各个方面都有区别的对象。
6.1.7.1 属性特性
在本规范中特性用来定义和解释对象属性的状态。
| 特性名称 | 值域 | 描述 |
|---|---|---|
| [[Value]] | 任何 ECMAScript 语言类型 | get 访问检索到的属性值 |
| [[Writable]] | Boolean |
如果为 |
| [[Enumerable]] | Boolean |
如果为 |
| [[Configurable]] | Boolean |
如果为 |
| 特性名称 | 值域 | 描述 |
|---|---|---|
| [[Get]] | Object | Undefined |
如果这个值是一个对象,那么它必须是一个 |
| [[Set]] | Object | Undefined |
如果这个值是一个对象,那么它必须是一个 |
| [[Enumerable]] | Boolean |
如果为 |
| [[Configurable]] | Boolean |
如果为 |
如果一个属性的特性的初始值没有被本规范显式地指定的,那么使用在表
| 特性名 | 默认值 |
|---|---|
| [[Value]] |
|
| [[Get]] |
|
| [[Set]] |
|
| [[Writable]] |
|
| [[Enumerable]] |
|
| [[Configurable]] |
|
6.1.7.2 对象的内部方法以及内部槽
在 ECMAScript 中,对象的实际语义是通过算法来调用内部方法指定的。在 ECMAScript 引擎中的每个对象都与一系列的定义它的运行时行为的内部方法相关联。这些内部方法不属于 ECMAScript 语言的一部分。本规范定义它们纯粹是为了说明目的。但是,在 ECMAScript 具体实现中的每个对象必须表现得与其相关关联的内部方法一致。其中确切的方式由实现者来决定。
内部方法名称是多态的。这意味着当一个通用内部方法被调用的时候,不同的对象值可能会执行不同的算法。调用内部方法实际的对象是这个调用 “target”。如果在运行时,实现的算法尝试使用一个对象不支持的内部方法,抛出一个TypeError异常。
内部槽对应于相关对象的内部状态,用于各种 ECMAScript 规范算法。内部槽不是对象的属性,也不会被继承。根据具体的内部槽规范,内部状态可能由任意 ECMAScript 语言类型的值或者指定的 ECMAScript 规范类型的值组成。除非另有指定,否则分配内部槽应作为创建一个对象的过程的部分,并且不应该动态地添加到对象上。除非另有指定,否则一个内部槽的初始值是
本规范内的内部方法和内部槽使用闭合的双方括号 [[]] 来标识。
表
表
| Internal Method | Signature | Description |
|---|---|---|
| [[GetPrototypeOf]] | ( ) → Object | Null |
确定为对象提供继承属性的对象。 |
| [[SetPrototypeOf]] | (Object | Null) → Boolean |
关联这个对象与提供继承属性的对象。传递 |
| [[IsExtensible]] | ( ) → Boolean | 决定是否允许添加额外的属性到这个对象上。 |
| [[PreventExtensions]] | ( ) → Boolean | 控制一个新的属性是否能加到这个对象上。返回 true 表示操作成功,返回 false 表示操作失败。 |
| [[GetOwnProperty]] |
(propertyKey) → Undefined | |
返回对象自身属性中 key 值为 propertyKey 的属性的属性描述符,如果没有这个属性返回undefined。
|
| [[DefineOwnProperty]] | (propertyKey, PropertyDescriptor) → Boolean | 创建或者改变 key 值为 propertyKey 的自身属性状态为 PropertyDescriptor。返回 true 表示属性被成功创建/更新,返回 false 表示属性不能被创建/更新。 |
| [[HasProperty]] | (propertyKey) → Boolean | 返回一个 Boolean 值,代表这个对象自身或者继承了一个 key 值为 propertyKey 的属性。 |
| [[Get]] | (propertyKey, Receiver) → any |
返回这个对象里 key 值为 propertyKey 的属性的值。如果必须运行一些的 ECMAScript 代码来检索这个属性值,Receiver 就会作为解析代码时的 |
| [[Set]] | (propertyKey, value, Receiver) → Boolean |
设置这个对象 key 值为 propertyKey 的属性的值为 value。如果必须运行一些的 ECMAScript 代码来检索这个属性值,Receiver 就会作为解析代码时的 |
| [[Delete]] | (propertyKey) → Boolean |
移除这个对象 key 值为 propertyKey 的自身属性。 如果这个属性没有被移除,仍然存在,则返回 |
| [[OwnPropertyKeys]] |
( ) → |
返回一个包含所有自身属性 key 值的 |
表
| Internal Method | Signature | Description |
|---|---|---|
| [[Call]] |
(any, a |
执行这个对象相关联的代码。通过一个函数表达式来调用。通过调用表达式,传递给内部函数的 arguments 为一个 |
| [[Construct]] |
(a |
创建一个对象。通过 new 或者 super 操作符调用。这个内部方法的第一个参数是一个包含操作符的参数的列表。第二个参数是 new 操作符初始化时应用的对象。实现这个内部方法的对象被称为构造函数。一个 |
这些
6.1.7.3 基本内部方法的不变量
ECMAScript 引擎中的内部方法必须符合以下指定的不变量列表。普通 ECMAScript 对象以及该规范中的标准怪异对象应保持这些不变量。ECMAScript Proxy 对象通过运行时检查 [[ProxyHandler]] 对象的陷阱调用结果的手段来保持这些不变量。
任何实现提供的怪异对象必须也保持这些不变量。违反这些不变量可能会导致 ECMAScript 代码出现不可预料的行为以及安全问题。然而,对于造成内存安全的违反不变量行为的实现决不能妥协。
实现不允许通过任何方式规避这些不变量。比如,通过提供替代接口来实现基本内部方法的功能而不强制执行他们的不变量。
定义:
- 内部方法的 target 是调用这个内部方法的对象。
- 如果 target 的 [[IsExtensible]] 内部方法返回值是 false 或者 [[PreventExtensions]] 内部方法返回值是 true,那么这个 target 是不可扩展的
- 一个不存在的属性是指一个不可扩展的 target 的自身属性中不存在的属性。
-
所有对
SameValue 的引用都是根据SameValue 算法定义的。
[[GetPrototypeOf]] ( )
- 返回的类型必须是 Object 或者 Null。
-
如果 target 是不可扩展的,并且 [[GetPrototypeOf]] 返回了一个值 v,那么任何将来对 [[GetPrototypeOf]] 的调用都应该返回与 v 相同的
SameValue 。
[[SetPrototypeOf]] (V)
- 返回的类型必须是 Boolean。
-
如果 target 是不可扩展的,[[SetPrototypeOf]] 必须返回 false,除非 V 与 target 执行 [[GetPrototypeOf]] 内置方法的
SameValue 相同。
[[IsExtensible]] ( )
- 返回的类型必须是 Boolean。
- 如果 [[IsExtensible]] 返回 false,所有将来对 target 的 [[IsExtensible]] 内置方法调用都必须返回 false。
[[PreventExtensions]] ( )
- 返回的类型必须是 Boolean。
- 如果 [[PreventExtensions]] 返回 false,所有将来对 target 的 [[IsExtensible]] 内置方法的的调用都必须返回 false,并且此刻开始 target 被认为是不可扩展的。
[[GetOwnProperty]] (P)
-
返回的类型必须是
Property Descriptor 或者 Undefined。 -
如果返回的类型是
Property Descriptor ,那么返回值必须是一个完整的 property descriptor (见6.2.5.6 )。 -
一个属性 P 被
数据属性 Desc 描述,如果 Desc.[[Value]] 等于 v,且 Desc.[[Writable]] 以及 Desc.[[Configurable]] 都为 false,那么所有将来调用 [[GetOwnProperty]](P) 内置方法时,返回的SameValue 必须是属性的 Desc.[[Value]]。 - 如果 P 属性除了 [[Writable]] 特性,其他特性在将来可能变化,或者属性可能消失,那么 P 的 [[Configurable]] 特性必须为 true。
- 如果 P 属性的 [[Writable]] 特性可能从 false 变为 true,那么 [[Configurable]] 特性必须为 true。
- 如果对象是不可扩展的且 P 属性不存在,那么将来所有对 target 的 [[GetOwnProperty]] (P) 内置方法的调用必须描述 P 属性不存在(即 [[GetOwnProperty]] (P) 必须返回 undefined)。
作为第三个不变量的推论,如果一个属性被描述为一个
[[DefineOwnProperty]] (P, Desc)
- 返回的类型必须是 Boolean。
-
如果 P 预先已经作为 target 的一个不可配置的自身属性被观察,那么 [[DefineOwnProperty]] 必须返回 false,除非满足一下条件之一:
- 如果 target 是不可配置的且 P 属性不存在,那么 [[DefineOwnProperty]] (P, Desc) 必须返回 false。也就是说,一个不可配置的 target 对象不能扩展新属性。
[[HasProperty]] ( P )
[[Get]] (P, Receiver)
-
如果 P,其值为 V,预先作为一个不可配置,不可写的 target 自身属性被观察,那么 [[GET]] 必须返回
SameValue 。 -
如果 P,其 [[Get]] 特性为 undefined,预先作为一个不可配置的 target 自身
访问器属性 被观察,那么 [[Get]] 操作必须返回 undefined。
[[Set]] ( P, V, Receiver)
- 返回的类型必须是 Boolean。
-
如果 P 预先作为一个不可配置,不可写的 target 自身
数据属性 被观察,那么 [[Set]] 必须返回 false。除非 V 是 P 的 [[Value]] 特性的SameValue 。 -
如果 P,其 [[Set]] 特性为 undefined,预先作为一个不可配置的 target 自身
访问器属性 被观察,那么 [[Set]] 操作必须返回 false。
[[Delete]] ( P )
- 返回的类型必须是 Boolean。
-
如果 P 预先作为一个不可配置的 target 自身数据或
访问器属性 被观察,那么 [[Delete]] 必须返回 false。
[[OwnPropertyKeys]] ( )
-
返回值必须是一个
List 。 - 返回的列表不能包含任何重复的元素。
-
返回的
List 的每个元素类型为 String 或者 Symbol。 -
返回的
List 必须包含至少预先已经被观察的自身属性的所有不可配置的 key。 -
如果对象是不可扩展的,那么返回的
List 必须只包含使用 [[GetOwnProperty]] 观察的对象所有属性的 key。
[[Construct]] ( )
- 返回值类型必须是 Object。
6.1.7.4 总所周知的内部对象
总所周知的内联函数是在该规范中通过算法明确引用的内置对象,这些内置对象通常有特定域的不变量。除非特别指出,每个内部对象在每个领域通常对应一系列相似对象的集合。
在本规范中像 %name% 这样的引用意味着关联到相应的 name 域的内部对象。决定当前域以及他的内联函数在
| 内在名称 | 全局名称 | ECMAScript 语言关联 |
|---|---|---|
|
|
Array
|
Array 构造函数 ( |
|
|
ArrayBuffer
|
ArrayBuffer 构造函数 ( |
|
|
ArrayBuffer.prototype
|
prototype |
|
|
数组迭代器对象的原型 ( |
|
|
|
Array.prototype
|
prototype |
|
|
Array.prototype.entries
|
entries |
|
|
Array.prototype.forEach
|
forEach |
|
|
Array.prototype.keys
|
keys |
|
|
Array.prototype.values
|
values |
|
|
The prototype of async-from-sync iterator objects ( |
|
|
|
async |
|
|
|
prototype |
|
|
|
The initial value of the prototype property of |
|
|
|
The |
|
|
|
The initial value of the prototype property of |
|
|
|
An object that all standard built-in async iterator objects indirectly inherit from | |
|
|
Atomics
|
Atomics 对象 ( |
|
|
Boolean
|
Boolean 构造函数 ( |
|
|
Boolean.prototype
|
prototype |
|
|
DataView
|
DataView 构造函数 ( |
|
|
DataView.prototype
|
prototype |
|
|
Date
|
Date 构造函数 ( |
|
|
Date.prototype
|
prototype |
|
|
decodeURI
|
decodeURI 函数 ( |
|
|
decodeURIComponent
|
decodeURIComponent 函数 ( |
|
|
encodeURI
|
encodeURI 函数 ( |
|
|
encodeURIComponent
|
encodeURIComponent 函数 ( |
|
|
Error
|
Error 构造函数 ( |
|
|
Error.prototype
|
prototype |
|
|
eval
|
eval 函数 ( |
| %EvalError% |
EvalError
|
EvalError 构造函数 ( |
| %EvalErrorPrototype% |
EvalError.prototype
|
%EvalError% prototype 属性的初始值
|
| %Float32Array% |
Float32Array
|
Float32Array 构造函数 ( |
| %Float32ArrayPrototype% |
Float32Array.prototype
|
%Float32Array% prototype |
| %Float64Array% |
Float64Array
|
Float64Array 构造函数 ( |
| %Float64ArrayPrototype% |
Float64Array.prototype
|
%Float64Array% prototype |
|
|
Function
|
Function 构造函数 ( |
|
|
Function.prototype
|
prototype |
|
|
prototype 属性的初始值
|
|
|
|
generator 对象的构造函数 ( |
|
|
|
prototype 属性的初始值
|
|
| %Int8Array% |
Int8Array
|
Int8Array 构造函数 ( |
| %Int8ArrayPrototype% |
Int8Array.prototype
|
%Int8Array% prototype |
| %Int16Array% |
Int16Array
|
Int16Array 构造函数 ( |
| %Int16ArrayPrototype% |
Int16Array.prototype
|
%Int16Array% prototype |
| %Int32Array% |
Int32Array
|
Int32Array 构造函数 ( |
| %Int32ArrayPrototype% |
Int32Array.prototype
|
%Int32Array% prototype |
|
|
isFinite
|
isFinite 函数 ( |
|
|
isNaN
|
isNaN 函数 ( |
|
|
所有标准内置迭代对象间接继承的对象 | |
|
|
JSON
|
JSON 对象 ( |
|
|
JSON.parse
|
parse |
|
|
Map
|
Map 构造函数 ( |
|
|
Map 迭代器对象的原型 ( |
|
|
|
Map.prototype
|
prototype |
|
|
Math
|
Math 对象 ( |
|
|
Number
|
Number 构造函数 ( |
|
|
Number.prototype
|
prototype 属性的初始值
|
|
|
Object
|
Object 构造函数 ( |
|
|
Object.prototype
|
prototype |
|
|
Object.prototype.toString
|
toString |
|
|
Object.prototype.valueOf
|
valueOf |
|
|
parseFloat
|
parseFloat 函数 ( |
|
|
parseInt
|
parseInt 函数 ( |
|
|
Promise
|
Promise 构造函数 ( |
|
|
Promise.prototype
|
prototype |
|
|
Promise.prototype.then
|
The initial value of the then |
|
|
Promise.all
|
The initial value of the all |
|
|
Promise.reject
|
The initial value of the reject |
|
|
Promise.resolve
|
The initial value of the resolve |
|
|
Proxy
|
Proxy 构造函数 ( |
| %RangeError% |
RangeError
|
RangeError 构造函数 ( |
| %RangeErrorPrototype% |
RangeError.prototype
|
%RangeError% prototype 属性的初始值
|
| %ReferenceError% |
ReferenceError
|
ReferenceError 构造函数 ( |
| %ReferenceErrorPrototype% |
ReferenceError.prototype
|
%ReferenceError% prototype 属性的初始值
|
|
|
Reflect
|
Reflect 对象 ( |
|
|
RegExp
|
RegExp 构造函数 ( |
|
|
RegExp.prototype
|
prototype |
|
|
Set
|
Set 构造函数 ( |
|
|
Set 迭代器对象的原型 ( |
|
|
|
Set.prototype
|
prototype |
|
|
SharedArrayBuffer
|
SharedArrayBuffer 构造函数 ( |
|
|
SharedArrayBuffer.prototype
|
prototype |
|
|
String
|
String 构造函数 ( |
|
|
String 迭代器对象的原型 ( |
|
|
|
String.prototype
|
prototype |
|
|
Symbol
|
Symbol 构造函数 ( |
|
|
Symbol.prototype
|
prototype |
| %SyntaxError% |
SyntaxError
|
SyntaxError 构造函数 ( |
| %SyntaxErrorPrototype% |
SyntaxError.prototype
|
%SyntaxError% prototype 属性的初始值
|
|
|
一个 |
|
|
|
所有数组类型 |
|
|
|
|
|
| %TypeError% |
TypeError
|
TypeError 构造函数 ( |
| %TypeErrorPrototype% |
TypeError.prototype
|
%TypeError% prototype 属性的初始值
|
| %Uint8Array% |
Uint8Array
|
Uint8Array 构造函数 ( |
| %Uint8ArrayPrototype% |
Uint8Array.prototype
|
%Uint8Array% prototype |
| %Uint8ClampedArray% |
Uint8ClampedArray
|
Uint8ClampedArray 构造函数 ( |
| %Uint8ClampedArrayPrototype% |
Uint8ClampedArray.prototype
|
%Uint8ClampedArray% prototype |
| %Uint16Array% |
Uint16Array
|
Uint16Array 构造函数 ( |
| %Uint16ArrayPrototype% |
Uint16Array.prototype
|
%Uint16Array% prototype |
| %Uint32Array% |
Uint32Array
|
Uint32Array 构造函数 ( |
| %Uint32ArrayPrototype% |
Uint32Array.prototype
|
%Uint32Array% prototype |
| %URIError% |
URIError
|
URIError 构造函数 ( |
| %URIErrorPrototype% |
URIError.prototype
|
%URIError% prototype 属性的初始值
|
|
|
WeakMap
|
WeakMap 构造函数 ( |
|
|
WeakMap.prototype
|
prototype |
|
|
WeakSet
|
WeakSet 构造函数 ( |
|
|
WeakSet.prototype
|
prototype |
6.2 ECMAScript规范类型
规范类型对应那些在算法中用来描述 ECMAScript 语言结构以及 ECMAScript 语言类型语义的元数据。 规范类型包括
6.2.1 List 以及 Record 规范类型
List 类型用来解释在 new 表达式,函数调用,以及其它需要一个简单的有序的值的 list 的算法中的参数列表(见
在规范中为了方便,一个字面量语法被用来表达一个新 List 值。 如 « 1, 2 » 定义一个新 List 值,它拥有两个元素,每个元素被初始化为一个特定的值。一个空的 List 值可以用 « » 表示。
Record 类型用来描述在该规范中的算法内的数据聚合。一个 Record 类型值包含一个或多个命名字段。每个字段的值是一个 ECMAScript 值或者通过由与 Record 类型相关联的名称代表的抽象值。字段名称始终用双括号括起来,例如 [[Value]]。
在规范中为了方便,使用类似对象字面量的语法来表示一个 Record 值。 如 { [[Field1]]: 42, [[Field2]]: false, [[Field3]]:
在规范文本和算法中,点记号可以用于指代记录值的特定字段。例如,如果 R 是上一段所示的记录,则 R.[[Field2]] 是 “R 中名称为 [[Field2]] 的字段 ” 的缩写。
应该命名常用记录字段组合的模式, 并且该名称可以用作Record字面量的前缀,以标识特定类型聚合的描述。 例如:PropertyDescriptor { [[Value]]: 42,[[Writable]]: false,[[Configurable]]: true }。
6.2.2 Set 和 Relation 规范类型
Set 类型被用来解释在内存模型中无序元素的集合。Set 类型的值是简单的元素的集合,其中没有任何元素出现超过一次。元素可以从 Set 中添加或者删除。不同的 Set 可以合并,相交或者相减。
Relation 类型被用来解释在 Set 上的约束。一个关系类型的值是它的的值域中有序对的集合。例如,一个在 event 上的关系是一个有序的的 event 对的集合。对于一个关系 R 以及在 R 的值域中的两个值 a 和 b,a R b 是有序对 (a, b) 是 R 的成员的简写。当 Relation 满足这些条件的最小 Relation 时,Relation 对于某些条件是最小的。
严格偏序是指一个 Relation 值 R 满足如下条件。
-
对于R值域中的 a,b,c:
- a R a 不成立,且
- 如果 a R b 并且 b R c 成立,那么 a R c 成立。
上述两种关系的特性被称为自反性和传递性。
严格全序是指一个 Relation 值 R 满足如下条件。
-
R 值域中的 a,b,c:
- a 全等于 b 或 a R b 或 b R a,且
- a R a 不成立,且
- 如果 a R b 同时 b R c,那么 a R c。
上述三种关系的特性,按顺序被称为完全性,自反性,传递性
6.2.3 Completion Record 规范类型
Completion 类型是一个用来解释运行时数值和控制流传播的 break,continue,return 和 throw)的行为。
Completion 类型值是字段名为表
| 字段名 | 值 | 意义 |
|---|---|---|
| [[Type]] |
|
结束发生的完成类型 |
| [[Value]] |
任何 ECMAScript 语言值或 |
产生的值 |
| [[Target]] |
任何 ECMAScript 字符串或 |
用于定向控制传输的目标标签。 |
术语 “异常结束” 是指 [[Type]] 值为除
6.2.3.1 Await
Algorithm steps that say
- Let completion be
Await (promise).
mean the same thing as:
- Let asyncContext be the
running execution context . - Let promiseCapability be !
NewPromiseCapability (%Promise% ). - Perform !
Call (promiseCapability.[[Resolve]],undefined , « promise »). - Let stepsFulfilled be the algorithm steps defined in
Await Fulfilled Functions . - Let onFulfilled be
CreateBuiltinFunction (stepsFulfilled, « [[AsyncContext]] »). - Set onFulfilled.[[AsyncContext]] to asyncContext.
- Let stepsRejected be the algorithm steps defined in
Await Rejected Functions . - Let onRejected be
CreateBuiltinFunction (stepsRejected, « [[AsyncContext]] »). - Set onRejected.[[AsyncContext]] to asyncContext.
- Let throwawayCapability be !
NewPromiseCapability (%Promise% ). - Set throwawayCapability.[[Promise]].[[PromiseIsHandled]] to
true . - Perform !
PerformPromiseThen (promiseCapability.[[Promise]], onFulfilled, onRejected, throwawayCapability). - Remove asyncContext from the
execution context stack and restore theexecution context that is at the top of theexecution context stack as therunning execution context . - Set the code evaluation state of asyncContext such that when evaluation is resumed with a
Completion completion, the following steps of the algorithm that invokedAwait will be performed, with completion available.
where all variables in the above steps, with the exception of completion, are ephemeral and visible only in the steps pertaining to Await.
Await can be combined with the ? and ! prefixes, so that for example
- Let value be ?
Await (promise).
means the same thing as:
- Let value be
Await (promise). ReturnIfAbrupt (value).
6.2.3.1.1 Await Fulfilled Functions
An
When an
- Let asyncContext be F.[[AsyncContext]].
- Let prevContext be the
running execution context . Suspend prevContext.- Push asyncContext onto the
execution context stack ; asyncContext is now therunning execution context . - Resume the suspended evaluation of asyncContext using
NormalCompletion (value) as the result of the operation that suspended it. Assert : When we reach this step, asyncContext has already been removed from theexecution context stack and prevContext is the currentlyrunning execution context .- Return
undefined .
The length property of an
6.2.3.1.2 Await Rejected Functions
An
When an
- Let asyncContext be F.[[AsyncContext]].
- Let prevContext be the
running execution context . Suspend prevContext.- Push asyncContext onto the
execution context stack ; asyncContext is now therunning execution context . - Resume the suspended evaluation of asyncContext using
ThrowCompletion (reason) as the result of the operation that suspended it. Assert : When we reach this step, asyncContext has already been removed from theexecution context stack and prevContext is the currentlyrunning execution context .- Return
undefined .
The length property of an
6.2.3.2 NormalCompletion
- Return
NormalCompletion (argument).
Is a shorthand that is defined as follows:
- Return
Completion { [[Type]]:normal , [[Value]]: argument, [[Target]]:empty }.
6.2.3.3 ThrowCompletion
The abstract operation ThrowCompletion with a single argument, such as:
- Return
ThrowCompletion (argument).
是下面定义的简写:
- Return
Completion {[[Type]]:throw , [[Value]]: argument, [[Target]]:empty }.
6.2.3.4 UpdateEmpty ( completionRecord, value )
Assert : If completionRecord.[[Type]] is eitherreturn orthrow , then completionRecord.[[Value]] is notempty .- If completionRecord.[[Value]] is not
empty , returnCompletion (completionRecord). - Return
Completion { [[Type]]: completionRecord.[[Type]], [[Value]]: value, [[Target]]: completionRecord.[[Target]] }.
6.2.4 Reference 规范类型
Reference 类型用于解释如 delete,typeof,分配操作,super 关键字以及其他语言功能的操作的行为。例如,分配一个左操作数预计将产生一个引用。
一个 Reference 是一个解析后的名称或者属性组合。一个 Reference 包含3个组件,基值组件,引用名组件,以及一个 Boolean 值的严格引用标志。一个基值组件可以是
一个 Super Reference 是指,用于表示使用 super 关键字表示一个名称组合的 Reference。一个
以下
6.2.4.1 GetBase ( V )
6.2.4.2 GetReferencedName ( V )
6.2.4.3 IsStrictReference ( V )
6.2.4.4 HasPrimitiveBase ( V )
6.2.4.5 IsPropertyReference ( V )
Assert :Type (V) isReference .- If either the base value component of V is an Object or
HasPrimitiveBase (V) istrue , returntrue ; otherwise returnfalse .
6.2.4.6 IsUnresolvableReference ( V )
6.2.4.7 IsSuperReference ( V )
6.2.4.8 GetValue ( V )
ReturnIfAbrupt (V).- If
Type (V) is notReference , return V. - Let base be
GetBase (V). - If
IsUnresolvableReference (V) istrue , throw aReferenceError exception. - If
IsPropertyReference (V) istrue , then- If
HasPrimitiveBase (V) istrue , then - Return ? base.[[Get]](
GetReferencedName (V),GetThisValue (V)).
- If
- Else base must be an
Environment Record ,- Return ? base.GetBindingValue(
GetReferencedName (V),IsStrictReference (V)) (see8.1.1 ).
- Return ? base.GetBindingValue(
在步骤 5.a.ii 中创建的对象在上面抽象方法和
6.2.4.9 PutValue ( V, W )
ReturnIfAbrupt (V).ReturnIfAbrupt (W).- If
Type (V) is notReference , throw aReferenceErrorexception. - Let base be
GetBase (V). - If
IsUnresolvableReference (V) istrue, then- If
IsStrictReference (V) istrue, then- Throw a
ReferenceErrorexception.
- Throw a
- Let globalObj be
GetGlobalObject (). - Return ?
Set (globalObj,GetReferencedName (V), W,false).
- If
- Else if
IsPropertyReference (V) istrue, then- If
HasPrimitiveBase (V) istrue, then - Let succeeded be ? base.[[Set]](
GetReferencedName (V), W,GetThisValue (V)). - If succeeded is
falseandIsStrictReference (V) istrue, throw aTypeErrorexception. - Return.
- If
- Else base must be an
Environment Record ,- Return ? base.SetMutableBinding(
GetReferencedName (V), W,IsStrictReference (V)) (see8.1.1 ).
- Return ? base.SetMutableBinding(
在步骤 6.a.ii 中创建的对象在上面抽象方法和
6.2.4.10 GetThisValue ( V )
Assert :IsPropertyReference (V) istrue .- If
IsSuperReference (V) istrue , then- Return the value of the thisValue component of the reference V.
- Return
GetBase (V).
6.2.4.11 InitializeReferencedBinding ( V, W )
ReturnIfAbrupt (V).ReturnIfAbrupt (W).Assert :Type (V) isReference .Assert :IsUnresolvableReference (V) isfalse .- Let base be
GetBase (V). Assert : base is anEnvironment Record .- Return base.InitializeBinding(
GetReferencedName (V), W).
6.2.5 Property Descriptor 规范类型
Property Descriptor 类型用来解释对象属性的特性的操作和具体化。Property Descriptor 的值为
Property Descriptor 值可以根据某些字段的存在或使用进一步分类为数据 Property Descriptor 和访问器 Property Descriptor。包含字段 [[Value]] 或 [[Writable]] 的是数据 Property Descriptor。包含字段 [[Get]] 或 [[Set]] 的是访问器 Property Descriptor。所有的 Property Descriptor 都可能包含 [[Enumerable]],[[Configurable]] 字段名。一个 Property Descriptor 值可能不会同时为一个数据 Property Descriptor 和一个访问器 Property Descriptor。然而,也不一定,一个通用 Property Descriptor 是一个既不是数据 Property Descriptor 也不是访问器 Property Descriptor 的 Property Descriptor值。一个完全填充的 Property Descriptor 既是一个数据 Property Descriptor 也是一个访问器 Property Descriptor, 他有所有符合表
在本规范中使用以下
6.2.5.1 IsAccessorDescriptor ( Desc )
当用
- If Desc is
undefined, returnfalse. - If both Desc.[[Get]] and Desc.[[Set]] are absent, return
false. - Return
true.
6.2.5.2 IsDataDescriptor ( Desc )
当用
- If Desc is
undefined , returnfalse . - If both Desc.[[Value]] and Desc.[[Writable]] are absent, return
false . - Return
true .
6.2.5.3 IsGenericDescriptor ( Desc )
当用
- If Desc is
undefined, returnfalse. - If
IsAccessorDescriptor (Desc) andIsDataDescriptor (Desc) are bothfalse, returntrue. - Return
false.
6.2.5.4 FromPropertyDescriptor ( Desc )
当用
- If Desc is
undefined , returnundefined . - Let obj be
ObjectCreate (%ObjectPrototype% ). Assert : obj is an extensible ordinary object with no own properties.- If Desc has a [[Value]] field, then
- Perform
CreateDataProperty (obj,"value", Desc.[[Value]]).
- Perform
- If Desc has a [[Writable]] field, then
- Perform
CreateDataProperty (obj,"writable", Desc.[[Writable]]).
- Perform
- If Desc has a [[Get]] field, then
- Perform
CreateDataProperty (obj,"get", Desc.[[Get]]).
- Perform
- If Desc has a [[Set]] field, then
- Perform
CreateDataProperty (obj,"set", Desc.[[Set]]).
- Perform
- If Desc has an [[Enumerable]] field, then
- Perform
CreateDataProperty (obj,"enumerable", Desc.[[Enumerable]]).
- Perform
- If Desc has a [[Configurable]] field, then
- Perform
CreateDataProperty (obj,"configurable", Desc.[[Configurable]]).
- Perform
Assert : All of the aboveCreateDataProperty operations returntrue .- Return obj.
6.2.5.5 ToPropertyDescriptor ( Obj )
当用一个对象 Obj 作为参数调用
- If
Type (Obj) is not Object, throw aTypeError exception. - Let desc be a new
Property Descriptor that initially has no fields. - Let hasEnumerable be ?
HasProperty (Obj,"enumerable"). - If hasEnumerable is
true , then - Let hasConfigurable be ?
HasProperty (Obj,"configurable"). - If hasConfigurable is
true , then - Let hasValue be ?
HasProperty (Obj,"value"). - If hasValue is
true , then- Let value be ?
Get (Obj,"value"). - Set desc.[[Value]] to value.
- Let value be ?
- Let hasWritable be ?
HasProperty (Obj,"writable"). - If hasWritable is
true , then - Let hasGet be ?
HasProperty (Obj,"get"). - If hasGet is
true , then- Let getter be ?
Get (Obj,"get"). - If
IsCallable (getter) isfalse and getter is notundefined , throw aTypeError exception. - Set desc.[[Get]] to getter.
- Let getter be ?
- Let hasSet be ?
HasProperty (Obj,"set"). - If hasSet is
true , then- Let setter be ?
Get (Obj,"set"). - If
IsCallable (setter) isfalse and setter is notundefined , throw aTypeError exception. - Set desc.[[Set]] to setter.
- Let setter be ?
- If desc.[[Get]] is present or desc.[[Set]] is present, then
- If desc.[[Value]] is present or desc.[[Writable]] is present, throw a
TypeError exception.
- If desc.[[Value]] is present or desc.[[Writable]] is present, throw a
- Return desc.
6.2.5.6 CompletePropertyDescriptor ( Desc )
当用
Assert : Desc is aProperty Descriptor .- Let like be
Record { [[Value]]:undefined , [[Writable]]:false , [[Get]]:undefined , [[Set]]:undefined , [[Enumerable]]:false , [[Configurable]]:false }. - If
IsGenericDescriptor (Desc) istrue orIsDataDescriptor (Desc) istrue , then- If Desc does not have a [[Value]] field, set Desc.[[Value]] to like.[[Value]].
- If Desc does not have a [[Writable]] field, set Desc.[[Writable]] to like.[[Writable]].
- Else,
- If Desc does not have a [[Get]] field, set Desc.[[Get]] to like.[[Get]].
- If Desc does not have a [[Set]] field, set Desc.[[Set]] to like.[[Set]].
- If Desc does not have an [[Enumerable]] field, set Desc.[[Enumerable]] to like.[[Enumerable]].
- If Desc does not have a [[Configurable]] field, set Desc.[[Configurable]] to like.[[Configurable]].
- Return Desc.
6.2.6 Lexical Environment 和 Environment Record 规范类型
6.2.7 Data Blocks
Data Block 规范类型用来描述不同且可变的字节(8 bit)大小的数字值序列。一个 Data Block 值由初始值为 0,固定数量的字节构成。
在本规范中为了方便,可以使用类似数组的语法来访问一个 Data Block 值的各个字节。这些符号将 Data Block 值的这些字节表示为一个从 0 开始的索引队列。 例如,如果 db 是一个 5 字节的 Data Block 值,那么 db[2] 可以用来访问第三字节。
驻留在内存中,可以被多个代理并发引用的数据块被称为 Shared Data Block。一个 Shared Data Block 有一个 空地址 的标识(目的是平等检测 Shared Data Block 值): 它不依赖于所述块在任何进程中映射到的虚拟地址,而是用该块来表示内存中的位置集合。只有当两个块包含的位置集合相等时他们才相等。否则,他们地址集合的交集为空,他们是不相等的。最后,可以从 Data Block 区分 Shared Data Blocks。
Shared Data Block 的语义由内存模型中的 Shared Data Block 事件来定义。下方的
Shared Data Block 事件由
下列
6.2.7.1 CreateByteDataBlock ( size )
当用整数参数 size 调用
Assert : size≥0.- Let db be a new
Data Block value consisting of size bytes. If it is impossible to create such aData Block , throw aRangeError exception. - Set all of the bytes of db to 0.
- Return db.
6.2.7.2 CreateSharedByteDataBlock ( size )
当用整数参数 size 调用
Assert : size≥0.- Let db be a new
Shared Data Block value consisting of size bytes. If it is impossible to create such aShared Data Block , throw aRangeError exception. - Let execution be the [[CandidateExecution]] field of the
surrounding agent 'sAgent Record . - Let eventList be the [[EventList]] field of the element in execution.[[EventLists]] whose [[AgentSignifier]] is
AgentSignifier (). - Let zero be « 0 ».
- For each index i of db, do
- Append
WriteSharedMemory { [[Order]]:"Init", [[NoTear]]:true , [[Block]]: db, [[ByteIndex]]: i, [[ElementSize]]: 1, [[Payload]]: zero } to eventList.
- Append
- Return db.
6.2.7.3 CopyDataBlockBytes ( toBlock, toIndex, fromBlock, fromIndex, count )
当
Assert : fromBlock and toBlock are distinctData Block orShared Data Block values.Assert : fromIndex, toIndex, and count areinteger values ≥ 0.- Let fromSize be the number of bytes in fromBlock.
Assert : fromIndex+count ≤ fromSize.- Let toSize be the number of bytes in toBlock.
Assert : toIndex+count ≤ toSize.- Repeat, while count>0
- If fromBlock is a
Shared Data Block , then- Let execution be the [[CandidateExecution]] field of the
surrounding agent 'sAgent Record . - Let eventList be the [[EventList]] field of the element in execution.[[EventLists]] whose [[AgentSignifier]] is
AgentSignifier (). - Let bytes be a
List of length 1 that contains a nondeterministically chosen byte value. - NOTE: In implementations, bytes is the result of a non-atomic read instruction on the underlying hardware. The nondeterminism is a semantic prescription of the
memory model to describe observable behaviour of hardware with weak consistency. - Let readEvent be
ReadSharedMemory { [[Order]]:"Unordered", [[NoTear]]:true , [[Block]]: fromBlock, [[ByteIndex]]: fromIndex, [[ElementSize]]: 1 }. - Append readEvent to eventList.
- Append
Chosen Value Record { [[Event]]: readEvent, [[ChosenValue]]: bytes } to execution.[[ChosenValues]]. - If toBlock is a
Shared Data Block , then- Append
WriteSharedMemory { [[Order]]:"Unordered", [[NoTear]]:true , [[Block]]: toBlock, [[ByteIndex]]: toIndex, [[ElementSize]]: 1, [[Payload]]: bytes } to eventList.
- Append
- Else,
- Set toBlock[toIndex] to bytes[0].
- Let execution be the [[CandidateExecution]] field of the
- Else,
Assert : toBlock is not aShared Data Block .- Set toBlock[toIndex] to fromBlock[fromIndex].
- Increment toIndex and fromIndex each by 1.
- Decrement count by 1.
- If fromBlock is a
- Return
NormalCompletion (empty ).
7 抽象操作
这些操作不是 ECMAScript 语言的一部分;在这里定义他们只是为了规范 ECMAScript 语言的语义。另外,本规范中还定义了其他特定的
7.1 类型转换
ECMAScript 语言根据需要会自动执行类型转换。为了解释清楚某些结构的语义,定义一组转换
7.1.1 ToPrimitive ( input [ , PreferredType ] )
Assert : input is anECMAScript language value .- If
Type (input) is Object, then- If PreferredType is not present, let hint be
"default". - Else if PreferredType is hint String, let hint be
"string". - Else PreferredType is hint Number, let hint be
"number". - Let exoticToPrim be ?
GetMethod (input, @@toPrimitive). - If exoticToPrim is not
undefined , then - If hint is
"default", set hint to"number". - Return ?
OrdinaryToPrimitive (input, hint).
- If PreferredType is not present, let hint be
- Return input.
7.1.1.1 OrdinaryToPrimitive ( O, hint )
当使用参数 O 和 hint 调用
Assert :Type (O) is Object.Assert :Type (hint) is String and its value is either"string"or"number".- If hint is
"string", then- Let methodNames be «
"toString","valueOf"».
- Let methodNames be «
- Else,
- Let methodNames be «
"valueOf","toString"».
- Let methodNames be «
- For each name in methodNames in
List order, do- Let method be ?
Get (O, name). - If
IsCallable (method) istrue , then
- Let method be ?
- Throw a
TypeError exception.
7.1.2 ToBoolean ( argument )
| 参数类型 | 结果 |
|---|---|
| Undefined |
返回 |
| Null |
返回 |
| Boolean | 返回 argument。 |
| Number |
如果 argument 为 |
| String |
如果 argument 是一个空字符串 (长度为0的字符串), 返回 |
| Symbol |
返回 |
| Object |
返回 |
7.1.3 ToNumber ( argument )
| 参数类型 | 结果 |
|---|---|
| Undefined |
返回 |
| Null |
返回 |
| Boolean |
如果 argument 是 |
| Number | 返回 argument (不转换)。 |
| String | 见下面语法和转换算法。 |
| Symbol |
抛出一个 |
| Object |
应用以下步骤:
|
7.1.3.1 应用于 String 类型的 ToNumber
应用
Syntax
以上所有未明确定义的语法符号都在数字字面量词法定义(
应该注意
-
StringNumericLiteral 可能包含前导和(或)结尾的空白和(或)行终止符。 -
十进制的
StringNumericLiteral 可能包含多位前导0的数字。 -
十进制的
StringNumericLiteral 可能包含一个+或-以指示其符号。 -
空的或者只有空格的
StringNumericLiteral 会被转换为+0 。 -
Infinity和-Infinity公认是StringNumericLiteral 而不是NumericLiteral 。
7.1.3.1.1 运行时语义: MV
字符串到 Number 值的转换和一个的数字字面量 Number 值的确定总体上来说是相似的(见
-
StringNumericLiteral ::: [empty] -
StringNumericLiteral ::: StrWhiteSpace -
StringNumericLiteral ::: StrWhiteSpace opt StrNumericLiteral StrWhiteSpace opt StrNumericLiteral 的数值, 无论是否存在空格. -
StrNumericLiteral ::: StrDecimalLiteral StrDecimalLiteral 的数值. -
StrNumericLiteral ::: BinaryIntegerLiteral BinaryIntegerLiteral 的数值. -
StrNumericLiteral ::: OctalIntegerLiteral OctalIntegerLiteral 的数值. -
StrNumericLiteral ::: HexIntegerLiteral HexIntegerLiteral 的数值. -
StrDecimalLiteral ::: StrUnsignedDecimalLiteral StrUnsignedDecimalLiteral 的数值. -
StrDecimalLiteral ::: + StrUnsignedDecimalLiteral StrUnsignedDecimalLiteral 的数值. -
StrDecimalLiteral ::: - StrUnsignedDecimalLiteral StrUnsignedDecimalLiteral 的数值的负数.(注意,如果StrUnsignedDecimalLiteral 的数值是 0,那么这个数值的负数也是 0。下面的舍入规则描述了合理的处理转换无符号数字 0 为一个浮点数+0 或-0 。) -
StrUnsignedDecimalLiteral ::: Infinity +∞). -
StrUnsignedDecimalLiteral ::: DecimalDigits . DecimalDigits 的数值. -
StrUnsignedDecimalLiteral ::: DecimalDigits . DecimalDigits DecimalDigits 的数值加上(第二个DecimalDigits 的数值乘上 10-n), 这里的 n 是第二个DecimalDigits 的码点数. -
StrUnsignedDecimalLiteral ::: DecimalDigits . ExponentPart DecimalDigits 的数值乘上 10e, 这里的 e 是ExponentPart 的数值. -
StrUnsignedDecimalLiteral ::: DecimalDigits . DecimalDigits ExponentPart DecimalDigits 的数值加上(第二个DecimalDigits 的数值乘以 10-n))乘以 10e, 这里 n 第二个DecimalDigits 码点数,e 是ExponentPart 的数值. -
StrUnsignedDecimalLiteral ::: . DecimalDigits DecimalDigits 的数值乘上 10-n, 这里的 n 是DecimalDigits 码点数. -
StrUnsignedDecimalLiteral ::: . DecimalDigits ExponentPart DecimalDigits 的数值乘以 10e-n, 这里 n 是DecimalDigits 的码点数,e 是ExponentPart 的数值. -
StrUnsignedDecimalLiteral ::: DecimalDigits DecimalDigits 的数值. -
StrUnsignedDecimalLiteral ::: DecimalDigits ExponentPart DecimalDigits 的数值乘上 10e, e 是ExponentPart 的数值.
一旦确定了字符串数字字面量确切的数值,它将被舍入为一个 Number 类型的值。如果数值为 0,那么它舍入的值为 "-",这种情况舍入值为
-
这个数字不是
0; 或者 -
数字的左侧是一个非零的数字且他的右边是一个不在
ExponentPart 的非零数字。那么这个数字是有效的。
7.1.4 ToInteger ( argument )
7.1.5 ToInt32 ( argument )
- Let number be ?
ToNumber (argument). - If number is
NaN ,+0 ,-0 ,+∞ , or-∞ , return+0 . - Let int be the
mathematical value that is the same sign as number and whose magnitude isfloor (abs (number)). - Let int32bit be int
modulo 232. - If int32bit ≥ 231, return int32bit - 232; otherwise return int32bit.
鉴于以上 ToInt32 的定义:
- ToInt32 是等幂的: 其作用在同一个元素上产生的结果相同。
-
对于任意 x,ToInt32(
ToUint32 (x)) 等于 ToInt32(x)。 (这是为了保证+∞ 和-∞ 会被映射为+0 。) -
ToInt32 把
-0 映射为+0 .
7.1.6 ToUint32 ( argument )
- Let number be ?
ToNumber (argument). - If number is
NaN ,+0 ,-0 ,+∞ , or-∞ , return+0 . - Let int be the
mathematical value that is the same sign as number and whose magnitude isfloor (abs (number)). - Let int32bit be int
modulo 232. - Return int32bit.
7.1.7 ToInt16 ( argument )
- Let number be ?
ToNumber (argument). - If number is
NaN ,+0 ,-0 ,+∞ , or-∞ , return+0 . - Let int be the
mathematical value that is the same sign as number and whose magnitude isfloor (abs (number)). - Let int16bit be int
modulo 216. - If int16bit ≥ 215, return int16bit - 216; otherwise return int16bit.
7.1.8 ToUint16 ( argument )
- Let number be ?
ToNumber (argument). - If number is
NaN ,+0 ,-0 ,+∞ , or-∞ , return+0 . - Let int be the
mathematical value that is the same sign as number and whose magnitude isfloor (abs (number)). - Let int16bit be int
modulo 216. - Return int16bit.
鉴于以上 ToUint16 的定义:
-
ToUint32 与 ToUint16 不同之处在于第四步时用 216 替换了 232。 -
ToUint16 把
-0 映射为+0 .
7.1.9 ToInt8 ( argument )
- Let number be ?
ToNumber (argument). - If number is
NaN ,+0 ,-0 ,+∞ , or-∞ , return+0 . - Let int be the
mathematical value that is the same sign as number and whose magnitude isfloor (abs (number)). - Let int8bit be int
modulo 28. - If int8bit ≥ 27, return int8bit - 28; otherwise return int8bit.
7.1.10 ToUint8 ( argument )
- Let number be ?
ToNumber (argument). - If number is
NaN ,+0 ,-0 ,+∞ , or-∞ , return+0 . - Let int be the
mathematical value that is the same sign as number and whose magnitude isfloor (abs (number)). - Let int8bit be int
modulo 28. - Return int8bit.
7.1.11 ToUint8Clamp ( argument )
与其他 ECMAScript 整数转换
7.1.12 ToString ( argument )
| 参数类型 | 结果 |
|---|---|
| Undefined |
返回 "undefined".
|
| Null |
返回 "null".
|
| Boolean |
如果 argument 是 如果 argument 是 |
| Number |
返回 |
| String | 返回 argument. |
| Symbol |
抛出一个 |
| Object |
应用如下步骤:
|
7.1.12.1 NumberToString ( m )
- If m is
NaN , return the String"NaN". - If m is
+0 or-0 , return the String"0". - If m is less than zero, return the
string-concatenation of"-"and !NumberToString (-m). - If m is
+∞ , return the String"Infinity". - Otherwise, let n, k, and s be integers such that k ≥ 1, 10k-1 ≤ s < 10k, the
Number value for s × 10n-k is m, and k is as small as possible. Note that k is the number of digits in the decimal representation of s, that s is not divisible by 10, and that the least significant digit of s is not necessarily uniquely determined by these criteria. - If k ≤ n ≤ 21, return the
string-concatenation of:- the code units of the k digits of the decimal representation of s (in order, with no leading zeroes)
- n-k occurrences of the code unit 0x0030 (DIGIT ZERO)
- If 0 < n ≤ 21, return the
string-concatenation of:- the code units of the most significant n digits of the decimal representation of s
- the code unit 0x002E (FULL STOP)
- the code units of the remaining k-n digits of the decimal representation of s
- If -6 < n ≤ 0, return the
string-concatenation of:- the code unit 0x0030 (DIGIT ZERO)
- the code unit 0x002E (FULL STOP)
- -n occurrences of the code unit 0x0030 (DIGIT ZERO)
- the code units of the k digits of the decimal representation of s
- Otherwise, if k = 1, return the
string-concatenation of: - Return the
string-concatenation of:- the code units of the most significant digit of the decimal representation of s
- the code unit 0x002E (FULL STOP)
- the code units of the remaining k-1 digits of the decimal representation of s
- the code unit 0x0065 (LATIN SMALL LETTER E)
- the code unit 0x002B (PLUS SIGN) or the code unit 0x002D (HYPHEN-MINUS) according to whether n-1 is positive or negative
- the code units of the decimal representation of the
integer abs (n-1) (with no leading zeroes)
对于提供了比上述转换规则更准确的实现,建议其中第五步参考下面的另一个版本:
- Otherwise, let n, k, and s be integers such that k ≥ 1, 10k-1 ≤ s < 10k, the
Number value for s × 10n-k is m, and k is as small as possible. If there are multiple possibilities for s, choose the value of s for which s × 10n-k is closest in value to m. If there are two such possible values of s, choose the one that is even. Note that k is the number of digits in the decimal representation of s and that s is not divisible by 10.
David M. Gay 编写的二进制转换为十进制中关于浮点数的文章和代码对于 ECMAScript 实现者可能会有帮助:
Gay, David M. Correctly Rounded Binary-Decimal and Decimal-Binary Conversions. Numerical Analysis, Manuscript 90-10. AT&T Bell Laboratories (Murray Hill, New Jersey). November 30, 1990. 相关文章可以在
http://ampl.com/REFS/abstracts.html#rounding 找到. 相关代码在
http://netlib.sandia.gov/fp/dtoa.c 和
http://netlib.sandia.gov/fp/g_fmt.c ,这些代码也可以在其他 netlib 镜像网站找到。
7.1.13 ToObject ( argument )
| 参数类型 | 结果 |
|---|---|
| Undefined |
抛出一个 |
| Null |
抛出一个 |
| Boolean |
返回一个内部槽 [[BooleanData]] 为 argument 的新 Boolean 对象。见 |
| Number |
返回一个内部槽 [[NumberData]] 为 argument 的新 Number 对象。见 |
| String |
返回一个内部槽 [[StringData]] 为 argument 的新 String 对象。见 |
| Symbol |
返回一个内部槽 [[SymbolData]] 为 argument 的新 Symbol 对象。见 |
| Object | 返回 argument。 |
7.1.14 ToPropertyKey ( argument )
- Let key be ?
ToPrimitive (argument, hint String). - If
Type (key) is Symbol, then- Return key.
- Return !
ToString (key).
7.1.15 ToLength ( argument )
7.1.16 CanonicalNumericIndexString ( argument )
如果 argument 为是一可以通过 "-0" 的字符串,则undefined。这个
一个规范的数字字符串是指 CanonicalNumericIndexString
7.1.17 ToIndex ( value )
- If value is
undefined, then- Let index be 0.
- Else,
- Let integerIndex be ?
ToInteger (value). - If integerIndex < 0, throw a
RangeError exception. - Let index be !
ToLength (integerIndex). - If
SameValueZero (integerIndex, index) isfalse , throw aRangeError exception.
- Let integerIndex be ?
- Return index.
7.2 测试与比较操作
7.2.1 RequireObjectCoercible ( argument )
| 参数类型 | 结果 |
|---|---|
| Undefined |
抛出一个 |
| Null |
抛出一个 |
| Boolean | 返回 argument. |
| Number | 返回 argument. |
| String | 返回 argument. |
| Symbol | 返回 argument. |
| Object | 返回 argument. |
7.2.2 IsArray ( argument )
- If
Type (argument) is not Object, returnfalse . - If argument is an Array
exotic object , returntrue . - If argument is a Proxy
exotic object , then- If argument.[[ProxyHandler]] is
null , throw aTypeError exception. - Let target be argument.[[ProxyTarget]].
- Return ?
IsArray (target).
- If argument.[[ProxyHandler]] is
- Return
false .
7.2.3 IsCallable ( argument )
- If
Type (argument) is not Object, returnfalse . - If argument has a [[Call]] internal method, return
true . - Return
false .
7.2.4 IsConstructor ( argument )
- If
Type (argument) is not Object, returnfalse . - If argument has a [[Construct]] internal method, return
true . - Return
false .
7.2.5 IsExtensible ( O )
7.2.6 IsInteger ( argument )
7.2.7 IsPropertyKey ( argument )
7.2.8 IsRegExp ( argument )
参数为 argument 的
7.2.9 IsStringPrefix ( p, q )
Assert :Type (p) is String.Assert :Type (q) is String.- If q can be the
string-concatenation of p and some other String r, returntrue . Otherwise, returnfalse . - NOTE: Any String is a prefix of itself, because r may be the empty String.
7.2.10 SameValue ( x, y )
内部比较
- If
Type (x) is different fromType (y), returnfalse . - If
Type (x) is Number, then- If x is
NaN and y isNaN , returntrue . - If x is
+0 and y is-0 , returnfalse . - If x is
-0 and y is+0 , returnfalse . - If x is the same
Number value as y, returntrue . - Return
false .
- If x is
- Return
SameValueNonNumber (x, y).
这个算法在比较有符号的 0 以及比较 NaN 时和严格相等比较算法不同。
7.2.11 SameValueZero ( x, y )
内部比较
- If
Type (x) is different fromType (y), returnfalse . - If
Type (x) is Number, then- If x is
NaN and y isNaN , returntrue . - If x is
+0 and y is-0 , returntrue . - If x is
-0 and y is+0 , returntrue . - If x is the same
Number value as y, returntrue . - Return
false.
- If x is
- Return
SameValueNonNumber (x, y).
SameValueZero 与 +0 和 -0 时不同
7.2.12 SameValueNonNumber ( x, y )
内部比较
Assert :Type (x) is not Number.Assert :Type (x) is the same asType (y).- If
Type (x) is Undefined, returntrue . - If
Type (x) is Null, returntrue . - If
Type (x) is String, then- If x and y are exactly the same sequence of code units (same length and same code units at corresponding indices), return
true ; otherwise, returnfalse .
- If x and y are exactly the same sequence of code units (same length and same code units at corresponding indices), return
- If
Type (x) is Boolean, then- If x and y are both
true or bothfalse , returntrue ; otherwise, returnfalse .
- If x and y are both
- If
Type (x) is Symbol, then- If x and y are both the same Symbol value, return
true ; otherwise, returnfalse .
- If x and y are both the same Symbol value, return
- If x and y are the same Object value, return
true . Otherwise, returnfalse .
7.2.13 抽象关系比较
比较x < y,x 和 y 都是 ECMAScript 语言值,将可能产生
- If the LeftFirst flag is
true, then- Let px be ?
ToPrimitive (x, hint Number). - Let py be ?
ToPrimitive (y, hint Number).
- Let px be ?
- Else the order of evaluation needs to be reversed to preserve left to right evaluation,
- Let py be ?
ToPrimitive (y, hint Number). - Let px be ?
ToPrimitive (x, hint Number).
- Let py be ?
- If
Type (px) is String andType (py) is String, then- If
IsStringPrefix (py, px) istrue , returnfalse . - If
IsStringPrefix (px, py) istrue , returntrue . - Let k be the smallest nonnegative
integer such that the code unit at index k within px is different from the code unit at index k within py. (There must be such a k, for neither String is a prefix of the other.) - Let m be the
integer that is the numeric value of the code unit at index k within px. - Let n be the
integer that is the numeric value of the code unit at index k within py. - If m < n, return
true . Otherwise, returnfalse .
- If
- Else,
- NOTE: Because px and py are primitive values evaluation order is not important.
- Let nx be ?
ToNumber (px). - Let ny be ?
ToNumber (py). - If nx is
NaN , returnundefined . - If ny is
NaN , returnundefined . - If nx and ny are the same
Number value , returnfalse . - If nx is
+0 and ny is-0 , returnfalse . - If nx is
-0 and ny is+0 , returnfalse . - If nx is
+∞ , returnfalse . - If ny is
+∞ , returntrue . - If ny is
-∞ , returnfalse . - If nx is
-∞ , returntrue . - If the
mathematical value of nx is less than themathematical value of ny—note that these mathematical values are both finite and not both zero—returntrue . Otherwise, returnfalse .
算法中的第三步和第七步不同是加法运算 + (
字符串类型的比较使用码元值序列的简单词典排序。这里没有尝试使用 Unicode 规范定义的更复杂的,基于语义的字符或字符串相等,以及排序顺序进行比较。因此,根据 Unicode 标准在规范上相等的字符串值可能测试为不相等。实际上,该算法假设了两个值是已经标准化的值。另外还需注意,对于包含补充字符的字符串,UTF-16 码元值序列与普通码元值序列的词典排序是不同的。
7.2.14 抽象相等比较
比较 x == y,产生
- If
Type (x) is the same asType (y), then- Return the result of performing
Strict Equality Comparison x === y.
- Return the result of performing
- If x is
null and y isundefined , returntrue . - If x is
undefined and y isnull , returntrue . - If
Type (x) is Number andType (y) is String, return the result of the comparison x == !ToNumber (y). - If
Type (x) is String andType (y) is Number, return the result of the comparison !ToNumber (x) == y. - If
Type (x) is Boolean, return the result of the comparison !ToNumber (x) == y. - If
Type (y) is Boolean, return the result of the comparison x == !ToNumber (y). - If
Type (x) is either String, Number, or Symbol andType (y) is Object, return the result of the comparison x ==ToPrimitive (y). - If
Type (x) is Object andType (y) is either String, Number, or Symbol, return the result of the comparisonToPrimitive (x) == y. - Return
false .
7.2.15 严格相等比较
比较 x === y,产生
- If
Type (x) is different fromType (y), returnfalse . - If
Type (x) is Number, then- If x is
NaN , returnfalse . - If y is
NaN , returnfalse . - If x is the same
Number value as y, returntrue . - If x is
+0 and y is-0 , returntrue . - If x is
-0 and y is+0 , returntrue . - Return
false .
- If x is
- Return
SameValueNonNumber (x, y).
该算法与
7.3 对象具有的操作
7.3.1 Get ( O, P )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Return ? O.[[Get]](P, O).
7.3.2 GetV ( V, P )
Assert :IsPropertyKey (P) istrue .- Let O be ?
ToObject (V). - Return ? O.[[Get]](P, V).
7.3.3 Set ( O, P, V, Throw )
7.3.4 CreateDataProperty ( O, P, V )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Let newDesc be the PropertyDescriptor { [[Value]]: V, [[Writable]]:
true , [[Enumerable]]:true , [[Configurable]]:true }. - Return ? O.[[DefineOwnProperty]](P, newDesc).
该
7.3.5 CreateMethodProperty ( O, P, V )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Let newDesc be the PropertyDescriptor { [[Value]]: V, [[Writable]]:
true , [[Enumerable]]:false , [[Configurable]]:true }. - Return ? O.[[DefineOwnProperty]](P, newDesc).
7.3.6 CreateDataPropertyOrThrow ( O, P, V )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Let success be ?
CreateDataProperty (O, P, V). - If success is
false , throw aTypeError exception. - Return success.
7.3.7 DefinePropertyOrThrow ( O, P, desc )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Let success be ? O.[[DefineOwnProperty]](P, desc).
- If success is
false , throw aTypeError exception. - Return success.
7.3.8 DeletePropertyOrThrow ( O, P )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Let success be ? O.[[Delete]](P).
- If success is
false , throw aTypeError exception. - Return success.
7.3.9 GetMethod ( V, P )
Assert :IsPropertyKey (P) istrue .- Let func be ?
GetV (V, P). - If func is either
undefined ornull , returnundefined . - If
IsCallable (func) isfalse , throw aTypeError exception. - Return func.
7.3.10 HasProperty ( O, P )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Return ? O.[[HasProperty]](P).
7.3.11 HasOwnProperty ( O, P )
Assert :Type (O) is Object.Assert :IsPropertyKey (P) istrue .- Let desc be ? O.[[GetOwnProperty]](P).
- If desc is
undefined , returnfalse . - Return
true .
7.3.12 Call ( F, V [ , argumentsList ] )
- If argumentsList is not present, set argumentsList to a new empty
List . - If
IsCallable (F) isfalse , throw aTypeError exception. - Return ? F.[[Call]](V, argumentsList).
7.3.13 Construct ( F [ , argumentsList [ , newTarget ]] )
- If newTarget is not present, set newTarget to F.
- If argumentsList is not present, set argumentsList to a new empty
List . Assert :IsConstructor (F) istrue .Assert :IsConstructor (newTarget) istrue .- Return ? F.[[Construct]](argumentsList, newTarget).
If newTarget is not present, this operation is equivalent to: new F(...argumentsList)
7.3.14 SetIntegrityLevel ( O, level )
Assert :Type (O) is Object.Assert : level is either"sealed"or"frozen".- Let status be ? O.[[PreventExtensions]]().
- If status is
false , returnfalse . - Let keys be ? O.[[OwnPropertyKeys]]().
- If level is
"sealed", then- For each element k of keys, do
- Perform ?
DefinePropertyOrThrow (O, k, PropertyDescriptor { [[Configurable]]:false }).
- Perform ?
- For each element k of keys, do
- Else level is
"frozen",- For each element k of keys, do
- Let currentDesc be ? O.[[GetOwnProperty]](k).
- If currentDesc is not
undefined , then- If
IsAccessorDescriptor (currentDesc) istrue , then- Let desc be the PropertyDescriptor { [[Configurable]]:
false }.
- Let desc be the PropertyDescriptor { [[Configurable]]:
- Else,
- Let desc be the PropertyDescriptor { [[Configurable]]:
false , [[Writable]]:false }.
- Let desc be the PropertyDescriptor { [[Configurable]]:
- Perform ?
DefinePropertyOrThrow (O, k, desc).
- If
- For each element k of keys, do
- Return
true .
7.3.15 TestIntegrityLevel ( O, level )
Assert :Type (O) is Object.Assert : level is either"sealed"or"frozen".- Let status be ?
IsExtensible (O). - If status is
true , returnfalse . - NOTE: If the object is extensible, none of its properties are examined.
- Let keys be ? O.[[OwnPropertyKeys]]().
- For each element k of keys, do
- Let currentDesc be ? O.[[GetOwnProperty]](k).
- If currentDesc is not
undefined , then- If currentDesc.[[Configurable]] is
true , returnfalse . - If level is
"frozen"andIsDataDescriptor (currentDesc) istrue , then- If currentDesc.[[Writable]] is
true , returnfalse .
- If currentDesc.[[Writable]] is
- If currentDesc.[[Configurable]] is
- Return
true .
7.3.16 CreateArrayFromList ( elements )
Assert : elements is aList whose elements are all ECMAScript language values.- Let array be !
ArrayCreate (0). - Let n be 0.
- For each element e of elements, do
- Let status be
CreateDataProperty (array, !ToString (n), e). Assert : status istrue .- Increment n by 1.
- Let status be
- Return array.
7.3.17 CreateListFromArrayLike ( obj [ , elementTypes ] )
7.3.18 Invoke ( V, P [ , argumentsList ] )
this 值, P 是属性 key, argumentsList 是传递给方法的参数列表。 如果 argumentsList 未提供,则使用一个空的
Assert :IsPropertyKey (P) istrue .- If argumentsList is not present, set argumentsList to a new empty
List . - Let func be ?
GetV (V, P). - Return ?
Call (func, V, argumentsList).
7.3.19 OrdinaryHasInstance ( C, O )
- If
IsCallable (C) isfalse , returnfalse . - If C has a [[BoundTargetFunction]] internal slot, then
- Let BC be C.[[BoundTargetFunction]].
- Return ?
InstanceofOperator (O, BC).
- If
Type (O) is not Object, returnfalse . - Let P be ?
Get (C,"prototype"). - If
Type (P) is not Object, throw aTypeError exception. - Repeat,
- Set O to ? O.[[GetPrototypeOf]]().
- If O is
null , returnfalse . - If
SameValue (P, O) istrue , returntrue .
7.3.20 SpeciesConstructor ( O, defaultConstructor )
Assert :Type (O) is Object.- Let C be ?
Get (O,"constructor"). - If C is
undefined , return defaultConstructor. - If
Type (C) is not Object, throw aTypeError exception. - Let S be ?
Get (C, @@species). - If S is either
undefined ornull , return defaultConstructor. - If
IsConstructor (S) istrue , return S. - Throw a
TypeError exception.
7.3.21 EnumerableOwnPropertyNames ( O, kind )
当使用对象 O 和字符串 kind 作为参数调用
Assert :Type (O) is Object.- Let ownKeys be ? O.[[OwnPropertyKeys]]().
- Let properties be a new empty
List . - For each element key of ownKeys in
List order, do- If
Type (key) is String, then- Let desc be ? O.[[GetOwnProperty]](key).
- If desc is not
undefined and desc.[[Enumerable]] istrue , then- If kind is
"key" , append key to properties. - Else,
- Let value be ?
Get (O, key). - If kind is
"value" , append value to properties. - Else,
Assert : kind is"key+value" .- Let entry be
CreateArrayFromList (« key, value »). - Append entry to properties.
- Let value be ?
- If kind is
- If
- Order the elements of properties so they are in the same relative order as would be produced by the Iterator that would be returned if the
EnumerateObjectProperties internal method were invoked with O. - Return properties.
7.3.22 GetFunctionRealm ( obj )
参数为 obj 的
Assert : obj is a callable object.- If obj has a [[Realm]] internal slot, then
- Return obj.[[Realm]].
- If obj is a Bound Function
exotic object , then- Let target be obj.[[BoundTargetFunction]].
- Return ?
GetFunctionRealm (target).
- If obj is a Proxy
exotic object , then- If obj.[[ProxyHandler]] is
null , throw aTypeError exception. - Let proxyTarget be obj.[[ProxyTarget]].
- Return ?
GetFunctionRealm (proxyTarget).
- If obj.[[ProxyHandler]] is
- Return
the current Realm Record .
第五步只有在 obj 是一个没有 [[Realm]] 内部槽的非标准函数怪异对象时执行。
7.3.23 CopyDataProperties ( target, source, excludedItems )
When the abstract operation CopyDataProperties is called with arguments target, source, and excludedItems, the following steps are taken:
Assert :Type (target) is Object.Assert : excludedItems is aList of property keys.- If source is
undefined ornull , return target. - Let from be !
ToObject (source). - Let keys be ? from.[[OwnPropertyKeys]]().
- For each element nextKey of keys in
List order, do- Let excluded be
false . - For each element e of excludedItems in
List order, do- If
SameValue (e, nextKey) istrue , then- Set excluded to
true .
- Set excluded to
- If
- If excluded is
false , then- Let desc be ? from.[[GetOwnProperty]](nextKey).
- If desc is not
undefined and desc.[[Enumerable]] istrue , then- Let propValue be ?
Get (from, nextKey). - Perform !
CreateDataProperty (target, nextKey, propValue).
- Let propValue be ?
- Let excluded be
- Return target.
The target passed in here is always a newly created object which is not directly accessible in case of an error being thrown.
7.4 迭代器对象具有的操作
参考常见的迭代接口 (
7.4.1 GetIterator ( obj [ , hint [, method ] )
参数为 obj 和可选参数 hint, method 的
- If hint is not present, set hint to
sync . Assert : hint is eithersync orasync .- If method is not present, then
- If hint is
async , then- Set method to ?
GetMethod (obj, @@asyncIterator). - If method is
undefined , then- Let syncMethod be ?
GetMethod (obj, @@iterator). - Let syncIteratorRecord be ?
GetIterator (obj,sync , syncMethod). - Return ?
CreateAsyncFromSyncIterator (syncIteratorRecord).
- Let syncMethod be ?
- Set method to ?
- Otherwise, set method to ?
GetMethod (obj, @@iterator).
- If hint is
- Let iterator be ?
Call (method, obj). - If
Type (iterator) is not Object, throw aTypeError exception. - Let nextMethod be ?
GetV (iterator,"next"). - Let iteratorRecord be
Record { [[Iterator]]: iterator, [[NextMethod]]: nextMethod, [[Done]]:false }. - Return iteratorRecord.
7.4.2 IteratorNext ( iteratorRecord [ , value ] )
参数为 iteratorRecord 和可选参数 value 的
7.4.3 IteratorComplete ( iterResult )
参数为 iterResult 的
7.4.4 IteratorValue ( iterResult )
使用参数为 iterResult 的
7.4.5 IteratorStep ( iteratorRecord )
使用参数 iteratorRecord 的
- Let result be ?
IteratorNext (iteratorRecord). - Let done be ?
IteratorComplete (result). - If done is
true , returnfalse . - Return result.
7.4.6 IteratorClose ( iteratorRecord, completion )
参数为 iteratorRecord 和 completion 的
Assert :Type (iteratorRecord.[[Iterator]]) is Object.Assert : completion is aCompletion Record .- Let iterator be iteratorRecord.[[Iterator]].
- Let return be ?
GetMethod (iterator,"return"). - If return is
undefined , returnCompletion (completion). - Let innerResult be
Call (return, iterator, « »). - If completion.[[Type]] is
throw , returnCompletion (completion). - If innerResult.[[Type]] is
throw , returnCompletion (innerResult). - If
Type (innerResult.[[Value]]) is not Object, throw aTypeError exception. - Return
Completion (completion).
7.4.7 AsyncIteratorClose ( iteratorRecord, completion )
The abstract operation AsyncIteratorClose with arguments iteratorRecord and completion is used to notify an async iterator that it should perform any actions it would normally perform when it has reached its completed state:
Assert :Type (iteratorRecord.[[Iterator]]) is Object.Assert : completion is aCompletion Record .- Let iterator be iteratorRecord.[[Iterator]].
- Let return be ?
GetMethod (iterator,"return"). - If return is
undefined , returnCompletion (completion). - Let innerResult be
Call (return, iterator, « »). - If innerResult.[[Type]] is
normal , set innerResult toAwait (innerResult.[[Value]]). - If completion.[[Type]] is
throw , returnCompletion (completion). - If innerResult.[[Type]] is
throw , returnCompletion (innerResult). - If
Type (innerResult.[[Value]]) is not Object, throw aTypeError exception. - Return
Completion (completion).
7.4.8 CreateIterResultObject ( value, done )
参数为 value 和 done 的
Assert :Type (done) is Boolean.- Let obj be
ObjectCreate (%ObjectPrototype% ). - Perform
CreateDataProperty (obj,"value", value). - Perform
CreateDataProperty (obj,"done", done). - Return obj.
7.4.9 CreateListIteratorRecord ( list )
参数为 list 的
- Let iterator be
ObjectCreate (%IteratorPrototype% , « [[IteratedList]], [[ListIteratorNextIndex]] »). - Set iterator.[[IteratedList]] to list.
- Set iterator.[[ListIteratorNextIndex]] to 0.
- Let steps be the algorithm steps defined in ListIterator
next(7.4.9.1 ). - Let next be
CreateBuiltinFunction (steps, « »). - Return
Record { [[Iterator]]: iterator, [[NextMethod]]: next, [[Done]]:false }.
这个迭代器对象列表从不直接通过 ECMAScript 代码访问。
7.4.9.1 ListIterator next ( )
ListIterator next 方法是一个标准的内置函数方法(章节
- Let O be the
this value. Assert :Type (O) is Object.Assert : O has an [[IteratedList]] internal slot.- Let list be O.[[IteratedList]].
- Let index be O.[[ListIteratorNextIndex]].
- Let len be the number of elements of list.
- If index ≥ len, then
- Return
CreateIterResultObject (undefined ,true ).
- Return
- Set O.[[ListIteratorNextIndex]] to index+1.
- Return
CreateIterResultObject (list[index],false ).
8 Executable Code and Execution Contexts
8.1 Lexical Environments
A Lexical Environment is a specification type used to define the association of
An
The outer environment reference is used to model the logical nesting of Lexical Environment values. The outer reference of a (inner) Lexical Environment is a reference to the Lexical Environment that logically surrounds the inner Lexical Environment. An outer Lexical Environment may, of course, have its own outer Lexical Environment. A Lexical Environment may serve as the outer environment for multiple inner Lexical Environments. For example, if a
A global environment is a Lexical Environment which does not have an outer environment. The
A module environment is a Lexical Environment that contains the bindings for the top level declarations of a
A function environment is a Lexical Environment that corresponds to the invocation of an ECMAScript this binding. A super method invocations.
Lexical Environments and
8.1.1 Environment Records
There are two primary kinds of Environment Record values used in this specification: declarative Environment Records and object Environment Records. Declarative Environment Records are used to define the effect of ECMAScript language syntactic elements such as
For specification purposes Environment Record values are values of the
| Method | Purpose |
|---|---|
| HasBinding(N) |
Determine if an |
| CreateMutableBinding(N, D) |
Create a new but uninitialized mutable binding in an |
| CreateImmutableBinding(N, S) |
Create a new but uninitialized immutable binding in an |
| InitializeBinding(N, V) |
Set the value of an already existing but uninitialized binding in an |
| SetMutableBinding(N, V, S) |
Set the value of an already existing mutable binding in an |
| GetBindingValue(N, S) |
Returns the value of an already existing binding from an |
| DeleteBinding(N) |
Delete a binding from an |
| HasThisBinding() |
Determine if an this binding. Return |
| HasSuperBinding() |
Determine if an super method binding. Return |
| WithBaseObject() |
If this with statement, return the with object. Otherwise, return |
8.1.1.1 Declarative Environment Records
Each declarative
The behaviour of the concrete specification methods for declarative Environment Records is defined by the following algorithms.
8.1.1.1.1 HasBinding ( N )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. - If envRec has a binding for the name that is the value of N, return
true . - Return
false .
8.1.1.1.2 CreateMutableBinding ( N, D )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. Assert : envRec does not already have a binding for N.- Create a mutable binding in envRec for N and record that it is uninitialized. If D is
true , record that the newly created binding may be deleted by a subsequent DeleteBinding call. - Return
NormalCompletion (empty ).
8.1.1.1.3 CreateImmutableBinding ( N, S )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. Assert : envRec does not already have a binding for N.- Create an immutable binding in envRec for N and record that it is uninitialized. If S is
true , record that the newly created binding is a strict binding. - Return
NormalCompletion (empty ).
8.1.1.1.4 InitializeBinding ( N, V )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. Assert : envRec must have an uninitialized binding for N.- Set the bound value for N in envRec to V.
Record that the binding for N in envRec has been initialized.- Return
NormalCompletion (empty ).
8.1.1.1.5 SetMutableBinding ( N, V, S )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. - If envRec does not have a binding for N, then
- If S is
true , throw aReferenceError exception. - Perform envRec.CreateMutableBinding(N,
true ). - Perform envRec.InitializeBinding(N, V).
- Return
NormalCompletion (empty ).
- If S is
- If the binding for N in envRec is a strict binding, set S to
true . - If the binding for N in envRec has not yet been initialized, throw a
ReferenceError exception. - Else if the binding for N in envRec is a mutable binding, change its bound value to V.
- Else,
Assert : This is an attempt to change the value of an immutable binding.- If S is
true , throw aTypeError exception.
- Return
NormalCompletion (empty ).
An example of ECMAScript code that results in a missing binding at step 2 is:
function f(){eval("var x; x = (delete x, 0);")}8.1.1.1.6 GetBindingValue ( N, S )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. Assert : envRec has a binding for N.- If the binding for N in envRec is an uninitialized binding, throw a
ReferenceError exception. - Return the value currently bound to N in envRec.
8.1.1.1.7 DeleteBinding ( N )
The concrete
- Let envRec be the declarative
Environment Record for which the method was invoked. Assert : envRec has a binding for the name that is the value of N.- If the binding for N in envRec cannot be deleted, return
false . - Remove the binding for N from envRec.
- Return
true .
8.1.1.1.8 HasThisBinding ( )
Regular declarative Environment Records do not provide a this binding.
- Return
false .
8.1.1.1.9 HasSuperBinding ( )
Regular declarative Environment Records do not provide a super binding.
- Return
false .
8.1.1.1.10 WithBaseObject ( )
Declarative Environment Records always return
- Return
undefined .
8.1.1.2 Object Environment Records
Each object
Object Environment Records created for with statements (
The behaviour of the concrete specification methods for object Environment Records is defined by the following algorithms.
8.1.1.2.1 HasBinding ( N )
The concrete
- Let envRec be the object
Environment Record for which the method was invoked. - Let bindings be the binding object for envRec.
- Let foundBinding be ?
HasProperty (bindings, N). - If foundBinding is
false , returnfalse . - If the withEnvironment flag of envRec is
false , returntrue . - Let unscopables be ?
Get (bindings, @@unscopables). - If
Type (unscopables) is Object, then - Return
true .
8.1.1.2.2 CreateMutableBinding ( N, D )
The concrete
- Let envRec be the object
Environment Record for which the method was invoked. - Let bindings be the binding object for envRec.
- Return ?
DefinePropertyOrThrow (bindings, N, PropertyDescriptor { [[Value]]:undefined , [[Writable]]:true , [[Enumerable]]:true , [[Configurable]]: D }).
Normally envRec will not have a binding for N but if it does, the semantics of
8.1.1.2.3 CreateImmutableBinding ( N, S )
The concrete
8.1.1.2.4 InitializeBinding ( N, V )
The concrete
- Let envRec be the object
Environment Record for which the method was invoked. Assert : envRec must have an uninitialized binding for N.Record that the binding for N in envRec has been initialized.- Return ? envRec.SetMutableBinding(N, V,
false ).
In this specification, all uses of CreateMutableBinding for object Environment Records are immediately followed by a call to InitializeBinding for the same name. Hence, implementations do not need to explicitly track the initialization state of individual object
8.1.1.2.5 SetMutableBinding ( N, V, S )
The concrete
- Let envRec be the object
Environment Record for which the method was invoked. - Let bindings be the binding object for envRec.
- Return ?
Set (bindings, N, V, S).
8.1.1.2.6 GetBindingValue ( N, S )
The concrete
- Let envRec be the object
Environment Record for which the method was invoked. - Let bindings be the binding object for envRec.
- Let value be ?
HasProperty (bindings, N). - If value is
false , then- If S is
false , return the valueundefined ; otherwise throw aReferenceError exception.
- If S is
- Return ?
Get (bindings, N).
8.1.1.2.7 DeleteBinding ( N )
The concrete
- Let envRec be the object
Environment Record for which the method was invoked. - Let bindings be the binding object for envRec.
- Return ? bindings.[[Delete]](N).
8.1.1.2.8 HasThisBinding ( )
Regular object Environment Records do not provide a this binding.
- Return
false .
8.1.1.2.9 HasSuperBinding ( )
Regular object Environment Records do not provide a super binding.
- Return
false .
8.1.1.2.10 WithBaseObject ( )
Object Environment Records return
- Let envRec be the object
Environment Record for which the method was invoked. - If the withEnvironment flag of envRec is
true , return the binding object for envRec. - Otherwise, return
undefined .
8.1.1.3 Function Environment Records
A function Environment Record is a declarative this binding. If a function is not an super, its function Environment Record also contains the state that is used to perform super method invocations from within the function.
Function Environment Records have the additional state fields listed in
| Field Name | Value | Meaning |
|---|---|---|
| [[ThisValue]] | Any |
This is the |
| [[ThisBindingStatus]] |
"lexical" | "initialized" | "uninitialized"
|
If the value is "lexical", this is an |
| [[FunctionObject]] | Object |
The |
| [[HomeObject]] |
Object | |
If the associated function has super property accesses and is not an |
| [[NewTarget]] |
Object | |
If this |
Function Environment Records support all of the declarative
| Method | Purpose |
|---|---|
| BindThisValue(V) | Set the [[ThisValue]] and record that it has been initialized. |
| GetThisBinding() |
Return the value of this this binding. Throws a this binding has not been initialized.
|
| GetSuperBase() |
Return the object that is the base for super property accesses bound in this super property accesses will produce runtime errors.
|
The behaviour of the additional concrete specification methods for function Environment Records is defined by the following algorithms:
8.1.1.3.1 BindThisValue ( V )
- Let envRec be the
function Environment Record for which the method was invoked. Assert : envRec.[[ThisBindingStatus]] is not"lexical".- If envRec.[[ThisBindingStatus]] is
"initialized", throw aReferenceError exception. - Set envRec.[[ThisValue]] to V.
- Set envRec.[[ThisBindingStatus]] to
"initialized". - Return V.
8.1.1.3.2 HasThisBinding ( )
- Let envRec be the
function Environment Record for which the method was invoked. - If envRec.[[ThisBindingStatus]] is
"lexical", returnfalse ; otherwise, returntrue .
8.1.1.3.3 HasSuperBinding ( )
- Let envRec be the
function Environment Record for which the method was invoked. - If envRec.[[ThisBindingStatus]] is
"lexical", returnfalse . - If envRec.[[HomeObject]] has the value
undefined , returnfalse ; otherwise, returntrue .
8.1.1.3.4 GetThisBinding ( )
- Let envRec be the
function Environment Record for which the method was invoked. Assert : envRec.[[ThisBindingStatus]] is not"lexical".- If envRec.[[ThisBindingStatus]] is
"uninitialized", throw aReferenceError exception. - Return envRec.[[ThisValue]].
8.1.1.3.5 GetSuperBase ( )
- Let envRec be the
function Environment Record for which the method was invoked. - Let home be envRec.[[HomeObject]].
- If home has the value
undefined , returnundefined . Assert :Type (home) is Object.- Return ? home.[[GetPrototypeOf]]().
8.1.1.4 Global Environment Records
A global
A global
Properties may be created directly on a
Global Environment Records have the additional fields listed in
| Field Name | Value | Meaning |
|---|---|---|
| [[ObjectRecord]] |
Object |
Binding object is the |
| [[GlobalThisValue]] | Object |
The value returned by this in global scope. Hosts may provide any ECMAScript Object value.
|
| [[DeclarativeRecord]] |
Declarative |
Contains bindings for all declarations in global code for the associated |
| [[VarNames]] |
|
The string names bound by |
| Method | Purpose |
|---|---|
| GetThisBinding() |
Return the value of this this binding.
|
| HasVarDeclaration (N) |
Determines if the argument identifier has a binding in this |
| HasLexicalDeclaration (N) |
Determines if the argument identifier has a binding in this |
| HasRestrictedGlobalProperty (N) |
Determines if the argument is the name of a |
| CanDeclareGlobalVar (N) | Determines if a corresponding CreateGlobalVarBinding call would succeed if called for the same argument N. |
| CanDeclareGlobalFunction (N) | Determines if a corresponding CreateGlobalFunctionBinding call would succeed if called for the same argument N. |
| CreateGlobalVarBinding(N, D) |
Used to create and initialize to var binding in the [[ObjectRecord]] component of a global var. The String value N is the bound name. If D is |
| CreateGlobalFunctionBinding(N, V, D) |
Create and initialize a global function binding in the [[ObjectRecord]] component of a global function. The String value N is the bound name. V is the initialization value. If the Boolean argument D is |
The behaviour of the concrete specification methods for global Environment Records is defined by the following algorithms.
8.1.1.4.1 HasBinding ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , returntrue . - Let ObjRec be envRec.[[ObjectRecord]].
- Return ? ObjRec.HasBinding(N).
8.1.1.4.2 CreateMutableBinding ( N, D )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , throw aTypeError exception. - Return DclRec.CreateMutableBinding(N, D).
8.1.1.4.3 CreateImmutableBinding ( N, S )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , throw aTypeError exception. - Return DclRec.CreateImmutableBinding(N, S).
8.1.1.4.4 InitializeBinding ( N, V )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , then- Return DclRec.InitializeBinding(N, V).
Assert : If the binding exists, it must be in the objectEnvironment Record .- Let ObjRec be envRec.[[ObjectRecord]].
- Return ? ObjRec.InitializeBinding(N, V).
8.1.1.4.5 SetMutableBinding ( N, V, S )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , then- Return DclRec.SetMutableBinding(N, V, S).
- Let ObjRec be envRec.[[ObjectRecord]].
- Return ? ObjRec.SetMutableBinding(N, V, S).
8.1.1.4.6 GetBindingValue ( N, S )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , then- Return DclRec.GetBindingValue(N, S).
- Let ObjRec be envRec.[[ObjectRecord]].
- Return ? ObjRec.GetBindingValue(N, S).
8.1.1.4.7 DeleteBinding ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- If DclRec.HasBinding(N) is
true , then- Return DclRec.DeleteBinding(N).
- Let ObjRec be envRec.[[ObjectRecord]].
- Let globalObject be the binding object for ObjRec.
- Let existingProp be ?
HasOwnProperty (globalObject, N). - If existingProp is
true , then- Let status be ? ObjRec.DeleteBinding(N).
- If status is
true , then- Let varNames be envRec.[[VarNames]].
- If N is an element of varNames, remove that element from the varNames.
- Return status.
- Return
true .
8.1.1.4.8 HasThisBinding ( )
- Return
true .
8.1.1.4.9 HasSuperBinding ( )
- Return
false .
8.1.1.4.10 WithBaseObject ( )
Global Environment Records always return
- Return
undefined .
8.1.1.4.11 GetThisBinding ( )
- Let envRec be the global
Environment Record for which the method was invoked. - Return envRec.[[GlobalThisValue]].
8.1.1.4.12 HasVarDeclaration ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let varDeclaredNames be envRec.[[VarNames]].
- If varDeclaredNames contains N, return
true . - Return
false .
8.1.1.4.13 HasLexicalDeclaration ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let DclRec be envRec.[[DeclarativeRecord]].
- Return DclRec.HasBinding(N).
8.1.1.4.14 HasRestrictedGlobalProperty ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let ObjRec be envRec.[[ObjectRecord]].
- Let globalObject be the binding object for ObjRec.
- Let existingProp be ? globalObject.[[GetOwnProperty]](N).
- If existingProp is
undefined , returnfalse . - If existingProp.[[Configurable]] is
true , returnfalse . - Return
true .
Properties may exist upon a undefined is an example of such a property.
8.1.1.4.15 CanDeclareGlobalVar ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let ObjRec be envRec.[[ObjectRecord]].
- Let globalObject be the binding object for ObjRec.
- Let hasProperty be ?
HasOwnProperty (globalObject, N). - If hasProperty is
true , returntrue . - Return ?
IsExtensible (globalObject).
8.1.1.4.16 CanDeclareGlobalFunction ( N )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let ObjRec be envRec.[[ObjectRecord]].
- Let globalObject be the binding object for ObjRec.
- Let existingProp be ? globalObject.[[GetOwnProperty]](N).
- If existingProp is
undefined , return ?IsExtensible (globalObject). - If existingProp.[[Configurable]] is
true , returntrue . - If
IsDataDescriptor (existingProp) istrue and existingProp has attribute values { [[Writable]]:true , [[Enumerable]]:true }, returntrue . - Return
false .
8.1.1.4.17 CreateGlobalVarBinding ( N, D )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let ObjRec be envRec.[[ObjectRecord]].
- Let globalObject be the binding object for ObjRec.
- Let hasProperty be ?
HasOwnProperty (globalObject, N). - Let extensible be ?
IsExtensible (globalObject). - If hasProperty is
false and extensible istrue , then- Perform ? ObjRec.CreateMutableBinding(N, D).
- Perform ? ObjRec.InitializeBinding(N,
undefined ).
- Let varDeclaredNames be envRec.[[VarNames]].
- If varDeclaredNames does not contain N, then
- Append N to varDeclaredNames.
- Return
NormalCompletion (empty ).
8.1.1.4.18 CreateGlobalFunctionBinding ( N, V, D )
The concrete
- Let envRec be the global
Environment Record for which the method was invoked. - Let ObjRec be envRec.[[ObjectRecord]].
- Let globalObject be the binding object for ObjRec.
- Let existingProp be ? globalObject.[[GetOwnProperty]](N).
- If existingProp is
undefined or existingProp.[[Configurable]] istrue , then- Let desc be the PropertyDescriptor { [[Value]]: V, [[Writable]]:
true , [[Enumerable]]:true , [[Configurable]]: D }.
- Let desc be the PropertyDescriptor { [[Value]]: V, [[Writable]]:
- Else,
- Let desc be the PropertyDescriptor { [[Value]]: V }.
- Perform ?
DefinePropertyOrThrow (globalObject, N, desc). Record that the binding for N in ObjRec has been initialized.- Perform ?
Set (globalObject, N, V,false ). - Let varDeclaredNames be envRec.[[VarNames]].
- If varDeclaredNames does not contain N, then
- Append N to varDeclaredNames.
- Return
NormalCompletion (empty ).
Global function declarations are always represented as own properties of the
8.1.1.5 Module Environment Records
A module
Module Environment Records support all of the declarative
| Method | Purpose |
|---|---|
| CreateImportBinding(N, M, N2) |
Create an immutable indirect binding in a module |
| GetThisBinding() |
Return the value of this this binding.
|
The behaviour of the additional concrete specification methods for module Environment Records are defined by the following algorithms:
8.1.1.5.1 GetBindingValue ( N, S )
The concrete
Assert : S istrue .- Let envRec be the module
Environment Record for which the method was invoked. Assert : envRec has a binding for N.- If the binding for N is an indirect binding, then
- Let M and N2 be the indirection values provided when this binding for N was created.
- Let targetEnv be M.[[Environment]].
- If targetEnv is
undefined , throw aReferenceError exception. - Let targetER be targetEnv's
EnvironmentRecord . - Return ? targetER.GetBindingValue(N2,
true ).
- If the binding for N in envRec is an uninitialized binding, throw a
ReferenceError exception. - Return the value currently bound to N in envRec.
S will always be
8.1.1.5.2 DeleteBinding ( N )
The concrete
Module Environment Records are only used within strict code and an
8.1.1.5.3 HasThisBinding ( )
Module Environment Records provide a this binding.
- Return
true .
8.1.1.5.4 GetThisBinding ( )
- Return
undefined .
8.1.1.5.5 CreateImportBinding ( N, M, N2 )
The concrete
- Let envRec be the module
Environment Record for which the method was invoked. Assert : envRec does not already have a binding for N.Assert : M is aModule Record .Assert : When M.[[Environment]] is instantiated it will have a direct binding for N2.- Create an immutable indirect binding in envRec for N that references M and N2 as its target binding and record that the binding is initialized.
- Return
NormalCompletion (empty ).
8.1.2 Lexical Environment Operations
The following
8.1.2.1 GetIdentifierReference ( lex, name, strict )
The abstract operation GetIdentifierReference is called with a
- If lex is the value
null , then- Return a value of type
Reference whose base value component isundefined , whose referenced name component is name, and whose strict reference flag is strict.
- Return a value of type
- Let envRec be lex's
EnvironmentRecord . - Let exists be ? envRec.HasBinding(name).
- If exists is
true , then- Return a value of type
Reference whose base value component is envRec, whose referenced name component is name, and whose strict reference flag is strict.
- Return a value of type
- Else,
- Let outer be the value of lex's outer environment reference.
- Return ?
GetIdentifierReference (outer, name, strict).
8.1.2.2 NewDeclarativeEnvironment ( E )
When the abstract operation NewDeclarativeEnvironment is called with a
- Let env be a new
Lexical Environment . - Let envRec be a new declarative
Environment Record containing no bindings. - Set env's
EnvironmentRecord to envRec. - Set the outer lexical environment reference of env to E.
- Return env.
8.1.2.3 NewObjectEnvironment ( O, E )
When the abstract operation NewObjectEnvironment is called with an Object O and a
- Let env be a new
Lexical Environment . - Let envRec be a new object
Environment Record containing O as the binding object. - Set env's
EnvironmentRecord to envRec. - Set the outer lexical environment reference of env to E.
- Return env.
8.1.2.4 NewFunctionEnvironment ( F, newTarget )
When the abstract operation NewFunctionEnvironment is called with arguments F and newTarget the following steps are performed:
Assert : F is an ECMAScript function.Assert :Type (newTarget) is Undefined or Object.- Let env be a new
Lexical Environment . - Let envRec be a new
function Environment Record containing no bindings. - Set envRec.[[FunctionObject]] to F.
- If F.[[ThisMode]] is
lexical , set envRec.[[ThisBindingStatus]] to"lexical". - Else, set envRec.[[ThisBindingStatus]] to
"uninitialized". - Let home be F.[[HomeObject]].
- Set envRec.[[HomeObject]] to home.
- Set envRec.[[NewTarget]] to newTarget.
- Set env's
EnvironmentRecord to envRec. - Set the outer lexical environment reference of env to F.[[Environment]].
- Return env.
8.1.2.5 NewGlobalEnvironment ( G, thisValue )
When the abstract operation NewGlobalEnvironment is called with arguments G and thisValue, the following steps are performed:
- Let env be a new
Lexical Environment . - Let objRec be a new object
Environment Record containing G as the binding object. - Let dclRec be a new declarative
Environment Record containing no bindings. - Let globalRec be a new global
Environment Record . - Set globalRec.[[ObjectRecord]] to objRec.
- Set globalRec.[[GlobalThisValue]] to thisValue.
- Set globalRec.[[DeclarativeRecord]] to dclRec.
- Set globalRec.[[VarNames]] to a new empty
List . - Set env's
EnvironmentRecord to globalRec. - Set the outer lexical environment reference of env to
null . - Return env.
8.1.2.6 NewModuleEnvironment ( E )
When the abstract operation NewModuleEnvironment is called with a
- Let env be a new
Lexical Environment . - Let envRec be a new module
Environment Record containing no bindings. - Set env's
EnvironmentRecord to envRec. - Set the outer lexical environment reference of env to E.
- Return env.
8.2 Realms
Before it is evaluated, all ECMAScript code must be associated with a realm. Conceptually, a
A
| Field Name | Value | Meaning |
|---|---|---|
| [[Intrinsics]] |
|
The intrinsic values used by code associated with this |
| [[GlobalObject]] | Object |
The |
| [[GlobalEnv]] |
|
The |
| [[TemplateMap]] |
A |
Template objects are canonicalized separately for each Once a |
| [[HostDefined]] |
Any, default value is |
Field reserved for use by host environments that need to associate additional information with a |
8.2.1 CreateRealm ( )
The abstract operation CreateRealm with no arguments performs the following steps:
- Let realmRec be a new
Realm Record . - Perform
CreateIntrinsics (realmRec). - Set realmRec.[[GlobalObject]] to
undefined . - Set realmRec.[[GlobalEnv]] to
undefined . - Set realmRec.[[TemplateMap]] to a new empty
List . - Return realmRec.
8.2.2 CreateIntrinsics ( realmRec )
The abstract operation CreateIntrinsics with argument realmRec performs the following steps:
- Let intrinsics be a new
Record . - Set realmRec.[[Intrinsics]] to intrinsics.
- Let objProto be
ObjectCreate (null ). - Set intrinsics.[[
%ObjectPrototype% ]] to objProto. - Let throwerSteps be the algorithm steps specified in
9.2.9.1 for the%ThrowTypeError% function. - Let thrower be
CreateBuiltinFunction (throwerSteps, « », realmRec,null ). - Set intrinsics.[[
%ThrowTypeError% ]] to thrower. - Let noSteps be an empty sequence of algorithm steps.
- Let funcProto be
CreateBuiltinFunction (noSteps, « », realmRec, objProto). - Set intrinsics.[[
%FunctionPrototype% ]] to funcProto. - Call thrower.[[SetPrototypeOf]](funcProto).
- Perform
AddRestrictedFunctionProperties (funcProto, realmRec). - Set fields of intrinsics with the values listed in
Table 7 that have not already been handled above. The field names are the names listed in column one of the table. The value of each field is a new object value fully and recursively populated with property values as defined by the specification of each object in clauses 18-26. All object property values are newly created object values. All values that are built-in function objects are created by performingCreateBuiltinFunction (<steps>, <slots>, realmRec, <prototype>) where <steps> is the definition of that function provided by this specification, <slots> is a list of the names, if any, of the function's specified internal slots, and <prototype> is the specified value of the function's [[Prototype]] internal slot. The creation of the intrinsics and their properties must be ordered to avoid any dependencies upon objects that have not yet been created. - Return intrinsics.
8.2.3 SetRealmGlobalObject ( realmRec, globalObj, thisValue )
The abstract operation SetRealmGlobalObject with arguments realmRec, globalObj, and thisValue performs the following steps:
- If globalObj is
undefined , then- Let intrinsics be realmRec.[[Intrinsics]].
- Set globalObj to
ObjectCreate (intrinsics.[[%ObjectPrototype% ]]).
Assert :Type (globalObj) is Object.- If thisValue is
undefined , set thisValue to globalObj. - Set realmRec.[[GlobalObject]] to globalObj.
- Let newGlobalEnv be
NewGlobalEnvironment (globalObj, thisValue). - Set realmRec.[[GlobalEnv]] to newGlobalEnv.
- Return realmRec.
8.2.4 SetDefaultGlobalBindings ( realmRec )
The abstract operation SetDefaultGlobalBindings with argument realmRec performs the following steps:
- Let global be realmRec.[[GlobalObject]].
- For each property of the Global Object specified in clause
18 , do- Let name be the String value of the
property name . - Let desc be the fully populated
data property descriptor for the property containing the specified attributes for the property. For properties listed in18.2 ,18.3 , or18.4 the value of the [[Value]] attribute is the corresponding intrinsic object from realmRec. - Perform ?
DefinePropertyOrThrow (global, name, desc).
- Let name be the String value of the
- Return global.
8.3 Execution Contexts
An execution context is a specification device that is used to track the runtime evaluation of code by an ECMAScript implementation. At any point in time, there is at most one execution context per
The execution context stack is used to track execution contexts. The
An execution context contains whatever implementation specific state is necessary to track the execution progress of its associated code. Each execution context has at least the state components listed in
| Component | Purpose |
|---|---|
| code evaluation state |
Any state needed to perform, suspend, and resume evaluation of the code associated with this |
| Function |
If this |
|
|
The |
| ScriptOrModule |
The |
Evaluation of code by the
The value of the
Execution contexts for ECMAScript code have the additional state components listed in
| Component | Purpose |
|---|---|
| LexicalEnvironment |
Identifies the |
| VariableEnvironment |
Identifies the |
The LexicalEnvironment and VariableEnvironment components of an execution context are always Lexical Environments.
Execution contexts representing the evaluation of generator objects have the additional state components listed in
| Component | Purpose |
|---|---|
| Generator |
The GeneratorObject that this |
In most situations only the
An execution context is purely a specification mechanism and need not correspond to any particular artefact of an ECMAScript implementation. It is impossible for ECMAScript code to directly access or observe an execution context.
8.3.1 GetActiveScriptOrModule ( )
The GetActiveScriptOrModule abstract operation is used to determine the running script or module, based on the
- If the
execution context stack is empty, returnnull . - Let ec be the topmost
execution context on theexecution context stack whose ScriptOrModule component is notnull . - If no such
execution context exists, returnnull . Otherwise, return ec's ScriptOrModule component.
8.3.2 ResolveBinding ( name [ , env ] )
The ResolveBinding abstract operation is used to determine the binding of name passed as a String value. The optional argument env can be used to explicitly provide the
- If env is not present or if env is
undefined , then- Set env to the
running execution context 's LexicalEnvironment.
- Set env to the
Assert : env is aLexical Environment .- If the code matching the syntactic production that is being evaluated is contained in
strict mode code , let strict betrue , else let strict befalse . - Return ?
GetIdentifierReference (env, name, strict).
The result of ResolveBinding is always a
8.3.3 GetThisEnvironment ( )
The abstract operation GetThisEnvironment finds the this. GetThisEnvironment performs the following steps:
- Let lex be the
running execution context 's LexicalEnvironment. - Repeat,
- Let envRec be lex's
EnvironmentRecord . - Let exists be envRec.HasThisBinding().
- If exists is
true , return envRec. - Let outer be the value of lex's outer environment reference.
Assert : outer is notnull .- Set lex to outer.
- Let envRec be lex's
The loop in step 2 will always terminate because the list of environments always ends with the this binding.
8.3.4 ResolveThisBinding ( )
The abstract operation ResolveThisBinding determines the binding of the this using the LexicalEnvironment of the
- Let envRec be
GetThisEnvironment (). - Return ? envRec.GetThisBinding().
8.3.5 GetNewTarget ( )
The abstract operation GetNewTarget determines the NewTarget value using the LexicalEnvironment of the
- Let envRec be
GetThisEnvironment (). Assert : envRec has a [[NewTarget]] field.- Return envRec.[[NewTarget]].
8.3.6 GetGlobalObject ( )
The abstract operation GetGlobalObject returns the
- Let ctx be the
running execution context . - Let currentRealm be ctx's
Realm . - Return currentRealm.[[GlobalObject]].
8.4 Jobs and Job Queues
A
Execution of a
| Field Name | Value | Meaning |
|---|---|---|
| [[Job]] |
The name of a |
This is the abstract operation that is performed when execution of this PendingJob is initiated. |
| [[Arguments]] |
A |
The |
| [[Realm]] |
A |
The |
| [[ScriptOrModule]] |
A |
The script or module for the initial |
| [[HostDefined]] |
Any, default value is |
Field reserved for use by host environments that need to associate additional information with a pending |
A
Each
A request for the future execution of a
The PendingJob records from a single
Typically an ECMAScript implementation will have its
The following
8.4.1 EnqueueJob ( queueName, job, arguments )
The EnqueueJob abstract operation requires three arguments: queueName, job, and arguments. It performs the following steps:
Assert :Type (queueName) is String and its value is the name of aJob Queue recognized by this implementation.Assert : job is the name of aJob .Assert : arguments is aList that has the same number of elements as the number of parameters required by job.- Let callerContext be the
running execution context . - Let callerRealm be callerContext's
Realm . - Let callerScriptOrModule be callerContext's ScriptOrModule.
- Let pending be PendingJob { [[Job]]: job, [[Arguments]]: arguments, [[Realm]]: callerRealm, [[ScriptOrModule]]: callerScriptOrModule, [[HostDefined]]:
undefined }. - Perform any implementation or host environment defined processing of pending. This may include modifying the [[HostDefined]] field or any other field of pending.
- Add pending at the back of the
Job Queue named by queueName. - Return
NormalCompletion (empty ).
8.5 InitializeHostDefinedRealm ( )
The abstract operation InitializeHostDefinedRealm performs the following steps:
- Let realm be
CreateRealm (). - Let newContext be a new
execution context . - Set the Function of newContext to
null . - Set the
Realm of newContext to realm. - Set the ScriptOrModule of newContext to
null . - Push newContext onto the
execution context stack ; newContext is now therunning execution context . - If the host requires use of an
exotic object to serve as realm'sglobal object , let global be such an object created in an implementation-defined manner. Otherwise, let global beundefined , indicating that an ordinary object should be created as theglobal object . - If the host requires that the
thisbinding in realm's global scope return an object other than theglobal object , let thisValue be such an object created in an implementation-defined manner. Otherwise, let thisValue beundefined , indicating that realm's globalthisbinding should be theglobal object . - Perform
SetRealmGlobalObject (realm, global, thisValue). - Let globalObj be ?
SetDefaultGlobalBindings (realm). - Create any implementation-defined
global object properties on globalObj. - Return
NormalCompletion (empty ).
8.6 RunJobs ( )
The abstract operation RunJobs performs the following steps:
- Perform ?
InitializeHostDefinedRealm (). - In an implementation-dependent manner, obtain the ECMAScript source texts (see clause
10 ) and any associated host-defined values for zero or more ECMAScript scripts and/or ECMAScript modules. For each such sourceText and hostDefined, do- If sourceText is the source code of a script, then
- Perform
EnqueueJob ("ScriptJobs",ScriptEvaluationJob , « sourceText, hostDefined »).
- Perform
- Else sourceText is the source code of a module,
- Perform
EnqueueJob ("ScriptJobs",TopLevelModuleEvaluationJob , « sourceText, hostDefined »).
- Perform
- If sourceText is the source code of a script, then
- Repeat,
Suspend therunning execution context and remove it from theexecution context stack .Assert : Theexecution context stack is now empty.- Let nextQueue be a non-empty
Job Queue chosen in an implementation-defined manner. If allJob Queues are empty, the result is implementation-defined. - Let nextPending be the PendingJob record at the front of nextQueue. Remove that record from nextQueue.
- Let newContext be a new
execution context . - Set newContext's Function to
null . - Set newContext's
Realm to nextPending.[[Realm]]. - Set newContext's ScriptOrModule to nextPending.[[ScriptOrModule]].
- Push newContext onto the
execution context stack ; newContext is now therunning execution context . - Perform any implementation or host environment defined job initialization using nextPending.
- Let result be the result of performing the abstract operation named by nextPending.[[Job]] using the elements of nextPending.[[Arguments]] as its arguments.
- If result is an
abrupt completion , performHostReportErrors (« result.[[Value]] »).
8.7 Agents
An agent comprises a set of ECMAScript execution contexts, an
An
Some web browsers share a single
While an
| Field Name | Value | Meaning |
|---|---|---|
| [[LittleEndian]] | Boolean | The default value computed for the isLittleEndian parameter when it is needed by the algorithms |
| [[CanBlock]] | Boolean | Determines whether the |
| [[Signifier]] | Any globally-unique value | Uniquely identifies the |
| [[IsLockFree1]] | Boolean | |
| [[IsLockFree2]] | Boolean | |
| [[CandidateExecution]] | A |
See the |
Once the values of [[Signifier]], [[IsLockFree1]], and [[IsLockFree2]] have been observed by any
The values of [[IsLockFree1]] and [[IsLockFree2]] are not necessarily determined by the hardware, but may also reflect implementation choices that can vary over time and between ECMAScript implementations.
There is no [[IsLockFree4]] property: 4-byte atomic operations are always lock-free.
In practice, if an atomic operation is implemented with any type of lock the operation is not lock-free. Lock-free does not imply wait-free: there is no upper bound on how many machine steps may be required to complete a lock-free atomic operation.
That an atomic access of size n is lock-free does not imply anything about the (perceived) atomicity of non-atomic accesses of size n, specifically, non-atomic accesses may still be performed as a sequence of several separate memory accesses. See
An
8.7.1 AgentSignifier ( )
The abstract operation AgentSignifier takes no arguments. It performs the following steps:
- Let AR be the
Agent Record of thesurrounding agent . - Return AR.[[Signifier]].
8.7.2 AgentCanSuspend ( )
The abstract operation AgentCanSuspend takes no arguments. It performs the following steps:
- Let AR be the
Agent Record of thesurrounding agent . - Return AR.[[CanBlock]].
In some environments it may not be reasonable for a given
8.8 Agent Clusters
An agent cluster is a maximal set of agents that can communicate by operating on shared memory.
Programs within different agents may share memory by unspecified means. At a minimum, the backing memory for SharedArrayBuffer objects can be shared among the agents in the cluster.
There may be agents that can communicate by message passing that cannot share memory; they are never in the same agent cluster.
Every
All agents within a cluster must have the same value for the [[LittleEndian]] property in their respective
If different agents within an agent cluster have different values of [[LittleEndian]] it becomes hard to use shared memory for multi-byte data.
All agents within a cluster must have the same values for the [[IsLockFree1]] property in their respective
All agents within a cluster must have different values for the [[Signifier]] property in their respective
An embedding may deactivate (stop forward progress) or activate (resume forward progress) an
The purpose of the preceding restriction is to avoid a situation where an
The implication of the restriction is that it will not be possible to share memory between agents that don't belong to the same suspend/wake collective within the embedding.
An embedding may terminate an
Prior to any evaluation of any ECMAScript code by any
All agents in an agent cluster share the same
An agent cluster is a specification mechanism and need not correspond to any particular artefact of an ECMAScript implementation.
8.9 Forward Progress
For an
An
Implementations must ensure that:
- every unblocked
agent with a dedicatedexecuting thread eventually makes forward progress - in a set of agents that share an
executing thread , oneagent eventually makes forward progress - an
agent does not cause anotheragent to become blocked except via explicit APIs that provide blocking.
This, along with the liveness guarantee in the "SeqCst" writes eventually become observable to all agents.
9 Ordinary and Exotic Objects Behaviours
9.1 Ordinary Object Internal Methods and Internal Slots
All ordinary objects have an internal slot called [[Prototype]]. The value of this internal slot is either
Every ordinary object has a Boolean-valued [[Extensible]] internal slot that controls whether or not properties may be added to the object. If the value of the [[Extensible]] internal slot is
In the following algorithm descriptions, assume O is an ordinary object, P is a property key value, V is any
Each ordinary object internal method delegates to a similarly-named abstract operation. If such an abstract operation depends on another internal method, then the internal method is invoked on O rather than calling the similarly-named abstract operation directly. These semantics ensure that exotic objects have their overridden internal methods invoked when ordinary object internal methods are applied to them.
9.1.1 [[GetPrototypeOf]] ( )
When the [[GetPrototypeOf]] internal method of O is called, the following steps are taken:
- Return !
OrdinaryGetPrototypeOf (O).
9.1.1.1 OrdinaryGetPrototypeOf ( O )
When the abstract operation OrdinaryGetPrototypeOf is called with Object O, the following steps are taken:
- Return O.[[Prototype]].
9.1.2 [[SetPrototypeOf]] ( V )
When the [[SetPrototypeOf]] internal method of O is called with argument V, the following steps are taken:
- Return !
OrdinarySetPrototypeOf (O, V).
9.1.2.1 OrdinarySetPrototypeOf ( O, V )
When the abstract operation OrdinarySetPrototypeOf is called with Object O and value V, the following steps are taken:
The loop in step 8 guarantees that there will be no circularities in any prototype chain that only includes objects that use the ordinary object definitions for [[GetPrototypeOf]] and [[SetPrototypeOf]].
9.1.3 [[IsExtensible]] ( )
When the [[IsExtensible]] internal method of O is called, the following steps are taken:
- Return !
OrdinaryIsExtensible (O).
9.1.3.1 OrdinaryIsExtensible ( O )
When the abstract operation OrdinaryIsExtensible is called with Object O, the following steps are taken:
- Return O.[[Extensible]].
9.1.4 [[PreventExtensions]] ( )
When the [[PreventExtensions]] internal method of O is called, the following steps are taken:
- Return !
OrdinaryPreventExtensions (O).
9.1.4.1 OrdinaryPreventExtensions ( O )
When the abstract operation OrdinaryPreventExtensions is called with Object O, the following steps are taken:
- Set O.[[Extensible]] to
false . - Return
true .
9.1.5 [[GetOwnProperty]] ( P )
When the [[GetOwnProperty]] internal method of O is called with property key P, the following steps are taken:
- Return !
OrdinaryGetOwnProperty (O, P).
9.1.5.1 OrdinaryGetOwnProperty ( O, P )
When the abstract operation OrdinaryGetOwnProperty is called with Object O and with property key P, the following steps are taken:
Assert :IsPropertyKey (P) istrue .- If O does not have an own property with key P, return
undefined . - Let D be a newly created
Property Descriptor with no fields. - Let X be O's own property whose key is P.
- If X is a
data property , then- Set D.[[Value]] to the value of X's [[Value]] attribute.
- Set D.[[Writable]] to the value of X's [[Writable]] attribute.
- Else X is an
accessor property ,- Set D.[[Get]] to the value of X's [[Get]] attribute.
- Set D.[[Set]] to the value of X's [[Set]] attribute.
- Set D.[[Enumerable]] to the value of X's [[Enumerable]] attribute.
- Set D.[[Configurable]] to the value of X's [[Configurable]] attribute.
- Return D.
9.1.6 [[DefineOwnProperty]] ( P, Desc )
When the [[DefineOwnProperty]] internal method of O is called with property key P and
- Return ?
OrdinaryDefineOwnProperty (O, P, Desc).
9.1.6.1 OrdinaryDefineOwnProperty ( O, P, Desc )
When the abstract operation OrdinaryDefineOwnProperty is called with Object O, property key P, and
- Let current be ? O.[[GetOwnProperty]](P).
- Let extensible be O.[[Extensible]].
- Return
ValidateAndApplyPropertyDescriptor (O, P, extensible, Desc, current).
9.1.6.2 IsCompatiblePropertyDescriptor ( Extensible, Desc, Current )
When the abstract operation IsCompatiblePropertyDescriptor is called with Boolean value Extensible, and Property Descriptors Desc, and Current, the following steps are taken:
- Return
ValidateAndApplyPropertyDescriptor (undefined ,undefined , Extensible, Desc, Current).
9.1.6.3 ValidateAndApplyPropertyDescriptor ( O, P, extensible, Desc, current )
When the abstract operation ValidateAndApplyPropertyDescriptor is called with Object O, property key P, Boolean value extensible, and Property Descriptors Desc, and current, the following steps are taken:
If
Assert : If O is notundefined , thenIsPropertyKey (P) istrue .- If current is
undefined , then- If extensible is
false , returnfalse . Assert : extensible istrue .- If
IsGenericDescriptor (Desc) istrue orIsDataDescriptor (Desc) istrue , then- If O is not
undefined , create an owndata property named P of object O whose [[Value]], [[Writable]], [[Enumerable]] and [[Configurable]] attribute values are described by Desc. If the value of an attribute field of Desc is absent, the attribute of the newly created property is set to its default value.
- If O is not
- Else Desc must be an accessor
Property Descriptor ,- If O is not
undefined , create an ownaccessor property named P of object O whose [[Get]], [[Set]], [[Enumerable]] and [[Configurable]] attribute values are described by Desc. If the value of an attribute field of Desc is absent, the attribute of the newly created property is set to its default value.
- If O is not
- Return
true .
- If extensible is
- If every field in Desc is absent, return
true . - If current.[[Configurable]] is
false , then- If Desc.[[Configurable]] is present and its value is
true , returnfalse . - If Desc.[[Enumerable]] is present and the [[Enumerable]] fields of current and Desc are the Boolean negation of each other, return
false .
- If Desc.[[Configurable]] is present and its value is
- If
IsGenericDescriptor (Desc) istrue , no further validation is required. - Else if
IsDataDescriptor (current) andIsDataDescriptor (Desc) have different results, then- If current.[[Configurable]] is
false , returnfalse . - If
IsDataDescriptor (current) istrue , then- If O is not
undefined , convert the property named P of object O from adata property to anaccessor property . Preserve the existing values of the converted property's [[Configurable]] and [[Enumerable]] attributes and set the rest of the property's attributes to their default values.
- If O is not
- Else,
- If O is not
undefined , convert the property named P of object O from anaccessor property to adata property . Preserve the existing values of the converted property's [[Configurable]] and [[Enumerable]] attributes and set the rest of the property's attributes to their default values.
- If O is not
- If current.[[Configurable]] is
- Else if
IsDataDescriptor (current) andIsDataDescriptor (Desc) are bothtrue , then- If current.[[Configurable]] is
false and current.[[Writable]] isfalse , then- If Desc.[[Writable]] is present and Desc.[[Writable]] is
true , returnfalse . - If Desc.[[Value]] is present and
SameValue (Desc.[[Value]], current.[[Value]]) isfalse , returnfalse . - Return
true .
- If Desc.[[Writable]] is present and Desc.[[Writable]] is
- If current.[[Configurable]] is
- Else
IsAccessorDescriptor (current) andIsAccessorDescriptor (Desc) are bothtrue , - If O is not
undefined , then- For each field of Desc that is present, set the corresponding attribute of the property named P of object O to the value of the field.
- Return
true .
9.1.7 [[HasProperty]] ( P )
When the [[HasProperty]] internal method of O is called with property key P, the following steps are taken:
- Return ?
OrdinaryHasProperty (O, P).
9.1.7.1 OrdinaryHasProperty ( O, P )
When the abstract operation OrdinaryHasProperty is called with Object O and with property key P, the following steps are taken:
Assert :IsPropertyKey (P) istrue .- Let hasOwn be ? O.[[GetOwnProperty]](P).
- If hasOwn is not
undefined , returntrue . - Let parent be ? O.[[GetPrototypeOf]]().
- If parent is not
null , then- Return ? parent.[[HasProperty]](P).
- Return
false .
9.1.8 [[Get]] ( P, Receiver )
When the [[Get]] internal method of O is called with property key P and
- Return ?
OrdinaryGet (O, P, Receiver).
9.1.8.1 OrdinaryGet ( O, P, Receiver )
When the abstract operation OrdinaryGet is called with Object O, property key P, and
Assert :IsPropertyKey (P) istrue .- Let desc be ? O.[[GetOwnProperty]](P).
- If desc is
undefined , then- Let parent be ? O.[[GetPrototypeOf]]().
- If parent is
null , returnundefined . - Return ? parent.[[Get]](P, Receiver).
- If
IsDataDescriptor (desc) istrue , return desc.[[Value]]. Assert :IsAccessorDescriptor (desc) istrue .- Let getter be desc.[[Get]].
- If getter is
undefined , returnundefined . - Return ?
Call (getter, Receiver).
9.1.9 [[Set]] ( P, V, Receiver )
When the [[Set]] internal method of O is called with property key P, value V, and
- Return ?
OrdinarySet (O, P, V, Receiver).
9.1.9.1 OrdinarySet ( O, P, V, Receiver )
When the abstract operation OrdinarySet is called with Object O, property key P, value V, and
Assert :IsPropertyKey (P) istrue .- Let ownDesc be ? O.[[GetOwnProperty]](P).
- Return
OrdinarySetWithOwnDescriptor (O, P, V, Receiver, ownDesc).
9.1.9.2 OrdinarySetWithOwnDescriptor ( O, P, V, Receiver, ownDesc )
When the abstract operation OrdinarySetWithOwnDescriptor is called with Object O, property key P, value V,
Assert :IsPropertyKey (P) istrue .- If ownDesc is
undefined , then- Let parent be ? O.[[GetPrototypeOf]]().
- If parent is not
null , then- Return ? parent.[[Set]](P, V, Receiver).
- Else,
- Set ownDesc to the PropertyDescriptor { [[Value]]:
undefined , [[Writable]]:true , [[Enumerable]]:true , [[Configurable]]:true }.
- Set ownDesc to the PropertyDescriptor { [[Value]]:
- If
IsDataDescriptor (ownDesc) istrue , then- If ownDesc.[[Writable]] is
false , returnfalse . - If
Type (Receiver) is not Object, returnfalse . - Let existingDescriptor be ? Receiver.[[GetOwnProperty]](P).
- If existingDescriptor is not
undefined , then- If
IsAccessorDescriptor (existingDescriptor) istrue , returnfalse . - If existingDescriptor.[[Writable]] is
false , returnfalse . - Let valueDesc be the PropertyDescriptor { [[Value]]: V }.
- Return ? Receiver.[[DefineOwnProperty]](P, valueDesc).
- If
- Else Receiver does not currently have a property P,
- Return ?
CreateDataProperty (Receiver, P, V).
- Return ?
- If ownDesc.[[Writable]] is
Assert :IsAccessorDescriptor (ownDesc) istrue .- Let setter be ownDesc.[[Set]].
- If setter is
undefined , returnfalse . - Perform ?
Call (setter, Receiver, « V »). - Return
true .
9.1.10 [[Delete]] ( P )
When the [[Delete]] internal method of O is called with property key P, the following steps are taken:
- Return ?
OrdinaryDelete (O, P).
9.1.10.1 OrdinaryDelete ( O, P )
When the abstract operation OrdinaryDelete is called with Object O and property key P, the following steps are taken:
Assert :IsPropertyKey (P) istrue .- Let desc be ? O.[[GetOwnProperty]](P).
- If desc is
undefined , returntrue . - If desc.[[Configurable]] is
true , then- Remove the own property with name P from O.
- Return
true .
- Return
false .
9.1.11 [[OwnPropertyKeys]] ( )
When the [[OwnPropertyKeys]] internal method of O is called, the following steps are taken:
- Return !
OrdinaryOwnPropertyKeys (O).
9.1.11.1 OrdinaryOwnPropertyKeys ( O )
When the abstract operation OrdinaryOwnPropertyKeys is called with Object O, the following steps are taken:
- Let keys be a new empty
List . - For each own property key P of O that is an
integer index , in ascending numeric index order, do- Add P as the last element of keys.
- For each own property key P of O that is a String but is not an
integer index , in ascending chronological order of property creation, do- Add P as the last element of keys.
- For each own property key P of O that is a Symbol, in ascending chronological order of property creation, do
- Add P as the last element of keys.
- Return keys.
9.1.12 ObjectCreate ( proto [ , internalSlotsList ] )
The abstract operation ObjectCreate with argument proto (an object or null) is used to specify the runtime creation of new ordinary objects. The optional argument internalSlotsList is a
- If internalSlotsList is not present, set internalSlotsList to a new empty
List . - Let obj be a newly created object with an internal slot for each name in internalSlotsList.
- Set obj's essential internal methods to the default ordinary object definitions specified in
9.1 . - Set obj.[[Prototype]] to proto.
- Set obj.[[Extensible]] to
true . - Return obj.
9.1.13 OrdinaryCreateFromConstructor ( constructor, intrinsicDefaultProto [ , internalSlotsList ] )
The abstract operation OrdinaryCreateFromConstructor creates an ordinary object whose [[Prototype]] value is retrieved from a prototype property, if it exists. Otherwise the intrinsic named by intrinsicDefaultProto is used for [[Prototype]]. The optional internalSlotsList is a
Assert : intrinsicDefaultProto is a String value that is this specification's name of an intrinsic object. The corresponding object must be an intrinsic that is intended to be used as the [[Prototype]] value of an object.- Let proto be ?
GetPrototypeFromConstructor (constructor, intrinsicDefaultProto). - Return
ObjectCreate (proto, internalSlotsList).
9.1.14 GetPrototypeFromConstructor ( constructor, intrinsicDefaultProto )
The abstract operation GetPrototypeFromConstructor determines the [[Prototype]] value that should be used to create an object corresponding to a specific prototype property, if it exists. Otherwise the intrinsic named by intrinsicDefaultProto is used for [[Prototype]]. This abstract operation performs the following steps:
Assert : intrinsicDefaultProto is a String value that is this specification's name of an intrinsic object. The corresponding object must be an intrinsic that is intended to be used as the [[Prototype]] value of an object.Assert :IsCallable (constructor) istrue .- Let proto be ?
Get (constructor,"prototype"). - If
Type (proto) is not Object, then- Let realm be ?
GetFunctionRealm (constructor). - Set proto to realm's intrinsic object named intrinsicDefaultProto.
- Let realm be ?
- Return proto.
If constructor does not supply a [[Prototype]] value, the default value that is used is obtained from the
9.2 ECMAScript Function Objects
ECMAScript function objects encapsulate parameterized ECMAScript code closed over a lexical environment and support the dynamic evaluation of that code. An ECMAScript
ECMAScript function objects have the additional internal slots listed in
| Internal Slot | Type | Description |
|---|---|---|
| [[Environment]] |
|
The |
| [[FormalParameters]] |
|
The root parse node of the source text that defines the function's formal parameter list. |
| [[FunctionKind]] | String |
Either "normal", "classConstructor", "generator", or "async".
|
| [[ECMAScriptCode]] |
|
The root parse node of the source text that defines the function's body. |
| [[ConstructorKind]] | String |
Either "base" or "derived".
|
| [[Realm]] |
|
The |
| [[ScriptOrModule]] |
|
The script or module in which the function was created. |
| [[ThisMode]] | (lexical, strict, global) |
Defines how this references are interpreted within the formal parameters and code body of the function. this refers to the |
| [[Strict]] | Boolean |
|
| [[HomeObject]] | Object |
If the function uses super, this is the object whose [[GetPrototypeOf]] provides the object where super property lookups begin.
|
All ECMAScript function objects have the [[Call]] internal method defined here. ECMAScript functions that are also constructors in addition have the [[Construct]] internal method.
9.2.1 [[Call]] ( thisArgument, argumentsList )
The [[Call]] internal method for an ECMAScript
Assert : F is an ECMAScriptfunction object .- If F.[[FunctionKind]] is
"classConstructor", throw aTypeError exception. - Let callerContext be the
running execution context . - Let calleeContext be
PrepareForOrdinaryCall (F,undefined ). Assert : calleeContext is now therunning execution context .- Perform
OrdinaryCallBindThis (F, calleeContext, thisArgument). - Let result be
OrdinaryCallEvaluateBody (F, argumentsList). - Remove calleeContext from the
execution context stack and restore callerContext as therunning execution context . - If result.[[Type]] is
return , returnNormalCompletion (result.[[Value]]). ReturnIfAbrupt (result).- Return
NormalCompletion (undefined ).
When calleeContext is removed from the
9.2.1.1 PrepareForOrdinaryCall ( F, newTarget )
When the abstract operation PrepareForOrdinaryCall is called with
Assert :Type (newTarget) is Undefined or Object.- Let callerContext be the
running execution context . - Let calleeContext be a new ECMAScript code
execution context . - Set the Function of calleeContext to F.
- Let calleeRealm be F.[[Realm]].
- Set the
Realm of calleeContext to calleeRealm. - Set the ScriptOrModule of calleeContext to F.[[ScriptOrModule]].
- Let localEnv be
NewFunctionEnvironment (F, newTarget). - Set the LexicalEnvironment of calleeContext to localEnv.
- Set the VariableEnvironment of calleeContext to localEnv.
- If callerContext is not already suspended, suspend callerContext.
- Push calleeContext onto the
execution context stack ; calleeContext is now therunning execution context . - NOTE: Any exception objects produced after this point are associated with calleeRealm.
- Return calleeContext.
9.2.1.2 OrdinaryCallBindThis ( F, calleeContext, thisArgument )
When the abstract operation OrdinaryCallBindThis is called with
- Let thisMode be F.[[ThisMode]].
- If thisMode is
lexical , returnNormalCompletion (undefined ). - Let calleeRealm be F.[[Realm]].
- Let localEnv be the LexicalEnvironment of calleeContext.
- If thisMode is
strict , let thisValue be thisArgument. - Else,
- If thisArgument is
undefined ornull , then- Let globalEnv be calleeRealm.[[GlobalEnv]].
- Let globalEnvRec be globalEnv's
EnvironmentRecord . Assert : globalEnvRec is a globalEnvironment Record .- Let thisValue be globalEnvRec.[[GlobalThisValue]].
- Else,
- If thisArgument is
- Let envRec be localEnv's
EnvironmentRecord . Assert : envRec is afunction Environment Record .Assert : The next step never returns anabrupt completion because envRec.[[ThisBindingStatus]] is not"initialized".- Return envRec.BindThisValue(thisValue).
9.2.1.3 OrdinaryCallEvaluateBody ( F, argumentsList )
When the abstract operation OrdinaryCallEvaluateBody is called with
- Return the result of EvaluateBody of the parsed code that is F.[[ECMAScriptCode]] passing F and argumentsList as the arguments.
9.2.2 [[Construct]] ( argumentsList, newTarget )
The [[Construct]] internal method for an ECMAScript
Assert : F is an ECMAScriptfunction object .Assert :Type (newTarget) is Object.- Let callerContext be the
running execution context . - Let kind be F.[[ConstructorKind]].
- If kind is
"base", then- Let thisArgument be ?
OrdinaryCreateFromConstructor (newTarget,"%ObjectPrototype%").
- Let thisArgument be ?
- Let calleeContext be
PrepareForOrdinaryCall (F, newTarget). Assert : calleeContext is now therunning execution context .- If kind is
"base", performOrdinaryCallBindThis (F, calleeContext, thisArgument). - Let constructorEnv be the LexicalEnvironment of calleeContext.
- Let envRec be constructorEnv's
EnvironmentRecord . - Let result be
OrdinaryCallEvaluateBody (F, argumentsList). - Remove calleeContext from the
execution context stack and restore callerContext as therunning execution context . - If result.[[Type]] is
return , then- If
Type (result.[[Value]]) is Object, returnNormalCompletion (result.[[Value]]). - If kind is
"base", returnNormalCompletion (thisArgument). - If result.[[Value]] is not
undefined , throw aTypeError exception.
- If
- Else,
ReturnIfAbrupt (result). - Return ? envRec.GetThisBinding().
9.2.3 FunctionAllocate ( functionPrototype, strict, functionKind )
The abstract operation FunctionAllocate requires the three arguments functionPrototype, strict and functionKind. FunctionAllocate performs the following steps:
Assert :Type (functionPrototype) is Object.Assert : functionKind is either"normal","non-constructor","generator","async", or"async generator".- If functionKind is
"normal", let needsConstruct betrue . - Else, let needsConstruct be
false . - If functionKind is
"non-constructor", set functionKind to"normal". - Let F be a newly created ECMAScript
function object with the internal slots listed inTable 27 . All of those internal slots are initialized toundefined . - Set F's essential internal methods to the default ordinary object definitions specified in
9.1 . - Set F.[[Call]] to the definition specified in
9.2.1 . - If needsConstruct is
true , then- Set F.[[Construct]] to the definition specified in
9.2.2 . - Set F.[[ConstructorKind]] to
"base".
- Set F.[[Construct]] to the definition specified in
- Set F.[[Strict]] to strict.
- Set F.[[FunctionKind]] to functionKind.
- Set F.[[Prototype]] to functionPrototype.
- Set F.[[Extensible]] to
true . - Set F.[[Realm]] to
the current Realm Record . - Return F.
9.2.4 FunctionInitialize ( F, kind, ParameterList, Body, Scope )
The abstract operation FunctionInitialize requires the arguments: a
- Let len be the ExpectedArgumentCount of ParameterList.
- Perform !
SetFunctionLength (F, len). - Let Strict be F.[[Strict]].
- Set F.[[Environment]] to Scope.
- Set F.[[FormalParameters]] to ParameterList.
- Set F.[[ECMAScriptCode]] to Body.
- Set F.[[ScriptOrModule]] to
GetActiveScriptOrModule (). - If kind is
Arrow , set F.[[ThisMode]] tolexical . - Else if Strict is
true , set F.[[ThisMode]] tostrict . - Else, set F.[[ThisMode]] to
global . - Return F.
9.2.5 FunctionCreate ( kind, ParameterList, Body, Scope, Strict [ , prototype ] )
The abstract operation FunctionCreate requires the arguments: kind which is one of (Normal, Method, Arrow), a parameter list
- If prototype is not present, then
- Set prototype to the intrinsic object
%FunctionPrototype% .
- Set prototype to the intrinsic object
- If kind is not
Normal , let allocKind be"non-constructor". - Else, let allocKind be
"normal". - Let F be
FunctionAllocate (prototype, Strict, allocKind). - Return
FunctionInitialize (F, kind, ParameterList, Body, Scope).
9.2.6 GeneratorFunctionCreate ( kind, ParameterList, Body, Scope, Strict )
The abstract operation GeneratorFunctionCreate requires the arguments: kind which is one of (Normal, Method), a parameter list
- Let functionPrototype be the intrinsic object
%Generator% . - Let F be
FunctionAllocate (functionPrototype, Strict,"generator"). - Return
FunctionInitialize (F, kind, ParameterList, Body, Scope).
9.2.7 AsyncGeneratorFunctionCreate ( kind, ParameterList, Body, Scope, Strict )
The abstract operation AsyncGeneratorFunctionCreate requires the arguments: kind which is one of (
- Let functionPrototype be the intrinsic object
%AsyncGenerator% . - Let F be !
FunctionAllocate (functionPrototype, Strict,"generator"). - Return !
FunctionInitialize (F, kind, ParameterList, Body, Scope).
9.2.8 AsyncFunctionCreate ( kind, parameters, body, Scope, Strict )
The abstract operation AsyncFunctionCreate requires the arguments: kind which is one of (
- Let functionPrototype be the intrinsic object
%AsyncFunctionPrototype% . - Let F be !
FunctionAllocate (functionPrototype, Strict,"async"). - Return !
FunctionInitialize (F, kind, parameters, body, Scope).
9.2.9 AddRestrictedFunctionProperties ( F, realm )
The abstract operation AddRestrictedFunctionProperties is called with a
Assert : realm.[[Intrinsics]].[[%ThrowTypeError% ]] exists and has been initialized.- Let thrower be realm.[[Intrinsics]].[[
%ThrowTypeError% ]]. - Perform !
DefinePropertyOrThrow (F,"caller", PropertyDescriptor { [[Get]]: thrower, [[Set]]: thrower, [[Enumerable]]:false , [[Configurable]]:true }). - Return !
DefinePropertyOrThrow (F,"arguments", PropertyDescriptor { [[Get]]: thrower, [[Set]]: thrower, [[Enumerable]]:false , [[Configurable]]:true }).
9.2.9.1 %ThrowTypeError% ( )
The %ThrowTypeError% intrinsic is an anonymous built-in
- Throw a
TypeError exception.
The value of the [[Extensible]] internal slot of a %ThrowTypeError% function is
The length property of a %ThrowTypeError% function has the attributes { [[Writable]]:
9.2.10 MakeConstructor ( F [ , writablePrototype [ , prototype ] ] )
The abstract operation MakeConstructor requires a Function argument F and optionally, a Boolean writablePrototype and an object prototype. If prototype is provided it is assumed to already contain, if needed, a "constructor" property whose value is F. This operation converts F into a
Assert : F is an ECMAScriptfunction object .Assert :IsConstructor (F) istrue .Assert : F is an extensible object that does not have aprototypeown property.- If writablePrototype is not present, set writablePrototype to
true . - If prototype is not present, then
- Set prototype to
ObjectCreate (%ObjectPrototype% ). - Perform !
DefinePropertyOrThrow (prototype,"constructor", PropertyDescriptor { [[Value]]: F, [[Writable]]: writablePrototype, [[Enumerable]]:false , [[Configurable]]:true }).
- Set prototype to
- Perform !
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]: writablePrototype, [[Enumerable]]:false , [[Configurable]]:false }). - Return
NormalCompletion (undefined ).
9.2.11 MakeClassConstructor ( F )
The abstract operation MakeClassConstructor with argument F performs the following steps:
Assert : F is an ECMAScriptfunction object .Assert : F.[[FunctionKind]] is"normal".- Set F.[[FunctionKind]] to
"classConstructor". - Return
NormalCompletion (undefined ).
9.2.12 MakeMethod ( F, homeObject )
The abstract operation MakeMethod with arguments F and homeObject configures F as a method by performing the following steps:
Assert : F is an ECMAScriptfunction object .Assert :Type (homeObject) is Object.- Set F.[[HomeObject]] to homeObject.
- Return
NormalCompletion (undefined ).
9.2.13 SetFunctionName ( F, name [ , prefix ] )
The abstract operation SetFunctionName requires a Function argument F, a String or Symbol argument name and optionally a String argument prefix. This operation adds a name property to F by performing the following steps:
Assert : F is an extensible object that does not have anameown property.Assert :Type (name) is either Symbol or String.Assert : If prefix is present, thenType (prefix) is String.- If
Type (name) is Symbol, then- Let description be name's [[Description]] value.
- If description is
undefined , set name to the empty String. - Else, set name to the
string-concatenation of"[", description, and"]".
- If prefix is present, then
- Set name to the
string-concatenation of prefix, the code unit 0x0020 (SPACE), and name.
- Set name to the
- Return !
DefinePropertyOrThrow (F,"name", PropertyDescriptor { [[Value]]: name, [[Writable]]:false , [[Enumerable]]:false , [[Configurable]]:true }).
9.2.14 SetFunctionLength ( F, length )
The abstract operation SetFunctionLength requires a Function argument F and a Number argument length. This operation adds a length property to F by performing the following steps:
Assert : F is an extensible object that does not have alengthown property.Assert :Type (length) is Number.Assert : length ≥ 0 and !ToInteger (length) is equal to length.- Return !
DefinePropertyOrThrow (F,"length", PropertyDescriptor{[[Value]]: length, [[Writable]]:false , [[Enumerable]]:false , [[Configurable]]:true }).
9.2.15 FunctionDeclarationInstantiation ( func, argumentsList )
When an
FunctionDeclarationInstantiation is performed as follows using arguments func and argumentsList. func is the
- Let calleeContext be the
running execution context . - Let env be the LexicalEnvironment of calleeContext.
- Let envRec be env's
EnvironmentRecord . - Let code be func.[[ECMAScriptCode]].
- Let strict be func.[[Strict]].
- Let formals be func.[[FormalParameters]].
- Let parameterNames be the BoundNames of formals.
- If parameterNames has any duplicate entries, let hasDuplicates be
true . Otherwise, let hasDuplicates befalse . - Let simpleParameterList be IsSimpleParameterList of formals.
- Let hasParameterExpressions be ContainsExpression of formals.
- Let varNames be the VarDeclaredNames of code.
- Let varDeclarations be the VarScopedDeclarations of code.
- Let lexicalNames be the LexicallyDeclaredNames of code.
- Let functionNames be a new empty
List . - Let functionsToInitialize be a new empty
List . - For each d in varDeclarations, in reverse list order, do
- If d is neither a
VariableDeclaration nor aForBinding nor aBindingIdentifier , thenAssert : d is either aFunctionDeclaration , aGeneratorDeclaration , anAsyncFunctionDeclaration , or anAsyncGeneratorDeclaration .- Let fn be the sole element of the BoundNames of d.
- If fn is not an element of functionNames, then
- Insert fn as the first element of functionNames.
- NOTE: If there are multiple function declarations for the same name, the last declaration is used.
- Insert d as the first element of functionsToInitialize.
- If d is neither a
- Let argumentsObjectNeeded be
true . - If func.[[ThisMode]] is
lexical , then- NOTE: Arrow functions never have an arguments objects.
- Set argumentsObjectNeeded to
false .
- Else if
"arguments"is an element of parameterNames, then- Set argumentsObjectNeeded to
false .
- Set argumentsObjectNeeded to
- Else if hasParameterExpressions is
false , then- If
"arguments"is an element of functionNames or if"arguments"is an element of lexicalNames, then- Set argumentsObjectNeeded to
false .
- Set argumentsObjectNeeded to
- If
- For each String paramName in parameterNames, do
- Let alreadyDeclared be envRec.HasBinding(paramName).
- NOTE: Early errors ensure that duplicate parameter names can only occur in non-strict functions that do not have parameter default values or rest parameters.
- If alreadyDeclared is
false , then- Perform ! envRec.CreateMutableBinding(paramName,
false ). - If hasDuplicates is
true , then- Perform ! envRec.InitializeBinding(paramName,
undefined ).
- Perform ! envRec.InitializeBinding(paramName,
- Perform ! envRec.CreateMutableBinding(paramName,
- If argumentsObjectNeeded is
true , then- If strict is
true or if simpleParameterList isfalse , then- Let ao be
CreateUnmappedArgumentsObject (argumentsList).
- Let ao be
- Else,
- NOTE: mapped argument object is only provided for non-strict functions that don't have a rest parameter, any parameter default value initializers, or any destructured parameters.
- Let ao be
CreateMappedArgumentsObject (func, formals, argumentsList, envRec).
- If strict is
true , then- Perform ! envRec.CreateImmutableBinding(
"arguments",false ).
- Perform ! envRec.CreateImmutableBinding(
- Else,
- Perform ! envRec.CreateMutableBinding(
"arguments",false ).
- Perform ! envRec.CreateMutableBinding(
- Call envRec.InitializeBinding(
"arguments", ao). - Let parameterBindings be a new
List of parameterNames with"arguments"appended.
- If strict is
- Else,
- Let parameterBindings be parameterNames.
- Let iteratorRecord be
CreateListIteratorRecord (argumentsList). - If hasDuplicates is
true , then- Perform ? IteratorBindingInitialization for formals with iteratorRecord and
undefined as arguments.
- Perform ? IteratorBindingInitialization for formals with iteratorRecord and
- Else,
- Perform ? IteratorBindingInitialization for formals with iteratorRecord and env as arguments.
- If hasParameterExpressions is
false , then- NOTE: Only a single lexical environment is needed for the parameters and top-level vars.
- Let instantiatedVarNames be a copy of the
List parameterBindings. - For each n in varNames, do
- If n is not an element of instantiatedVarNames, then
- Append n to instantiatedVarNames.
- Perform ! envRec.CreateMutableBinding(n,
false ). - Call envRec.InitializeBinding(n,
undefined ).
- If n is not an element of instantiatedVarNames, then
- Let varEnv be env.
- Let varEnvRec be envRec.
- Else,
- NOTE: A separate
Environment Record is needed to ensure that closures created by expressions in the formal parameter list do not have visibility of declarations in the function body. - Let varEnv be
NewDeclarativeEnvironment (env). - Let varEnvRec be varEnv's
EnvironmentRecord . - Set the VariableEnvironment of calleeContext to varEnv.
- Let instantiatedVarNames be a new empty
List . - For each n in varNames, do
- If n is not an element of instantiatedVarNames, then
- Append n to instantiatedVarNames.
- Perform ! varEnvRec.CreateMutableBinding(n,
false ). - If n is not an element of parameterBindings or if n is an element of functionNames, let initialValue be
undefined . - Else,
- Let initialValue be ! envRec.GetBindingValue(n,
false ).
- Let initialValue be ! envRec.GetBindingValue(n,
- Call varEnvRec.InitializeBinding(n, initialValue).
- NOTE: vars whose names are the same as a formal parameter, initially have the same value as the corresponding initialized parameter.
- If n is not an element of instantiatedVarNames, then
- NOTE: A separate
- NOTE: Annex
B.3.3.1 adds additional steps at this point. - If strict is
false , then- Let lexEnv be
NewDeclarativeEnvironment (varEnv). - NOTE: Non-strict functions use a separate lexical
Environment Record for top-level lexical declarations so that adirect eval can determine whether any var scoped declarations introduced by the eval code conflict with pre-existing top-level lexically scoped declarations. This is not needed for strict functions because a strictdirect eval always places all declarations into a newEnvironment Record .
- Let lexEnv be
- Else, let lexEnv be varEnv.
- Let lexEnvRec be lexEnv's
EnvironmentRecord . - Set the LexicalEnvironment of calleeContext to lexEnv.
- Let lexDeclarations be the LexicallyScopedDeclarations of code.
- For each element d in lexDeclarations, do
- NOTE: A lexically declared name cannot be the same as a function/generator declaration, formal parameter, or a var name. Lexically declared names are only instantiated here but not initialized.
- For each element dn of the BoundNames of d, do
- If IsConstantDeclaration of d is
true , then- Perform ! lexEnvRec.CreateImmutableBinding(dn,
true ).
- Perform ! lexEnvRec.CreateImmutableBinding(dn,
- Else,
- Perform ! lexEnvRec.CreateMutableBinding(dn,
false ).
- Perform ! lexEnvRec.CreateMutableBinding(dn,
- If IsConstantDeclaration of d is
- For each
Parse Node f in functionsToInitialize, do- Let fn be the sole element of the BoundNames of f.
- Let fo be the result of performing InstantiateFunctionObject for f with argument lexEnv.
- Perform ! varEnvRec.SetMutableBinding(fn, fo,
false ).
- Return
NormalCompletion (empty ).
Parameter
9.3 Built-in Function Objects
The built-in function objects defined in this specification may be implemented as either ECMAScript function objects (
If a built-in
Unless otherwise specified every built-in
The behaviour specified for each built-in function via algorithm steps or other means is the specification of the function body behaviour for both [[Call]] and [[Construct]] invocations of the function. However, [[Construct]] invocation is not supported by all built-in functions. For each built-in function, when invoked with [[Call]], the [[Call]] thisArgument provides the "classConstructor".
Built-in function objects that are not identified as constructors do not implement the [[Construct]] internal method unless otherwise specified in the description of a particular function. When a built-in new expression the argumentsList parameter of the invoked [[Construct]] internal method provides the values for the built-in
Built-in functions that are not constructors do not have a prototype property unless otherwise specified in the description of a particular function.
If a built-in
9.3.1 [[Call]] ( thisArgument, argumentsList )
The [[Call]] internal method for a built-in
- Let callerContext be the
running execution context . - If callerContext is not already suspended, suspend callerContext.
- Let calleeContext be a new ECMAScript code
execution context . - Set the Function of calleeContext to F.
- Let calleeRealm be F.[[Realm]].
- Set the
Realm of calleeContext to calleeRealm. - Set the ScriptOrModule of calleeContext to F.[[ScriptOrModule]].
- Perform any necessary implementation-defined initialization of calleeContext.
- Push calleeContext onto the
execution context stack ; calleeContext is now therunning execution context . - Let result be the
Completion Record that is the result of evaluating F in an implementation-defined manner that conforms to the specification of F. thisArgument is thethis value, argumentsList provides the named parameters, and the NewTarget value isundefined . - Remove calleeContext from the
execution context stack and restore callerContext as therunning execution context . - Return result.
When calleeContext is removed from the
9.3.2 [[Construct]] ( argumentsList, newTarget )
The [[Construct]] internal method for built-in
- Let result be the
Completion Record that is the result of evaluating F in an implementation-defined manner that conforms to the specification of F. Thethis value is uninitialized, argumentsList provides the named parameters, and newTarget provides the NewTarget value.
9.3.3 CreateBuiltinFunction ( steps, internalSlotsList [ , realm [ , prototype ] ] )
The abstract operation CreateBuiltinFunction takes arguments steps, internalSlotsList, realm, and prototype. The argument internalSlotsList is a
Assert : steps is either a set of algorithm steps or other definition of a function's behaviour provided in this specification.- If realm is not present, set realm to
the current Realm Record . Assert : realm is aRealm Record .- If prototype is not present, set prototype to realm.[[Intrinsics]].[[
%FunctionPrototype% ]]. - Let func be a new built-in
function object that when called performs the action described by steps. The newfunction object has internal slots whose names are the elements of internalSlotsList. The initial value of each of those internal slots isundefined . - Set func.[[Realm]] to realm.
- Set func.[[Prototype]] to prototype.
- Set func.[[Extensible]] to
true . - Set func.[[ScriptOrModule]] to
null . - Return func.
Each built-in function defined in this specification is created by calling the CreateBuiltinFunction abstract operation.
9.4 Built-in Exotic Object Internal Methods and Slots
This specification defines several kinds of built-in exotic objects. These objects generally behave similar to ordinary objects except for a few specific situations. The following exotic objects use the ordinary object internal methods except where it is explicitly specified otherwise below:
9.4.1 Bound Function Exotic Objects
A bound function is an
Bound function objects do not have the internal slots of ECMAScript function objects defined in
| Internal Slot | Type | Description |
|---|---|---|
| [[BoundTargetFunction]] | Callable Object |
The wrapped |
| [[BoundThis]] | Any |
The value that is always passed as the |
| [[BoundArguments]] |
|
A list of values whose elements are used as the first arguments to any call to the wrapped function. |
Bound function objects provide all of the essential internal methods as specified in
9.4.1.1 [[Call]] ( thisArgument, argumentsList )
When the [[Call]] internal method of a
- Let target be F.[[BoundTargetFunction]].
- Let boundThis be F.[[BoundThis]].
- Let boundArgs be F.[[BoundArguments]].
- Let args be a new list containing the same values as the list boundArgs in the same order followed by the same values as the list argumentsList in the same order.
- Return ?
Call (target, boundThis, args).
9.4.1.2 [[Construct]] ( argumentsList, newTarget )
When the [[Construct]] internal method of a
- Let target be F.[[BoundTargetFunction]].
Assert :IsConstructor (target) istrue .- Let boundArgs be F.[[BoundArguments]].
- Let args be a new list containing the same values as the list boundArgs in the same order followed by the same values as the list argumentsList in the same order.
- If
SameValue (F, newTarget) istrue , set newTarget to target. - Return ?
Construct (target, args, newTarget).
9.4.1.3 BoundFunctionCreate ( targetFunction, boundThis, boundArgs )
The abstract operation BoundFunctionCreate with arguments targetFunction, boundThis and boundArgs is used to specify the creation of new Bound Function exotic objects. It performs the following steps:
Assert :Type (targetFunction) is Object.- Let proto be ? targetFunction.[[GetPrototypeOf]]().
- Let obj be a newly created object.
- Set obj's essential internal methods to the default ordinary object definitions specified in
9.1 . - Set obj.[[Call]] as described in
9.4.1.1 . - If
IsConstructor (targetFunction) istrue , then- Set obj.[[Construct]] as described in
9.4.1.2 .
- Set obj.[[Construct]] as described in
- Set obj.[[Prototype]] to proto.
- Set obj.[[Extensible]] to
true . - Set obj.[[BoundTargetFunction]] to targetFunction.
- Set obj.[[BoundThis]] to boundThis.
- Set obj.[[BoundArguments]] to boundArgs.
- Return obj.
9.4.2 Array Exotic Objects
An Array object is an length property whose value is always a nonnegative length property is numerically greater than the name of every own property whose name is an length property is changed, if necessary, to be one more than the numeric value of that length property is changed, every own property whose name is an length or
A String
Array exotic objects always have a non-configurable property named "length".
Array exotic objects provide an alternative definition for the [[DefineOwnProperty]] internal method. Except for that internal method, Array exotic objects provide all of the other essential internal methods as specified in
9.4.2.1 [[DefineOwnProperty]] ( P, Desc )
When the [[DefineOwnProperty]] internal method of an Array
Assert :IsPropertyKey (P) istrue .- If P is
"length", then- Return ?
ArraySetLength (A, Desc).
- Return ?
- Else if P is an
array index , then- Let oldLenDesc be
OrdinaryGetOwnProperty (A,"length"). Assert : oldLenDesc will never beundefined or an accessor descriptor because Array objects are created with a lengthdata property that cannot be deleted or reconfigured.- Let oldLen be oldLenDesc.[[Value]].
- Let index be !
ToUint32 (P). - If index ≥ oldLen and oldLenDesc.[[Writable]] is
false , returnfalse . - Let succeeded be !
OrdinaryDefineOwnProperty (A, P, Desc). - If succeeded is
false , returnfalse . - If index ≥ oldLen, then
- Set oldLenDesc.[[Value]] to index + 1.
- Let succeeded be
OrdinaryDefineOwnProperty (A,"length", oldLenDesc). Assert : succeeded istrue .
- Return
true .
- Let oldLenDesc be
- Return
OrdinaryDefineOwnProperty (A, P, Desc).
9.4.2.2 ArrayCreate ( length [ , proto ] )
The abstract operation ArrayCreate with argument length (either 0 or a positive
Assert : length is aninteger Number ≥ 0.- If length is
-0 , set length to+0 . - If length>232-1, throw a
RangeError exception. - If proto is not present, set proto to the intrinsic object
%ArrayPrototype% . - Let A be a newly created Array
exotic object . - Set A's essential internal methods except for [[DefineOwnProperty]] to the default ordinary object definitions specified in
9.1 . - Set A.[[DefineOwnProperty]] as specified in
9.4.2.1 . - Set A.[[Prototype]] to proto.
- Set A.[[Extensible]] to
true . - Perform !
OrdinaryDefineOwnProperty (A,"length", PropertyDescriptor{[[Value]]: length, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Return A.
9.4.2.3 ArraySpeciesCreate ( originalArray, length )
The abstract operation ArraySpeciesCreate with arguments originalArray and length is used to specify the creation of a new Array object using a
Assert : length is aninteger Number ≥ 0.- If length is
-0 , set length to+0 . - Let isArray be ?
IsArray (originalArray). - If isArray is
false , return ?ArrayCreate (length). - Let C be ?
Get (originalArray,"constructor"). - If
IsConstructor (C) istrue , then- Let thisRealm be
the current Realm Record . - Let realmC be ?
GetFunctionRealm (C). - If thisRealm and realmC are not the same
Realm Record , then
- Let thisRealm be
- If
Type (C) is Object, then- Set C to ?
Get (C, @@species). - If C is
null , set C toundefined .
- Set C to ?
- If C is
undefined , return ?ArrayCreate (length). - If
IsConstructor (C) isfalse , throw aTypeError exception. - Return ?
Construct (C, « length »).
If originalArray was created using the standard built-in Array
9.4.2.4 ArraySetLength ( A, Desc )
When the abstract operation ArraySetLength is called with an Array
- If Desc.[[Value]] is absent, then
- Return
OrdinaryDefineOwnProperty (A,"length", Desc).
- Return
- Let newLenDesc be a copy of Desc.
- Let newLen be ?
ToUint32 (Desc.[[Value]]). - Let numberLen be ?
ToNumber (Desc.[[Value]]). - If newLen ≠ numberLen, throw a
RangeError exception. - Set newLenDesc.[[Value]] to newLen.
- Let oldLenDesc be
OrdinaryGetOwnProperty (A,"length"). Assert : oldLenDesc will never beundefined or an accessor descriptor because Array objects are created with a lengthdata property that cannot be deleted or reconfigured.- Let oldLen be oldLenDesc.[[Value]].
- If newLen ≥ oldLen, then
- Return
OrdinaryDefineOwnProperty (A,"length", newLenDesc).
- Return
- If oldLenDesc.[[Writable]] is
false , returnfalse . - If newLenDesc.[[Writable]] is absent or has the value
true , let newWritable betrue . - Else,
- Need to defer setting the [[Writable]] attribute to
false in case any elements cannot be deleted. - Let newWritable be
false . - Set newLenDesc.[[Writable]] to
true .
- Need to defer setting the [[Writable]] attribute to
- Let succeeded be !
OrdinaryDefineOwnProperty (A,"length", newLenDesc). - If succeeded is
false , returnfalse . - Repeat, while newLen < oldLen,
- Set oldLen to oldLen - 1.
- Let deleteSucceeded be ! A.[[Delete]](!
ToString (oldLen)). - If deleteSucceeded is
false , then- Set newLenDesc.[[Value]] to oldLen + 1.
- If newWritable is
false , set newLenDesc.[[Writable]] tofalse . - Perform !
OrdinaryDefineOwnProperty (A,"length", newLenDesc). - Return
false .
- If newWritable is
false , then- Return
OrdinaryDefineOwnProperty (A,"length", PropertyDescriptor { [[Writable]]:false }). This call will always returntrue .
- Return
- Return
true .
In steps 3 and 4, if Desc.[[Value]] is an object then its valueOf method is called twice. This is legacy behaviour that was specified with this effect starting with the 2nd Edition of this specification.
9.4.3 String Exotic Objects
A String object is an "length" whose value is the number of code unit elements in the encapsulated String value. Both the code unit data properties and the "length" property are non-writable and non-configurable.
String exotic objects have the same internal slots as ordinary objects. They also have a [[StringData]] internal slot.
String exotic objects provide alternative definitions for the following internal methods. All of the other String
9.4.3.1 [[GetOwnProperty]] ( P )
When the [[GetOwnProperty]] internal method of a String
Assert :IsPropertyKey (P) istrue .- Let desc be
OrdinaryGetOwnProperty (S, P). - If desc is not
undefined , return desc. - Return !
StringGetOwnProperty (S, P).
9.4.3.2 [[DefineOwnProperty]] ( P, Desc )
When the [[DefineOwnProperty]] internal method of a String
Assert :IsPropertyKey (P) istrue .- Let stringDesc be !
StringGetOwnProperty (S, P). - If stringDesc is not
undefined , then- Let extensible be S.[[Extensible]].
- Return !
IsCompatiblePropertyDescriptor (extensible, Desc, stringDesc).
- Return !
OrdinaryDefineOwnProperty (S, P, Desc).
9.4.3.3 [[OwnPropertyKeys]] ( )
When the [[OwnPropertyKeys]] internal method of a String
- Let keys be a new empty
List . - Let str be the String value of O.[[StringData]].
- Let len be the length of str.
- For each
integer i starting with 0 such that i < len, in ascending order, do- Add !
ToString (i) as the last element of keys.
- Add !
- For each own property key P of O such that P is an
integer index andToInteger (P) ≥ len, in ascending numeric index order, do- Add P as the last element of keys.
- For each own property key P of O such that
Type (P) is String and P is not aninteger index , in ascending chronological order of property creation, do- Add P as the last element of keys.
- For each own property key P of O such that
Type (P) is Symbol, in ascending chronological order of property creation, do- Add P as the last element of keys.
- Return keys.
9.4.3.4 StringCreate ( value, prototype )
The abstract operation StringCreate with arguments value and prototype is used to specify the creation of new String exotic objects. It performs the following steps:
Assert :Type (value) is String.- Let S be a newly created String
exotic object . - Set S.[[StringData]] to value.
- Set S's essential internal methods to the default ordinary object definitions specified in
9.1 . - Set S.[[GetOwnProperty]] as specified in
9.4.3.1 . - Set S.[[DefineOwnProperty]] as specified in
9.4.3.2 . - Set S.[[OwnPropertyKeys]] as specified in
9.4.3.3 . - Set S.[[Prototype]] to prototype.
- Set S.[[Extensible]] to
true . - Let length be the number of code unit elements in value.
- Perform !
DefinePropertyOrThrow (S,"length", PropertyDescriptor { [[Value]]: length, [[Writable]]:false , [[Enumerable]]:false , [[Configurable]]:false }). - Return S.
9.4.3.5 StringGetOwnProperty ( S, P )
The abstract operation StringGetOwnProperty called with arguments S and P performs the following steps:
Assert : S is an Object that has a [[StringData]] internal slot.Assert :IsPropertyKey (P) istrue .- If
Type (P) is not String, returnundefined . - Let index be !
CanonicalNumericIndexString (P). - If index is
undefined , returnundefined . - If
IsInteger (index) isfalse , returnundefined . - If index =
-0 , returnundefined . - Let str be the String value of S.[[StringData]].
- Let len be the length of str.
- If index < 0 or len ≤ index, return
undefined . - Let resultStr be the String value of length 1, containing one code unit from str, specifically the code unit at index index.
- Return a PropertyDescriptor { [[Value]]: resultStr, [[Writable]]:
false , [[Enumerable]]:true , [[Configurable]]:false }.
9.4.4 Arguments Exotic Objects
Most ECMAScript functions make an arguments object available to their code. Depending upon the characteristics of the function definition, its arguments object is either an ordinary object or an arguments
Arguments exotic objects have the same internal slots as ordinary objects. They also have a [[ParameterMap]] internal slot. Ordinary arguments objects also have a [[ParameterMap]] internal slot whose value is always undefined. For ordinary argument objects the [[ParameterMap]] internal slot is only used by Object.prototype.toString (
Arguments exotic objects provide alternative definitions for the following internal methods. All of the other arguments
The
The ParameterMap object and its property values are used as a device for specifying the arguments object correspondence to argument bindings. The ParameterMap object and the objects that are the values of its properties are not directly observable from ECMAScript code. An ECMAScript implementation does not need to actually create or use such objects to implement the specified semantics.
Ordinary arguments objects define a non-configurable "callee" which throws a "callee" property has a more specific meaning for arguments exotic objects, which are created only for some class of non-strict functions. The definition of this property in the ordinary variant exists to ensure that it is not defined in any other manner by conforming ECMAScript implementations.
ECMAScript implementations of arguments exotic objects have historically contained an "caller". Prior to ECMAScript 2017, this specification included the definition of a throwing "caller" property on ordinary arguments objects. Since implementations do not contain this extension any longer, ECMAScript 2017 dropped the requirement for a throwing "caller" accessor.
9.4.4.1 [[GetOwnProperty]] ( P )
The [[GetOwnProperty]] internal method of an arguments
- Let args be the arguments object.
- Let desc be
OrdinaryGetOwnProperty (args, P). - If desc is
undefined , return desc. - Let map be args.[[ParameterMap]].
- Let isMapped be !
HasOwnProperty (map, P). - If isMapped is
true , then- Set desc.[[Value]] to
Get (map, P).
- Set desc.[[Value]] to
- Return desc.
9.4.4.2 [[DefineOwnProperty]] ( P, Desc )
The [[DefineOwnProperty]] internal method of an arguments
- Let args be the arguments object.
- Let map be args.[[ParameterMap]].
- Let isMapped be
HasOwnProperty (map, P). - Let newArgDesc be Desc.
- If isMapped is
true andIsDataDescriptor (Desc) istrue , then- If Desc.[[Value]] is not present and Desc.[[Writable]] is present and its value is
false , then- Set newArgDesc to a copy of Desc.
- Set newArgDesc.[[Value]] to
Get (map, P).
- If Desc.[[Value]] is not present and Desc.[[Writable]] is present and its value is
- Let allowed be ?
OrdinaryDefineOwnProperty (args, P, newArgDesc). - If allowed is
false , returnfalse . - If isMapped is
true , then- If
IsAccessorDescriptor (Desc) istrue , then- Call map.[[Delete]](P).
- Else,
- If
- Return
true .
9.4.4.3 [[Get]] ( P, Receiver )
The [[Get]] internal method of an arguments
- Let args be the arguments object.
- Let map be args.[[ParameterMap]].
- Let isMapped be !
HasOwnProperty (map, P). - If isMapped is
false , then- Return ?
OrdinaryGet (args, P, Receiver).
- Return ?
- Else map contains a formal parameter mapping for P,
- Return
Get (map, P).
- Return
9.4.4.4 [[Set]] ( P, V, Receiver )
The [[Set]] internal method of an arguments
- Let args be the arguments object.
- If
SameValue (args, Receiver) isfalse , then- Let isMapped be
false .
- Let isMapped be
- Else,
- Let map be args.[[ParameterMap]].
- Let isMapped be !
HasOwnProperty (map, P).
- If isMapped is
true , then - Return ?
OrdinarySet (args, P, V, Receiver).
9.4.4.5 [[Delete]] ( P )
The [[Delete]] internal method of an arguments
- Let args be the arguments object.
- Let map be args.[[ParameterMap]].
- Let isMapped be !
HasOwnProperty (map, P). - Let result be ?
OrdinaryDelete (args, P). - If result is
true and isMapped istrue , then- Call map.[[Delete]](P).
- Return result.
9.4.4.6 CreateUnmappedArgumentsObject ( argumentsList )
The abstract operation CreateUnmappedArgumentsObject called with an argument argumentsList performs the following steps:
- Let len be the number of elements in argumentsList.
- Let obj be
ObjectCreate (%ObjectPrototype% , « [[ParameterMap]] »). - Set obj.[[ParameterMap]] to
undefined . - Perform
DefinePropertyOrThrow (obj,"length", PropertyDescriptor { [[Value]]: len, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:true }). - Let index be 0.
- Repeat, while index < len,
- Let val be argumentsList[index].
- Perform
CreateDataProperty (obj, !ToString (index), val). - Let index be index + 1.
- Perform !
DefinePropertyOrThrow (obj, @@iterator, PropertyDescriptor { [[Value]]:%ArrayProto_values% , [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:true }). - Perform !
DefinePropertyOrThrow (obj,"callee", PropertyDescriptor { [[Get]]:%ThrowTypeError% , [[Set]]:%ThrowTypeError% , [[Enumerable]]:false , [[Configurable]]:false }). - Return obj.
9.4.4.7 CreateMappedArgumentsObject ( func, formals, argumentsList, env )
The abstract operation CreateMappedArgumentsObject is called with object func,
Assert : formals does not contain a rest parameter, any binding patterns, or any initializers. It may contain duplicate identifiers.- Let len be the number of elements in argumentsList.
- Let obj be a newly created arguments
exotic object with a [[ParameterMap]] internal slot. - Set obj.[[GetOwnProperty]] as specified in
9.4.4.1 . - Set obj.[[DefineOwnProperty]] as specified in
9.4.4.2 . - Set obj.[[Get]] as specified in
9.4.4.3 . - Set obj.[[Set]] as specified in
9.4.4.4 . - Set obj.[[Delete]] as specified in
9.4.4.5 . - Set the remainder of obj's essential internal methods to the default ordinary object definitions specified in
9.1 . - Set obj.[[Prototype]] to
%ObjectPrototype% . - Set obj.[[Extensible]] to
true . - Let map be
ObjectCreate (null ). - Set obj.[[ParameterMap]] to map.
- Let parameterNames be the BoundNames of formals.
- Let numberOfParameters be the number of elements in parameterNames.
- Let index be 0.
- Repeat, while index < len,
- Let val be argumentsList[index].
- Perform
CreateDataProperty (obj, !ToString (index), val). - Let index be index + 1.
- Perform
DefinePropertyOrThrow (obj,"length", PropertyDescriptor { [[Value]]: len, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:true }). - Let mappedNames be a new empty
List . - Let index be numberOfParameters - 1.
- Repeat, while index ≥ 0,
- Let name be parameterNames[index].
- If name is not an element of mappedNames, then
- Add name as an element of the list mappedNames.
- If index < len, then
- Let g be
MakeArgGetter (name, env). - Let p be
MakeArgSetter (name, env). - Perform map.[[DefineOwnProperty]](!
ToString (index), PropertyDescriptor { [[Set]]: p, [[Get]]: g, [[Enumerable]]:false , [[Configurable]]:true }).
- Let g be
- Let index be index - 1.
- Perform !
DefinePropertyOrThrow (obj, @@iterator, PropertyDescriptor { [[Value]]:%ArrayProto_values% , [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:true }). - Perform !
DefinePropertyOrThrow (obj,"callee", PropertyDescriptor { [[Value]]: func, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:true }). - Return obj.
9.4.4.7.1 MakeArgGetter ( name, env )
The abstract operation MakeArgGetter called with String name and
- Let steps be the steps of an ArgGetter function as specified below.
- Let getter be
CreateBuiltinFunction (steps, « [[Name]], [[Env]] »). - Set getter.[[Name]] to name.
- Set getter.[[Env]] to env.
- Return getter.
An ArgGetter function is an anonymous built-in function with [[Name]] and [[Env]] internal slots. When an ArgGetter function f that expects no arguments is called it performs the following steps:
- Let name be f.[[Name]].
- Let env be f.[[Env]].
- Return env.GetBindingValue(name,
false ).
ArgGetter functions are never directly accessible to ECMAScript code.
9.4.4.7.2 MakeArgSetter ( name, env )
The abstract operation MakeArgSetter called with String name and
- Let steps be the steps of an ArgSetter function as specified below.
- Let setter be
CreateBuiltinFunction (steps, « [[Name]], [[Env]] »). - Set setter.[[Name]] to name.
- Set setter.[[Env]] to env.
- Return setter.
An ArgSetter function is an anonymous built-in function with [[Name]] and [[Env]] internal slots. When an ArgSetter function f is called with argument value it performs the following steps:
- Let name be f.[[Name]].
- Let env be f.[[Env]].
- Return env.SetMutableBinding(name, value,
false ).
ArgSetter functions are never directly accessible to ECMAScript code.
9.4.5 Integer-Indexed Exotic Objects
An Integer-Indexed exotic object is an
9.4.5.1 [[GetOwnProperty]] ( P )
When the [[GetOwnProperty]] internal method of an
Assert :IsPropertyKey (P) istrue .Assert : O is an Object that has a [[ViewedArrayBuffer]] internal slot.- If
Type (P) is String, then- Let numericIndex be !
CanonicalNumericIndexString (P). - If numericIndex is not
undefined , then- Let value be ?
IntegerIndexedElementGet (O, numericIndex). - If value is
undefined , returnundefined . - Return a PropertyDescriptor { [[Value]]: value, [[Writable]]:
true , [[Enumerable]]:true , [[Configurable]]:false }.
- Let value be ?
- Let numericIndex be !
- Return
OrdinaryGetOwnProperty (O, P).
9.4.5.2 [[HasProperty]] ( P )
When the [[HasProperty]] internal method of an
Assert :IsPropertyKey (P) istrue .Assert : O is an Object that has a [[ViewedArrayBuffer]] internal slot.- If
Type (P) is String, then- Let numericIndex be !
CanonicalNumericIndexString (P). - If numericIndex is not
undefined , then- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - If
IsInteger (numericIndex) isfalse , returnfalse . - If numericIndex =
-0 , returnfalse . - If numericIndex < 0, return
false . - If numericIndex ≥ O.[[ArrayLength]], return
false . - Return
true .
- Let numericIndex be !
- Return ?
OrdinaryHasProperty (O, P).
9.4.5.3 [[DefineOwnProperty]] ( P, Desc )
When the [[DefineOwnProperty]] internal method of an
Assert :IsPropertyKey (P) istrue .Assert : O is an Object that has a [[ViewedArrayBuffer]] internal slot.- If
Type (P) is String, then- Let numericIndex be !
CanonicalNumericIndexString (P). - If numericIndex is not
undefined , then- If
IsInteger (numericIndex) isfalse , returnfalse . - If numericIndex =
-0 , returnfalse . - If numericIndex < 0, return
false . - Let length be O.[[ArrayLength]].
- If numericIndex ≥ length, return
false . - If
IsAccessorDescriptor (Desc) istrue , returnfalse . - If Desc has a [[Configurable]] field and if Desc.[[Configurable]] is
true , returnfalse . - If Desc has an [[Enumerable]] field and if Desc.[[Enumerable]] is
false , returnfalse . - If Desc has a [[Writable]] field and if Desc.[[Writable]] is
false , returnfalse . - If Desc has a [[Value]] field, then
- Let value be Desc.[[Value]].
- Return ?
IntegerIndexedElementSet (O, numericIndex, value).
- Return
true .
- If
- Let numericIndex be !
- Return !
OrdinaryDefineOwnProperty (O, P, Desc).
9.4.5.4 [[Get]] ( P, Receiver )
When the [[Get]] internal method of an
Assert :IsPropertyKey (P) istrue .- If
Type (P) is String, then- Let numericIndex be !
CanonicalNumericIndexString (P). - If numericIndex is not
undefined , then- Return ?
IntegerIndexedElementGet (O, numericIndex).
- Return ?
- Let numericIndex be !
- Return ?
OrdinaryGet (O, P, Receiver).
9.4.5.5 [[Set]] ( P, V, Receiver )
When the [[Set]] internal method of an
Assert :IsPropertyKey (P) istrue .- If
Type (P) is String, then- Let numericIndex be !
CanonicalNumericIndexString (P). - If numericIndex is not
undefined , then- Return ?
IntegerIndexedElementSet (O, numericIndex, V).
- Return ?
- Let numericIndex be !
- Return ?
OrdinarySet (O, P, V, Receiver).
9.4.5.6 [[OwnPropertyKeys]] ( )
When the [[OwnPropertyKeys]] internal method of an
- Let keys be a new empty
List . Assert : O is an Object that has [[ViewedArrayBuffer]], [[ArrayLength]], [[ByteOffset]], and [[TypedArrayName]] internal slots.- Let len be O.[[ArrayLength]].
- For each
integer i starting with 0 such that i < len, in ascending order, do- Add !
ToString (i) as the last element of keys.
- Add !
- For each own property key P of O such that
Type (P) is String and P is not aninteger index , in ascending chronological order of property creation, do- Add P as the last element of keys.
- For each own property key P of O such that
Type (P) is Symbol, in ascending chronological order of property creation, do- Add P as the last element of keys.
- Return keys.
9.4.5.7 IntegerIndexedObjectCreate ( prototype, internalSlotsList )
The abstract operation IntegerIndexedObjectCreate with arguments prototype and internalSlotsList is used to specify the creation of new
Assert : internalSlotsList contains the names [[ViewedArrayBuffer]], [[ArrayLength]], [[ByteOffset]], and [[TypedArrayName]].- Let A be a newly created object with an internal slot for each name in internalSlotsList.
- Set A's essential internal methods to the default ordinary object definitions specified in
9.1 . - Set A.[[GetOwnProperty]] as specified in
9.4.5.1 . - Set A.[[HasProperty]] as specified in
9.4.5.2 . - Set A.[[DefineOwnProperty]] as specified in
9.4.5.3 . - Set A.[[Get]] as specified in
9.4.5.4 . - Set A.[[Set]] as specified in
9.4.5.5 . - Set A.[[OwnPropertyKeys]] as specified in
9.4.5.6 . - Set A.[[Prototype]] to prototype.
- Set A.[[Extensible]] to
true . - Return A.
9.4.5.8 IntegerIndexedElementGet ( O, index )
The abstract operation IntegerIndexedElementGet with arguments O and index performs the following steps:
Assert :Type (index) is Number.Assert : O is an Object that has [[ViewedArrayBuffer]], [[ArrayLength]], [[ByteOffset]], and [[TypedArrayName]] internal slots.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - If
IsInteger (index) isfalse , returnundefined . - If index =
-0 , returnundefined . - Let length be O.[[ArrayLength]].
- If index < 0 or index ≥ length, return
undefined . - Let offset be O.[[ByteOffset]].
- Let arrayTypeName be the String value of O.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for arrayTypeName. - Let indexedPosition be (index × elementSize) + offset.
- Let elementType be the String value of the Element Type value in
Table 56 for arrayTypeName. - Return
GetValueFromBuffer (buffer, indexedPosition, elementType,true ,"Unordered").
9.4.5.9 IntegerIndexedElementSet ( O, index, value )
The abstract operation IntegerIndexedElementSet with arguments O, index, and value performs the following steps:
Assert :Type (index) is Number.Assert : O is an Object that has [[ViewedArrayBuffer]], [[ArrayLength]], [[ByteOffset]], and [[TypedArrayName]] internal slots.- Let numValue be ?
ToNumber (value). - Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - If
IsInteger (index) isfalse , returnfalse . - If index =
-0 , returnfalse . - Let length be O.[[ArrayLength]].
- If index < 0 or index ≥ length, return
false . - Let offset be O.[[ByteOffset]].
- Let arrayTypeName be the String value of O.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for arrayTypeName. - Let indexedPosition be (index × elementSize) + offset.
- Let elementType be the String value of the Element Type value in
Table 56 for arrayTypeName. - Perform
SetValueInBuffer (buffer, indexedPosition, elementType, numValue,true ,"Unordered"). - Return
true .
9.4.6 Module Namespace Exotic Objects
A module namespace object is an export * export items. Each String-valued own property key is the StringValue of the corresponding exported binding name. These are the only String-keyed properties of a module namespace
Module namespace objects have the internal slots defined in
| Internal Slot | Type | Description |
|---|---|---|
| [[Module]] |
|
The |
| [[Exports]] |
|
A Array.prototype.sort using |
| [[Prototype]] | Null |
This slot always contains the value |
Module namespace exotic objects provide alternative definitions for all of the internal methods except [[GetPrototypeOf]], which behaves as defined in
9.4.6.1 [[SetPrototypeOf]] ( V )
When the [[SetPrototypeOf]] internal method of a module namespace
- Return ?
SetImmutablePrototype (O, V).
9.4.6.2 [[IsExtensible]] ( )
When the [[IsExtensible]] internal method of a module namespace
- Return
false .
9.4.6.3 [[PreventExtensions]] ( )
When the [[PreventExtensions]] internal method of a module namespace
- Return
true .
9.4.6.4 [[GetOwnProperty]] ( P )
When the [[GetOwnProperty]] internal method of a module namespace
- If
Type (P) is Symbol, returnOrdinaryGetOwnProperty (O, P). - Let exports be O.[[Exports]].
- If P is not an element of exports, return
undefined . - Let value be ? O.[[Get]](P, O).
- Return PropertyDescriptor { [[Value]]: value, [[Writable]]:
true , [[Enumerable]]:true , [[Configurable]]:false }.
9.4.6.5 [[DefineOwnProperty]] ( P, Desc )
When the [[DefineOwnProperty]] internal method of a module namespace
- Return
false .
9.4.6.6 [[HasProperty]] ( P )
When the [[HasProperty]] internal method of a module namespace
- If
Type (P) is Symbol, returnOrdinaryHasProperty (O, P). - Let exports be O.[[Exports]].
- If P is an element of exports, return
true . - Return
false .
9.4.6.7 [[Get]] ( P, Receiver )
When the [[Get]] internal method of a module namespace
Assert :IsPropertyKey (P) istrue .- If
Type (P) is Symbol, then- Return ?
OrdinaryGet (O, P, Receiver).
- Return ?
- Let exports be O.[[Exports]].
- If P is not an element of exports, return
undefined . - Let m be O.[[Module]].
- Let binding be ! m.ResolveExport(P, « »).
Assert : binding is aResolvedBinding Record .- Let targetModule be binding.[[Module]].
Assert : targetModule is notundefined .- Let targetEnv be targetModule.[[Environment]].
- If targetEnv is
undefined , throw aReferenceError exception. - Let targetEnvRec be targetEnv's
EnvironmentRecord . - Return ? targetEnvRec.GetBindingValue(binding.[[BindingName]],
true ).
ResolveExport is idempotent and side-effect free. An implementation might choose to pre-compute or cache the ResolveExport results for the [[Exports]] of each module namespace
9.4.6.8 [[Set]] ( P, V, Receiver )
When the [[Set]] internal method of a module namespace
- Return
false .
9.4.6.9 [[Delete]] ( P )
When the [[Delete]] internal method of a module namespace
Assert :IsPropertyKey (P) istrue .- If
Type (P) is Symbol, then- Return ?
OrdinaryDelete (O, P).
- Return ?
- Let exports be O.[[Exports]].
- If P is an element of exports, return
false . - Return
true .
9.4.6.10 [[OwnPropertyKeys]] ( )
When the [[OwnPropertyKeys]] internal method of a module namespace
- Let exports be a copy of O.[[Exports]].
- Let symbolKeys be !
OrdinaryOwnPropertyKeys (O). - Append all the entries of symbolKeys to the end of exports.
- Return exports.
9.4.6.11 ModuleNamespaceCreate ( module, exports )
The abstract operation ModuleNamespaceCreate with arguments module, and exports is used to specify the creation of new module namespace exotic objects. It performs the following steps:
Assert : module is aModule Record .Assert : module.[[Namespace]] isundefined .Assert : exports is aList of String values.- Let M be a newly created object.
- Set M's essential internal methods to the definitions specified in
9.4.6 . - Set M.[[Module]] to module.
- Let sortedExports be a new
List containing the same values as the list exports where the values are ordered as if an Array of the same values had been sorted usingArray.prototype.sortusingundefined as comparefn. - Set M.[[Exports]] to sortedExports.
- Create own properties of M corresponding to the definitions in
26.3 . - Set module.[[Namespace]] to M.
- Return M.
9.4.7 Immutable Prototype Exotic Objects
An immutable prototype exotic object is an
Immutable prototype exotic objects have the same internal slots as ordinary objects. They are exotic only in the following internal methods. All other internal methods of immutable prototype exotic objects that are not explicitly defined below are instead defined as in ordinary objects.
9.4.7.1 [[SetPrototypeOf]] ( V )
When the [[SetPrototypeOf]] internal method of an
- Return ?
SetImmutablePrototype (O, V).
9.4.7.2 SetImmutablePrototype ( O, V )
When the SetImmutablePrototype abstract operation is called with arguments O and V, the following steps are taken:
9.5 Proxy Object Internal Methods and Internal Slots
A proxy object is an
| Internal Method | Handler Method |
|---|---|
| [[GetPrototypeOf]] |
getPrototypeOf
|
| [[SetPrototypeOf]] |
setPrototypeOf
|
| [[IsExtensible]] |
isExtensible
|
| [[PreventExtensions]] |
preventExtensions
|
| [[GetOwnProperty]] |
getOwnPropertyDescriptor
|
| [[DefineOwnProperty]] |
defineProperty
|
| [[HasProperty]] |
has
|
| [[Get]] |
get
|
| [[Set]] |
set
|
| [[Delete]] |
deleteProperty
|
| [[OwnPropertyKeys]] |
ownKeys
|
| [[Call]] |
apply
|
| [[Construct]] |
construct
|
When a handler method is called to provide the implementation of a proxy object internal method, the handler method is passed the proxy's target object as a parameter. A proxy's handler object does not necessarily have a method corresponding to every essential internal method. Invoking an internal method on the proxy results in the invocation of the corresponding internal method on the proxy's target object if the handler object does not have a method corresponding to the internal trap.
The [[ProxyHandler]] and [[ProxyTarget]] internal slots of a proxy object are always initialized when the object is created and typically may not be modified. Some proxy objects are created in a manner that permits them to be subsequently revoked. When a proxy is revoked, its [[ProxyHandler]] and [[ProxyTarget]] internal slots are set to
Because proxy objects permit the implementation of internal methods to be provided by arbitrary ECMAScript code, it is possible to define a proxy object whose handler methods violates the invariants defined in
In the following algorithm descriptions, assume O is an ECMAScript proxy object, P is a property key value, V is any
9.5.1 [[GetPrototypeOf]] ( )
When the [[GetPrototypeOf]] internal method of a Proxy
- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"getPrototypeOf"). - If trap is
undefined , then- Return ? target.[[GetPrototypeOf]]().
- Let handlerProto be ?
Call (trap, handler, « target »). - If
Type (handlerProto) is neither Object nor Null, throw aTypeError exception. - Let extensibleTarget be ?
IsExtensible (target). - If extensibleTarget is
true , return handlerProto. - Let targetProto be ? target.[[GetPrototypeOf]]().
- If
SameValue (handlerProto, targetProto) isfalse , throw aTypeError exception. - Return handlerProto.
[[GetPrototypeOf]] for proxy objects enforces the following invariants:
-
The result of [[GetPrototypeOf]] must be either an Object or
null . - If the target object is not extensible, [[GetPrototypeOf]] applied to the proxy object must return the same value as [[GetPrototypeOf]] applied to the proxy object's target object.
9.5.2 [[SetPrototypeOf]] ( V )
When the [[SetPrototypeOf]] internal method of a Proxy
Assert : EitherType (V) is Object orType (V) is Null.- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"setPrototypeOf"). - If trap is
undefined , then- Return ? target.[[SetPrototypeOf]](V).
- Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target, V »)). - If booleanTrapResult is
false , returnfalse . - Let extensibleTarget be ?
IsExtensible (target). - If extensibleTarget is
true , returntrue . - Let targetProto be ? target.[[GetPrototypeOf]]().
- If
SameValue (V, targetProto) isfalse , throw aTypeError exception. - Return
true .
[[SetPrototypeOf]] for proxy objects enforces the following invariants:
- The result of [[SetPrototypeOf]] is a Boolean value.
- If the target object is not extensible, the argument value must be the same as the result of [[GetPrototypeOf]] applied to target object.
9.5.3 [[IsExtensible]] ( )
When the [[IsExtensible]] internal method of a Proxy
- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"isExtensible"). - If trap is
undefined , then- Return ? target.[[IsExtensible]]().
- Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target »)). - Let targetResult be ? target.[[IsExtensible]]().
- If
SameValue (booleanTrapResult, targetResult) isfalse , throw aTypeError exception. - Return booleanTrapResult.
[[IsExtensible]] for proxy objects enforces the following invariants:
- The result of [[IsExtensible]] is a Boolean value.
- [[IsExtensible]] applied to the proxy object must return the same value as [[IsExtensible]] applied to the proxy object's target object with the same argument.
9.5.4 [[PreventExtensions]] ( )
When the [[PreventExtensions]] internal method of a Proxy
- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"preventExtensions"). - If trap is
undefined , then- Return ? target.[[PreventExtensions]]().
- Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target »)). - If booleanTrapResult is
true , then- Let targetIsExtensible be ? target.[[IsExtensible]]().
- If targetIsExtensible is
true , throw aTypeError exception.
- Return booleanTrapResult.
[[PreventExtensions]] for proxy objects enforces the following invariants:
- The result of [[PreventExtensions]] is a Boolean value.
-
[[PreventExtensions]] applied to the proxy object only returns
true if [[IsExtensible]] applied to the proxy object's target object isfalse .
9.5.5 [[GetOwnProperty]] ( P )
When the [[GetOwnProperty]] internal method of a Proxy
Assert :IsPropertyKey (P) istrue .- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"getOwnPropertyDescriptor"). - If trap is
undefined , then- Return ? target.[[GetOwnProperty]](P).
- Let trapResultObj be ?
Call (trap, handler, « target, P »). - If
Type (trapResultObj) is neither Object nor Undefined, throw aTypeError exception. - Let targetDesc be ? target.[[GetOwnProperty]](P).
- If trapResultObj is
undefined , then- If targetDesc is
undefined , returnundefined . - If targetDesc.[[Configurable]] is
false , throw aTypeError exception. - Let extensibleTarget be ?
IsExtensible (target). Assert :Type (extensibleTarget) is Boolean.- If extensibleTarget is
false , throw aTypeError exception. - Return
undefined .
- If targetDesc is
- Let extensibleTarget be ?
IsExtensible (target). - Let resultDesc be ?
ToPropertyDescriptor (trapResultObj). - Call
CompletePropertyDescriptor (resultDesc). - Let valid be
IsCompatiblePropertyDescriptor (extensibleTarget, resultDesc, targetDesc). - If valid is
false , throw aTypeError exception. - If resultDesc.[[Configurable]] is
false , then- If targetDesc is
undefined or targetDesc.[[Configurable]] istrue , then- Throw a
TypeError exception.
- Throw a
- If targetDesc is
- Return resultDesc.
[[GetOwnProperty]] for proxy objects enforces the following invariants:
-
The result of [[GetOwnProperty]] must be either an Object or
undefined . - A property cannot be reported as non-existent, if it exists as a non-configurable own property of the target object.
- A property cannot be reported as non-existent, if it exists as an own property of the target object and the target object is not extensible.
- A property cannot be reported as existent, if it does not exist as an own property of the target object and the target object is not extensible.
- A property cannot be reported as non-configurable, if it does not exist as an own property of the target object or if it exists as a configurable own property of the target object.
9.5.6 [[DefineOwnProperty]] ( P, Desc )
When the [[DefineOwnProperty]] internal method of a Proxy
Assert :IsPropertyKey (P) istrue .- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"defineProperty"). - If trap is
undefined , then- Return ? target.[[DefineOwnProperty]](P, Desc).
- Let descObj be
FromPropertyDescriptor (Desc). - Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target, P, descObj »)). - If booleanTrapResult is
false , returnfalse . - Let targetDesc be ? target.[[GetOwnProperty]](P).
- Let extensibleTarget be ?
IsExtensible (target). - If Desc has a [[Configurable]] field and if Desc.[[Configurable]] is
false , then- Let settingConfigFalse be
true .
- Let settingConfigFalse be
- Else, let settingConfigFalse be
false . - If targetDesc is
undefined , then- If extensibleTarget is
false , throw aTypeError exception. - If settingConfigFalse is
true , throw aTypeError exception.
- If extensibleTarget is
- Else targetDesc is not
undefined ,- If
IsCompatiblePropertyDescriptor (extensibleTarget, Desc, targetDesc) isfalse , throw aTypeError exception. - If settingConfigFalse is
true and targetDesc.[[Configurable]] istrue , throw aTypeError exception.
- If
- Return
true .
[[DefineOwnProperty]] for proxy objects enforces the following invariants:
- The result of [[DefineOwnProperty]] is a Boolean value.
- A property cannot be added, if the target object is not extensible.
- A property cannot be non-configurable, unless there exists a corresponding non-configurable own property of the target object.
-
If a property has a corresponding target object property then applying the
Property Descriptor of the property to the target object using [[DefineOwnProperty]] will not throw an exception.
9.5.7 [[HasProperty]] ( P )
When the [[HasProperty]] internal method of a Proxy
Assert :IsPropertyKey (P) istrue .- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"has"). - If trap is
undefined , then- Return ? target.[[HasProperty]](P).
- Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target, P »)). - If booleanTrapResult is
false , then- Let targetDesc be ? target.[[GetOwnProperty]](P).
- If targetDesc is not
undefined , then- If targetDesc.[[Configurable]] is
false , throw aTypeError exception. - Let extensibleTarget be ?
IsExtensible (target). - If extensibleTarget is
false , throw aTypeError exception.
- If targetDesc.[[Configurable]] is
- Return booleanTrapResult.
[[HasProperty]] for proxy objects enforces the following invariants:
- The result of [[HasProperty]] is a Boolean value.
- A property cannot be reported as non-existent, if it exists as a non-configurable own property of the target object.
- A property cannot be reported as non-existent, if it exists as an own property of the target object and the target object is not extensible.
9.5.8 [[Get]] ( P, Receiver )
When the [[Get]] internal method of a Proxy
Assert :IsPropertyKey (P) istrue .- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"get"). - If trap is
undefined , then- Return ? target.[[Get]](P, Receiver).
- Let trapResult be ?
Call (trap, handler, « target, P, Receiver »). - Let targetDesc be ? target.[[GetOwnProperty]](P).
- If targetDesc is not
undefined and targetDesc.[[Configurable]] isfalse , then- If
IsDataDescriptor (targetDesc) istrue and targetDesc.[[Writable]] isfalse , then- If
SameValue (trapResult, targetDesc.[[Value]]) isfalse , throw aTypeError exception.
- If
- If
IsAccessorDescriptor (targetDesc) istrue and targetDesc.[[Get]] isundefined , then- If trapResult is not
undefined , throw aTypeError exception.
- If trapResult is not
- If
- Return trapResult.
[[Get]] for proxy objects enforces the following invariants:
-
The value reported for a property must be the same as the value of the corresponding target object property if the target object property is a non-writable, non-configurable own
data property . -
The value reported for a property must be
undefined if the corresponding target object property is a non-configurable ownaccessor property that hasundefined as its [[Get]] attribute.
9.5.9 [[Set]] ( P, V, Receiver )
When the [[Set]] internal method of a Proxy
Assert :IsPropertyKey (P) istrue .- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"set"). - If trap is
undefined , then- Return ? target.[[Set]](P, V, Receiver).
- Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target, P, V, Receiver »)). - If booleanTrapResult is
false , returnfalse . - Let targetDesc be ? target.[[GetOwnProperty]](P).
- If targetDesc is not
undefined and targetDesc.[[Configurable]] isfalse , then- If
IsDataDescriptor (targetDesc) istrue and targetDesc.[[Writable]] isfalse , then- If
SameValue (V, targetDesc.[[Value]]) isfalse , throw aTypeError exception.
- If
- If
IsAccessorDescriptor (targetDesc) istrue , then- If targetDesc.[[Set]] is
undefined , throw aTypeError exception.
- If targetDesc.[[Set]] is
- If
- Return
true .
[[Set]] for proxy objects enforces the following invariants:
- The result of [[Set]] is a Boolean value.
-
Cannot change the value of a property to be different from the value of the corresponding target object property if the corresponding target object property is a non-writable, non-configurable own
data property . -
Cannot set the value of a property if the corresponding target object property is a non-configurable own
accessor property that hasundefined as its [[Set]] attribute.
9.5.10 [[Delete]] ( P )
When the [[Delete]] internal method of a Proxy
Assert :IsPropertyKey (P) istrue .- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"deleteProperty"). - If trap is
undefined , then- Return ? target.[[Delete]](P).
- Let booleanTrapResult be
ToBoolean (?Call (trap, handler, « target, P »)). - If booleanTrapResult is
false , returnfalse . - Let targetDesc be ? target.[[GetOwnProperty]](P).
- If targetDesc is
undefined , returntrue . - If targetDesc.[[Configurable]] is
false , throw aTypeError exception. - Return
true .
[[Delete]] for proxy objects enforces the following invariants:
- The result of [[Delete]] is a Boolean value.
- A property cannot be reported as deleted, if it exists as a non-configurable own property of the target object.
9.5.11 [[OwnPropertyKeys]] ( )
When the [[OwnPropertyKeys]] internal method of a Proxy
- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"ownKeys"). - If trap is
undefined , then- Return ? target.[[OwnPropertyKeys]]().
- Let trapResultArray be ?
Call (trap, handler, « target »). - Let trapResult be ?
CreateListFromArrayLike (trapResultArray, « String, Symbol »). - If trapResult contains any duplicate entries, throw a
TypeError exception. - Let extensibleTarget be ?
IsExtensible (target). - Let targetKeys be ? target.[[OwnPropertyKeys]]().
Assert : targetKeys is aList containing only String and Symbol values.Assert : targetKeys contains no duplicate entries.- Let targetConfigurableKeys be a new empty
List . - Let targetNonconfigurableKeys be a new empty
List . - For each element key of targetKeys, do
- Let desc be ? target.[[GetOwnProperty]](key).
- If desc is not
undefined and desc.[[Configurable]] isfalse , then- Append key as an element of targetNonconfigurableKeys.
- Else,
- Append key as an element of targetConfigurableKeys.
- If extensibleTarget is
true and targetNonconfigurableKeys is empty, then- Return trapResult.
- Let uncheckedResultKeys be a new
List which is a copy of trapResult. - For each key that is an element of targetNonconfigurableKeys, do
- If key is not an element of uncheckedResultKeys, throw a
TypeError exception. - Remove key from uncheckedResultKeys.
- If key is not an element of uncheckedResultKeys, throw a
- If extensibleTarget is
true , return trapResult. - For each key that is an element of targetConfigurableKeys, do
- If key is not an element of uncheckedResultKeys, throw a
TypeError exception. - Remove key from uncheckedResultKeys.
- If key is not an element of uncheckedResultKeys, throw a
- If uncheckedResultKeys is not empty, throw a
TypeError exception. - Return trapResult.
[[OwnPropertyKeys]] for proxy objects enforces the following invariants:
-
The result of [[OwnPropertyKeys]] is a
List . -
The returned
List contains no duplicate entries. -
The Type of each result
List element is either String or Symbol. -
The result
List must contain the keys of all non-configurable own properties of the target object. -
If the target object is not extensible, then the result
List must contain all the keys of the own properties of the target object and no other values.
9.5.12 [[Call]] ( thisArgument, argumentsList )
The [[Call]] internal method of a Proxy
- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"apply"). - If trap is
undefined , then- Return ?
Call (target, thisArgument, argumentsList).
- Return ?
- Let argArray be
CreateArrayFromList (argumentsList). - Return ?
Call (trap, handler, « target, thisArgument, argArray »).
A Proxy
9.5.13 [[Construct]] ( argumentsList, newTarget )
The [[Construct]] internal method of a Proxy
- Let handler be O.[[ProxyHandler]].
- If handler is
null , throw aTypeError exception. Assert :Type (handler) is Object.- Let target be O.[[ProxyTarget]].
- Let trap be ?
GetMethod (handler,"construct"). - If trap is
undefined , thenAssert :IsConstructor (target) istrue .- Return ?
Construct (target, argumentsList, newTarget).
- Let argArray be
CreateArrayFromList (argumentsList). - Let newObj be ?
Call (trap, handler, « target, argArray, newTarget »). - If
Type (newObj) is not Object, throw aTypeError exception. - Return newObj.
A Proxy
[[Construct]] for proxy objects enforces the following invariants:
- The result of [[Construct]] must be an Object.
9.5.14 ProxyCreate ( target, handler )
The abstract operation ProxyCreate with arguments target and handler is used to specify the creation of new Proxy exotic objects. It performs the following steps:
- If
Type (target) is not Object, throw aTypeError exception. - If target is a Proxy
exotic object and target.[[ProxyHandler]] isnull , throw aTypeError exception. - If
Type (handler) is not Object, throw aTypeError exception. - If handler is a Proxy
exotic object and handler.[[ProxyHandler]] isnull , throw aTypeError exception. - Let P be a newly created object.
- Set P's essential internal methods (except for [[Call]] and [[Construct]]) to the definitions specified in
9.5 . - If
IsCallable (target) istrue , then- Set P.[[Call]] as specified in
9.5.12 . - If
IsConstructor (target) istrue , then- Set P.[[Construct]] as specified in
9.5.13 .
- Set P.[[Construct]] as specified in
- Set P.[[Call]] as specified in
- Set P.[[ProxyTarget]] to target.
- Set P.[[ProxyHandler]] to handler.
- Return P.
10 ECMAScript Language: Source Code
10.1 Source Text
Syntax
ECMAScript code is expressed using Unicode. ECMAScript source text is a sequence of code points. All Unicode code point values from U+0000 to U+10FFFF, including surrogate code points, may occur in source text where permitted by the ECMAScript grammars. The actual encodings used to store and interchange ECMAScript source text is not relevant to this specification. Regardless of the external source text encoding, a conforming ECMAScript implementation processes the source text as if it was an equivalent sequence of
The components of a combining character sequence are treated as individual Unicode code points even though a user might think of the whole sequence as a single character.
In string literals, regular expression literals, template literals and identifiers, any Unicode code point may also be expressed using Unicode escape sequences that explicitly express a code point's numeric value. Within a comment, such an escape sequence is effectively ignored as part of the comment.
ECMAScript differs from the Java programming language in the behaviour of Unicode escape sequences. In a Java program, if the Unicode escape sequence \u000A, for example, occurs within a single-line comment, it is interpreted as a line terminator (Unicode code point U+000A is LINE FEED (LF)) and therefore the next code point is not part of the comment. Similarly, if the Unicode escape sequence \u000A occurs within a string literal in a Java program, it is likewise interpreted as a line terminator, which is not allowed within a string literal—one must write \n instead of \u000A to cause a LINE FEED (LF) to be part of the String value of a string literal. In an ECMAScript program, a Unicode escape sequence occurring within a comment is never interpreted and therefore cannot contribute to termination of the comment. Similarly, a Unicode escape sequence occurring within a string literal in an ECMAScript program always contributes to the literal and is never interpreted as a line terminator or as a code point that might terminate the string literal.
10.1.1 Static Semantics: UTF16Encoding ( cp )
The UTF16Encoding of a numeric code point value, cp, is determined as follows:
10.1.2 Static Semantics: UTF16Decode ( lead, trail )
Two code units, lead and trail, that form a UTF-16
10.2 Types of Source Code
There are four types of ECMAScript code:
-
Global code is source text that is treated as an ECMAScript
Script . The global code of a particularScript does not include any source text that is parsed as part of aFunctionDeclaration ,FunctionExpression ,GeneratorDeclaration ,GeneratorExpression ,AsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration ,AsyncGeneratorExpression ,MethodDefinition ,ArrowFunction ,AsyncArrowFunction ,ClassDeclaration , orClassExpression . -
Eval code is the source text supplied to the built-in
evalfunction. More precisely, if the parameter to the built-inevalfunction is a String, it is treated as an ECMAScriptScript . The eval code for a particular invocation ofevalis the global code portion of thatScript . -
Function code is source text that is parsed to supply the value of the [[ECMAScriptCode]] and [[FormalParameters]] internal slots (see
9.2 ) of an ECMAScriptfunction object . The function code of a particular ECMAScript function does not include any source text that is parsed as the function code of a nestedFunctionDeclaration ,FunctionExpression ,GeneratorDeclaration ,GeneratorExpression ,AsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration ,AsyncGeneratorExpression ,MethodDefinition ,ArrowFunction ,AsyncArrowFunction ,ClassDeclaration , orClassExpression . -
Module code is source text that is code that is provided as a
ModuleBody . It is the code that is directly evaluated when a module is initialized. The module code of a particular module does not include any source text that is parsed as part of a nestedFunctionDeclaration ,FunctionExpression ,GeneratorDeclaration ,GeneratorExpression ,AsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration ,AsyncGeneratorExpression ,MethodDefinition ,ArrowFunction ,AsyncArrowFunction ,ClassDeclaration , orClassExpression .
Function code is generally provided as the bodies of Function Definitions (Function GeneratorFunction AsyncFunction
10.2.1 Strict Mode Code
An ECMAScript
-
Global code is strict mode code if it begins with a
Directive Prologue that contains aUse Strict Directive . - Module code is always strict mode code.
-
All parts of a
ClassDeclaration or aClassExpression are strict mode code. -
Eval code is strict mode code if it begins with a
Directive Prologue that contains aUse Strict Directive or if the call toevalis adirect eval that is contained in strict mode code. -
Function code is strict mode code if the associated
FunctionDeclaration ,FunctionExpression ,GeneratorDeclaration ,GeneratorExpression ,AsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration ,AsyncGeneratorExpression ,MethodDefinition ,ArrowFunction , orAsyncArrowFunction is contained in strict mode code or if the code that produces the value of the function's [[ECMAScriptCode]] internal slot begins with aDirective Prologue that contains aUse Strict Directive . -
Function code that is supplied as the arguments to the built-in
Function,Generator,AsyncFunction, andAsyncGeneratorconstructors is strict mode code if the last argument is a String that when processed is aFunctionBody that begins with aDirective Prologue that contains aUse Strict Directive .
ECMAScript code that is not strict mode code is called non-strict code.
10.2.2 Non-ECMAScript Functions
An ECMAScript implementation may support the evaluation of function exotic objects whose evaluative behaviour is expressed in some implementation-defined form of executable code other than via ECMAScript code. Whether a
11 ECMAScript Language: Lexical Grammar
The source text of an ECMAScript
There are several situations where the identification of lexical input elements is sensitive to the syntactic grammar context that is consuming the input elements. This requires multiple goal symbols for the lexical grammar. The
The use of multiple lexical goals ensures that there are no lexical ambiguities that would affect automatic semicolon insertion. For example, there are no syntactic grammar contexts where both a leading division or division-assignment, and a leading
a = b
/hi/g.exec(c).map(d);where the first non-whitespace, non-comment code point after a
a = b / hi / g.exec(c).map(d);Syntax
11.1 Unicode Format-Control Characters
The Unicode format-control characters (i.e., the characters in category “Cf” in the Unicode Character Database such as LEFT-TO-RIGHT MARK or RIGHT-TO-LEFT MARK) are control codes used to control the formatting of a range of text in the absence of higher-level protocols for this (such as mark-up languages).
It is useful to allow format-control characters in source text to facilitate editing and display. All format control characters may be used within comments, and within string literals, template literals, and regular expression literals.
U+200C (ZERO WIDTH NON-JOINER) and U+200D (ZERO WIDTH JOINER) are format-control characters that are used to make necessary distinctions when forming words or phrases in certain languages. In ECMAScript source text these code points may also be used in an
U+FEFF (ZERO WIDTH NO-BREAK SPACE) is a format-control character used primarily at the start of a text to mark it as Unicode and to allow detection of the text's encoding and byte order. <ZWNBSP> characters intended for this purpose can sometimes also appear after the start of a text, for example as a result of concatenating files. In ECMAScript source text <ZWNBSP> code points are treated as white space characters (see
The special treatment of certain format-control characters outside of comments, string literals, and regular expression literals is summarized in
| Code Point | Name | Abbreviation | Usage |
|---|---|---|---|
U+200C
|
ZERO WIDTH NON-JOINER | <ZWNJ> |
|
U+200D
|
ZERO WIDTH JOINER | <ZWJ> |
|
U+FEFF
|
ZERO WIDTH NO-BREAK SPACE | <ZWNBSP> |
|
11.2 White Space
White space code points are used to improve source text readability and to separate tokens (indivisible lexical units) from each other, but are otherwise insignificant. White space code points may occur between any two tokens and at the start or end of input. White space code points may occur within a
The ECMAScript white space code points are listed in
| Code Point | Name | Abbreviation |
|---|---|---|
U+0009
|
CHARACTER TABULATION | <TAB> |
U+000B
|
LINE TABULATION | <VT> |
U+000C
|
FORM FEED (FF) | <FF> |
U+0020
|
SPACE | <SP> |
U+00A0
|
NO-BREAK SPACE | <NBSP> |
U+FEFF
|
ZERO WIDTH NO-BREAK SPACE | <ZWNBSP> |
| Other category “Zs” | Any other Unicode “Space_Separator” code point | <USP> |
ECMAScript implementations must recognize as
Other than for the code points listed in
Syntax
11.3 Line Terminators
Like white space code points, line terminator code points are used to improve source text readability and to separate tokens (indivisible lexical units) from each other. However, unlike white space code points, line terminators have some influence over the behaviour of the syntactic grammar. In general, line terminators may occur between any two tokens, but there are a few places where they are forbidden by the syntactic grammar. Line terminators also affect the process of automatic semicolon insertion (
A line terminator can occur within a
Line terminators are included in the set of white space code points that are matched by the \s class in regular expressions.
The ECMAScript line terminator code points are listed in
| Code Point | Unicode Name | Abbreviation |
|---|---|---|
U+000A
|
LINE FEED (LF) | <LF> |
U+000D
|
CARRIAGE RETURN (CR) | <CR> |
U+2028
|
LINE SEPARATOR | <LS> |
U+2029
|
PARAGRAPH SEPARATOR | <PS> |
Only the Unicode code points in
Syntax
11.4 Comments
Comments can be either single or multi-line. Multi-line comments cannot nest.
Because a single-line comment can contain any Unicode code point except a // marker to the end of the line. However, the
Comments behave like white space and are discarded except that, if a
Syntax
11.5 Tokens
Syntax
The
11.6 Names and Keywords
This standard specifies specific code point additions: U+0024 (DOLLAR SIGN) and U+005F (LOW LINE) are permitted anywhere in an
Unicode escape sequences are permitted in an \ preceding the u and { } code units, if they appear, do not contribute code points to the \
Two
Syntax
The definitions of the nonterminal
The nonterminal _ via
The sets of code points with Unicode properties “ID_Start” and “ID_Continue” include, respectively, the code points with Unicode properties “Other_ID_Start” and “Other_ID_Continue”.
11.6.1 Identifier Names
11.6.1.1 Static Semantics: Early Errors
-
It is a Syntax Error if SV(
UnicodeEscapeSequence ) is none of"$", or"_", or theUTF16Encoding of a code point matched by theUnicodeIDStart lexical grammar production.
-
It is a Syntax Error if SV(
UnicodeEscapeSequence ) is none of"$", or"_", or theUTF16Encoding of either <ZWNJ> or <ZWJ>, or theUTF16Encoding of a Unicode code point that would be matched by theUnicodeIDContinue lexical grammar production.
11.6.1.2 Static Semantics: StringValue
- Return the String value consisting of the sequence of code units corresponding to
IdentifierName . In determining the sequence any occurrences of\UnicodeEscapeSequence are first replaced with the code point represented by theUnicodeEscapeSequence and then the code points of the entireIdentifierName are converted to code units byUTF16Encoding each code point.
11.6.2 Reserved Words
A
Syntax
The \
11.6.2.1 Keywords
The following tokens are ECMAScript keywords and may not be used as
Syntax
In some contexts yield and await are given the semantics of an let and static are treated as reserved words through static semantic restrictions (see
11.6.2.2 Future Reserved Words
The following tokens are reserved for use as keywords in future language extensions.
Syntax
Use of the following tokens within
implements
|
package
|
protected
|
|
interface
|
private
|
public
|
11.7 Punctuators
Syntax
11.8 Literals
11.8.1 Null Literals
Syntax
11.8.2 Boolean Literals
Syntax
11.8.3 Numeric Literals
Syntax
The
For example: 3in is an error and not the two input elements 3 and in.
A conforming implementation, when processing
11.8.3.1 Static Semantics: MV
A numeric literal stands for a value of the Number type. This value is determined in two steps: first, a
-
The MV of
NumericLiteral :: DecimalLiteral DecimalLiteral . -
The MV of
NumericLiteral :: BinaryIntegerLiteral BinaryIntegerLiteral . -
The MV of
NumericLiteral :: OctalIntegerLiteral OctalIntegerLiteral . -
The MV of
NumericLiteral :: HexIntegerLiteral HexIntegerLiteral . -
The MV of
DecimalLiteral :: DecimalIntegerLiteral . DecimalIntegerLiteral . -
The MV of
DecimalLiteral :: DecimalIntegerLiteral . DecimalDigits DecimalIntegerLiteral plus (the MV ofDecimalDigits × 10-n), where n is the number of code points inDecimalDigits . -
The MV of
DecimalLiteral :: DecimalIntegerLiteral . ExponentPart DecimalIntegerLiteral × 10e, where e is the MV ofExponentPart . -
The MV of
DecimalLiteral :: DecimalIntegerLiteral . DecimalDigits ExponentPart DecimalIntegerLiteral plus (the MV ofDecimalDigits × 10-n)) × 10e, where n is the number of code points inDecimalDigits and e is the MV ofExponentPart . -
The MV of
DecimalLiteral :: . DecimalDigits DecimalDigits × 10-n, where n is the number of code points inDecimalDigits . -
The MV of
DecimalLiteral :: . DecimalDigits ExponentPart DecimalDigits × 10e-n, where n is the number of code points inDecimalDigits and e is the MV ofExponentPart . -
The MV of
DecimalLiteral :: DecimalIntegerLiteral DecimalIntegerLiteral . -
The MV of
DecimalLiteral :: DecimalIntegerLiteral ExponentPart DecimalIntegerLiteral × 10e, where e is the MV ofExponentPart . -
The MV of
DecimalIntegerLiteral :: 0 -
The MV of
DecimalIntegerLiteral :: NonZeroDigit NonZeroDigit . -
The MV of
DecimalIntegerLiteral :: NonZeroDigit DecimalDigits NonZeroDigit × 10n) plus the MV ofDecimalDigits , where n is the number of code points inDecimalDigits . -
The MV of
DecimalDigits :: DecimalDigit DecimalDigit . -
The MV of
DecimalDigits :: DecimalDigits DecimalDigit DecimalDigits × 10) plus the MV ofDecimalDigit . -
The MV of
ExponentPart :: ExponentIndicator SignedInteger SignedInteger . -
The MV of
SignedInteger :: DecimalDigits DecimalDigits . -
The MV of
SignedInteger :: + DecimalDigits DecimalDigits . -
The MV of
SignedInteger :: - DecimalDigits DecimalDigits . -
The MV of
DecimalDigit :: 0 HexDigit :: 0 OctalDigit :: 0 BinaryDigit :: 0 -
The MV of
DecimalDigit :: 1 NonZeroDigit :: 1 HexDigit :: 1 OctalDigit :: 1 BinaryDigit :: 1 -
The MV of
DecimalDigit :: 2 NonZeroDigit :: 2 HexDigit :: 2 OctalDigit :: 2 -
The MV of
DecimalDigit :: 3 NonZeroDigit :: 3 HexDigit :: 3 OctalDigit :: 3 -
The MV of
DecimalDigit :: 4 NonZeroDigit :: 4 HexDigit :: 4 OctalDigit :: 4 -
The MV of
DecimalDigit :: 5 NonZeroDigit :: 5 HexDigit :: 5 OctalDigit :: 5 -
The MV of
DecimalDigit :: 6 NonZeroDigit :: 6 HexDigit :: 6 OctalDigit :: 6 -
The MV of
DecimalDigit :: 7 NonZeroDigit :: 7 HexDigit :: 7 OctalDigit :: 7 -
The MV of
DecimalDigit :: 8 NonZeroDigit :: 8 HexDigit :: 8 -
The MV of
DecimalDigit :: 9 NonZeroDigit :: 9 HexDigit :: 9 -
The MV of
HexDigit :: a HexDigit :: A -
The MV of
HexDigit :: b HexDigit :: B -
The MV of
HexDigit :: c HexDigit :: C -
The MV of
HexDigit :: d HexDigit :: D -
The MV of
HexDigit :: e HexDigit :: E -
The MV of
HexDigit :: f HexDigit :: F -
The MV of
BinaryIntegerLiteral :: 0b BinaryDigits BinaryDigits . -
The MV of
BinaryIntegerLiteral :: 0B BinaryDigits BinaryDigits . -
The MV of
BinaryDigits :: BinaryDigit BinaryDigit . -
The MV of
BinaryDigits :: BinaryDigits BinaryDigit BinaryDigits × 2) plus the MV ofBinaryDigit . -
The MV of
OctalIntegerLiteral :: 0o OctalDigits OctalDigits . -
The MV of
OctalIntegerLiteral :: 0O OctalDigits OctalDigits . -
The MV of
OctalDigits :: OctalDigit OctalDigit . -
The MV of
OctalDigits :: OctalDigits OctalDigit OctalDigits × 8) plus the MV ofOctalDigit . -
The MV of
HexIntegerLiteral :: 0x HexDigits HexDigits . -
The MV of
HexIntegerLiteral :: 0X HexDigits HexDigits . -
The MV of
HexDigits :: HexDigit HexDigit . -
The MV of
HexDigits :: HexDigits HexDigit HexDigits × 16) plus the MV ofHexDigit .
Once the exact MV for a numeric literal has been determined, it is then rounded to a value of the Number type. If the MV is 0, then the rounded value is 0 digit or the 0 digit and then incrementing the literal at the 20th significant digit position. A digit is significant if it is not part of an
-
it is not
0; or -
there is a nonzero digit to its left and there is a nonzero digit, not in the
ExponentPart , to its right.
11.8.4 String Literals
A string literal is zero or more Unicode code points enclosed in single or double quotes. Unicode code points may also be represented by an escape sequence. All code points may appear literally in a string literal except for the closing quote code points, U+005C (REVERSE SOLIDUS), U+000D (CARRIAGE RETURN), U+2028 (LINE SEPARATOR), U+2029 (PARAGRAPH SEPARATOR), and U+000A (LINE FEED). Any code points may appear in the form of an escape sequence. String literals evaluate to ECMAScript String values. When generating these String values Unicode code points are UTF-16 encoded as defined in
Syntax
A conforming implementation, when processing
The definition of the nonterminal
A line terminator code point cannot appear in a string literal, except as part of a \n or \u000A.
11.8.4.1 Static Semantics: StringValue
- Return the String value whose elements are the SV of this
StringLiteral .
11.8.4.2 Static Semantics: SV
A string literal stands for a value of the String type. The String value (SV) of the literal is described in terms of code unit values contributed by the various parts of the string literal. As part of this process, some Unicode code points within the string literal are interpreted as having a
-
The SV of
StringLiteral :: " " -
The SV of
StringLiteral :: ' ' -
The SV of
StringLiteral :: " DoubleStringCharacters " DoubleStringCharacters . -
The SV of
StringLiteral :: ' SingleStringCharacters ' SingleStringCharacters . -
The SV of
DoubleStringCharacters :: DoubleStringCharacter DoubleStringCharacter . -
The SV of
DoubleStringCharacters :: DoubleStringCharacter DoubleStringCharacters DoubleStringCharacter followed by the code units of the SV ofDoubleStringCharacters in order. -
The SV of
SingleStringCharacters :: SingleStringCharacter SingleStringCharacter . -
The SV of
SingleStringCharacters :: SingleStringCharacter SingleStringCharacters SingleStringCharacter followed by the code units of the SV ofSingleStringCharacters in order. -
The SV of
DoubleStringCharacter :: SourceCharacter but not one of " or\ orLineTerminator UTF16Encoding of the code point value ofSourceCharacter . -
The SV of
DoubleStringCharacter :: \ EscapeSequence EscapeSequence . -
The SV of
DoubleStringCharacter :: LineContinuation -
The SV of
SingleStringCharacter :: SourceCharacter but not one of ' or\ orLineTerminator UTF16Encoding of the code point value ofSourceCharacter . -
The SV of
SingleStringCharacter :: \ EscapeSequence EscapeSequence . -
The SV of
SingleStringCharacter :: LineContinuation -
The SV of
EscapeSequence :: CharacterEscapeSequence CharacterEscapeSequence . -
The SV of
EscapeSequence :: 0 -
The SV of
EscapeSequence :: HexEscapeSequence HexEscapeSequence . -
The SV of
EscapeSequence :: UnicodeEscapeSequence UnicodeEscapeSequence . -
The SV of
CharacterEscapeSequence :: SingleEscapeCharacter SingleEscapeCharacter according toTable 34 .
| Escape Sequence | Code Unit Value | Unicode Character Name | Symbol |
|---|---|---|---|
\b
|
0x0008
|
BACKSPACE | <BS> |
\t
|
0x0009
|
CHARACTER TABULATION | <HT> |
\n
|
0x000A
|
LINE FEED (LF) | <LF> |
\v
|
0x000B
|
LINE TABULATION | <VT> |
\f
|
0x000C
|
FORM FEED (FF) | <FF> |
\r
|
0x000D
|
CARRIAGE RETURN (CR) | <CR> |
\"
|
0x0022
|
QUOTATION MARK |
"
|
\'
|
0x0027
|
APOSTROPHE |
'
|
\\
|
0x005C
|
REVERSE SOLIDUS |
\
|
-
The SV of
CharacterEscapeSequence :: NonEscapeCharacter NonEscapeCharacter . -
The SV of
NonEscapeCharacter :: SourceCharacter but not one of EscapeCharacter orLineTerminator UTF16Encoding of the code point value ofSourceCharacter . -
The SV of
HexEscapeSequence :: x HexDigit HexDigit HexDigit ) plus the MV of the secondHexDigit . -
The SV of
UnicodeEscapeSequence :: u Hex4Digits Hex4Digits . -
The SV of
Hex4Digits :: HexDigit HexDigit HexDigit HexDigit HexDigit ) plus (0x100 times the MV of the secondHexDigit ) plus (0x10 times the MV of the thirdHexDigit ) plus the MV of the fourthHexDigit . -
The SV of
UnicodeEscapeSequence :: u{ CodePoint } UTF16Encoding of the MV ofCodePoint .
11.8.5 Regular Expression Literals
A regular expression literal is an input element that is converted to a RegExp object (see === to each other even if the two literals' contents are identical. A RegExp object may also be created at runtime by new RegExp or calling the RegExp
The productions below describe the syntax for a regular expression literal and are used by the input element scanner to find the end of the regular expression literal. The source text comprising the
An implementation may extend the ECMAScript Regular Expression grammar defined in
Syntax
Regular expression literals may not be empty; instead of representing an empty regular expression literal, the code unit sequence // starts a single-line comment. To specify an empty regular expression, use: /(?:)/.
11.8.5.1 Static Semantics: Early Errors
-
It is a Syntax Error if
IdentifierPart contains a Unicode escape sequence.
11.8.5.2 Static Semantics: BodyText
- Return the source text that was recognized as
RegularExpressionBody .
11.8.5.3 Static Semantics: FlagText
- Return the source text that was recognized as
RegularExpressionFlags .
11.8.6 Template Literal Lexical Components
Syntax
A conforming implementation must not use the extended definition of
11.8.6.1 Static Semantics: TV and TRV
A template literal component is interpreted as a sequence of Unicode code points. The Template Value (TV) of a literal component is described in terms of code unit values (SV,
-
The TV and TRV of
NoSubstitutionTemplate :: ` ` -
The TV and TRV of
TemplateHead :: ` ${ -
The TV and TRV of
TemplateMiddle :: } ${ -
The TV and TRV of
TemplateTail :: } ` -
The TV of
NoSubstitutionTemplate :: ` TemplateCharacters ` TemplateCharacters . -
The TV of
TemplateHead :: ` TemplateCharacters ${ TemplateCharacters . -
The TV of
TemplateMiddle :: } TemplateCharacters ${ TemplateCharacters . -
The TV of
TemplateTail :: } TemplateCharacters ` TemplateCharacters . -
The TV of
TemplateCharacters :: TemplateCharacter TemplateCharacter . -
The TV of
TemplateCharacters :: TemplateCharacter TemplateCharacters undefined if either the TV ofTemplateCharacter isundefined or the TV ofTemplateCharacters isundefined . Otherwise, it is a sequence consisting of the code units of the TV ofTemplateCharacter followed by the code units of the TV ofTemplateCharacters . -
The TV of
TemplateCharacter :: SourceCharacter but not one of ` or\ or$ orLineTerminator UTF16Encoding of the code point value ofSourceCharacter . -
The TV of
TemplateCharacter :: $ -
The TV of
TemplateCharacter :: \ EscapeSequence EscapeSequence . -
The TV of
TemplateCharacter :: \ NotEscapeSequence undefined . -
The TV of
TemplateCharacter :: LineContinuation LineContinuation . -
The TV of
TemplateCharacter :: LineTerminatorSequence LineTerminatorSequence . -
The TV of
LineContinuation :: \ LineTerminatorSequence -
The TRV of
NoSubstitutionTemplate :: ` TemplateCharacters ` TemplateCharacters . -
The TRV of
TemplateHead :: ` TemplateCharacters ${ TemplateCharacters . -
The TRV of
TemplateMiddle :: } TemplateCharacters ${ TemplateCharacters . -
The TRV of
TemplateTail :: } TemplateCharacters ` TemplateCharacters . -
The TRV of
TemplateCharacters :: TemplateCharacter TemplateCharacter . -
The TRV of
TemplateCharacters :: TemplateCharacter TemplateCharacters TemplateCharacter followed by the code units of the TRV ofTemplateCharacters . -
The TRV of
TemplateCharacter :: SourceCharacter but not one of ` or\ or$ orLineTerminator UTF16Encoding of the code point value ofSourceCharacter . -
The TRV of
TemplateCharacter :: $ -
The TRV of
TemplateCharacter :: \ EscapeSequence EscapeSequence . -
The TRV of
TemplateCharacter :: \ NotEscapeSequence NotEscapeSequence . -
The TRV of
TemplateCharacter :: LineContinuation LineContinuation . -
The TRV of
TemplateCharacter :: LineTerminatorSequence LineTerminatorSequence . -
The TRV of
EscapeSequence :: CharacterEscapeSequence CharacterEscapeSequence . -
The TRV of
EscapeSequence :: 0 -
The TRV of
EscapeSequence :: HexEscapeSequence HexEscapeSequence . -
The TRV of
EscapeSequence :: UnicodeEscapeSequence UnicodeEscapeSequence . -
The TRV of
NotEscapeSequence :: 0 DecimalDigit DecimalDigit . -
The TRV of
NotEscapeSequence :: x [lookahead ∉ HexDigit ] -
The TRV of
NotEscapeSequence :: x HexDigit [lookahead ∉ HexDigit ]HexDigit . -
The TRV of
NotEscapeSequence :: u [lookahead ∉ HexDigit ][lookahead ≠ { ] -
The TRV of
NotEscapeSequence :: u HexDigit [lookahead ∉ HexDigit ]HexDigit . -
The TRV of
NotEscapeSequence :: u HexDigit HexDigit [lookahead ∉ HexDigit ]HexDigit followed by the code units of the TRV of the secondHexDigit . -
The TRV of
NotEscapeSequence :: u HexDigit HexDigit HexDigit [lookahead ∉ HexDigit ]HexDigit followed by the code units of the TRV of the secondHexDigit followed by the code units of the TRV of the thirdHexDigit . -
The TRV of
NotEscapeSequence :: u { [lookahead ∉ HexDigit ] -
The TRV of
NotEscapeSequence :: u { NotCodePoint [lookahead ∉ HexDigit ]NotCodePoint . -
The TRV of
NotEscapeSequence :: u { CodePoint [lookahead ∉ HexDigit ][lookahead ≠ } ]CodePoint . -
The TRV of
DecimalDigit :: one of 0 1 2 3 4 5 6 7 8 9 SourceCharacter that is that single code point. -
The TRV of
CharacterEscapeSequence :: SingleEscapeCharacter SingleEscapeCharacter . -
The TRV of
CharacterEscapeSequence :: NonEscapeCharacter NonEscapeCharacter . -
The TRV of
SingleEscapeCharacter :: one of ' " \ b f n r t v SourceCharacter that is that single code point. -
The TRV of
HexEscapeSequence :: x HexDigit HexDigit HexDigit followed by the TRV of the secondHexDigit . -
The TRV of
UnicodeEscapeSequence :: u Hex4Digits Hex4Digits . -
The TRV of
UnicodeEscapeSequence :: u{ CodePoint } CodePoint followed by the code unit 0x007D (RIGHT CURLY BRACKET). -
The TRV of
Hex4Digits :: HexDigit HexDigit HexDigit HexDigit HexDigit followed by the TRV of the secondHexDigit followed by the TRV of the thirdHexDigit followed by the TRV of the fourthHexDigit . -
The TRV of
HexDigits :: HexDigit HexDigit . -
The TRV of
HexDigits :: HexDigits HexDigit HexDigits followed by TRV ofHexDigit . -
The TRV of a
HexDigit is the SV of theSourceCharacter that is thatHexDigit . -
The TRV of
LineContinuation :: \ LineTerminatorSequence LineTerminatorSequence . -
The TRV of
LineTerminatorSequence :: <LF> -
The TRV of
LineTerminatorSequence :: <CR> -
The TRV of
LineTerminatorSequence :: <LS> -
The TRV of
LineTerminatorSequence :: <PS> -
The TRV of
LineTerminatorSequence :: <CR> <LF>
TV excludes the code units of
11.9 Automatic Semicolon Insertion
Most ECMAScript statements and declarations must be terminated with a semicolon. Such semicolons may always appear explicitly in the source text. For convenience, however, such semicolons may be omitted from the source text in certain situations. These situations are described by saying that semicolons are automatically inserted into the source code token stream in those situations.
11.9.1 Rules of Automatic Semicolon Insertion
In the following rules, “token” means the actual recognized lexical token determined using the current lexical
There are three basic rules of semicolon insertion:
-
When, as the source text is parsed from left to right, a token (called the offending token) is encountered that is not allowed by any production of the grammar, then a semicolon is automatically inserted before the offending token if one or more of the following conditions is true:
-
The offending token is separated from the previous token by at least one
LineTerminator . -
The offending token is
}. -
The previous token is
)and the inserted semicolon would then be parsed as the terminating semicolon of a do-while statement (13.7.2 ).
-
The offending token is separated from the previous token by at least one
- When, as the source text is parsed from left to right, the end of the input stream of tokens is encountered and the parser is unable to parse the input token stream as a single instance of the goal nonterminal, then a semicolon is automatically inserted at the end of the input stream.
-
When, as the source text is parsed from left to right, a token is encountered that is allowed by some production of the grammar, but the production is a restricted production and the token would be the first token for a terminal or nonterminal immediately following the annotation “[no
LineTerminator here]” within the restricted production (and therefore such a token is called a restricted token), and the restricted token is separated from the previous token by at least oneLineTerminator , then a semicolon is automatically inserted before the restricted token.
However, there is an additional overriding condition on the preceding rules: a semicolon is never inserted automatically if the semicolon would then be parsed as an empty statement or if that semicolon would become one of the two semicolons in the header of a for statement (see
The following are the only restricted productions in the grammar:
The practical effect of these restricted productions is as follows:
-
When a
++or--token is encountered where the parser would treat it as a postfix operator, and at least oneLineTerminator occurred between the preceding token and the++or--token, then a semicolon is automatically inserted before the++or--token. -
When a
continue,break,return,throw, oryieldtoken is encountered and aLineTerminator is encountered before the next token, a semicolon is automatically inserted after thecontinue,break,return,throw, oryieldtoken.
The resulting practical advice to ECMAScript programmers is:
-
A postfix
++or--operator should appear on the same line as its operand. -
An
Expression in areturnorthrowstatement or anAssignmentExpression in ayieldexpression should start on the same line as thereturn,throw, oryieldtoken. -
A
LabelIdentifier in abreakorcontinuestatement should be on the same line as thebreakorcontinuetoken.
11.9.2 Examples of Automatic Semicolon Insertion
The source
{ 1 2 } 3is not a valid sentence in the ECMAScript grammar, even with the automatic semicolon insertion rules. In contrast, the source
{ 1
2 } 3is also not a valid ECMAScript sentence, but is transformed by automatic semicolon insertion into the following:
{ 1
;2 ;} 3;which is a valid ECMAScript sentence.
The source
for (a; b
)is not a valid ECMAScript sentence and is not altered by automatic semicolon insertion because the semicolon is needed for the header of a for statement. Automatic semicolon insertion never inserts one of the two semicolons in the header of a for statement.
The source
return
a + bis transformed by automatic semicolon insertion into the following:
return;
a + b;The expression a + b is not treated as a value to be returned by the return statement, because a return.
The source
a = b
++cis transformed by automatic semicolon insertion into the following:
a = b;
++c;The token ++ is not treated as a postfix operator applying to the variable b, because a b and ++.
The source
if (a > b)
else c = dis not a valid ECMAScript sentence and is not altered by automatic semicolon insertion before the else token, even though no production of the grammar applies at that point, because an automatically inserted semicolon would then be parsed as an empty statement.
The source
a = b + c
(d + e).print()is not transformed by automatic semicolon insertion, because the parenthesized expression that begins the second line can be interpreted as an argument list for a function call:
a = b + c(d + e).print()In the circumstance that an assignment statement must begin with a left parenthesis, it is a good idea for the programmer to provide an explicit semicolon at the end of the preceding statement rather than to rely on automatic semicolon insertion.
12 ECMAScript Language: Expressions
12.1 Identifiers
Syntax
yield and await are permitted as
let
await 0;12.1.1 Static Semantics: Early Errors
-
It is a Syntax Error if the code matched by this production is contained in
strict mode code and the StringValue ofIdentifier is"arguments"or"eval".
-
It is a Syntax Error if the code matched by this production is contained in
strict mode code .
-
It is a Syntax Error if the
goal symbol of the syntactic grammar isModule .
- It is a Syntax Error if this production has a [Yield] parameter.
- It is a Syntax Error if this production has an [Await] parameter.
-
It is a Syntax Error if this production has a [Yield] parameter and StringValue of
Identifier is"yield". -
It is a Syntax Error if this production has an [Await] parameter and StringValue of
Identifier is"await".
-
It is a Syntax Error if this phrase is contained in
strict mode code and the StringValue ofIdentifierName is:"implements","interface","let","package","private","protected","public","static", or"yield". -
It is a Syntax Error if the
goal symbol of the syntactic grammar isModule and the StringValue ofIdentifierName is"await". -
It is a Syntax Error if StringValue of
IdentifierName is the same String value as the StringValue of anyReservedWord except foryieldorawait.
StringValue of
12.1.2 Static Semantics: BoundNames
- Return a new
List containing the StringValue ofIdentifier .
- Return a new
List containing"yield".
- Return a new
List containing"await".
12.1.3 Static Semantics: IsValidSimpleAssignmentTarget
- If this
IdentifierReference is contained instrict mode code and StringValue ofIdentifier is"eval"or"arguments", returnfalse . - Return
true .
- Return
true .
- Return
true .
12.1.4 Static Semantics: StringValue
- Return
"yield".
- Return
"await".
- Return the StringValue of
IdentifierName .
12.1.5 Runtime Semantics: BindingInitialization
With parameters value and environment.
var statements and formal parameter lists of some non-strict functions (See
- Let name be StringValue of
Identifier . - Return ?
InitializeBoundName (name, value, environment).
- Return ?
InitializeBoundName ("yield", value, environment).
- Return ?
InitializeBoundName ("await", value, environment).
12.1.5.1 Runtime Semantics: InitializeBoundName ( name, value, environment )
Assert :Type (name) is String.- If environment is not
undefined , then- Let env be the
EnvironmentRecord component of environment. - Perform env.InitializeBinding(name, value).
- Return
NormalCompletion (undefined ).
- Let env be the
- Else,
- Let lhs be
ResolveBinding (name). - Return ?
PutValue (lhs, value).
- Let lhs be
12.1.6 Runtime Semantics: Evaluation
- Return ?
ResolveBinding (StringValue ofIdentifier ).
- Return ?
ResolveBinding ("yield").
- Return ?
ResolveBinding ("await").
The result of evaluating an
In yield may be used as an identifier. Evaluating the yield as if it was an
12.2 Primary Expression
Syntax
Supplemental Syntax
When processing an instance of the production
the interpretation of
12.2.1 Semantics
12.2.1.1 Static Semantics: CoveredParenthesizedExpression
- Return the
ParenthesizedExpression that iscovered byCoverParenthesizedExpressionAndArrowParameterList .
12.2.1.2 Static Semantics: HasName
- Let expr be CoveredParenthesizedExpression of
CoverParenthesizedExpressionAndArrowParameterList . - If IsFunctionDefinition of expr is
false , returnfalse . - Return HasName of expr.
12.2.1.3 Static Semantics: IsFunctionDefinition
- Return
false .
- Let expr be CoveredParenthesizedExpression of
CoverParenthesizedExpressionAndArrowParameterList . - Return IsFunctionDefinition of expr.
12.2.1.4 Static Semantics: IsIdentifierRef
- Return
true .
- Return
false .
12.2.1.5 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
- Let expr be CoveredParenthesizedExpression of
CoverParenthesizedExpressionAndArrowParameterList . - Return IsValidSimpleAssignmentTarget of expr.
12.2.2 The this Keyword
12.2.2.1 Runtime Semantics: Evaluation
- Return ?
ResolveThisBinding ().
12.2.3 Identifier Reference
See
12.2.4 Literals
Syntax
12.2.4.1 Runtime Semantics: Evaluation
- Return
null .
- If
BooleanLiteral is the tokenfalse, returnfalse . - If
BooleanLiteral is the tokentrue, returntrue .
- Return the number whose value is MV of
NumericLiteral as defined in11.8.3 .
- Return the StringValue of
StringLiteral as defined in11.8.4.1 .
12.2.5 Array Initializer
An
Array elements may be elided at the beginning, middle or end of the element list. Whenever a comma in the element list is not preceded by an
Syntax
12.2.5.1 Static Semantics: ElisionWidth
- Return the numeric value 1.
- Let preceding be the ElisionWidth of
Elision . - Return preceding+1.
12.2.5.2 Runtime Semantics: ArrayAccumulation
With parameters array and nextIndex.
- Let padding be the ElisionWidth of
Elision ; ifElision is not present, use the numeric value zero. - Let initResult be the result of evaluating
AssignmentExpression . - Let initValue be ?
GetValue (initResult). - Let created be
CreateDataProperty (array,ToString (ToUint32 (nextIndex+padding)), initValue). Assert : created istrue .- Return nextIndex+padding+1.
- Let padding be the ElisionWidth of
Elision ; ifElision is not present, use the numeric value zero. - Return the result of performing ArrayAccumulation for
SpreadElement with arguments array and nextIndex+padding.
- Let postIndex be the result of performing ArrayAccumulation for
ElementList with arguments array and nextIndex. ReturnIfAbrupt (postIndex).- Let padding be the ElisionWidth of
Elision ; ifElision is not present, use the numeric value zero. - Let initResult be the result of evaluating
AssignmentExpression . - Let initValue be ?
GetValue (initResult). - Let created be
CreateDataProperty (array,ToString (ToUint32 (postIndex+padding)), initValue). Assert : created istrue .- Return postIndex+padding+1.
- Let postIndex be the result of performing ArrayAccumulation for
ElementList with arguments array and nextIndex. ReturnIfAbrupt (postIndex).- Let padding be the ElisionWidth of
Elision ; ifElision is not present, use the numeric value zero. - Return the result of performing ArrayAccumulation for
SpreadElement with arguments array and postIndex+padding.
- Let spreadRef be the result of evaluating
AssignmentExpression . - Let spreadObj be ?
GetValue (spreadRef). - Let iteratorRecord be ?
GetIterator (spreadObj). - Repeat,
- Let next be ?
IteratorStep (iteratorRecord). - If next is
false , return nextIndex. - Let nextValue be ?
IteratorValue (next). - Let status be
CreateDataProperty (array,ToString (ToUint32 (nextIndex)), nextValue). Assert : status istrue .- Let nextIndex be nextIndex + 1.
- Let next be ?
12.2.5.3 Runtime Semantics: Evaluation
- Let array be !
ArrayCreate (0). - Let pad be the ElisionWidth of
Elision ; ifElision is not present, use the numeric value zero. - Perform
Set (array,"length",ToUint32 (pad),false ). - NOTE: The above Set cannot fail because of the nature of the object returned by
ArrayCreate . - Return array.
- Let array be !
ArrayCreate (0). - Let len be the result of performing ArrayAccumulation for
ElementList with arguments array and 0. ReturnIfAbrupt (len).- Perform
Set (array,"length",ToUint32 (len),false ). - NOTE: The above Set cannot fail because of the nature of the object returned by
ArrayCreate . - Return array.
- Let array be !
ArrayCreate (0). - Let len be the result of performing ArrayAccumulation for
ElementList with arguments array and 0. ReturnIfAbrupt (len).- Let padding be the ElisionWidth of
Elision ; ifElision is not present, use the numeric value zero. - Perform
Set (array,"length",ToUint32 (padding+len),false ). - NOTE: The above Set cannot fail because of the nature of the object returned by
ArrayCreate . - Return array.
12.2.6 Object Initializer
An object initializer is an expression describing the initialization of an Object, written in a form resembling a literal. It is a list of zero or more pairs of property keys and associated values, enclosed in curly brackets. The values need not be literals; they are evaluated each time the object initializer is evaluated.
Syntax
In certain contexts,
12.2.6.1 Static Semantics: Early Errors
-
It is a Syntax Error if HasDirectSuper of
MethodDefinition istrue .
In addition to describing an actual object initializer the
- Always throw a Syntax Error if code matches this production.
This production exists so that
12.2.6.2 Static Semantics: ComputedPropertyContains
With parameter symbol.
- Return
false .
- Return the result of
ComputedPropertyName Contains symbol.
12.2.6.3 Static Semantics: Contains
With parameter symbol.
- If symbol is
MethodDefinition , returntrue . - Return the result of ComputedPropertyContains for
MethodDefinition with argument symbol.
Static semantic rules that depend upon substructure generally do not look into function definitions.
- If symbol is a
ReservedWord , returnfalse . - If symbol is an
Identifier and StringValue of symbol is the same value as the StringValue ofIdentifierName , returntrue . - Return
false .
12.2.6.4 Static Semantics: IsComputedPropertyKey
- Return
false .
- Return
true .
12.2.6.5 Static Semantics: PropName
- Return StringValue of
IdentifierReference .
- Return
empty .
- Return PropName of
PropertyName .
- Return StringValue of
IdentifierName .
- Return the String value whose code units are the SV of the
StringLiteral .
- Let nbr be the result of forming the value of the
NumericLiteral . - Return !
ToString (nbr).
- Return
empty .
12.2.6.6 Static Semantics: PropertyNameList
- If PropName of
PropertyDefinition isempty , return a new emptyList . - Return a new
List containing PropName ofPropertyDefinition .
- Let list be PropertyNameList of
PropertyDefinitionList . - If PropName of
PropertyDefinition isempty , return list. - Append PropName of
PropertyDefinition to the end of list. - Return list.
12.2.6.7 Runtime Semantics: Evaluation
- Return
ObjectCreate (%ObjectPrototype% ).
- Let obj be
ObjectCreate (%ObjectPrototype% ). - Perform ? PropertyDefinitionEvaluation of
PropertyDefinitionList with arguments obj andtrue . - Return obj.
- Return StringValue of
IdentifierName .
- Return the String value whose code units are the SV of the
StringLiteral .
- Let nbr be the result of forming the value of the
NumericLiteral . - Return !
ToString (nbr).
- Let exprValue be the result of evaluating
AssignmentExpression . - Let propName be ?
GetValue (exprValue). - Return ?
ToPropertyKey (propName).
12.2.6.8 Runtime Semantics: PropertyDefinitionEvaluation
With parameters object and enumerable.
- Perform ? PropertyDefinitionEvaluation of
PropertyDefinitionList with arguments object and enumerable. - Return the result of performing PropertyDefinitionEvaluation of
PropertyDefinition with arguments object and enumerable.
- Let exprValue be the result of evaluating
AssignmentExpression . - Let fromValue be ?
GetValue (exprValue). - Let excludedNames be a new empty
List . - Return ?
CopyDataProperties (object, fromValue, excludedNames).
- Let propName be StringValue of
IdentifierReference . - Let exprValue be the result of evaluating
IdentifierReference . - Let propValue be ?
GetValue (exprValue). Assert : enumerable istrue .- Return
CreateDataPropertyOrThrow (object, propName, propValue).
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- Let exprValueRef be the result of evaluating
AssignmentExpression . - Let propValue be ?
GetValue (exprValueRef). - If
IsAnonymousFunctionDefinition (AssignmentExpression ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (propValue,"name"). - If hasNameProperty is
false , performSetFunctionName (propValue, propKey).
- Let hasNameProperty be ?
Assert : enumerable istrue .- Return
CreateDataPropertyOrThrow (object, propKey, propValue).
An alternative semantics for this production is given in
12.2.7 Function Defining Expressions
See
See
See
See
See
12.2.8 Regular Expression Literals
Syntax
See
12.2.8.1 Static Semantics: Early Errors
-
It is a Syntax Error if BodyText of
RegularExpressionLiteral cannot be recognized using thegoal symbol Pattern of the ECMAScript RegExp grammar specified in21.2.1 . -
It is a Syntax Error if FlagText of
RegularExpressionLiteral contains any code points other than"g","i","m","s","u", or"y", or if it contains the same code point more than once.
12.2.8.2 Runtime Semantics: Evaluation
- Let pattern be the String value consisting of the
UTF16Encoding of each code point of BodyText ofRegularExpressionLiteral . - Let flags be the String value consisting of the
UTF16Encoding of each code point of FlagText ofRegularExpressionLiteral . - Return
RegExpCreate (pattern, flags).
12.2.9 Template Literals
Syntax
12.2.9.1 Static Semantics: Early Errors
-
It is a Syntax Error if the number of elements in the result of TemplateStrings of
TemplateLiteral with argumentfalse is greater than 232-1. -
It is a Syntax Error if the [Tagged] parameter was not set and
NoSubstitutionTemplate ContainsNotEscapeSequence .
-
It is a Syntax Error if the [Tagged] parameter was not set and
TemplateHead ContainsNotEscapeSequence .
-
It is a Syntax Error if the [Tagged] parameter was not set and
TemplateTail ContainsNotEscapeSequence .
-
It is a Syntax Error if the [Tagged] parameter was not set and
TemplateMiddle ContainsNotEscapeSequence .
12.2.9.2 Static Semantics: TemplateStrings
With parameter raw.
- If raw is
false , then- Let string be the TV of
NoSubstitutionTemplate .
- Let string be the TV of
- Else,
- Let string be the TRV of
NoSubstitutionTemplate .
- Let string be the TRV of
- Return a
List containing the single element, string.
- If raw is
false , then- Let head be the TV of
TemplateHead .
- Let head be the TV of
- Else,
- Let head be the TRV of
TemplateHead .
- Let head be the TRV of
- Let tail be TemplateStrings of
TemplateSpans with argument raw. - Return a
List containing head followed by the elements, in order, of tail.
- If raw is
false , then- Let tail be the TV of
TemplateTail .
- Let tail be the TV of
- Else,
- Let tail be the TRV of
TemplateTail .
- Let tail be the TRV of
- Return a
List containing the single element, tail.
- Let middle be TemplateStrings of
TemplateMiddleList with argument raw. - If raw is
false , then- Let tail be the TV of
TemplateTail .
- Let tail be the TV of
- Else,
- Let tail be the TRV of
TemplateTail .
- Let tail be the TRV of
- Return a
List containing the elements, in order, of middle followed by tail.
- If raw is
false , then- Let string be the TV of
TemplateMiddle .
- Let string be the TV of
- Else,
- Let string be the TRV of
TemplateMiddle .
- Let string be the TRV of
- Return a
List containing the single element, string.
- Let front be TemplateStrings of
TemplateMiddleList with argument raw. - If raw is
false , then- Let last be the TV of
TemplateMiddle .
- Let last be the TV of
- Else,
- Let last be the TRV of
TemplateMiddle .
- Let last be the TRV of
- Append last as the last element of the
List front. - Return front.
12.2.9.3 Runtime Semantics: ArgumentListEvaluation
- Let templateLiteral be this
TemplateLiteral . - Let siteObj be
GetTemplateObject (templateLiteral). - Return a
List containing the one element which is siteObj.
- Let templateLiteral be this
TemplateLiteral . - Let siteObj be
GetTemplateObject (templateLiteral). - Let firstSubRef be the result of evaluating
Expression . - Let firstSub be ?
GetValue (firstSubRef). - Let restSub be SubstitutionEvaluation of
TemplateSpans . ReturnIfAbrupt (restSub).Assert : restSub is aList .- Return a
List whose first element is siteObj, whose second elements is firstSub, and whose subsequent elements are the elements of restSub, in order. restSub may contain no elements.
12.2.9.4 Runtime Semantics: GetTemplateObject ( templateLiteral )
The abstract operation GetTemplateObject is called with a
- Let rawStrings be TemplateStrings of templateLiteral with argument
true . - Let realm be
the current Realm Record . - Let templateRegistry be realm.[[TemplateMap]].
- For each element e of templateRegistry, do
- If e.[[Site]] is
the same Parse Node as templateLiteral, then- Return e.[[Array]].
- If e.[[Site]] is
- Let cookedStrings be TemplateStrings of templateLiteral with argument
false . - Let count be the number of elements in the
List cookedStrings. Assert : count ≤ 232-1.- Let template be !
ArrayCreate (count). - Let rawObj be !
ArrayCreate (count). - Let index be 0.
- Repeat, while index < count
- Let prop be !
ToString (index). - Let cookedValue be the String value cookedStrings[index].
- Call template.[[DefineOwnProperty]](prop, PropertyDescriptor { [[Value]]: cookedValue, [[Writable]]:
false , [[Enumerable]]:true , [[Configurable]]:false }). - Let rawValue be the String value rawStrings[index].
- Call rawObj.[[DefineOwnProperty]](prop, PropertyDescriptor { [[Value]]: rawValue, [[Writable]]:
false , [[Enumerable]]:true , [[Configurable]]:false }). - Let index be index+1.
- Let prop be !
- Perform
SetIntegrityLevel (rawObj,"frozen"). - Call template.[[DefineOwnProperty]](
"raw", PropertyDescriptor { [[Value]]: rawObj, [[Writable]]:false , [[Enumerable]]:false , [[Configurable]]:false }). - Perform
SetIntegrityLevel (template,"frozen"). - Append the
Record { [[Site]]: templateLiteral, [[Array]]: template } to templateRegistry. - Return template.
The creation of a template object cannot result in an
Each
Future editions of this specification may define additional non-enumerable properties of template objects.
12.2.9.5 Runtime Semantics: SubstitutionEvaluation
- Return a new empty
List .
- Return the result of SubstitutionEvaluation of
TemplateMiddleList .
- Let subRef be the result of evaluating
Expression . - Let sub be ?
GetValue (subRef). - Return a
List containing only sub.
- Let preceding be the result of SubstitutionEvaluation of
TemplateMiddleList . ReturnIfAbrupt (preceding).- Let nextRef be the result of evaluating
Expression . - Let next be ?
GetValue (nextRef). - Append next as the last element of the
List preceding. - Return preceding.
12.2.9.6 Runtime Semantics: Evaluation
- Return the String value whose code units are the elements of the TV of
NoSubstitutionTemplate as defined in11.8.6 .
- Let head be the TV of
TemplateHead as defined in11.8.6 . - Let sub be the result of evaluating
Expression . ReturnIfAbrupt (sub).- Let middle be ?
ToString (sub). - Let tail be the result of evaluating
TemplateSpans . ReturnIfAbrupt (tail).- Return the
string-concatenation of head, middle, and tail.
The string conversion semantics applied to the String.prototype.concat rather than the + operator.
- Let tail be the TV of
TemplateTail as defined in11.8.6 . - Return the String value consisting of the code units of tail.
- Let head be the result of evaluating
TemplateMiddleList . ReturnIfAbrupt (head).- Let tail be the TV of
TemplateTail as defined in11.8.6 . - Return the
string-concatenation of head and tail.
- Let head be the TV of
TemplateMiddle as defined in11.8.6 . - Let sub be the result of evaluating
Expression . ReturnIfAbrupt (sub).- Let middle be ?
ToString (sub). - Return the sequence of code units consisting of the code units of head followed by the elements of middle.
The string conversion semantics applied to the String.prototype.concat rather than the + operator.
- Let rest be the result of evaluating
TemplateMiddleList . ReturnIfAbrupt (rest).- Let middle be the TV of
TemplateMiddle as defined in11.8.6 . - Let sub be the result of evaluating
Expression . ReturnIfAbrupt (sub).- Let last be ?
ToString (sub). - Return the sequence of code units consisting of the elements of rest followed by the code units of middle followed by the elements of last.
The string conversion semantics applied to the String.prototype.concat rather than the + operator.
12.2.10 The Grouping Operator
12.2.10.1 Static Semantics: Early Errors
-
It is a Syntax Error if
CoverParenthesizedExpressionAndArrowParameterList is notcovering aParenthesizedExpression . -
All Early Error rules for
ParenthesizedExpression and its derived productions also apply to CoveredParenthesizedExpression ofCoverParenthesizedExpressionAndArrowParameterList .
12.2.10.2 Static Semantics: IsFunctionDefinition
- Return IsFunctionDefinition of
Expression .
12.2.10.3 Static Semantics: IsValidSimpleAssignmentTarget
- Return IsValidSimpleAssignmentTarget of
Expression .
12.2.10.4 Runtime Semantics: Evaluation
- Let expr be CoveredParenthesizedExpression of
CoverParenthesizedExpressionAndArrowParameterList . - Return the result of evaluating expr.
- Return the result of evaluating
Expression . This may be of typeReference .
This algorithm does not apply delete and typeof may be applied to parenthesized expressions.
12.3 Left-Hand-Side Expressions
Syntax
Supplemental Syntax
When processing an instance of the production
12.3.1 Static Semantics
12.3.1.1 Static Semantics: CoveredCallExpression
- Return the
CallMemberExpression that iscovered byCoverCallExpressionAndAsyncArrowHead .
12.3.1.2 Static Semantics: Contains
With parameter symbol.
- If
MemberExpression Contains symbol istrue , returntrue . - If symbol is a
ReservedWord , returnfalse . - If symbol is an
Identifier and StringValue of symbol is the same value as the StringValue ofIdentifierName , returntrue . - Return
false .
- If symbol is the
ReservedWord super, returntrue . - If symbol is a
ReservedWord , returnfalse . - If symbol is an
Identifier and StringValue of symbol is the same value as the StringValue ofIdentifierName , returntrue . - Return
false .
- If
CallExpression Contains symbol istrue , returntrue . - If symbol is a
ReservedWord , returnfalse . - If symbol is an
Identifier and StringValue of symbol is the same value as the StringValue ofIdentifierName , returntrue . - Return
false .
12.3.1.3 Static Semantics: IsFunctionDefinition
- Return
false .
12.3.1.4 Static Semantics: IsDestructuring
- If
PrimaryExpression is either anObjectLiteral or anArrayLiteral , returntrue . - Return
false .
- Return
false .
12.3.1.5 Static Semantics: IsIdentifierRef
- Return
false .
12.3.1.6 Static Semantics: IsValidSimpleAssignmentTarget
- Return
true .
- Return
false .
12.3.2 Property Accessors
Properties are accessed by name, using either the dot notation:
or the bracket notation:
The dot notation is explained by the following syntactic conversion:
is identical in its behaviour to
and similarly
is identical in its behaviour to
where <identifier-name-string> is the result of evaluating StringValue of
12.3.2.1 Runtime Semantics: Evaluation
- Let baseReference be the result of evaluating
MemberExpression . - Let baseValue be ?
GetValue (baseReference). - Let propertyNameReference be the result of evaluating
Expression . - Let propertyNameValue be ?
GetValue (propertyNameReference). - Let bv be ?
RequireObjectCoercible (baseValue). - Let propertyKey be ?
ToPropertyKey (propertyNameValue). - If the code matched by this
MemberExpression isstrict mode code , let strict betrue , else let strict befalse . - Return a value of type
Reference whose base value component is bv, whose referenced name component is propertyKey, and whose strict reference flag is strict.
- Let baseReference be the result of evaluating
MemberExpression . - Let baseValue be ?
GetValue (baseReference). - Let bv be ?
RequireObjectCoercible (baseValue). - Let propertyNameString be StringValue of
IdentifierName . - If the code matched by this
MemberExpression isstrict mode code , let strict betrue , else let strict befalse . - Return a value of type
Reference whose base value component is bv, whose referenced name component is propertyNameString, and whose strict reference flag is strict.
Is evaluated in exactly the same manner as
Is evaluated in exactly the same manner as
12.3.3 The new Operator
12.3.3.1 Runtime Semantics: Evaluation
- Return ?
EvaluateNew (NewExpression ,empty ).
- Return ?
EvaluateNew (MemberExpression ,Arguments ).
12.3.3.1.1 Runtime Semantics: EvaluateNew ( constructExpr, arguments )
The abstract operation EvaluateNew with arguments constructExpr, and arguments performs the following steps:
Assert : constructExpr is either aNewExpression or aMemberExpression .Assert : arguments is eitherempty or anArguments .- Let ref be the result of evaluating constructExpr.
- Let constructor be ?
GetValue (ref). - If arguments is
empty , let argList be a new emptyList . - Else,
- Let argList be ArgumentListEvaluation of arguments.
ReturnIfAbrupt (argList).
- If
IsConstructor (constructor) isfalse , throw aTypeError exception. - Return ?
Construct (constructor, argList).
12.3.4 Function Calls
12.3.4.1 Runtime Semantics: Evaluation
- Let expr be CoveredCallExpression of
CoverCallExpressionAndAsyncArrowHead . - Let memberExpr be the
MemberExpression of expr. - Let arguments be the
Arguments of expr. - Let ref be the result of evaluating memberExpr.
- Let func be ?
GetValue (ref). - If
Type (ref) isReference andIsPropertyReference (ref) isfalse andGetReferencedName (ref) is"eval", then- If
SameValue (func,%eval% ) istrue , then- Let argList be ? ArgumentListEvaluation of arguments.
- If argList has no elements, return
undefined . - Let evalText be the first element of argList.
- If the source code matching this
CallExpression isstrict mode code , let strictCaller betrue . Otherwise let strictCaller befalse . - Let evalRealm be
the current Realm Record . - Perform ?
HostEnsureCanCompileStrings (evalRealm, evalRealm). - Return ?
PerformEval (evalText, evalRealm, strictCaller,true ).
- If
- Let thisCall be this
CallExpression . - Let tailCall be
IsInTailPosition (thisCall). - Return ?
EvaluateCall (func, ref, arguments, tailCall).
A
- Let ref be the result of evaluating
CallExpression . - Let func be ?
GetValue (ref). - Let thisCall be this
CallExpression . - Let tailCall be
IsInTailPosition (thisCall). - Return ?
EvaluateCall (func, ref,Arguments , tailCall).
12.3.4.2 Runtime Semantics: EvaluateCall ( func, ref, arguments, tailPosition )
The abstract operation EvaluateCall takes as arguments a value func, a value ref, a
- If
Type (ref) isReference , then- If
IsPropertyReference (ref) istrue , then- Let thisValue be
GetThisValue (ref).
- Let thisValue be
- Else the base of ref is an
Environment Record ,- Let refEnv be
GetBase (ref). - Let thisValue be refEnv.WithBaseObject().
- Let refEnv be
- If
- Else
Type (ref) is notReference ,- Let thisValue be
undefined .
- Let thisValue be
- Let argList be ArgumentListEvaluation of arguments.
ReturnIfAbrupt (argList).- If
Type (func) is not Object, throw aTypeError exception. - If
IsCallable (func) isfalse , throw aTypeError exception. - If tailPosition is
true , performPrepareForTailCall (). - Let result be
Call (func, thisValue, argList). Assert : If tailPosition istrue , the above call will not return here, but instead evaluation will continue as if the following return has already occurred.Assert : If result is not anabrupt completion , thenType (result) is anECMAScript language type .- Return result.
12.3.5 The super Keyword
12.3.5.1 Runtime Semantics: Evaluation
- Let propertyNameReference be the result of evaluating
Expression . - Let propertyNameValue be ?
GetValue (propertyNameReference). - Let propertyKey be ?
ToPropertyKey (propertyNameValue). - If the code matched by this
SuperProperty isstrict mode code , let strict betrue , else let strict befalse . - Return ?
MakeSuperPropertyReference (propertyKey, strict).
- Let propertyKey be StringValue of
IdentifierName . - If the code matched by this
SuperProperty isstrict mode code , let strict betrue , else let strict befalse . - Return ?
MakeSuperPropertyReference (propertyKey, strict).
- Let newTarget be
GetNewTarget (). Assert :Type (newTarget) is Object.- Let func be ?
GetSuperConstructor (). - Let argList be ArgumentListEvaluation of
Arguments . ReturnIfAbrupt (argList).- Let result be ?
Construct (func, argList, newTarget). - Let thisER be
GetThisEnvironment (). - Return ? thisER.BindThisValue(result).
12.3.5.2 Runtime Semantics: GetSuperConstructor ( )
The abstract operation GetSuperConstructor performs the following steps:
- Let envRec be
GetThisEnvironment (). Assert : envRec is afunction Environment Record .- Let activeFunction be envRec.[[FunctionObject]].
Assert : activeFunction is an ECMAScriptfunction object .- Let superConstructor be ! activeFunction.[[GetPrototypeOf]]().
- If
IsConstructor (superConstructor) isfalse , throw aTypeError exception. - Return superConstructor.
12.3.5.3 Runtime Semantics: MakeSuperPropertyReference ( propertyKey, strict )
The abstract operation MakeSuperPropertyReference with arguments propertyKey and strict performs the following steps:
- Let env be
GetThisEnvironment (). Assert : env.HasSuperBinding() istrue .- Let actualThis be ? env.GetThisBinding().
- Let baseValue be ? env.GetSuperBase().
- Let bv be ?
RequireObjectCoercible (baseValue). - Return a value of type
Reference that is aSuper Reference whose base value component is bv, whose referenced name component is propertyKey, whose thisValue component is actualThis, and whose strict reference flag is strict.
12.3.6 Argument Lists
The evaluation of an argument list produces a
12.3.6.1 Runtime Semantics: ArgumentListEvaluation
- Return a new empty
List .
- Let ref be the result of evaluating
AssignmentExpression . - Let arg be ?
GetValue (ref). - Return a
List whose sole item is arg.
- Let list be a new empty
List . - Let spreadRef be the result of evaluating
AssignmentExpression . - Let spreadObj be ?
GetValue (spreadRef). - Let iteratorRecord be ?
GetIterator (spreadObj). - Repeat,
- Let next be ?
IteratorStep (iteratorRecord). - If next is
false , return list. - Let nextArg be ?
IteratorValue (next). - Append nextArg as the last element of list.
- Let next be ?
- Let precedingArgs be ArgumentListEvaluation of
ArgumentList . ReturnIfAbrupt (precedingArgs).- Let ref be the result of evaluating
AssignmentExpression . - Let arg be ?
GetValue (ref). - Append arg to the end of precedingArgs.
- Return precedingArgs.
- Let precedingArgs be ArgumentListEvaluation of
ArgumentList . ReturnIfAbrupt (precedingArgs).- Let spreadRef be the result of evaluating
AssignmentExpression . - Let iteratorRecord be ?
GetIterator (?GetValue (spreadRef)). - Repeat,
- Let next be ?
IteratorStep (iteratorRecord). - If next is
false , return precedingArgs. - Let nextArg be ?
IteratorValue (next). - Append nextArg as the last element of precedingArgs.
- Let next be ?
12.3.7 Tagged Templates
A tagged template is a function call where the arguments of the call are derived from a
12.3.7.1 Runtime Semantics: Evaluation
- Let tagRef be the result of evaluating
MemberExpression . - Let tagFunc be ?
GetValue (tagRef). - Let thisCall be this
MemberExpression . - Let tailCall be
IsInTailPosition (thisCall). - Return ?
EvaluateCall (tagFunc, tagRef,TemplateLiteral , tailCall).
- Let tagRef be the result of evaluating
CallExpression . - Let tagFunc be ?
GetValue (tagRef). - Let thisCall be this
CallExpression . - Let tailCall be
IsInTailPosition (thisCall). - Return ?
EvaluateCall (tagFunc, tagRef,TemplateLiteral , tailCall).
12.3.8 Meta Properties
12.3.8.1 Runtime Semantics: Evaluation
- Return
GetNewTarget ().
12.4 Update Expressions
Syntax
12.4.1 Static Semantics: Early Errors
-
It is an early
Reference Error if IsValidSimpleAssignmentTarget ofLeftHandSideExpression isfalse .
-
It is an early
Reference Error if IsValidSimpleAssignmentTarget ofUnaryExpression isfalse .
12.4.2 Static Semantics: IsFunctionDefinition
- Return
false .
12.4.3 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.4.4 Postfix Increment Operator
12.4.4.1 Runtime Semantics: Evaluation
- Let lhs be the result of evaluating
LeftHandSideExpression . - Let oldValue be ?
ToNumber (?GetValue (lhs)). - Let newValue be the result of adding the value 1 to oldValue, using the same rules as for the
+operator (see12.8.5 ). - Perform ?
PutValue (lhs, newValue). - Return oldValue.
12.4.5 Postfix Decrement Operator
12.4.5.1 Runtime Semantics: Evaluation
- Let lhs be the result of evaluating
LeftHandSideExpression . - Let oldValue be ?
ToNumber (?GetValue (lhs)). - Let newValue be the result of subtracting the value 1 from oldValue, using the same rules as for the
-operator (see12.8.5 ). - Perform ?
PutValue (lhs, newValue). - Return oldValue.
12.4.6 Prefix Increment Operator
12.4.6.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Let oldValue be ?
ToNumber (?GetValue (expr)). - Let newValue be the result of adding the value 1 to oldValue, using the same rules as for the
+operator (see12.8.5 ). - Perform ?
PutValue (expr, newValue). - Return newValue.
12.4.7 Prefix Decrement Operator
12.4.7.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Let oldValue be ?
ToNumber (?GetValue (expr)). - Let newValue be the result of subtracting the value 1 from oldValue, using the same rules as for the
-operator (see12.8.5 ). - Perform ?
PutValue (expr, newValue). - Return newValue.
12.5 Unary Operators
Syntax
12.5.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.5.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.5.3 The delete Operator
12.5.3.1 Static Semantics: Early Errors
-
It is a Syntax Error if the
UnaryExpression is contained instrict mode code and the derivedUnaryExpression isPrimaryExpression : IdentifierReference -
It is a Syntax Error if the derived
UnaryExpression is
PrimaryExpression : CoverParenthesizedExpressionAndArrowParameterList
andCoverParenthesizedExpressionAndArrowParameterList ultimately derives a phrase that, if used in place ofUnaryExpression , would produce a Syntax Error according to these rules. This rule is recursively applied.
The last rule means that expressions such as delete (((foo))) produce early errors because of recursive application of the first rule.
12.5.3.2 Runtime Semantics: Evaluation
- Let ref be the result of evaluating
UnaryExpression . ReturnIfAbrupt (ref).- If
Type (ref) is notReference , returntrue . - If
IsUnresolvableReference (ref) istrue , thenAssert :IsStrictReference (ref) isfalse .- Return
true .
- If
IsPropertyReference (ref) istrue , then- If
IsSuperReference (ref) istrue , throw aReferenceError exception. - Let baseObj be !
ToObject (GetBase (ref)). - Let deleteStatus be ? baseObj.[[Delete]](
GetReferencedName (ref)). - If deleteStatus is
false andIsStrictReference (ref) istrue , throw aTypeError exception. - Return deleteStatus.
- If
- Else ref is a
Reference to anEnvironment Record binding,- Let bindings be
GetBase (ref). - Return ? bindings.DeleteBinding(
GetReferencedName (ref)).
- Let bindings be
When a delete operator occurs within delete operator occurs within
12.5.4 The void Operator
12.5.4.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Perform ?
GetValue (expr). - Return
undefined .
12.5.5 The typeof Operator
12.5.5.1 Runtime Semantics: Evaluation
- Let val be the result of evaluating
UnaryExpression . - If
Type (val) isReference , then- If
IsUnresolvableReference (val) istrue , return"undefined".
- If
- Set val to ?
GetValue (val). - Return a String according to
Table 35 .
| Type of val | Result |
|---|---|
| Undefined |
"undefined"
|
| Null |
"object"
|
| Boolean |
"boolean"
|
| Number |
"number"
|
| String |
"string"
|
| Symbol |
"symbol"
|
| Object (ordinary and does not implement [[Call]]) |
"object"
|
| Object (standard exotic and does not implement [[Call]]) |
"object"
|
| Object (implements [[Call]]) |
"function"
|
| Object (non-standard exotic and does not implement [[Call]]) |
Implementation-defined. Must not be "undefined", "boolean", "function", "number", "symbol", or "string".
|
Implementations are discouraged from defining new typeof result values for non-standard exotic objects. If possible "object" should be used for such objects.
12.5.6 Unary + Operator
The unary + operator converts its operand to Number type.
12.5.6.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Return ?
ToNumber (?GetValue (expr)).
12.5.7 Unary - Operator
The unary - operator converts its operand to Number type and then negates it. Negating
12.5.7.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Let oldValue be ?
ToNumber (?GetValue (expr)). - If oldValue is
NaN , returnNaN . - Return the result of negating oldValue; that is, compute a Number with the same magnitude but opposite sign.
12.5.8 Bitwise NOT Operator ( ~ )
12.5.8.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Let oldValue be ?
ToInt32 (?GetValue (expr)). - Return the result of applying bitwise complement to oldValue. The result is a signed 32-bit
integer .
12.5.9 Logical NOT Operator ( ! )
12.5.9.1 Runtime Semantics: Evaluation
- Let expr be the result of evaluating
UnaryExpression . - Let oldValue be
ToBoolean (?GetValue (expr)). - If oldValue is
true , returnfalse . - Return
true .
12.6 Exponentiation Operator
Syntax
12.6.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.6.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.6.3 Runtime Semantics: Evaluation
- Let left be the result of evaluating
UpdateExpression . - Let leftValue be ?
GetValue (left). - Let right be the result of evaluating
ExponentiationExpression . - Let rightValue be ?
GetValue (right). - Let base be ?
ToNumber (leftValue). - Let exponent be ?
ToNumber (rightValue). - Return the result of
Applying the ** operator with base and exponent as specified in12.6.4 .
12.6.4 Applying the ** Operator
Returns an implementation-dependent approximation of the result of raising base to the power exponent.
- If exponent is
NaN , the result isNaN . - If exponent is
+0 , the result is 1, even if base isNaN . - If exponent is
-0 , the result is 1, even if base isNaN . - If base is
NaN and exponent is nonzero, the result isNaN . - If
abs (base) > 1 and exponent is+∞ , the result is+∞ . - If
abs (base) > 1 and exponent is-∞ , the result is+0 . - If
abs (base) is 1 and exponent is+∞ , the result isNaN . - If
abs (base) is 1 and exponent is-∞ , the result isNaN . - If
abs (base) < 1 and exponent is+∞ , the result is+0 . - If
abs (base) < 1 and exponent is-∞ , the result is+∞ . - If base is
+∞ and exponent > 0, the result is+∞ . - If base is
+∞ and exponent < 0, the result is+0 . - If base is
-∞ and exponent > 0 and exponent is an oddinteger , the result is-∞ . - If base is
-∞ and exponent > 0 and exponent is not an oddinteger , the result is+∞ . - If base is
-∞ and exponent < 0 and exponent is an oddinteger , the result is-0 . - If base is
-∞ and exponent < 0 and exponent is not an oddinteger , the result is+0 . - If base is
+0 and exponent > 0, the result is+0 . - If base is
+0 and exponent < 0, the result is+∞ . - If base is
-0 and exponent > 0 and exponent is an oddinteger , the result is-0 . - If base is
-0 and exponent > 0 and exponent is not an oddinteger , the result is+0 . - If base is
-0 and exponent < 0 and exponent is an oddinteger , the result is-∞ . - If base is
-0 and exponent < 0 and exponent is not an oddinteger , the result is+∞ . - If base < 0 and base is finite and exponent is finite and exponent is not an
integer , the result isNaN .
The result of base ** exponent when base is
12.7 Multiplicative Operators
Syntax
12.7.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.7.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.7.3 Runtime Semantics: Evaluation
- Let left be the result of evaluating
MultiplicativeExpression . - Let leftValue be ?
GetValue (left). - Let right be the result of evaluating
ExponentiationExpression . - Let rightValue be ?
GetValue (right). - Let lnum be ?
ToNumber (leftValue). - Let rnum be ?
ToNumber (rightValue). - Return the result of applying the
MultiplicativeOperator (*,/, or%) to lnum and rnum as specified in12.7.3.1 ,12.7.3.2 , or12.7.3.3 .
12.7.3.1 Applying the * Operator
The *
The result of a floating-point multiplication is governed by the rules of IEEE 754-2008 binary double-precision arithmetic:
-
If either operand is
NaN , the result isNaN . - The sign of the result is positive if both operands have the same sign, negative if the operands have different signs.
-
Multiplication of an infinity by a zero results in
NaN . - Multiplication of an infinity by an infinity results in an infinity. The sign is determined by the rule already stated above.
- Multiplication of an infinity by a finite nonzero value results in a signed infinity. The sign is determined by the rule already stated above.
-
In the remaining cases, where neither an infinity nor
NaN is involved, the product is computed and rounded to the nearest representable value using IEEE 754-2008 round to nearest, ties to even mode. If the magnitude is too large to represent, the result is then an infinity of appropriate sign. If the magnitude is too small to represent, the result is then a zero of appropriate sign. The ECMAScript language requires support of gradual underflow as defined by IEEE 754-2008.
12.7.3.2 Applying the / Operator
The /
-
If either operand is
NaN , the result isNaN . - The sign of the result is positive if both operands have the same sign, negative if the operands have different signs.
-
Division of an infinity by an infinity results in
NaN . - Division of an infinity by a zero results in an infinity. The sign is determined by the rule already stated above.
- Division of an infinity by a nonzero finite value results in a signed infinity. The sign is determined by the rule already stated above.
- Division of a finite value by an infinity results in zero. The sign is determined by the rule already stated above.
-
Division of a zero by a zero results in
NaN ; division of zero by any other finite value results in zero, with the sign determined by the rule already stated above. - Division of a nonzero finite value by a zero results in a signed infinity. The sign is determined by the rule already stated above.
-
In the remaining cases, where neither an infinity, nor a zero, nor
NaN is involved, the quotient is computed and rounded to the nearest representable value using IEEE 754-2008 round to nearest, ties to even mode. If the magnitude is too large to represent, the operation overflows; the result is then an infinity of appropriate sign. If the magnitude is too small to represent, the operation underflows and the result is a zero of the appropriate sign. The ECMAScript language requires support of gradual underflow as defined by IEEE 754-2008.
12.7.3.3 Applying the % Operator
The %
In C and C++, the remainder operator accepts only integral operands; in ECMAScript, it also accepts floating-point operands.
The result of a floating-point remainder operation as computed by the % operator is not the same as the “remainder” operation defined by IEEE 754-2008. The IEEE 754-2008 “remainder” operation computes the remainder from a rounding division, not a truncating division, and so its behaviour is not analogous to that of the usual % on floating-point operations to behave in a manner analogous to that of the Java
The result of an ECMAScript floating-point remainder operation is determined by the rules of IEEE arithmetic:
-
If either operand is
NaN , the result isNaN . - The sign of the result equals the sign of the dividend.
-
If the dividend is an infinity, or the divisor is a zero, or both, the result is
NaN . - If the dividend is finite and the divisor is an infinity, the result equals the dividend.
- If the dividend is a zero and the divisor is nonzero and finite, the result is the same as the dividend.
-
In the remaining cases, where neither an infinity, nor a zero, nor
NaN is involved, the floating-point remainder r from a dividend n and a divisor d is defined by the mathematical relation r = n - (d × q) where q is aninteger that is negative only if n/d is negative and positive only if n/d is positive, and whose magnitude is as large as possible without exceeding the magnitude of the true mathematical quotient of n and d. r is computed and rounded to the nearest representable value using IEEE 754-2008 round to nearest, ties to even mode.
12.8 Additive Operators
Syntax
12.8.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.8.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.8.3 The Addition Operator ( + )
The addition operator either performs string concatenation or numeric addition.
12.8.3.1 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
AdditiveExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
MultiplicativeExpression . - Let rval be ?
GetValue (rref). - Let lprim be ?
ToPrimitive (lval). - Let rprim be ?
ToPrimitive (rval). - If
Type (lprim) is String orType (rprim) is String, then- Let lstr be ?
ToString (lprim). - Let rstr be ?
ToString (rprim). - Return the
string-concatenation of lstr and rstr.
- Let lstr be ?
- Let lnum be ?
ToNumber (lprim). - Let rnum be ?
ToNumber (rprim). - Return the result of applying the addition operation to lnum and rnum. See the Note below
12.8.5 .
No hint is provided in the calls to
Step 7 differs from step 3 of the
12.8.4 The Subtraction Operator ( - )
12.8.4.1 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
AdditiveExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
MultiplicativeExpression . - Let rval be ?
GetValue (rref). - Let lnum be ?
ToNumber (lval). - Let rnum be ?
ToNumber (rval). - Return the result of applying the subtraction operation to lnum and rnum. See the note below
12.8.5 .
12.8.5 Applying the Additive Operators to Numbers
The + operator performs addition when applied to two operands of numeric type, producing the sum of the operands. The - operator performs subtraction, producing the difference of two numeric operands.
Addition is a commutative operation, but not always associative.
The result of an addition is determined using the rules of IEEE 754-2008 binary double-precision arithmetic:
-
If either operand is
NaN , the result isNaN . -
The sum of two infinities of opposite sign is
NaN . - The sum of two infinities of the same sign is the infinity of that sign.
- The sum of an infinity and a finite value is equal to the infinite operand.
-
The sum of two negative zeroes is
-0 . The sum of two positive zeroes, or of two zeroes of opposite sign, is+0 . - The sum of a zero and a nonzero finite value is equal to the nonzero operand.
-
The sum of two nonzero finite values of the same magnitude and opposite sign is
+0 . -
In the remaining cases, where neither an infinity, nor a zero, nor
NaN is involved, and the operands have the same sign or have different magnitudes, the sum is computed and rounded to the nearest representable value using IEEE 754-2008 round to nearest, ties to even mode. If the magnitude is too large to represent, the operation overflows and the result is then an infinity of appropriate sign. The ECMAScript language requires support of gradual underflow as defined by IEEE 754-2008.
The - operator performs subtraction when applied to two operands of numeric type, producing the difference of its operands; the left operand is the minuend and the right operand is the subtrahend. Given numeric operands a and b, it is always the case that a-b produces the same result as a+(-b).
12.9 Bitwise Shift Operators
Syntax
12.9.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.9.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.9.3 The Left Shift Operator ( << )
Performs a bitwise left shift operation on the left operand by the amount specified by the right operand.
12.9.3.1 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
ShiftExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
AdditiveExpression . - Let rval be ?
GetValue (rref). - Let lnum be ?
ToInt32 (lval). - Let rnum be ?
ToUint32 (rval). - Let shiftCount be the result of masking out all but the least significant 5 bits of rnum, that is, compute rnum & 0x1F.
- Return the result of left shifting lnum by shiftCount bits. The result is a signed 32-bit
integer .
12.9.4 The Signed Right Shift Operator ( >> )
Performs a sign-filling bitwise right shift operation on the left operand by the amount specified by the right operand.
12.9.4.1 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
ShiftExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
AdditiveExpression . - Let rval be ?
GetValue (rref). - Let lnum be ?
ToInt32 (lval). - Let rnum be ?
ToUint32 (rval). - Let shiftCount be the result of masking out all but the least significant 5 bits of rnum, that is, compute rnum & 0x1F.
- Return the result of performing a sign-extending right shift of lnum by shiftCount bits. The most significant bit is propagated. The result is a signed 32-bit
integer .
12.9.5 The Unsigned Right Shift Operator ( >>> )
Performs a zero-filling bitwise right shift operation on the left operand by the amount specified by the right operand.
12.9.5.1 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
ShiftExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
AdditiveExpression . - Let rval be ?
GetValue (rref). - Let lnum be ?
ToUint32 (lval). - Let rnum be ?
ToUint32 (rval). - Let shiftCount be the result of masking out all but the least significant 5 bits of rnum, that is, compute rnum & 0x1F.
- Return the result of performing a zero-filling right shift of lnum by shiftCount bits. Vacated bits are filled with zero. The result is an unsigned 32-bit
integer .
12.10 Relational Operators
The result of evaluating a relational operator is always of type Boolean, reflecting whether the relationship named by the operator holds between its two operands.
Syntax
The [In] grammar parameter is needed to avoid confusing the in operator in a relational expression with the in operator in a for statement.
12.10.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.10.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.10.3 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
RelationalExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
ShiftExpression . - Let rval be ?
GetValue (rref). - Let r be the result of performing
Abstract Relational Comparison lval < rval. ReturnIfAbrupt (r).- If r is
undefined , returnfalse . Otherwise, return r.
- Let lref be the result of evaluating
RelationalExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
ShiftExpression . - Let rval be ?
GetValue (rref). - Let r be the result of performing
Abstract Relational Comparison rval < lval with LeftFirst equal tofalse . ReturnIfAbrupt (r).- If r is
undefined , returnfalse . Otherwise, return r.
- Let lref be the result of evaluating
RelationalExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
ShiftExpression . - Let rval be ?
GetValue (rref). - Let r be the result of performing
Abstract Relational Comparison rval < lval with LeftFirst equal tofalse . ReturnIfAbrupt (r).- If r is
true orundefined , returnfalse . Otherwise, returntrue .
- Let lref be the result of evaluating
RelationalExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
ShiftExpression . - Let rval be ?
GetValue (rref). - Let r be the result of performing
Abstract Relational Comparison lval < rval. ReturnIfAbrupt (r).- If r is
true orundefined , returnfalse . Otherwise, returntrue .
- Let lref be the result of evaluating
RelationalExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
ShiftExpression . - Let rval be ?
GetValue (rref). - Return ?
InstanceofOperator (lval, rval).
- Let lref be the result of evaluating
RelationalExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
ShiftExpression . - Let rval be ?
GetValue (rref). - If
Type (rval) is not Object, throw aTypeError exception. - Return ?
HasProperty (rval,ToPropertyKey (lval)).
12.10.4 Runtime Semantics: InstanceofOperator ( V, target )
The abstract operation InstanceofOperator(V, target) implements the generic algorithm for determining if ECMAScript value V is an instance of object target either by consulting target's @@hasinstance method or, if absent, determining whether the value of target's prototype property is present in V's prototype chain. This abstract operation performs the following steps:
- If
Type (target) is not Object, throw aTypeError exception. - Let instOfHandler be ?
GetMethod (target, @@hasInstance). - If instOfHandler is not
undefined , then - If
IsCallable (target) isfalse , throw aTypeError exception. - Return ?
OrdinaryHasInstance (target, V).
Steps 4 and 5 provide compatibility with previous editions of ECMAScript that did not use a @@hasInstance method to define the instanceof operator semantics. If an object does not define or inherit @@hasInstance it uses the default instanceof semantics.
12.11 Equality Operators
The result of evaluating an equality operator is always of type Boolean, reflecting whether the relationship named by the operator holds between its two operands.
Syntax
12.11.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.11.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.11.3 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
EqualityExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
RelationalExpression . - Let rval be ?
GetValue (rref). - Return the result of performing
Abstract Equality Comparison rval == lval.
- Let lref be the result of evaluating
EqualityExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
RelationalExpression . - Let rval be ?
GetValue (rref). - Let r be the result of performing
Abstract Equality Comparison rval == lval. - If r is
true , returnfalse . Otherwise, returntrue .
- Let lref be the result of evaluating
EqualityExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
RelationalExpression . - Let rval be ?
GetValue (rref). - Return the result of performing
Strict Equality Comparison rval === lval.
- Let lref be the result of evaluating
EqualityExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
RelationalExpression . - Let rval be ?
GetValue (rref). - Let r be the result of performing
Strict Equality Comparison rval === lval. - If r is
true , returnfalse . Otherwise, returntrue .
Given the above definition of equality:
-
String comparison can be forced by:
"" + a == "" + b. -
Numeric comparison can be forced by:
+a == +b. -
Boolean comparison can be forced by:
!a == !b.
The equality operators maintain the following invariants:
-
A != Bis equivalent to!(A == B). -
A == Bis equivalent toB == A, except in the order of evaluation ofAandB.
The equality operator is not always transitive. For example, there might be two distinct String objects, each representing the same String value; each String object would be considered equal to the String value by the == operator, but the two String objects would not be equal to each other. For example:
-
new String("a") == "a"and"a" == new String("a")are bothtrue . -
new String("a") == new String("a")isfalse .
Comparison of Strings uses a simple equality test on sequences of code unit values. There is no attempt to use the more complex, semantically oriented definitions of character or string equality and collating order defined in the Unicode specification. Therefore Strings values that are canonically equal according to the Unicode standard could test as unequal. In effect this algorithm assumes that both Strings are already in normalized form.
12.12 Binary Bitwise Operators
Syntax
12.12.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.12.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.12.3 Runtime Semantics: Evaluation
The production
- Let lref be the result of evaluating A.
- Let lval be ?
GetValue (lref). - Let rref be the result of evaluating B.
- Let rval be ?
GetValue (rref). - Let lnum be ?
ToInt32 (lval). - Let rnum be ?
ToInt32 (rval). - Return the result of applying the bitwise operator @ to lnum and rnum. The result is a signed 32-bit
integer .
12.13 Binary Logical Operators
Syntax
The value produced by a && or || operator is not necessarily of type Boolean. The value produced will always be the value of one of the two operand expressions.
12.13.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.13.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.13.3 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
LogicalANDExpression . - Let lval be ?
GetValue (lref). - Let lbool be
ToBoolean (lval). - If lbool is
false , return lval. - Let rref be the result of evaluating
BitwiseORExpression . - Return ?
GetValue (rref).
- Let lref be the result of evaluating
LogicalORExpression . - Let lval be ?
GetValue (lref). - Let lbool be
ToBoolean (lval). - If lbool is
true , return lval. - Let rref be the result of evaluating
LogicalANDExpression . - Return ?
GetValue (rref).
12.14 Conditional Operator ( ? : )
Syntax
The grammar for a
12.14.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.14.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.14.3 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
LogicalORExpression . - Let lval be
ToBoolean (?GetValue (lref)). - If lval is
true , then- Let trueRef be the result of evaluating the first
AssignmentExpression . - Return ?
GetValue (trueRef).
- Let trueRef be the result of evaluating the first
- Else,
- Let falseRef be the result of evaluating the second
AssignmentExpression . - Return ?
GetValue (falseRef).
- Let falseRef be the result of evaluating the second
12.15 Assignment Operators
Syntax
12.15.1 Static Semantics: Early Errors
-
It is a Syntax Error if
LeftHandSideExpression is either anObjectLiteral or anArrayLiteral andLeftHandSideExpression is notcovering anAssignmentPattern . -
It is an early
Reference Error ifLeftHandSideExpression is neither anObjectLiteral nor anArrayLiteral and IsValidSimpleAssignmentTarget ofLeftHandSideExpression isfalse .
-
It is an early
Reference Error if IsValidSimpleAssignmentTarget ofLeftHandSideExpression isfalse .
12.15.2 Static Semantics: IsFunctionDefinition
- Return
true .
- Return
false .
12.15.3 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.15.4 Runtime Semantics: Evaluation
- If
LeftHandSideExpression is neither anObjectLiteral nor anArrayLiteral , then- Let lref be the result of evaluating
LeftHandSideExpression . ReturnIfAbrupt (lref).- Let rref be the result of evaluating
AssignmentExpression . - Let rval be ?
GetValue (rref). - If
IsAnonymousFunctionDefinition (AssignmentExpression ) and IsIdentifierRef ofLeftHandSideExpression are bothtrue , then- Let hasNameProperty be ?
HasOwnProperty (rval,"name"). - If hasNameProperty is
false , performSetFunctionName (rval,GetReferencedName (lref)).
- Let hasNameProperty be ?
- Perform ?
PutValue (lref, rval). - Return rval.
- Let lref be the result of evaluating
- Let assignmentPattern be the
AssignmentPattern that iscovered byLeftHandSideExpression . - Let rref be the result of evaluating
AssignmentExpression . - Let rval be ?
GetValue (rref). - Perform ? DestructuringAssignmentEvaluation of assignmentPattern using rval as the argument.
- Return rval.
- Let lref be the result of evaluating
LeftHandSideExpression . - Let lval be ?
GetValue (lref). - Let rref be the result of evaluating
AssignmentExpression . - Let rval be ?
GetValue (rref). - Let op be the
@whereAssignmentOperator is@=. - Let r be the result of applying op to lval and rval as if evaluating the expression lval op rval.
- Perform ?
PutValue (lref, r). - Return r.
When an assignment occurs within
12.15.5 Destructuring Assignment
Supplemental Syntax
In certain circumstances when processing an instance of the production
12.15.5.1 Static Semantics: Early Errors
-
It is a Syntax Error if IsValidSimpleAssignmentTarget of
IdentifierReference isfalse .
-
It is a Syntax Error if
DestructuringAssignmentTarget is anArrayLiteral or anObjectLiteral .
-
It is a Syntax Error if
LeftHandSideExpression is either anObjectLiteral or anArrayLiteral and ifLeftHandSideExpression is notcovering anAssignmentPattern . -
It is a Syntax Error if
LeftHandSideExpression is neither anObjectLiteral nor anArrayLiteral and IsValidSimpleAssignmentTarget(LeftHandSideExpression ) isfalse .
12.15.5.2 Runtime Semantics: DestructuringAssignmentEvaluation
With parameter value.
- Perform ?
RequireObjectCoercible (value). - Return
NormalCompletion (empty ).
- Perform ?
RequireObjectCoercible (value). - Perform ? PropertyDestructuringAssignmentEvaluation for
AssignmentPropertyList using value as the argument. - Return
NormalCompletion (empty ).
- Let iteratorRecord be ?
GetIterator (value). - Return ?
IteratorClose (iteratorRecord,NormalCompletion (empty )).
- Let iteratorRecord be ?
GetIterator (value). - Let result be the result of performing IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument. - If iteratorRecord.[[Done]] is
false , return ?IteratorClose (iteratorRecord, result). - Return result.
- Let iteratorRecord be ?
GetIterator (value). - If
Elision is present, then- Let status be the result of performing IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument. - If status is an
abrupt completion , thenAssert : iteratorRecord.[[Done]] istrue .- Return
Completion (status).
- Let status be the result of performing IteratorDestructuringAssignmentEvaluation of
- Let result be the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentRestElement with iteratorRecord as the argument. - If iteratorRecord.[[Done]] is
false , return ?IteratorClose (iteratorRecord, result). - Return result.
- Let iteratorRecord be ?
GetIterator (value). - Let result be the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentElementList using iteratorRecord as the argument. - If iteratorRecord.[[Done]] is
false , return ?IteratorClose (iteratorRecord, result). - Return result.
- Let iteratorRecord be ?
GetIterator (value). - Let status be the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentElementList using iteratorRecord as the argument. - If status is an
abrupt completion , then- If iteratorRecord.[[Done]] is
false , return ?IteratorClose (iteratorRecord, status). - Return
Completion (status).
- If iteratorRecord.[[Done]] is
- If
Elision is present, then- Set status to the result of performing IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument. - If status is an
abrupt completion , thenAssert : iteratorRecord.[[Done]] istrue .- Return
Completion (status).
- Set status to the result of performing IteratorDestructuringAssignmentEvaluation of
- If
AssignmentRestElement is present, then- Set status to the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentRestElement with iteratorRecord as the argument.
- Set status to the result of performing IteratorDestructuringAssignmentEvaluation of
- If iteratorRecord.[[Done]] is
false , return ?IteratorClose (iteratorRecord, status). - Return
Completion (status).
- Let excludedNames be a new empty
List . - Return the result of performing RestDestructuringAssignmentEvaluation of
AssignmentRestProperty with value and excludedNames as the arguments.
- Let excludedNames be the result of performing ? PropertyDestructuringAssignmentEvaluation for
AssignmentPropertyList using value as the argument. - Return the result of performing RestDestructuringAssignmentEvaluation of
AssignmentRestProperty with value and excludedNames as the arguments.
12.15.5.3 Runtime Semantics: PropertyDestructuringAssignmentEvaluation
With parameter value.
- Let propertyNames be the result of performing ? PropertyDestructuringAssignmentEvaluation for
AssignmentPropertyList using value as the argument. - Let nextNames be the result of performing ? PropertyDestructuringAssignmentEvaluation for
AssignmentProperty using value as the argument. - Append each item in nextNames to the end of propertyNames.
- Return propertyNames.
- Let P be StringValue of
IdentifierReference . - Let lref be ?
ResolveBinding (P). - Let v be ?
GetV (value, P). - If
Initializer is present and v isopt undefined , then- Let defaultValue be the result of evaluating
Initializer . - Set v to ?
GetValue (defaultValue). - If
IsAnonymousFunctionDefinition (Initializer ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (v,"name"). - If hasNameProperty is
false , performSetFunctionName (v, P).
- Let hasNameProperty be ?
- Let defaultValue be the result of evaluating
- Perform ?
PutValue (lref, v). - Return a new
List containing P.
- Let name be the result of evaluating
PropertyName . ReturnIfAbrupt (name).- Perform ? KeyedDestructuringAssignmentEvaluation of
AssignmentElement with value and name as the arguments. - Return a new
List containing name.
12.15.5.4 Runtime Semantics: RestDestructuringAssignmentEvaluation
With parameters value and excludedNames.
- Let lref be the result of evaluating
DestructuringAssignmentTarget . ReturnIfAbrupt (lref).- Let restObj be
ObjectCreate (%ObjectPrototype% ). - Perform ?
CopyDataProperties (restObj, value, excludedNames). - Return
PutValue (lref, restObj).
12.15.5.5 Runtime Semantics: IteratorDestructuringAssignmentEvaluation
With parameter iteratorRecord.
- Return the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentElisionElement using iteratorRecord as the argument.
- Perform ? IteratorDestructuringAssignmentEvaluation of
AssignmentElementList using iteratorRecord as the argument. - Return the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentElisionElement using iteratorRecord as the argument.
- Return the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentElement with iteratorRecord as the argument.
- Perform ? IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument. - Return the result of performing IteratorDestructuringAssignmentEvaluation of
AssignmentElement with iteratorRecord as the argument.
- If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue .
- Let next be
- Return
NormalCompletion (empty ).
- Perform ? IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument. - If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue .
- Let next be
- Return
NormalCompletion (empty ).
- If
DestructuringAssignmentTarget is neither anObjectLiteral nor anArrayLiteral , then- Let lref be the result of evaluating
DestructuringAssignmentTarget . ReturnIfAbrupt (lref).
- Let lref be the result of evaluating
- If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue . - Else,
- Let value be
IteratorValue (next). - If value is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (value).
- Let value be
- Let next be
- If iteratorRecord.[[Done]] is
true , let value beundefined . - If
Initializer is present and value isundefined , then- Let defaultValue be the result of evaluating
Initializer . - Let v be ?
GetValue (defaultValue).
- Let defaultValue be the result of evaluating
- Else, let v be value.
- If
DestructuringAssignmentTarget is anObjectLiteral or anArrayLiteral , then- Let nestedAssignmentPattern be the
AssignmentPattern that iscovered byDestructuringAssignmentTarget . - Return the result of performing DestructuringAssignmentEvaluation of nestedAssignmentPattern with v as the argument.
- Let nestedAssignmentPattern be the
- If
Initializer is present and value isundefined andIsAnonymousFunctionDefinition (Initializer ) and IsIdentifierRef ofDestructuringAssignmentTarget are bothtrue , then- Let hasNameProperty be ?
HasOwnProperty (v,"name"). - If hasNameProperty is
false , performSetFunctionName (v,GetReferencedName (lref)).
- Let hasNameProperty be ?
- Return ?
PutValue (lref, v).
Left to right evaluation order is maintained by evaluating a
- If
DestructuringAssignmentTarget is neither anObjectLiteral nor anArrayLiteral , then- Let lref be the result of evaluating
DestructuringAssignmentTarget . ReturnIfAbrupt (lref).
- Let lref be the result of evaluating
- Let A be !
ArrayCreate (0). - Let n be 0.
- Repeat, while iteratorRecord.[[Done]] is
false ,- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue . - Else,
- Let nextValue be
IteratorValue (next). - If nextValue is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (nextValue).- Let status be
CreateDataProperty (A, !ToString (n), nextValue). Assert : status istrue .- Increment n by 1.
- Let nextValue be
- Let next be
- If
DestructuringAssignmentTarget is neither anObjectLiteral nor anArrayLiteral , then- Return ?
PutValue (lref, A).
- Return ?
- Let nestedAssignmentPattern be the
AssignmentPattern that iscovered byDestructuringAssignmentTarget . - Return the result of performing DestructuringAssignmentEvaluation of nestedAssignmentPattern with A as the argument.
12.15.5.6 Runtime Semantics: KeyedDestructuringAssignmentEvaluation
With parameters value and propertyName.
- If
DestructuringAssignmentTarget is neither anObjectLiteral nor anArrayLiteral , then- Let lref be the result of evaluating
DestructuringAssignmentTarget . ReturnIfAbrupt (lref).
- Let lref be the result of evaluating
- Let v be ?
GetV (value, propertyName). - If
Initializer is present and v isundefined , then- Let defaultValue be the result of evaluating
Initializer . - Let rhsValue be ?
GetValue (defaultValue).
- Let defaultValue be the result of evaluating
- Else, let rhsValue be v.
- If
DestructuringAssignmentTarget is anObjectLiteral or anArrayLiteral , then- Let assignmentPattern be the
AssignmentPattern that iscovered byDestructuringAssignmentTarget . - Return the result of performing DestructuringAssignmentEvaluation of assignmentPattern with rhsValue as the argument.
- Let assignmentPattern be the
- If
Initializer is present and v isundefined andIsAnonymousFunctionDefinition (Initializer ) and IsIdentifierRef ofDestructuringAssignmentTarget are bothtrue , then- Let hasNameProperty be ?
HasOwnProperty (rhsValue,"name"). - If hasNameProperty is
false , performSetFunctionName (rhsValue,GetReferencedName (lref)).
- Let hasNameProperty be ?
- Return ?
PutValue (lref, rhsValue).
12.16 Comma Operator ( , )
Syntax
12.16.1 Static Semantics: IsFunctionDefinition
- Return
false .
12.16.2 Static Semantics: IsValidSimpleAssignmentTarget
- Return
false .
12.16.3 Runtime Semantics: Evaluation
- Let lref be the result of evaluating
Expression . - Perform ?
GetValue (lref). - Let rref be the result of evaluating
AssignmentExpression . - Return ?
GetValue (rref).
13 ECMAScript Language: Statements and Declarations
Syntax
13.1 Statement Semantics
13.1.1 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return
false .
13.1.2 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return
false .
13.1.3 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return
false .
- Let newIterationSet be a copy of iterationSet with all the elements of labelSet appended.
- Return ContainsUndefinedContinueTarget of
IterationStatement with arguments newIterationSet and « ».
13.1.4 Static Semantics: DeclarationPart
- Return
FunctionDeclaration .
- Return
GeneratorDeclaration .
- Return
AsyncFunctionDeclaration .
- Return
AsyncGeneratorDeclaration .
- Return
ClassDeclaration .
- Return
LexicalDeclaration .
13.1.5 Static Semantics: VarDeclaredNames
- Return a new empty
List .
13.1.6 Static Semantics: VarScopedDeclarations
- Return a new empty
List .
13.1.7 Runtime Semantics: LabelledEvaluation
With parameter labelSet.
- Let stmtResult be the result of performing LabelledEvaluation of
IterationStatement with argument labelSet. - If stmtResult.[[Type]] is
break , then- If stmtResult.[[Target]] is
empty , then- If stmtResult.[[Value]] is
empty , set stmtResult toNormalCompletion (undefined ). - Else, set stmtResult to
NormalCompletion (stmtResult.[[Value]]).
- If stmtResult.[[Value]] is
- If stmtResult.[[Target]] is
- Return
Completion (stmtResult).
- Let stmtResult be the result of evaluating
SwitchStatement . - If stmtResult.[[Type]] is
break , then- If stmtResult.[[Target]] is
empty , then- If stmtResult.[[Value]] is
empty , set stmtResult toNormalCompletion (undefined ). - Else, set stmtResult to
NormalCompletion (stmtResult.[[Value]]).
- If stmtResult.[[Value]] is
- If stmtResult.[[Target]] is
- Return
Completion (stmtResult).
A
13.1.8 Runtime Semantics: Evaluation
- Return
NormalCompletion (empty ).
- Return the result of evaluating
FunctionDeclaration .
- Let newLabelSet be a new empty
List . - Return the result of performing LabelledEvaluation of this
BreakableStatement with argument newLabelSet.
13.2 Block
Syntax
13.2.1 Static Semantics: Early Errors
-
It is a Syntax Error if the LexicallyDeclaredNames of
StatementList contains any duplicate entries. -
It is a Syntax Error if any element of the LexicallyDeclaredNames of
StatementList also occurs in the VarDeclaredNames ofStatementList .
13.2.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return
false .
- Let hasDuplicates be ContainsDuplicateLabels of
StatementList with argument labelSet. - If hasDuplicates is
true , returntrue . - Return ContainsDuplicateLabels of
StatementListItem with argument labelSet.
- Return
false .
13.2.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return
false .
- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of
StatementList with argument labelSet. - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedBreakTarget of
StatementListItem with argument labelSet.
- Return
false .
13.2.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return
false .
- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of
StatementList with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedContinueTarget of
StatementListItem with arguments iterationSet and « ».
- Return
false .
13.2.5 Static Semantics: LexicallyDeclaredNames
- Return a new empty
List .
- Let names be LexicallyDeclaredNames of
StatementList . - Append to names the elements of the LexicallyDeclaredNames of
StatementListItem . - Return names.
- If
Statement isStatement : LabelledStatement LabelledStatement . - Return a new empty
List .
- Return the BoundNames of
Declaration .
13.2.6 Static Semantics: LexicallyScopedDeclarations
- Let declarations be LexicallyScopedDeclarations of
StatementList . - Append to declarations the elements of the LexicallyScopedDeclarations of
StatementListItem . - Return declarations.
- If
Statement isStatement : LabelledStatement LabelledStatement . - Return a new empty
List .
- Return a new
List containing DeclarationPart ofDeclaration .
13.2.7 Static Semantics: TopLevelLexicallyDeclaredNames
- Let names be TopLevelLexicallyDeclaredNames of
StatementList . - Append to names the elements of the TopLevelLexicallyDeclaredNames of
StatementListItem . - Return names.
- Return a new empty
List .
- If
Declaration isDeclaration : HoistableDeclaration - Return « ».
- Return the BoundNames of
Declaration .
At the top level of a function, or script, function declarations are treated like var declarations rather than like lexical declarations.
13.2.8 Static Semantics: TopLevelLexicallyScopedDeclarations
- Return a new empty
List .
- Let declarations be TopLevelLexicallyScopedDeclarations of
StatementList . - Append to declarations the elements of the TopLevelLexicallyScopedDeclarations of
StatementListItem . - Return declarations.
- Return a new empty
List .
- If
Declaration isDeclaration : HoistableDeclaration - Return « ».
- Return a new
List containingDeclaration .
13.2.9 Static Semantics: TopLevelVarDeclaredNames
- Return a new empty
List .
- Let names be TopLevelVarDeclaredNames of
StatementList . - Append to names the elements of the TopLevelVarDeclaredNames of
StatementListItem . - Return names.
- If
Declaration isDeclaration : HoistableDeclaration - Return the BoundNames of
HoistableDeclaration .
- Return the BoundNames of
- Return a new empty
List .
- If
Statement isStatement : LabelledStatement Statement . - Return VarDeclaredNames of
Statement .
At the top level of a function or script, inner function declarations are treated like var declarations.
13.2.10 Static Semantics: TopLevelVarScopedDeclarations
- Return a new empty
List .
- Let declarations be TopLevelVarScopedDeclarations of
StatementList . - Append to declarations the elements of the TopLevelVarScopedDeclarations of
StatementListItem . - Return declarations.
- If
Statement isStatement : LabelledStatement Statement . - Return VarScopedDeclarations of
Statement .
- If
Declaration isDeclaration : HoistableDeclaration - Let declaration be DeclarationPart of
HoistableDeclaration . - Return « declaration ».
- Let declaration be DeclarationPart of
- Return a new empty
List .
13.2.11 Static Semantics: VarDeclaredNames
- Return a new empty
List .
- Let names be VarDeclaredNames of
StatementList . - Append to names the elements of the VarDeclaredNames of
StatementListItem . - Return names.
- Return a new empty
List .
13.2.12 Static Semantics: VarScopedDeclarations
- Return a new empty
List .
- Let declarations be VarScopedDeclarations of
StatementList . - Append to declarations the elements of the VarScopedDeclarations of
StatementListItem . - Return declarations.
- Return a new empty
List .
13.2.13 Runtime Semantics: Evaluation
- Return
NormalCompletion (empty ).
- Let oldEnv be the
running execution context 's LexicalEnvironment. - Let blockEnv be
NewDeclarativeEnvironment (oldEnv). - Perform
BlockDeclarationInstantiation (StatementList , blockEnv). - Set the
running execution context 's LexicalEnvironment to blockEnv. - Let blockValue be the result of evaluating
StatementList . - Set the
running execution context 's LexicalEnvironment to oldEnv. - Return blockValue.
No matter how control leaves the
- Let sl be the result of evaluating
StatementList . ReturnIfAbrupt (sl).- Let s be the result of evaluating
StatementListItem . - Return
Completion (UpdateEmpty (s, sl)).
The value of a eval function all return the value 1:
eval("1;;;;;")
eval("1;{}")
eval("1;var a;")13.2.14 Runtime Semantics: BlockDeclarationInstantiation ( code, env )
When a
BlockDeclarationInstantiation is performed as follows using arguments code and env. code is the
- Let envRec be env's
EnvironmentRecord . Assert : envRec is a declarativeEnvironment Record .- Let declarations be the LexicallyScopedDeclarations of code.
- For each element d in declarations, do
- For each element dn of the BoundNames of d, do
- If IsConstantDeclaration of d is
true , then- Perform ! envRec.CreateImmutableBinding(dn,
true ).
- Perform ! envRec.CreateImmutableBinding(dn,
- Else,
- Perform ! envRec.CreateMutableBinding(dn,
false ).
- Perform ! envRec.CreateMutableBinding(dn,
- If IsConstantDeclaration of d is
- If d is a
FunctionDeclaration , aGeneratorDeclaration , anAsyncFunctionDeclaration , or anAsyncGeneratorDeclaration , then- Let fn be the sole element of the BoundNames of d.
- Let fo be the result of performing InstantiateFunctionObject for d with argument env.
- Perform envRec.InitializeBinding(fn, fo).
- For each element dn of the BoundNames of d, do
13.3 Declarations and the Variable Statement
13.3.1 Let and Const Declarations
let and const declarations define variables that are scoped to the let declaration does not have an
Syntax
13.3.1.1 Static Semantics: Early Errors
-
It is a Syntax Error if the BoundNames of
BindingList contains"let". -
It is a Syntax Error if the BoundNames of
BindingList contains any duplicate entries.
-
It is a Syntax Error if
Initializer is not present and IsConstantDeclaration of theLexicalDeclaration containing thisLexicalBinding istrue .
13.3.1.2 Static Semantics: BoundNames
- Return the BoundNames of
BindingList .
- Let names be the BoundNames of
BindingList . - Append to names the elements of the BoundNames of
LexicalBinding . - Return names.
- Return the BoundNames of
BindingIdentifier .
- Return the BoundNames of
BindingPattern .
13.3.1.3 Static Semantics: IsConstantDeclaration
- Return IsConstantDeclaration of
LetOrConst .
- Return
false .
- Return
true .
13.3.1.4 Runtime Semantics: Evaluation
- Let next be the result of evaluating
BindingList . ReturnIfAbrupt (next).- Return
NormalCompletion (empty ).
- Let next be the result of evaluating
BindingList . ReturnIfAbrupt (next).- Return the result of evaluating
LexicalBinding .
- Let lhs be
ResolveBinding (StringValue ofBindingIdentifier ). - Return
InitializeReferencedBinding (lhs,undefined ).
A const declaration.
- Let bindingId be StringValue of
BindingIdentifier . - Let lhs be
ResolveBinding (bindingId). - Let rhs be the result of evaluating
Initializer . - Let value be ?
GetValue (rhs). - If
IsAnonymousFunctionDefinition (Initializer ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , performSetFunctionName (value, bindingId).
- Let hasNameProperty be ?
- Return
InitializeReferencedBinding (lhs, value).
- Let rhs be the result of evaluating
Initializer . - Let value be ?
GetValue (rhs). - Let env be the
running execution context 's LexicalEnvironment. - Return the result of performing BindingInitialization for
BindingPattern using value and env as the arguments.
13.3.2 Variable Statement
A var statement declares variables that are scoped to the
Syntax
13.3.2.1 Static Semantics: BoundNames
- Let names be BoundNames of
VariableDeclarationList . - Append to names the elements of BoundNames of
VariableDeclaration . - Return names.
- Return the BoundNames of
BindingIdentifier .
- Return the BoundNames of
BindingPattern .
13.3.2.2 Static Semantics: VarDeclaredNames
- Return BoundNames of
VariableDeclarationList .
13.3.2.3 Static Semantics: VarScopedDeclarations
- Return a new
List containingVariableDeclaration .
- Let declarations be VarScopedDeclarations of
VariableDeclarationList . - Append
VariableDeclaration to declarations. - Return declarations.
13.3.2.4 Runtime Semantics: Evaluation
- Let next be the result of evaluating
VariableDeclarationList . ReturnIfAbrupt (next).- Return
NormalCompletion (empty ).
- Let next be the result of evaluating
VariableDeclarationList . ReturnIfAbrupt (next).- Return the result of evaluating
VariableDeclaration .
- Return
NormalCompletion (empty ).
- Let bindingId be StringValue of
BindingIdentifier . - Let lhs be ?
ResolveBinding (bindingId). - Let rhs be the result of evaluating
Initializer . - Let value be ?
GetValue (rhs). - If
IsAnonymousFunctionDefinition (Initializer ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , performSetFunctionName (value, bindingId).
- Let hasNameProperty be ?
- Return ?
PutValue (lhs, value).
If a
- Let rhs be the result of evaluating
Initializer . - Let rval be ?
GetValue (rhs). - Return the result of performing BindingInitialization for
BindingPattern passing rval andundefined as arguments.
13.3.3 Destructuring Binding Patterns
Syntax
13.3.3.1 Static Semantics: BoundNames
- Return a new empty
List .
- Return a new empty
List .
- Return the BoundNames of
BindingRestElement .
- Return the BoundNames of
BindingElementList .
- Let names be BoundNames of
BindingElementList . - Append to names the elements of BoundNames of
BindingRestElement . - Return names.
- Let names be BoundNames of
BindingPropertyList . - Append to names the elements of BoundNames of
BindingProperty . - Return names.
- Let names be BoundNames of
BindingElementList . - Append to names the elements of BoundNames of
BindingElisionElement . - Return names.
- Return BoundNames of
BindingElement .
- Return the BoundNames of
BindingElement .
- Return the BoundNames of
BindingIdentifier .
- Return the BoundNames of
BindingPattern .
13.3.3.2 Static Semantics: ContainsExpression
- Return
false .
- Return
false .
- Return ContainsExpression of
BindingRestElement .
- Return ContainsExpression of
BindingElementList .
- Let has be ContainsExpression of
BindingElementList . - If has is
true , returntrue . - Return ContainsExpression of
BindingRestElement .
- Let has be ContainsExpression of
BindingPropertyList . - If has is
true , returntrue . - Return ContainsExpression of
BindingProperty .
- Let has be ContainsExpression of
BindingElementList . - If has is
true , returntrue . - Return ContainsExpression of
BindingElisionElement .
- Return ContainsExpression of
BindingElement .
- Let has be IsComputedPropertyKey of
PropertyName . - If has is
true , returntrue . - Return ContainsExpression of
BindingElement .
- Return
true .
- Return
false .
- Return
true .
- Return
false .
- Return ContainsExpression of
BindingPattern .
13.3.3.3 Static Semantics: HasInitializer
- Return
false .
- Return
true .
- Return
false .
- Return
true .
13.3.3.4 Static Semantics: IsSimpleParameterList
- Return
false .
- Return
false .
- Return
true .
- Return
false .
13.3.3.5 Runtime Semantics: BindingInitialization
With parameters value and environment.
When
- Perform ?
RequireObjectCoercible (value). - Return the result of performing BindingInitialization for
ObjectBindingPattern using value and environment as arguments.
- Let iteratorRecord be ?
GetIterator (value). - Let result be IteratorBindingInitialization for
ArrayBindingPattern using iteratorRecord and environment as arguments. - If iteratorRecord.[[Done]] is
false , return ?IteratorClose (iteratorRecord, result). - Return result.
- Return
NormalCompletion (empty ).
- Perform ? PropertyBindingInitialization for
BindingPropertyList using value and environment as the arguments. - Return
NormalCompletion (empty ).
- Let excludedNames be a new empty
List . - Return the result of performing RestBindingInitialization of
BindingRestProperty with value, environment, and excludedNames as the arguments.
- Let excludedNames be the result of performing ? PropertyBindingInitialization of
BindingPropertyList using value and environment as arguments. - Return the result of performing RestBindingInitialization of
BindingRestProperty with value, environment, and excludedNames as the arguments.
13.3.3.6 Runtime Semantics: PropertyBindingInitialization
With parameters value and environment.
- Let boundNames be the result of performing ? PropertyBindingInitialization for
BindingPropertyList using value and environment as arguments. - Let nextNames be the result of performing ? PropertyBindingInitialization for
BindingProperty using value and environment as arguments. - Append each item in nextNames to the end of boundNames.
- Return boundNames.
- Let name be the string that is the only element of BoundNames of
SingleNameBinding . - Perform ? KeyedBindingInitialization for
SingleNameBinding using value, environment, and name as the arguments. - Return a new
List containing name.
- Let P be the result of evaluating
PropertyName . ReturnIfAbrupt (P).- Perform ? KeyedBindingInitialization of
BindingElement with value, environment, and P as the arguments. - Return a new
List containing P.
13.3.3.7 Runtime Semantics: RestBindingInitialization
With parameters value, environment, and excludedNames.
- Let lhs be ?
ResolveBinding (StringValue ofBindingIdentifier , environment). - Let restObj be
ObjectCreate (%ObjectPrototype% ). - Perform ?
CopyDataProperties (restObj, value, excludedNames). - If environment is
undefined , returnPutValue (lhs, restObj). - Return
InitializeReferencedBinding (lhs, restObj).
13.3.3.8 Runtime Semantics: IteratorBindingInitialization
With parameters iteratorRecord and environment.
When
- Return
NormalCompletion (empty ).
- Return the result of performing IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument.
- If
Elision is present, then- Perform ? IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument.
- Perform ? IteratorDestructuringAssignmentEvaluation of
- Return the result of performing IteratorBindingInitialization for
BindingRestElement with iteratorRecord and environment as arguments.
- Return the result of performing IteratorBindingInitialization for
BindingElementList with iteratorRecord and environment as arguments.
- Return the result of performing IteratorBindingInitialization for
BindingElementList with iteratorRecord and environment as arguments.
- Perform ? IteratorBindingInitialization for
BindingElementList with iteratorRecord and environment as arguments. - Return the result of performing IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument.
- Perform ? IteratorBindingInitialization for
BindingElementList with iteratorRecord and environment as arguments. - If
Elision is present, then- Perform ? IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument.
- Perform ? IteratorDestructuringAssignmentEvaluation of
- Return the result of performing IteratorBindingInitialization for
BindingRestElement with iteratorRecord and environment as arguments.
- Return the result of performing IteratorBindingInitialization for
BindingElisionElement with iteratorRecord and environment as arguments.
- Perform ? IteratorBindingInitialization for
BindingElementList with iteratorRecord and environment as arguments. - Return the result of performing IteratorBindingInitialization for
BindingElisionElement using iteratorRecord and environment as arguments.
- Return the result of performing IteratorBindingInitialization of
BindingElement with iteratorRecord and environment as the arguments.
- Perform ? IteratorDestructuringAssignmentEvaluation of
Elision with iteratorRecord as the argument. - Return the result of performing IteratorBindingInitialization of
BindingElement with iteratorRecord and environment as the arguments.
- Return the result of performing IteratorBindingInitialization for
SingleNameBinding with iteratorRecord and environment as the arguments.
- Let bindingId be StringValue of
BindingIdentifier . - Let lhs be ?
ResolveBinding (bindingId, environment). - If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue . - Else,
- Let v be
IteratorValue (next). - If v is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (v).
- Let v be
- Let next be
- If iteratorRecord.[[Done]] is
true , let v beundefined . - If
Initializer is present and v isundefined , then- Let defaultValue be the result of evaluating
Initializer . - Set v to ?
GetValue (defaultValue). - If
IsAnonymousFunctionDefinition (Initializer ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (v,"name"). - If hasNameProperty is
false , performSetFunctionName (v, bindingId).
- Let hasNameProperty be ?
- Let defaultValue be the result of evaluating
- If environment is
undefined , return ?PutValue (lhs, v). - Return
InitializeReferencedBinding (lhs, v).
- If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue . - Else,
- Let v be
IteratorValue (next). - If v is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (v).
- Let v be
- Let next be
- If iteratorRecord.[[Done]] is
true , let v beundefined . - If
Initializer is present and v isundefined , then- Let defaultValue be the result of evaluating
Initializer . - Set v to ?
GetValue (defaultValue).
- Let defaultValue be the result of evaluating
- Return the result of performing BindingInitialization of
BindingPattern with v and environment as the arguments.
- Let lhs be ?
ResolveBinding (StringValue ofBindingIdentifier , environment). - Let A be !
ArrayCreate (0). - Let n be 0.
- Repeat,
- If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue .
- Let next be
- If iteratorRecord.[[Done]] is
true , then- If environment is
undefined , return ?PutValue (lhs, A). - Return
InitializeReferencedBinding (lhs, A).
- If environment is
- Let nextValue be
IteratorValue (next). - If nextValue is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (nextValue).- Let status be
CreateDataProperty (A, !ToString (n), nextValue). Assert : status istrue .- Increment n by 1.
- If iteratorRecord.[[Done]] is
- Let A be !
ArrayCreate (0). - Let n be 0.
- Repeat,
- If iteratorRecord.[[Done]] is
false , then- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue .
- Let next be
- If iteratorRecord.[[Done]] is
true , then- Return the result of performing BindingInitialization of
BindingPattern with A and environment as the arguments.
- Return the result of performing BindingInitialization of
- Let nextValue be
IteratorValue (next). - If nextValue is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (nextValue).- Let status be
CreateDataProperty (A, !ToString (n), nextValue). Assert : status istrue .- Increment n by 1.
- If iteratorRecord.[[Done]] is
13.3.3.9 Runtime Semantics: KeyedBindingInitialization
With parameters value, environment, and propertyName.
When
- Let v be ?
GetV (value, propertyName). - If
Initializer is present and v isundefined , then- Let defaultValue be the result of evaluating
Initializer . - Set v to ?
GetValue (defaultValue).
- Let defaultValue be the result of evaluating
- Return the result of performing BindingInitialization for
BindingPattern passing v and environment as arguments.
- Let bindingId be StringValue of
BindingIdentifier . - Let lhs be ?
ResolveBinding (bindingId, environment). - Let v be ?
GetV (value, propertyName). - If
Initializer is present and v isundefined , then- Let defaultValue be the result of evaluating
Initializer . - Set v to ?
GetValue (defaultValue). - If
IsAnonymousFunctionDefinition (Initializer ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (v,"name"). - If hasNameProperty is
false , performSetFunctionName (v, bindingId).
- Let hasNameProperty be ?
- Let defaultValue be the result of evaluating
- If environment is
undefined , return ?PutValue (lhs, v). - Return
InitializeReferencedBinding (lhs, v).
13.4 Empty Statement
Syntax
13.4.1 Runtime Semantics: Evaluation
- Return
NormalCompletion (empty ).
13.5 Expression Statement
Syntax
An function or class keywords because that would make it ambiguous with a async function because that would make it ambiguous with an let [ because that would make it ambiguous with a let
13.5.1 Runtime Semantics: Evaluation
- Let exprRef be the result of evaluating
Expression . - Return ?
GetValue (exprRef).
13.6 The if Statement
Syntax
Each else for which the choice of associated if is ambiguous shall be associated with the nearest possible if that would otherwise have no corresponding else.
13.6.1 Static Semantics: Early Errors
-
It is a Syntax Error if
IsLabelledFunction (Statement ) istrue .
It is only necessary to apply this rule if the extension specified in
13.6.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
13.6.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
13.6.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
13.6.5 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Statement .
13.6.6 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Statement .
13.6.7 Runtime Semantics: Evaluation
- Let exprRef be the result of evaluating
Expression . - Let exprValue be
ToBoolean (?GetValue (exprRef)). - If exprValue is
true , then- Let stmtCompletion be the result of evaluating the first
Statement .
- Let stmtCompletion be the result of evaluating the first
- Else,
- Let stmtCompletion be the result of evaluating the second
Statement .
- Let stmtCompletion be the result of evaluating the second
- Return
Completion (UpdateEmpty (stmtCompletion,undefined )).
- Let exprRef be the result of evaluating
Expression . - Let exprValue be
ToBoolean (?GetValue (exprRef)). - If exprValue is
false , then- Return
NormalCompletion (undefined ).
- Return
- Else,
- Let stmtCompletion be the result of evaluating
Statement . - Return
Completion (UpdateEmpty (stmtCompletion,undefined )).
- Let stmtCompletion be the result of evaluating
13.7 Iteration Statements
Syntax
This section is extended by Annex
13.7.1 Semantics
13.7.1.1 Static Semantics: Early Errors
-
It is a Syntax Error if
IsLabelledFunction (Statement ) istrue .
It is only necessary to apply this rule if the extension specified in
13.7.1.2 Runtime Semantics: LoopContinues ( completion, labelSet )
The abstract operation LoopContinues with arguments completion and labelSet is defined by the following steps:
- If completion.[[Type]] is
normal , returntrue . - If completion.[[Type]] is not
continue , returnfalse . - If completion.[[Target]] is
empty , returntrue . - If completion.[[Target]] is an element of labelSet, return
true . - Return
false .
Within the
13.7.2 The do-while Statement
13.7.2.1 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
13.7.2.2 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
13.7.2.3 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
13.7.2.4 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Statement .
13.7.2.5 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Statement .
13.7.2.6 Runtime Semantics: LabelledEvaluation
With parameter labelSet.
- Let V be
undefined . - Repeat,
- Let stmtResult be the result of evaluating
Statement . - If
LoopContinues (stmtResult, labelSet) isfalse , returnCompletion (UpdateEmpty (stmtResult, V)). - If stmtResult.[[Value]] is not
empty , set V to stmtResult.[[Value]]. - Let exprRef be the result of evaluating
Expression . - Let exprValue be ?
GetValue (exprRef). - If
ToBoolean (exprValue) isfalse , returnNormalCompletion (V).
- Let stmtResult be the result of evaluating
13.7.3 The while Statement
13.7.3.1 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
13.7.3.2 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
13.7.3.3 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
13.7.3.4 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Statement .
13.7.3.5 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Statement .
13.7.3.6 Runtime Semantics: LabelledEvaluation
With parameter labelSet.
- Let V be
undefined . - Repeat,
- Let exprRef be the result of evaluating
Expression . - Let exprValue be ?
GetValue (exprRef). - If
ToBoolean (exprValue) isfalse , returnNormalCompletion (V). - Let stmtResult be the result of evaluating
Statement . - If
LoopContinues (stmtResult, labelSet) isfalse , returnCompletion (UpdateEmpty (stmtResult, V)). - If stmtResult.[[Value]] is not
empty , set V to stmtResult.[[Value]].
- Let exprRef be the result of evaluating
13.7.4 The for Statement
13.7.4.1 Static Semantics: Early Errors
-
It is a Syntax Error if any element of the BoundNames of
LexicalDeclaration also occurs in the VarDeclaredNames ofStatement .
13.7.4.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
13.7.4.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
13.7.4.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
13.7.4.5 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Statement .
- Let names be BoundNames of
VariableDeclarationList . - Append to names the elements of the VarDeclaredNames of
Statement . - Return names.
- Return the VarDeclaredNames of
Statement .
13.7.4.6 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Statement .
- Let declarations be VarScopedDeclarations of
VariableDeclarationList . - Append to declarations the elements of the VarScopedDeclarations of
Statement . - Return declarations.
- Return the VarScopedDeclarations of
Statement .
13.7.4.7 Runtime Semantics: LabelledEvaluation
With parameter labelSet.
- If the first
Expression is present, then- Let exprRef be the result of evaluating the first
Expression . - Perform ?
GetValue (exprRef).
- Let exprRef be the result of evaluating the first
- Return ?
ForBodyEvaluation (the secondExpression , the thirdExpression ,Statement , « », labelSet).
- Let varDcl be the result of evaluating
VariableDeclarationList . ReturnIfAbrupt (varDcl).- Return ?
ForBodyEvaluation (the firstExpression , the secondExpression ,Statement , « », labelSet).
- Let oldEnv be the
running execution context 's LexicalEnvironment. - Let loopEnv be
NewDeclarativeEnvironment (oldEnv). - Let loopEnvRec be loopEnv's
EnvironmentRecord . - Let isConst be the result of performing IsConstantDeclaration of
LexicalDeclaration . - Let boundNames be the BoundNames of
LexicalDeclaration . - For each element dn of boundNames, do
- If isConst is
true , then- Perform ! loopEnvRec.CreateImmutableBinding(dn,
true ).
- Perform ! loopEnvRec.CreateImmutableBinding(dn,
- Else,
- Perform ! loopEnvRec.CreateMutableBinding(dn,
false ).
- Perform ! loopEnvRec.CreateMutableBinding(dn,
- If isConst is
- Set the
running execution context 's LexicalEnvironment to loopEnv. - Let forDcl be the result of evaluating
LexicalDeclaration . - If forDcl is an
abrupt completion , then- Set the
running execution context 's LexicalEnvironment to oldEnv. - Return
Completion (forDcl).
- Set the
- If isConst is
false , let perIterationLets be boundNames; otherwise let perIterationLets be « ». - Let bodyResult be
ForBodyEvaluation (the firstExpression , the secondExpression ,Statement , perIterationLets, labelSet). - Set the
running execution context 's LexicalEnvironment to oldEnv. - Return
Completion (bodyResult).
13.7.4.8 Runtime Semantics: ForBodyEvaluation ( test, increment, stmt, perIterationBindings, labelSet )
The abstract operation ForBodyEvaluation with arguments test, increment, stmt, perIterationBindings, and labelSet is performed as follows:
- Let V be
undefined . - Perform ?
CreatePerIterationEnvironment (perIterationBindings). - Repeat,
- If test is not
[empty] , then- Let testRef be the result of evaluating test.
- Let testValue be ?
GetValue (testRef). - If
ToBoolean (testValue) isfalse , returnNormalCompletion (V).
- Let result be the result of evaluating stmt.
- If
LoopContinues (result, labelSet) isfalse , returnCompletion (UpdateEmpty (result, V)). - If result.[[Value]] is not
empty , set V to result.[[Value]]. - Perform ?
CreatePerIterationEnvironment (perIterationBindings). - If increment is not
[empty] , then- Let incRef be the result of evaluating increment.
- Perform ?
GetValue (incRef).
- If test is not
13.7.4.9 Runtime Semantics: CreatePerIterationEnvironment ( perIterationBindings )
The abstract operation CreatePerIterationEnvironment with argument perIterationBindings is performed as follows:
- If perIterationBindings has any elements, then
- Let lastIterationEnv be the
running execution context 's LexicalEnvironment. - Let lastIterationEnvRec be lastIterationEnv's
EnvironmentRecord . - Let outer be lastIterationEnv's outer environment reference.
Assert : outer is notnull .- Let thisIterationEnv be
NewDeclarativeEnvironment (outer). - Let thisIterationEnvRec be thisIterationEnv's
EnvironmentRecord . - For each element bn of perIterationBindings, do
- Perform ! thisIterationEnvRec.CreateMutableBinding(bn,
false ). - Let lastValue be ? lastIterationEnvRec.GetBindingValue(bn,
true ). - Perform thisIterationEnvRec.InitializeBinding(bn, lastValue).
- Perform ! thisIterationEnvRec.CreateMutableBinding(bn,
- Set the
running execution context 's LexicalEnvironment to thisIterationEnv.
- Let lastIterationEnv be the
- Return
undefined .
13.7.5 The for-in, for-of, and for-await-of Statements
13.7.5.1 Static Semantics: Early Errors
-
It is a Syntax Error if
LeftHandSideExpression is either anObjectLiteral or anArrayLiteral and ifLeftHandSideExpression is notcovering anAssignmentPattern .
If
-
It is a Syntax Error if IsValidSimpleAssignmentTarget of
LeftHandSideExpression isfalse . -
It is a Syntax Error if the
LeftHandSideExpression isCoverParenthesizedExpressionAndArrowParameterList : ( Expression ) Expression derives a phrase that would produce a Syntax Error according to these rules if that phrase were substituted forLeftHandSideExpression . This rule is recursively applied.
The last rule means that the other rules are applied even if parentheses surround
-
It is a Syntax Error if the BoundNames of
ForDeclaration contains"let". -
It is a Syntax Error if any element of the BoundNames of
ForDeclaration also occurs in the VarDeclaredNames ofStatement . -
It is a Syntax Error if the BoundNames of
ForDeclaration contains any duplicate entries.
13.7.5.2 Static Semantics: BoundNames
- Return the BoundNames of
ForBinding .
13.7.5.3 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
This section is extended by Annex
13.7.5.4 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
This section is extended by Annex
13.7.5.5 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
This section is extended by Annex
13.7.5.6 Static Semantics: IsDestructuring
- Return IsDestructuring of
ForBinding .
- Return
false .
- Return
true .
This section is extended by Annex
13.7.5.7 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Statement .
- Let names be the BoundNames of
ForBinding . - Append to names the elements of the VarDeclaredNames of
Statement . - Return names.
- Return the VarDeclaredNames of
Statement .
- Return the VarDeclaredNames of
Statement .
- Let names be the BoundNames of
ForBinding . - Append to names the elements of the VarDeclaredNames of
Statement . - Return names.
- Return the VarDeclaredNames of
Statement .
This section is extended by Annex
13.7.5.8 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Statement .
- Let declarations be a
List containingForBinding . - Append to declarations the elements of the VarScopedDeclarations of
Statement . - Return declarations.
- Return the VarScopedDeclarations of
Statement .
- Return the VarScopedDeclarations of
Statement .
- Let declarations be a
List containingForBinding . - Append to declarations the elements of the VarScopedDeclarations of
Statement . - Return declarations.
- Return the VarScopedDeclarations of
Statement .
This section is extended by Annex
13.7.5.9 Runtime Semantics: BindingInitialization
With parameters value and environment.
var statements and the formal parameter lists of some non-strict functions (see
- Return the result of performing BindingInitialization for
ForBinding passing value and environment as the arguments.
13.7.5.10 Runtime Semantics: BindingInstantiation
With parameter environment.
- Let envRec be environment's
EnvironmentRecord . Assert : envRec is a declarativeEnvironment Record .- For each element name of the BoundNames of
ForBinding , do- If IsConstantDeclaration of
LetOrConst istrue , then- Perform ! envRec.CreateImmutableBinding(name,
true ).
- Perform ! envRec.CreateImmutableBinding(name,
- Else,
- Perform ! envRec.CreateMutableBinding(name,
false ).
- Perform ! envRec.CreateMutableBinding(name,
- If IsConstantDeclaration of
13.7.5.11 Runtime Semantics: LabelledEvaluation
With parameter labelSet.
- Let keyResult be ?
ForIn/OfHeadEvaluation (« »,Expression ,enumerate ). - Return ?
ForIn/OfBodyEvaluation (LeftHandSideExpression ,Statement , keyResult,enumerate ,assignment , labelSet).
- Let keyResult be ?
ForIn/OfHeadEvaluation (« »,Expression ,enumerate ). - Return ?
ForIn/OfBodyEvaluation (ForBinding ,Statement , keyResult,enumerate ,varBinding , labelSet).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (BoundNames ofForDeclaration ,Expression ,enumerate ). - Return ?
ForIn/OfBodyEvaluation (ForDeclaration ,Statement , keyResult,enumerate ,lexicalBinding , labelSet).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (« »,AssignmentExpression ,iterate ). - Return ?
ForIn/OfBodyEvaluation (LeftHandSideExpression ,Statement , keyResult,iterate ,assignment , labelSet).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (« »,AssignmentExpression ,iterate ). - Return ?
ForIn/OfBodyEvaluation (ForBinding ,Statement , keyResult,iterate ,varBinding , labelSet).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (BoundNames ofForDeclaration ,AssignmentExpression ,iterate ). - Return ?
ForIn/OfBodyEvaluation (ForDeclaration ,Statement , keyResult,iterate ,lexicalBinding , labelSet).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (« »,AssignmentExpression ,async-iterate ). - Return ?
ForIn/OfBodyEvaluation (LeftHandSideExpression ,Statement , keyResult,iterate ,assignment , labelSet,async ).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (« »,AssignmentExpression ,async-iterate ). - Return ?
ForIn/OfBodyEvaluation (ForBinding ,Statement , keyResult,iterate ,varBinding , labelSet,async ).
- Let keyResult be the result of performing ?
ForIn/OfHeadEvaluation (BoundNames ofForDeclaration ,AssignmentExpression ,async-iterate ). - Return ?
ForIn/OfBodyEvaluation (ForDeclaration ,Statement , keyResult,iterate ,lexicalBinding , labelSet,async ).
This section is extended by Annex
13.7.5.12 Runtime Semantics: ForIn/OfHeadEvaluation ( TDZnames, expr, iterationKind )
The abstract operation ForIn/OfHeadEvaluation is called with arguments TDZnames, expr, and iterationKind. The value of iterationKind is either
- Let oldEnv be the
running execution context 's LexicalEnvironment. - If TDZnames is not an empty
List , thenAssert : TDZnames has no duplicate entries.- Let TDZ be
NewDeclarativeEnvironment (oldEnv). - Let TDZEnvRec be TDZ's
EnvironmentRecord . - For each string name in TDZnames, do
- Perform ! TDZEnvRec.CreateMutableBinding(name,
false ).
- Perform ! TDZEnvRec.CreateMutableBinding(name,
- Set the
running execution context 's LexicalEnvironment to TDZ.
- Let exprRef be the result of evaluating expr.
- Set the
running execution context 's LexicalEnvironment to oldEnv. - Let exprValue be ?
GetValue (exprRef). - If iterationKind is
enumerate , then- If exprValue is
undefined ornull , then- Return
Completion { [[Type]]:break , [[Value]]:empty , [[Target]]:empty }.
- Return
- Let obj be !
ToObject (exprValue). - Return ?
EnumerateObjectProperties (obj).
- If exprValue is
- Else,
Assert : iterationKind isiterate .- If iterationKind is
async-iterate , let iteratorHint beasync . - Else, let iteratorHint be
sync . - Return ?
GetIterator (exprValue, iteratorHint).
13.7.5.13 Runtime Semantics: ForIn/OfBodyEvaluation ( lhs, stmt, iteratorRecord, iterationKind, lhsKind, labelSet [ , iteratorKind ] )
The abstract operation ForIn/OfBodyEvaluation is called with arguments lhs, stmt, iteratorRecord, iterationKind, lhsKind, labelSet, and optional argument iteratorKind. The value of lhsKind is either
- If iteratorKind is not present, set iteratorKind to
sync . - Let oldEnv be the
running execution context 's LexicalEnvironment. - Let V be
undefined . - Let destructuring be IsDestructuring of lhs.
- If destructuring is
true and if lhsKind isassignment , thenAssert : lhs is aLeftHandSideExpression .- Let assignmentPattern be the
AssignmentPattern that iscovered by lhs.
- Repeat,
- Let nextResult be ?
Call (iteratorRecord.[[NextMethod]], iteratorRecord.[[Iterator]], « »). - If iteratorKind is
async , then set nextResult to ?Await (nextResult). - If
Type (nextResult) is not Object, throw aTypeError exception. - Let nextValue be ?
IteratorValue (nextResult). - If lhsKind is either
assignment orvarBinding , then- If destructuring is
false , then- Let lhsRef be the result of evaluating lhs. (It may be evaluated repeatedly.)
- If destructuring is
- Else,
Assert : lhsKind islexicalBinding .Assert : lhs is aForDeclaration .- Let iterationEnv be
NewDeclarativeEnvironment (oldEnv). - Perform BindingInstantiation for lhs passing iterationEnv as the argument.
- Set the
running execution context 's LexicalEnvironment to iterationEnv. - If destructuring is
false , thenAssert : lhs binds a single name.- Let lhsName be the sole element of BoundNames of lhs.
- Let lhsRef be !
ResolveBinding (lhsName).
- If destructuring is
false , then- If lhsRef is an
abrupt completion , then- Let status be lhsRef.
- Else if lhsKind is
lexicalBinding , then- Let status be
InitializeReferencedBinding (lhsRef, nextValue).
- Let status be
- Else,
- Let status be
PutValue (lhsRef, nextValue).
- Let status be
- If lhsRef is an
- Else,
- If lhsKind is
assignment , then- Let status be the result of performing DestructuringAssignmentEvaluation of assignmentPattern using nextValue as the argument.
- Else if lhsKind is
varBinding , thenAssert : lhs is aForBinding .- Let status be the result of performing BindingInitialization for lhs passing nextValue and
undefined as the arguments.
- Else,
Assert : lhsKind islexicalBinding .Assert : lhs is aForDeclaration .- Let status be the result of performing BindingInitialization for lhs passing nextValue and iterationEnv as arguments.
- If lhsKind is
- If status is an
abrupt completion , then- Set the
running execution context 's LexicalEnvironment to oldEnv. - If iteratorKind is
async , return ?AsyncIteratorClose (iteratorRecord, status). - If iterationKind is
enumerate , then- Return status.
- Else,
Assert : iterationKind isiterate .- Return ?
IteratorClose (iteratorRecord, status).
- Set the
- Let result be the result of evaluating stmt.
- Set the
running execution context 's LexicalEnvironment to oldEnv. - If
LoopContinues (result, labelSet) isfalse , then- If iterationKind is
enumerate , then- Return
Completion (UpdateEmpty (result, V)).
- Return
- Else,
Assert : iterationKind isiterate .- Set status to
UpdateEmpty (result, V). - If iteratorKind is
async , return ?AsyncIteratorClose (iteratorRecord, status). - Return ?
IteratorClose (iteratorRecord, status).
- If iterationKind is
- If result.[[Value]] is not
empty , set V to result.[[Value]].
- Let nextResult be ?
13.7.5.14 Runtime Semantics: Evaluation
- Let bindingId be StringValue of
BindingIdentifier . - Return ?
ResolveBinding (bindingId).
13.7.5.15 EnumerateObjectProperties ( O )
When the abstract operation EnumerateObjectProperties is called with argument O, the following steps are taken:
Assert :Type (O) is Object.- Return an Iterator object (
25.1.1.2 ) whosenextmethod iterates over all the String-valued keys of enumerable properties of O. The iterator object is never directly accessible to ECMAScript code. The mechanics and order of enumerating the properties is not specified but must conform to the rules specified below.
The iterator's throw and return methods are next method processes object properties to determine whether the property key should be returned as an iterator value. Returned property keys do not include keys that are Symbols. Properties of the target object may be deleted during enumeration. A property that is deleted before it is processed by the iterator's next method is ignored. If new properties are added to the target object during enumeration, the newly added properties are not guaranteed to be processed in the active enumeration. A next method at most once in any enumeration.
Enumerating the properties of the target object includes enumerating properties of its prototype, and the prototype of the prototype, and so on, recursively; but a property of a prototype is not processed if it has the same name as a property that has already been processed by the iterator's next method. The values of [[Enumerable]] attributes are not considered when determining if a property of a prototype object has already been processed. The enumerable property names of prototype objects must be obtained by invoking EnumerateObjectProperties passing the prototype object as the argument. EnumerateObjectProperties must obtain the own property keys of the target object by calling its [[OwnPropertyKeys]] internal method. Property attributes of the target object must be obtained by calling its [[GetOwnProperty]] internal method.
The following is an informative definition of an ECMAScript generator function that conforms to these rules:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === "symbol") continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}13.8 The continue Statement
Syntax
13.8.1 Static Semantics: Early Errors
-
It is a Syntax Error if this
ContinueStatement is not nested, directly or indirectly (but not crossing function boundaries), within anIterationStatement .
13.8.2 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return
false .
- If the StringValue of
LabelIdentifier is not an element of iterationSet, returntrue . - Return
false .
13.8.3 Runtime Semantics: Evaluation
- Return
Completion { [[Type]]:continue , [[Value]]:empty , [[Target]]:empty }.
- Let label be the StringValue of
LabelIdentifier . - Return
Completion { [[Type]]:continue , [[Value]]:empty , [[Target]]: label }.
13.9 The break Statement
Syntax
13.9.1 Static Semantics: Early Errors
-
It is a Syntax Error if this
BreakStatement is not nested, directly or indirectly (but not crossing function boundaries), within anIterationStatement or aSwitchStatement .
13.9.2 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return
false .
- If the StringValue of
LabelIdentifier is not an element of labelSet, returntrue . - Return
false .
13.9.3 Runtime Semantics: Evaluation
- Return
Completion { [[Type]]:break , [[Value]]:empty , [[Target]]:empty }.
- Let label be the StringValue of
LabelIdentifier . - Return
Completion { [[Type]]:break , [[Value]]:empty , [[Target]]: label }.
13.10 The return Statement
Syntax
A return statement causes a function to cease execution and, in most cases, returns a value to the caller. If return statement may not actually return a value to the caller depending on surrounding context. For example, in a try block, a return statement's completion record may be replaced with another completion record during evaluation of the finally block.
13.10.1 Runtime Semantics: Evaluation
- Return
Completion { [[Type]]:return , [[Value]]:undefined , [[Target]]:empty }.
- Let exprRef be the result of evaluating
Expression . - Let exprValue be ?
GetValue (exprRef). - If !
GetGeneratorKind () isasync , set exprValue to ?Await (exprValue). - Return
Completion { [[Type]]:return , [[Value]]: exprValue, [[Target]]:empty }.
13.11 The with Statement
Syntax
The with statement adds an object
13.11.1 Static Semantics: Early Errors
-
It is a Syntax Error if the code that matches this production is contained in
strict mode code . -
It is a Syntax Error if
IsLabelledFunction (Statement ) istrue .
It is only necessary to apply the second rule if the extension specified in
13.11.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
13.11.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
13.11.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
13.11.5 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Statement .
13.11.6 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Statement .
13.11.7 Runtime Semantics: Evaluation
- Let val be the result of evaluating
Expression . - Let obj be ?
ToObject (?GetValue (val)). - Let oldEnv be the
running execution context 's LexicalEnvironment. - Let newEnv be
NewObjectEnvironment (obj, oldEnv). - Set the withEnvironment flag of newEnv's
EnvironmentRecord totrue . - Set the
running execution context 's LexicalEnvironment to newEnv. - Let C be the result of evaluating
Statement . - Set the
running execution context 's LexicalEnvironment to oldEnv. - Return
Completion (UpdateEmpty (C,undefined )).
No matter how control leaves the embedded
13.12 The switch Statement
Syntax
13.12.1 Static Semantics: Early Errors
13.12.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
CaseBlock with argument labelSet.
- Return
false .
- If the first
CaseClauses is present, then- Let hasDuplicates be ContainsDuplicateLabels of the first
CaseClauses with argument labelSet. - If hasDuplicates is
true , returntrue .
- Let hasDuplicates be ContainsDuplicateLabels of the first
- Let hasDuplicates be ContainsDuplicateLabels of
DefaultClause with argument labelSet. - If hasDuplicates is
true , returntrue . - If the second
CaseClauses is not present, returnfalse . - Return ContainsDuplicateLabels of the second
CaseClauses with argument labelSet.
- Let hasDuplicates be ContainsDuplicateLabels of
CaseClauses with argument labelSet. - If hasDuplicates is
true , returntrue . - Return ContainsDuplicateLabels of
CaseClause with argument labelSet.
- If the
StatementList is present, return ContainsDuplicateLabels ofStatementList with argument labelSet. - Return
false .
- If the
StatementList is present, return ContainsDuplicateLabels ofStatementList with argument labelSet. - Return
false .
13.12.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Return ContainsUndefinedBreakTarget of
CaseBlock with argument labelSet.
- Return
false .
- If the first
CaseClauses is present, then- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of the first
CaseClauses with argument labelSet. - If hasUndefinedLabels is
true , returntrue .
- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of the first
- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of
DefaultClause with argument labelSet. - If hasUndefinedLabels is
true , returntrue . - If the second
CaseClauses is not present, returnfalse . - Return ContainsUndefinedBreakTarget of the second
CaseClauses with argument labelSet.
- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of
CaseClauses with argument labelSet. - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedBreakTarget of
CaseClause with argument labelSet.
- If the
StatementList is present, return ContainsUndefinedBreakTarget ofStatementList with argument labelSet. - Return
false .
- If the
StatementList is present, return ContainsUndefinedBreakTarget ofStatementList with argument labelSet. - Return
false .
13.12.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Return ContainsUndefinedContinueTarget of
CaseBlock with arguments iterationSet and « ».
- Return
false .
- If the first
CaseClauses is present, then- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of the first
CaseClauses with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue .
- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of the first
- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of
DefaultClause with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue . - If the second
CaseClauses is not present, returnfalse . - Return ContainsUndefinedContinueTarget of the second
CaseClauses with arguments iterationSet and « ».
- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of
CaseClauses with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedContinueTarget of
CaseClause with arguments iterationSet and « ».
- If the
StatementList is present, return ContainsUndefinedContinueTarget ofStatementList with arguments iterationSet and « ». - Return
false .
- If the
StatementList is present, return ContainsUndefinedContinueTarget ofStatementList with arguments iterationSet and « ». - Return
false .
13.12.5 Static Semantics: LexicallyDeclaredNames
- Return a new empty
List .
- If the first
CaseClauses is present, let names be the LexicallyDeclaredNames of the firstCaseClauses . - Else, let names be a new empty
List . - Append to names the elements of the LexicallyDeclaredNames of the
DefaultClause . - If the second
CaseClauses is not present, return names. - Return the result of appending to names the elements of the LexicallyDeclaredNames of the second
CaseClauses .
- Let names be LexicallyDeclaredNames of
CaseClauses . - Append to names the elements of the LexicallyDeclaredNames of
CaseClause . - Return names.
- If the
StatementList is present, return the LexicallyDeclaredNames ofStatementList . - Return a new empty
List .
- If the
StatementList is present, return the LexicallyDeclaredNames ofStatementList . - Return a new empty
List .
13.12.6 Static Semantics: LexicallyScopedDeclarations
- Return a new empty
List .
- If the first
CaseClauses is present, let declarations be the LexicallyScopedDeclarations of the firstCaseClauses . - Else, let declarations be a new empty
List . - Append to declarations the elements of the LexicallyScopedDeclarations of the
DefaultClause . - If the second
CaseClauses is not present, return declarations. - Return the result of appending to declarations the elements of the LexicallyScopedDeclarations of the second
CaseClauses .
- Let declarations be LexicallyScopedDeclarations of
CaseClauses . - Append to declarations the elements of the LexicallyScopedDeclarations of
CaseClause . - Return declarations.
- If the
StatementList is present, return the LexicallyScopedDeclarations ofStatementList . - Return a new empty
List .
- If the
StatementList is present, return the LexicallyScopedDeclarations ofStatementList . - Return a new empty
List .
13.12.7 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
CaseBlock .
- Return a new empty
List .
- If the first
CaseClauses is present, let names be the VarDeclaredNames of the firstCaseClauses . - Else, let names be a new empty
List . - Append to names the elements of the VarDeclaredNames of the
DefaultClause . - If the second
CaseClauses is not present, return names. - Return the result of appending to names the elements of the VarDeclaredNames of the second
CaseClauses .
- Let names be VarDeclaredNames of
CaseClauses . - Append to names the elements of the VarDeclaredNames of
CaseClause . - Return names.
- If the
StatementList is present, return the VarDeclaredNames ofStatementList . - Return a new empty
List .
- If the
StatementList is present, return the VarDeclaredNames ofStatementList . - Return a new empty
List .
13.12.8 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
CaseBlock .
- Return a new empty
List .
- If the first
CaseClauses is present, let declarations be the VarScopedDeclarations of the firstCaseClauses . - Else, let declarations be a new empty
List . - Append to declarations the elements of the VarScopedDeclarations of the
DefaultClause . - If the second
CaseClauses is not present, return declarations. - Return the result of appending to declarations the elements of the VarScopedDeclarations of the second
CaseClauses .
- Let declarations be VarScopedDeclarations of
CaseClauses . - Append to declarations the elements of the VarScopedDeclarations of
CaseClause . - Return declarations.
- If the
StatementList is present, return the VarScopedDeclarations ofStatementList . - Return a new empty
List .
- If the
StatementList is present, return the VarScopedDeclarations ofStatementList . - Return a new empty
List .
13.12.9 Runtime Semantics: CaseBlockEvaluation
With parameter input.
- Return
NormalCompletion (undefined ).
- Let V be
undefined . - Let A be the
List ofCaseClause items inCaseClauses , in source text order. - Let found be
false . - For each
CaseClause C in A, do- If found is
false , then- Set found to ?
CaseClauseIsSelected (C, input).
- Set found to ?
- If found is
true , then- Let R be the result of evaluating C.
- If R.[[Value]] is not
empty , set V to R.[[Value]]. - If R is an
abrupt completion , returnCompletion (UpdateEmpty (R, V)).
- If found is
- Return
NormalCompletion (V).
- Let V be
undefined . - If the first
CaseClauses is present, then- Let A be the
List ofCaseClause items in the firstCaseClauses , in source text order.
- Let A be the
- Else,
- Let A be « ».
- Let found be
false . - For each
CaseClause C in A, do- If found is
false , then- Set found to ?
CaseClauseIsSelected (C, input).
- Set found to ?
- If found is
true , then- Let R be the result of evaluating C.
- If R.[[Value]] is not
empty , set V to R.[[Value]]. - If R is an
abrupt completion , returnCompletion (UpdateEmpty (R, V)).
- If found is
- Let foundInB be
false . - If the second
CaseClauses is present, then- Let B be the
List ofCaseClause items in the secondCaseClauses , in source text order.
- Let B be the
- Else,
- Let B be « ».
- If found is
false , then- For each
CaseClause C in B, do- If foundInB is
false , then- Set foundInB to ?
CaseClauseIsSelected (C, input).
- Set foundInB to ?
- If foundInB is
true , then- Let R be the result of evaluating
CaseClause C. - If R.[[Value]] is not
empty , set V to R.[[Value]]. - If R is an
abrupt completion , returnCompletion (UpdateEmpty (R, V)).
- Let R be the result of evaluating
- If foundInB is
- For each
- If foundInB is
true , returnNormalCompletion (V). - Let R be the result of evaluating
DefaultClause . - If R.[[Value]] is not
empty , set V to R.[[Value]]. - If R is an
abrupt completion , returnCompletion (UpdateEmpty (R, V)). - For each
CaseClause C in B (NOTE: this is another complete iteration of the secondCaseClauses ), do- Let R be the result of evaluating
CaseClause C. - If R.[[Value]] is not
empty , set V to R.[[Value]]. - If R is an
abrupt completion , returnCompletion (UpdateEmpty (R, V)).
- Let R be the result of evaluating
- Return
NormalCompletion (V).
13.12.10 Runtime Semantics: CaseClauseIsSelected ( C, input )
The abstract operation CaseClauseIsSelected, given
Assert : C is an instance of the productionCaseClause : case Expression : StatementList opt - Let exprRef be the result of evaluating the
Expression of C. - Let clauseSelector be ?
GetValue (exprRef). - Return the result of performing
Strict Equality Comparison input === clauseSelector.
This operation does not execute C's
13.12.11 Runtime Semantics: Evaluation
- Let exprRef be the result of evaluating
Expression . - Let switchValue be ?
GetValue (exprRef). - Let oldEnv be the
running execution context 's LexicalEnvironment. - Let blockEnv be
NewDeclarativeEnvironment (oldEnv). - Perform
BlockDeclarationInstantiation (CaseBlock , blockEnv). - Set the
running execution context 's LexicalEnvironment to blockEnv. - Let R be the result of performing CaseBlockEvaluation of
CaseBlock with argument switchValue. - Set the
running execution context 's LexicalEnvironment to oldEnv. - Return R.
No matter how control leaves the
- Return
NormalCompletion (empty ).
- Return the result of evaluating
StatementList .
- Return
NormalCompletion (empty ).
- Return the result of evaluating
StatementList .
13.13 Labelled Statements
Syntax
A break and continue statements. ECMAScript has no goto statement. A
13.13.1 Static Semantics: Early Errors
- It is a Syntax Error if any source text matches this rule.
An alternative definition for this rule is provided in
13.13.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Let label be the StringValue of
LabelIdentifier . - If label is an element of labelSet, return
true . - Let newLabelSet be a copy of labelSet with label appended.
- Return ContainsDuplicateLabels of
LabelledItem with argument newLabelSet.
- Return
false .
13.13.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Let label be the StringValue of
LabelIdentifier . - Let newLabelSet be a copy of labelSet with label appended.
- Return ContainsUndefinedBreakTarget of
LabelledItem with argument newLabelSet.
- Return
false .
13.13.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Let label be the StringValue of
LabelIdentifier . - Let newLabelSet be a copy of labelSet with label appended.
- Return ContainsUndefinedContinueTarget of
LabelledItem with arguments iterationSet and newLabelSet.
- Return
false .
13.13.5 Static Semantics: IsLabelledFunction ( stmt )
The abstract operation IsLabelledFunction with argument stmt performs the following steps:
- If stmt is not a
LabelledStatement , returnfalse . - Let item be the
LabelledItem of stmt. - If item is
LabelledItem : FunctionDeclaration true . - Let subStmt be the
Statement of item. - Return
IsLabelledFunction (subStmt).
13.13.6 Static Semantics: LexicallyDeclaredNames
- Return the LexicallyDeclaredNames of
LabelledItem .
- Return a new empty
List .
- Return BoundNames of
FunctionDeclaration .
13.13.7 Static Semantics: LexicallyScopedDeclarations
- Return the LexicallyScopedDeclarations of
LabelledItem .
- Return a new empty
List .
- Return a new
List containingFunctionDeclaration .
13.13.8 Static Semantics: TopLevelLexicallyDeclaredNames
- Return a new empty
List .
13.13.9 Static Semantics: TopLevelLexicallyScopedDeclarations
- Return a new empty
List .
13.13.10 Static Semantics: TopLevelVarDeclaredNames
- Return the TopLevelVarDeclaredNames of
LabelledItem .
- If
Statement isStatement : LabelledStatement Statement . - Return VarDeclaredNames of
Statement .
- Return BoundNames of
FunctionDeclaration .
13.13.11 Static Semantics: TopLevelVarScopedDeclarations
- Return the TopLevelVarScopedDeclarations of
LabelledItem .
- If
Statement isStatement : LabelledStatement Statement . - Return VarScopedDeclarations of
Statement .
- Return a new
List containingFunctionDeclaration .
13.13.12 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
LabelledItem .
- Return a new empty
List .
13.13.13 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
LabelledItem .
- Return a new empty
List .
13.13.14 Runtime Semantics: LabelledEvaluation
With parameter labelSet.
- Let label be the StringValue of
LabelIdentifier . - Append label as an element of labelSet.
- Let stmtResult be LabelledEvaluation of
LabelledItem with argument labelSet. - If stmtResult.[[Type]] is
break andSameValue (stmtResult.[[Target]], label) istrue , then- Set stmtResult to
NormalCompletion (stmtResult.[[Value]]).
- Set stmtResult to
- Return
Completion (stmtResult).
- If
Statement is either aLabelledStatement or aBreakableStatement , then- Return LabelledEvaluation of
Statement with argument labelSet.
- Return LabelledEvaluation of
- Else,
- Return the result of evaluating
Statement .
- Return the result of evaluating
- Return the result of evaluating
FunctionDeclaration .
13.13.15 Runtime Semantics: Evaluation
- Let newLabelSet be a new empty
List . - Return LabelledEvaluation of this
LabelledStatement with argument newLabelSet.
13.14 The throw Statement
Syntax
13.14.1 Runtime Semantics: Evaluation
- Let exprRef be the result of evaluating
Expression . - Let exprValue be ?
GetValue (exprRef). - Return
ThrowCompletion (exprValue).
13.15 The try Statement
Syntax
The try statement encloses a block of code in which an exceptional condition can occur, such as a runtime error or a throw statement. The catch clause provides the exception-handling code. When a catch clause catches an exception, its
13.15.1 Static Semantics: Early Errors
-
It is a Syntax Error if BoundNames of
CatchParameter contains any duplicate elements. -
It is a Syntax Error if any element of the BoundNames of
CatchParameter also occurs in the LexicallyDeclaredNames ofBlock . -
It is a Syntax Error if any element of the BoundNames of
CatchParameter also occurs in the VarDeclaredNames ofBlock .
An alternative
13.15.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Return ContainsDuplicateLabels of
Block with argument labelSet.
13.15.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of
Block with argument labelSet. - If hasUndefinedLabels is
true , returntrue . - Let hasUndefinedLabels be ContainsUndefinedBreakTarget of
Catch with argument labelSet. - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedBreakTarget of
Finally with argument labelSet.
- Return ContainsUndefinedBreakTarget of
Block with argument labelSet.
13.15.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of
Block with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue . - Let hasUndefinedLabels be ContainsUndefinedContinueTarget of
Catch with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedContinueTarget of
Finally with arguments iterationSet and « ».
- Return ContainsUndefinedContinueTarget of
Block with arguments iterationSet and « ».
13.15.5 Static Semantics: VarDeclaredNames
- Return the VarDeclaredNames of
Block .
13.15.6 Static Semantics: VarScopedDeclarations
- Return the VarScopedDeclarations of
Block .
13.15.7 Runtime Semantics: CatchClauseEvaluation
With parameter thrownValue.
- Let oldEnv be the
running execution context 's LexicalEnvironment. - Let catchEnv be
NewDeclarativeEnvironment (oldEnv). - Let catchEnvRec be catchEnv's
EnvironmentRecord . - For each element argName of the BoundNames of
CatchParameter , do- Perform ! catchEnvRec.CreateMutableBinding(argName,
false ).
- Perform ! catchEnvRec.CreateMutableBinding(argName,
- Set the
running execution context 's LexicalEnvironment to catchEnv. - Let status be the result of performing BindingInitialization for
CatchParameter passing thrownValue and catchEnv as arguments. - If status is an
abrupt completion , then- Set the
running execution context 's LexicalEnvironment to oldEnv. - Return
Completion (status).
- Set the
- Let B be the result of evaluating
Block . - Set the
running execution context 's LexicalEnvironment to oldEnv. - Return
Completion (B).
No matter how control leaves the
13.15.8 Runtime Semantics: Evaluation
- Let B be the result of evaluating
Block . - If B.[[Type]] is
throw , let C be CatchClauseEvaluation ofCatch with argument B.[[Value]]. - Else, let C be B.
- Return
Completion (UpdateEmpty (C,undefined )).
- Let B be the result of evaluating
Block . - Let F be the result of evaluating
Finally . - If F.[[Type]] is
normal , set F to B. - Return
Completion (UpdateEmpty (F,undefined )).
- Let B be the result of evaluating
Block . - If B.[[Type]] is
throw , let C be CatchClauseEvaluation ofCatch with argument B.[[Value]]. - Else, let C be B.
- Let F be the result of evaluating
Finally . - If F.[[Type]] is
normal , set F to C. - Return
Completion (UpdateEmpty (F,undefined )).
13.16 The debugger Statement
Syntax
13.16.1 Runtime Semantics: Evaluation
Evaluating a
- If an implementation-defined debugging facility is available and enabled, then
- Perform an implementation-defined debugging action.
- Let result be an implementation-defined
Completion value.
- Else,
- Let result be
NormalCompletion (empty ).
- Let result be
- Return result.
14 ECMAScript Language: Functions and Classes
14.1 Function Definitions
Syntax
14.1.1 Directive Prologues and the Use Strict Directive
A Directive Prologue is the longest sequence of
A Use Strict Directive is an "use strict" or 'use strict'. A
A
The
14.1.2 Static Semantics: Early Errors
-
If the source code matching this production is
strict mode code , the Early Error rules forUniqueFormalParameters : FormalParameters -
If the source code matching this production is
strict mode code , it is a Syntax Error ifBindingIdentifier is present and the StringValue ofBindingIdentifier is"eval"or"arguments". -
It is a Syntax Error if ContainsUseStrict of
FunctionBody istrue and IsSimpleParameterList ofFormalParameters isfalse . -
It is a Syntax Error if any element of the BoundNames of
FormalParameters also occurs in the LexicallyDeclaredNames ofFunctionBody . -
It is a Syntax Error if
FormalParameters ContainsSuperProperty istrue . -
It is a Syntax Error if
FunctionBody ContainsSuperProperty istrue . -
It is a Syntax Error if
FormalParameters ContainsSuperCall istrue . -
It is a Syntax Error if
FunctionBody ContainsSuperCall istrue .
The LexicallyDeclaredNames of a
-
It is a Syntax Error if BoundNames of
FormalParameters contains any duplicate elements.
-
It is a Syntax Error if IsSimpleParameterList of
FormalParameterList isfalse and BoundNames ofFormalParameterList contains any duplicate elements.
Multiple occurrences of the same
-
It is a Syntax Error if the LexicallyDeclaredNames of
FunctionStatementList contains any duplicate entries. -
It is a Syntax Error if any element of the LexicallyDeclaredNames of
FunctionStatementList also occurs in the VarDeclaredNames ofFunctionStatementList . -
It is a Syntax Error if ContainsDuplicateLabels of
FunctionStatementList with argument « » istrue . -
It is a Syntax Error if ContainsUndefinedBreakTarget of
FunctionStatementList with argument « » istrue . -
It is a Syntax Error if ContainsUndefinedContinueTarget of
FunctionStatementList with arguments « » and « » istrue .
14.1.3 Static Semantics: BoundNames
- Return the BoundNames of
BindingIdentifier .
- Return «
"*default*"».
"*default*" is used within this specification as a synthetic name for hoistable anonymous functions that are defined using export declarations.
- Return a new empty
List .
- Let names be BoundNames of
FormalParameterList . - Append to names the BoundNames of
FunctionRestParameter . - Return names.
- Let names be BoundNames of
FormalParameterList . - Append to names the BoundNames of
FormalParameter . - Return names.
14.1.4 Static Semantics: Contains
With parameter symbol.
- Return
false .
Static semantic rules that depend upon substructure generally do not look into function definitions.
14.1.5 Static Semantics: ContainsExpression
- Return
false .
- If ContainsExpression of
FormalParameterList istrue , returntrue . - Return ContainsExpression of
FunctionRestParameter .
- If ContainsExpression of
FormalParameterList istrue , returntrue . - Return ContainsExpression of
FormalParameter .
14.1.6 Static Semantics: ContainsUseStrict
- If the
Directive Prologue ofFunctionStatementList contains aUse Strict Directive , returntrue ; otherwise, returnfalse .
14.1.7 Static Semantics: ExpectedArgumentCount
- Return 0.
- Return ExpectedArgumentCount of
FormalParameterList .
The ExpectedArgumentCount of a
- Let count be ExpectedArgumentCount of
FormalParameterList . - If HasInitializer of
FormalParameterList istrue or HasInitializer ofFormalParameter istrue , return count. - Return count + 1.
14.1.8 Static Semantics: HasInitializer
- If HasInitializer of
FormalParameterList istrue , returntrue . - Return HasInitializer of
FormalParameter .
14.1.9 Static Semantics: HasName
- Return
false .
- Return
true .
14.1.10 Static Semantics: IsAnonymousFunctionDefinition ( expr )
The abstract operation IsAnonymousFunctionDefinition determines if its argument is a function definition that does not bind a name. The argument expr is the result of parsing an
- If IsFunctionDefinition of expr is
false , returnfalse . - Let hasName be the result of HasName of expr.
- If hasName is
true , returnfalse . - Return
true .
14.1.11 Static Semantics: IsConstantDeclaration
- Return
false .
14.1.12 Static Semantics: IsFunctionDefinition
- Return
true .
14.1.13 Static Semantics: IsSimpleParameterList
- Return
true .
- Return
false .
- If IsSimpleParameterList of
FormalParameterList isfalse , returnfalse . - Return IsSimpleParameterList of
FormalParameter .
- Return IsSimpleParameterList of
BindingElement .
14.1.14 Static Semantics: LexicallyDeclaredNames
- Return a new empty
List .
- Return TopLevelLexicallyDeclaredNames of
StatementList .
14.1.15 Static Semantics: LexicallyScopedDeclarations
- Return a new empty
List .
- Return the TopLevelLexicallyScopedDeclarations of
StatementList .
14.1.16 Static Semantics: VarDeclaredNames
- Return a new empty
List .
- Return TopLevelVarDeclaredNames of
StatementList .
14.1.17 Static Semantics: VarScopedDeclarations
- Return a new empty
List .
- Return the TopLevelVarScopedDeclarations of
StatementList .
14.1.18 Runtime Semantics: EvaluateBody
With parameters functionObject and
- Perform ?
FunctionDeclarationInstantiation (functionObject, argumentsList). - Return the result of evaluating
FunctionStatementList .
14.1.19 Runtime Semantics: IteratorBindingInitialization
With parameters iteratorRecord and environment.
When
- Return
NormalCompletion (empty ).
- Perform ? IteratorBindingInitialization for
FormalParameterList using iteratorRecord and environment as the arguments. - Return the result of performing IteratorBindingInitialization for
FunctionRestParameter using iteratorRecord and environment as the arguments.
- Perform ? IteratorBindingInitialization for
FormalParameterList using iteratorRecord and environment as the arguments. - Return the result of performing IteratorBindingInitialization for
FormalParameter using iteratorRecord and environment as the arguments.
- If ContainsExpression of
BindingElement isfalse , return the result of performing IteratorBindingInitialization forBindingElement using iteratorRecord and environment as the arguments. - Let currentContext be the
running execution context . - Let originalEnv be the VariableEnvironment of currentContext.
Assert : The VariableEnvironment and LexicalEnvironment of currentContext are the same.Assert : environment and originalEnv are the same.- Let paramVarEnv be
NewDeclarativeEnvironment (originalEnv). - Set the VariableEnvironment of currentContext to paramVarEnv.
- Set the LexicalEnvironment of currentContext to paramVarEnv.
- Let result be the result of performing IteratorBindingInitialization for
BindingElement using iteratorRecord and environment as the arguments. - Set the VariableEnvironment of currentContext to originalEnv.
- Set the LexicalEnvironment of currentContext to originalEnv.
- Return result.
The new
- If ContainsExpression of
BindingRestElement isfalse , return the result of performing IteratorBindingInitialization forBindingRestElement using iteratorRecord and environment as the arguments. - Let currentContext be the
running execution context . - Let originalEnv be the VariableEnvironment of currentContext.
Assert : The VariableEnvironment and LexicalEnvironment of currentContext are the same.Assert : environment and originalEnv are the same.- Let paramVarEnv be
NewDeclarativeEnvironment (originalEnv). - Set the VariableEnvironment of currentContext to paramVarEnv.
- Set the LexicalEnvironment of currentContext to paramVarEnv.
- Let result be the result of performing IteratorBindingInitialization for
BindingRestElement using iteratorRecord and environment as the arguments. - Set the VariableEnvironment of currentContext to originalEnv.
- Set the LexicalEnvironment of currentContext to originalEnv.
- Return result.
The new
14.1.20 Runtime Semantics: InstantiateFunctionObject
With parameter scope.
- If the function code for
FunctionDeclaration isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let name be StringValue of
BindingIdentifier . - Let F be
FunctionCreate (Normal ,FormalParameters ,FunctionBody , scope, strict). - Perform
MakeConstructor (F). - Perform
SetFunctionName (F, name). - Return F.
- Let F be
FunctionCreate (Normal ,FormalParameters ,FunctionBody , scope,true ). - Perform
MakeConstructor (F). - Perform
SetFunctionName (F,"default"). - Return F.
An anonymous export default declaration, and its function code is therefore always
14.1.21 Runtime Semantics: Evaluation
- Return
NormalCompletion (empty ).
An alternative semantics is provided in
- Return
NormalCompletion (empty ).
- If the function code for
FunctionExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let closure be
FunctionCreate (Normal ,FormalParameters ,FunctionBody , scope, strict). - Perform
MakeConstructor (closure). - Return closure.
- If the function code for
FunctionExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let funcEnv be
NewDeclarativeEnvironment (scope). - Let envRec be funcEnv's
EnvironmentRecord . - Let name be StringValue of
BindingIdentifier . - Perform envRec.CreateImmutableBinding(name,
false ). - Let closure be
FunctionCreate (Normal ,FormalParameters ,FunctionBody , funcEnv, strict). - Perform
MakeConstructor (closure). - Perform
SetFunctionName (closure, name). - Perform envRec.InitializeBinding(name, closure).
- Return closure.
The
A prototype property is automatically created for every function defined using a
- Return
NormalCompletion (undefined ).
14.2 Arrow Function Definitions
Syntax
Supplemental Syntax
When the production
is recognized the following grammar is used to refine the interpretation of
14.2.1 Static Semantics: Early Errors
-
It is a Syntax Error if
ArrowParameters ContainsYieldExpression istrue . -
It is a Syntax Error if
ArrowParameters ContainsAwaitExpression istrue . -
It is a Syntax Error if ContainsUseStrict of
ConciseBody istrue and IsSimpleParameterList ofArrowParameters isfalse . -
It is a Syntax Error if any element of the BoundNames of
ArrowParameters also occurs in the LexicallyDeclaredNames ofConciseBody .
-
It is a Syntax Error if
CoverParenthesizedExpressionAndArrowParameterList is notcovering anArrowFormalParameters . -
All
early error rules forArrowFormalParameters and its derived productions also apply to CoveredFormalsList ofCoverParenthesizedExpressionAndArrowParameterList .
14.2.2 Static Semantics: BoundNames
- Let formals be CoveredFormalsList of
CoverParenthesizedExpressionAndArrowParameterList . - Return the BoundNames of formals.
14.2.3 Static Semantics: Contains
With parameter symbol.
- If symbol is not one of
NewTarget ,SuperProperty ,SuperCall ,superorthis, returnfalse . - If
ArrowParameters Contains symbol istrue , returntrue . - Return
ConciseBody Contains symbol.
Normally, Contains does not look inside most function forms. However, Contains is used to detect new.target, this, and super usage within an
- Let formals be CoveredFormalsList of
CoverParenthesizedExpressionAndArrowParameterList . - Return formals Contains symbol.
14.2.4 Static Semantics: ContainsExpression
- Return
false .
14.2.5 Static Semantics: ContainsUseStrict
- Return
false .
14.2.6 Static Semantics: ExpectedArgumentCount
- Return 1.
14.2.7 Static Semantics: HasName
- Return
false .
14.2.8 Static Semantics: IsSimpleParameterList
- Return
true .
- Let formals be CoveredFormalsList of
CoverParenthesizedExpressionAndArrowParameterList . - Return IsSimpleParameterList of formals.
14.2.9 Static Semantics: CoveredFormalsList
- Return this
ArrowParameters .
- Return the
ArrowFormalParameters that iscovered byCoverParenthesizedExpressionAndArrowParameterList .
14.2.10 Static Semantics: LexicallyDeclaredNames
- Return a new empty
List .
14.2.11 Static Semantics: LexicallyScopedDeclarations
- Return a new empty
List .
14.2.12 Static Semantics: VarDeclaredNames
- Return a new empty
List .
14.2.13 Static Semantics: VarScopedDeclarations
- Return a new empty
List .
14.2.14 Runtime Semantics: IteratorBindingInitialization
With parameters iteratorRecord and environment.
When
Assert : iteratorRecord.[[Done]] isfalse .- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue . - Else,
- Let v be
IteratorValue (next). - If v is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (v).
- Let v be
- If iteratorRecord.[[Done]] is
true , let v beundefined . - Return the result of performing BindingInitialization for
BindingIdentifier using v and environment as the arguments.
14.2.15 Runtime Semantics: EvaluateBody
With parameters functionObject and
- Perform ?
FunctionDeclarationInstantiation (functionObject, argumentsList). - Let exprRef be the result of evaluating
AssignmentExpression . - Let exprValue be ?
GetValue (exprRef). - Return
Completion { [[Type]]:return , [[Value]]: exprValue, [[Target]]:empty }.
14.2.16 Runtime Semantics: Evaluation
- If the function code for this
ArrowFunction isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let parameters be CoveredFormalsList of
ArrowParameters . - Let closure be
FunctionCreate (Arrow , parameters,ConciseBody , scope, strict). - Return closure.
An arguments, super, this, or new.target. Any reference to arguments, super, this, or new.target within an super, the super is always contained within a non-super is accessible via the scope that is captured by the
14.3 Method Definitions
Syntax
14.3.1 Static Semantics: Early Errors
-
It is a Syntax Error if ContainsUseStrict of
FunctionBody istrue and IsSimpleParameterList ofUniqueFormalParameters isfalse . -
It is a Syntax Error if any element of the BoundNames of
UniqueFormalParameters also occurs in the LexicallyDeclaredNames ofFunctionBody .
-
It is a Syntax Error if BoundNames of
PropertySetParameterList contains any duplicate elements. -
It is a Syntax Error if ContainsUseStrict of
FunctionBody istrue and IsSimpleParameterList ofPropertySetParameterList isfalse . -
It is a Syntax Error if any element of the BoundNames of
PropertySetParameterList also occurs in the LexicallyDeclaredNames ofFunctionBody .
14.3.2 Static Semantics: ComputedPropertyContains
With parameter symbol.
- Return the result of ComputedPropertyContains for
PropertyName with argument symbol.
14.3.3 Static Semantics: ExpectedArgumentCount
- If HasInitializer of
FormalParameter istrue , return 0. - Return 1.
14.3.4 Static Semantics: HasDirectSuper
- If
UniqueFormalParameters ContainsSuperCall istrue , returntrue . - Return
FunctionBody ContainsSuperCall .
- Return
FunctionBody ContainsSuperCall .
- If
PropertySetParameterList ContainsSuperCall istrue , returntrue . - Return
FunctionBody ContainsSuperCall .
14.3.5 Static Semantics: PropName
- Return PropName of
PropertyName .
14.3.6 Static Semantics: SpecialMethod
- Return
false .
- Return
true .
14.3.7 Runtime Semantics: DefineMethod
With parameters object and optional parameter functionPrototype.
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- If the function code for this
MethodDefinition isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - If functionPrototype is present as a parameter, then
- Let kind be
Normal . - Let prototype be functionPrototype.
- Let kind be
- Else,
- Let kind be
Method . - Let prototype be the intrinsic object
%FunctionPrototype% .
- Let kind be
- Let closure be
FunctionCreate (kind,UniqueFormalParameters ,FunctionBody , scope, strict, prototype). - Perform
MakeMethod (closure, object). - Return the
Record { [[Key]]: propKey, [[Closure]]: closure }.
14.3.8 Runtime Semantics: PropertyDefinitionEvaluation
With parameters object and enumerable.
- Let methodDef be DefineMethod of
MethodDefinition with argument object. ReturnIfAbrupt (methodDef).- Perform
SetFunctionName (methodDef.[[Closure]], methodDef.[[Key]]). - Let desc be the PropertyDescriptor { [[Value]]: methodDef.[[Closure]], [[Writable]]:
true , [[Enumerable]]: enumerable, [[Configurable]]:true }. - Return ?
DefinePropertyOrThrow (object, methodDef.[[Key]], desc).
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- If the function code for this
MethodDefinition isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let formalParameterList be an instance of the production
FormalParameters : [empty] - Let closure be
FunctionCreate (Method , formalParameterList,FunctionBody , scope, strict). - Perform
MakeMethod (closure, object). - Perform
SetFunctionName (closure, propKey,"get"). - Let desc be the PropertyDescriptor { [[Get]]: closure, [[Enumerable]]: enumerable, [[Configurable]]:
true }. - Return ?
DefinePropertyOrThrow (object, propKey, desc).
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- If the function code for this
MethodDefinition isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let closure be
FunctionCreate (Method ,PropertySetParameterList ,FunctionBody , scope, strict). - Perform
MakeMethod (closure, object). - Perform
SetFunctionName (closure, propKey,"set"). - Let desc be the PropertyDescriptor { [[Set]]: closure, [[Enumerable]]: enumerable, [[Configurable]]:
true }. - Return ?
DefinePropertyOrThrow (object, propKey, desc).
14.4 Generator Function Definitions
Syntax
The syntactic context immediately following yield requires use of the
14.4.1 Static Semantics: Early Errors
-
It is a Syntax Error if HasDirectSuper of
GeneratorMethod istrue . -
It is a Syntax Error if
UniqueFormalParameters ContainsYieldExpression istrue . -
It is a Syntax Error if ContainsUseStrict of
GeneratorBody istrue and IsSimpleParameterList ofUniqueFormalParameters isfalse . -
It is a Syntax Error if any element of the BoundNames of
UniqueFormalParameters also occurs in the LexicallyDeclaredNames ofGeneratorBody .
-
If the source code matching this production is
strict mode code , the Early Error rules forUniqueFormalParameters : FormalParameters -
If the source code matching this production is
strict mode code , it is a Syntax Error ifBindingIdentifier is present and the StringValue ofBindingIdentifier is"eval"or"arguments". -
It is a Syntax Error if ContainsUseStrict of
GeneratorBody istrue and IsSimpleParameterList ofFormalParameters isfalse . -
It is a Syntax Error if any element of the BoundNames of
FormalParameters also occurs in the LexicallyDeclaredNames ofGeneratorBody . -
It is a Syntax Error if
FormalParameters ContainsYieldExpression istrue . -
It is a Syntax Error if
FormalParameters ContainsSuperProperty istrue . -
It is a Syntax Error if
GeneratorBody ContainsSuperProperty istrue . -
It is a Syntax Error if
FormalParameters ContainsSuperCall istrue . -
It is a Syntax Error if
GeneratorBody ContainsSuperCall istrue .
14.4.2 Static Semantics: BoundNames
- Return the BoundNames of
BindingIdentifier .
- Return «
"*default*"».
"*default*" is used within this specification as a synthetic name for hoistable anonymous functions that are defined using export declarations.
14.4.3 Static Semantics: ComputedPropertyContains
With parameter symbol.
- Return the result of ComputedPropertyContains for
PropertyName with argument symbol.
14.4.4 Static Semantics: Contains
With parameter symbol.
- Return
false .
Static semantic rules that depend upon substructure generally do not look into function definitions.
14.4.5 Static Semantics: HasDirectSuper
- If
UniqueFormalParameters ContainsSuperCall istrue , returntrue . - Return
GeneratorBody ContainsSuperCall .
14.4.6 Static Semantics: HasName
- Return
false .
- Return
true .
14.4.7 Static Semantics: IsConstantDeclaration
- Return
false .
14.4.8 Static Semantics: IsFunctionDefinition
- Return
true .
14.4.9 Static Semantics: PropName
- Return PropName of
PropertyName .
14.4.10 Runtime Semantics: EvaluateBody
With parameters functionObject and
- Perform ?
FunctionDeclarationInstantiation (functionObject, argumentsList). - Let G be ?
OrdinaryCreateFromConstructor (functionObject,"%GeneratorPrototype%", « [[GeneratorState]], [[GeneratorContext]] »). - Perform
GeneratorStart (G,FunctionBody ). - Return
Completion { [[Type]]:return , [[Value]]: G, [[Target]]:empty }.
14.4.11 Runtime Semantics: InstantiateFunctionObject
With parameter scope.
- If the function code for
GeneratorDeclaration isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let name be StringValue of
BindingIdentifier . - Let F be
GeneratorFunctionCreate (Normal ,FormalParameters ,GeneratorBody , scope, strict). - Let prototype be
ObjectCreate (%GeneratorPrototype% ). - Perform
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform
SetFunctionName (F, name). - Return F.
- Let F be
GeneratorFunctionCreate (Normal ,FormalParameters ,GeneratorBody , scope,true ). - Let prototype be
ObjectCreate (%GeneratorPrototype% ). - Perform
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform
SetFunctionName (F,"default"). - Return F.
An anonymous export default declaration, and its function code is therefore always
14.4.12 Runtime Semantics: PropertyDefinitionEvaluation
With parameters object and enumerable.
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- If the function code for this
GeneratorMethod isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let closure be
GeneratorFunctionCreate (Method ,UniqueFormalParameters ,GeneratorBody , scope, strict). - Perform
MakeMethod (closure, object). - Let prototype be
ObjectCreate (%GeneratorPrototype% ). - Perform
DefinePropertyOrThrow (closure,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform
SetFunctionName (closure, propKey). - Let desc be the PropertyDescriptor { [[Value]]: closure, [[Writable]]:
true , [[Enumerable]]: enumerable, [[Configurable]]:true }. - Return ?
DefinePropertyOrThrow (object, propKey, desc).
14.4.13 Runtime Semantics: Evaluation
- If the function code for this
GeneratorExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let closure be
GeneratorFunctionCreate (Normal ,FormalParameters ,GeneratorBody , scope, strict). - Let prototype be
ObjectCreate (%GeneratorPrototype% ). - Perform
DefinePropertyOrThrow (closure,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Return closure.
- If the function code for this
GeneratorExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let funcEnv be
NewDeclarativeEnvironment (scope). - Let envRec be funcEnv's
EnvironmentRecord . - Let name be StringValue of
BindingIdentifier . - Perform envRec.CreateImmutableBinding(name,
false ). - Let closure be
GeneratorFunctionCreate (Normal ,FormalParameters ,GeneratorBody , funcEnv, strict). - Let prototype be
ObjectCreate (%GeneratorPrototype% ). - Perform
DefinePropertyOrThrow (closure,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform
SetFunctionName (closure, name). - Perform envRec.InitializeBinding(name, closure).
- Return closure.
The
- Let generatorKind be !
GetGeneratorKind (). - If generatorKind is
async , then return ?AsyncGeneratorYield (undefined ). - Otherwise, return ?
GeneratorYield (CreateIterResultObject (undefined ,false )).
- Let generatorKind be !
GetGeneratorKind (). - Let exprRef be the result of evaluating
AssignmentExpression . - Let value be ?
GetValue (exprRef). - If generatorKind is
async , then return ?AsyncGeneratorYield (value). - Otherwise, return ?
GeneratorYield (CreateIterResultObject (value,false )).
- Let generatorKind be !
GetGeneratorKind (). - Let exprRef be the result of evaluating
AssignmentExpression . - Let value be ?
GetValue (exprRef). - Let iteratorRecord be ?
GetIterator (value, generatorKind). - Let iterator be iteratorRecord.[[Iterator]].
- Let received be
NormalCompletion (undefined ). - Repeat,
- If received.[[Type]] is
normal , then- Let innerResult be ?
Call (iteratorRecord.[[NextMethod]], iteratorRecord.[[Iterator]], « received.[[Value]] »). - If generatorKind is
async , then set innerResult to ?Await (innerResult). - If
Type (innerResult) is not Object, throw aTypeError exception. - Let done be ?
IteratorComplete (innerResult). - If done is
true , then- Return ?
IteratorValue (innerResult).
- Return ?
- If generatorKind is
async , then set received toAsyncGeneratorYield (?IteratorValue (innerResult)). - Else, set received to
GeneratorYield (innerResult).
- Let innerResult be ?
- Else if received.[[Type]] is
throw , then- Let throw be ?
GetMethod (iterator,"throw"). - If throw is not
undefined , then- Let innerResult be ?
Call (throw, iterator, « received.[[Value]] »). - If generatorKind is
async , then set innerResult to ?Await (innerResult). - NOTE: Exceptions from the inner iterator
throwmethod are propagated. Normal completions from an innerthrowmethod are processed similarly to an innernext. - If
Type (innerResult) is not Object, throw aTypeError exception. - Let done be ?
IteratorComplete (innerResult). - If done is
true , then- Return ?
IteratorValue (innerResult).
- Return ?
- If generatorKind is
async , then set received toAsyncGeneratorYield (?IteratorValue (innerResult)). - Else, set received to
GeneratorYield (innerResult).
- Let innerResult be ?
- Else,
- NOTE: If iterator does not have a
throwmethod, this throw is going to terminate theyield*loop. But first we need to give iterator a chance to clean up. - Let closeCompletion be
Completion { [[Type]]:normal , [[Value]]:empty , [[Target]]:empty }. - If generatorKind is
async , perform ?AsyncIteratorClose (iteratorRecord, closeCompletion). - Else, perform ?
IteratorClose (iteratorRecord, closeCompletion). - NOTE: The next step throws a
TypeError to indicate that there was ayield*protocol violation: iterator does not have athrowmethod. - Throw a
TypeError exception.
- NOTE: If iterator does not have a
- Let throw be ?
- Else,
Assert : received.[[Type]] isreturn .- Let return be ?
GetMethod (iterator,"return"). - If return is
undefined , then- If generatorKind is
async , then set received.[[Value]] to ?Await (received.[[Value]]). - Return
Completion (received).
- If generatorKind is
- Let innerReturnResult be ?
Call (return, iterator, « received.[[Value]] »). - If generatorKind is
async , then set innerReturnResult to ?Await (innerReturnResult). - If
Type (innerReturnResult) is not Object, throw aTypeError exception. - Let done be ?
IteratorComplete (innerReturnResult). - If done is
true , then- Let value be ?
IteratorValue (innerReturnResult). - Return
Completion { [[Type]]:return , [[Value]]: value, [[Target]]:empty }.
- Let value be ?
- If generatorKind is
async , then set received toAsyncGeneratorYield (?IteratorValue (innerReturnResult)). - Else, set received to
GeneratorYield (innerReturnResult).
- If received.[[Type]] is
14.5 Async Generator Function Definitions
Syntax
14.5.1 Static Semantics: Early Errors
- It is a Syntax Error if HasDirectSuper of
AsyncGeneratorMethod istrue . - It is a Syntax Error if
UniqueFormalParameters ContainsYieldExpression istrue . - It is a Syntax Error if
UniqueFormalParameters ContainsAwaitExpression istrue . - It is a Syntax Error if ContainsUseStrict of
AsyncGeneratorBody istrue and IsSimpleParameterList ofUniqueFormalParameters isfalse . - It is a Syntax Error if any element of the BoundNames of
UniqueFormalParameters also occurs in the LexicallyDeclaredNames ofAsyncGeneratorBody .
- If the source code matching this production is
strict mode code , the Early Error rules forUniqueFormalParameters : FormalParameters - If the source code matching this production is
strict mode code , it is a Syntax Error ifBindingIdentifier is theIdentifierName evalor theIdentifierName arguments. - It is a Syntax Error if ContainsUseStrict of
AsyncGeneratorBody istrue and IsSimpleParameterList ofFormalParameters isfalse . - It is a Syntax Error if any element of the BoundNames of
FormalParameters also occurs in the LexicallyDeclaredNames ofAsyncGeneratorBody . - It is a Syntax Error if
FormalParameters ContainsYieldExpression istrue . - It is a Syntax Error if
FormalParameters ContainsAwaitExpression istrue . - It is a Syntax Error if
FormalParameters ContainsSuperProperty istrue . - It is a Syntax Error if
AsyncGeneratorBody ContainsSuperProperty istrue . - It is a Syntax Error if
FormalParameters ContainsSuperCall istrue . - It is a Syntax Error if
AsyncGeneratorBody ContainsSuperCall istrue .
14.5.2 Static Semantics: BoundNames
- Return the BoundNames of
BindingIdentifier .
- Return «
"*default*"».
"*default*" is used within this specification as a synthetic name for hoistable anonymous functions that are defined using export declarations.
14.5.3 Static Semantics: ComputedPropertyContains
With parameter symbol.
- Return the result of ComputedPropertyContains for
PropertyName with argument symbol.
14.5.4 Static Semantics: Contains
With parameter symbol.
- Return
false .
Static semantic rules that depend upon substructure generally do not look into function definitions.
14.5.5 Static Semantics: HasDirectSuper
- If
UniqueFormalParameters ContainsSuperCall istrue , returntrue . - Return
AsyncGeneratorBody ContainsSuperCall .
14.5.6 Static Semantics: HasName
- Return
false .
- Return
true .
14.5.7 Static Semantics: IsConstantDeclaration
- Return
false .
14.5.8 Static Semantics: IsFunctionDefinition
- Return
true .
14.5.9 Static Semantics: PropName
- Return PropName of
PropertyName .
14.5.10 Runtime Semantics: EvaluateBody
With parameters functionObject and
- Perform ?
FunctionDeclarationInstantiation (functionObject, argumentsList). - Let generator be ?
OrdinaryCreateFromConstructor (functionObject,"%AsyncGeneratorPrototype%", « [[AsyncGeneratorState]], [[AsyncGeneratorContext]], [[AsyncGeneratorQueue]] »). - Perform !
AsyncGeneratorStart (generator,FunctionBody ). - Return
Completion { [[Type]]:return , [[Value]]: generator, [[Target]]:empty }.
14.5.11 Runtime Semantics: InstantiateFunctionObject
With parameter scope.
- If the function code for
AsyncGeneratorDeclaration isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let name be StringValue of
BindingIdentifier . - Let F be !
AsyncGeneratorFunctionCreate (Normal ,FormalParameters ,AsyncGeneratorBody , scope, strict). - Let prototype be !
ObjectCreate (%AsyncGeneratorPrototype% ). - Perform !
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform !
SetFunctionName (F, name). - Return F.
- If the function code for
AsyncGeneratorDeclaration isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let F be
AsyncGeneratorFunctionCreate (Normal ,FormalParameters ,AsyncGeneratorBody , scope, strict). - Let prototype be
ObjectCreate (%AsyncGeneratorPrototype% ). - Perform
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform
SetFunctionName (F,"default"). - Return F.
An anonymous export default declaration.
14.5.12 Runtime Semantics: PropertyDefinitionEvaluation
With parameter object and enumerable.
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- If the function code for this
AsyncGeneratorMethod isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let closure be !
AsyncGeneratorFunctionCreate (Method ,UniqueFormalParameters ,AsyncGeneratorBody , scope, strict). - Perform !
MakeMethod (closure, object). - Let prototype be !
ObjectCreate (%AsyncGeneratorPrototype% ). - Perform !
DefinePropertyOrThrow (closure,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform !
SetFunctionName (closure, propKey). - Let desc be PropertyDescriptor { [[Value]]: closure, [[Writable]]:
true , [[Enumerable]]: enumerable, [[Configurable]]:true }. - Return ?
DefinePropertyOrThrow (object, propKey, desc).
14.5.13 Runtime Semantics: Evaluation
- If the function code for this
AsyncGeneratorExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let closure be !
AsyncGeneratorFunctionCreate (Normal ,FormalParameters ,AsyncGeneratorBody , scope, strict). - Let prototype be !
ObjectCreate (%AsyncGeneratorPrototype% ). - Perform !
DefinePropertyOrThrow (closure,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Return closure.
- If the function code for this
AsyncGeneratorExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the
running execution context 's LexicalEnvironment. - Let funcEnv be !
NewDeclarativeEnvironment (scope). - Let envRec be funcEnv's
EnvironmentRecord . - Let name be StringValue of
BindingIdentifier . - Perform ! envRec.CreateImmutableBinding(name).
- Let closure be !
AsyncGeneratorFunctionCreate (Normal ,FormalParameters ,AsyncGeneratorBody , funcEnv, strict). - Let prototype be !
ObjectCreate (%AsyncGeneratorPrototype% ). - Perform !
DefinePropertyOrThrow (closure,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Perform !
SetFunctionName (closure, name). - Perform ! envRec.InitializeBinding(name, closure).
- Return closure.
The
14.6 Class Definitions
Syntax
A class definition is always
14.6.1 Static Semantics: Early Errors
-
It is a Syntax Error if
ClassHeritage is not present and the following algorithm evaluates totrue :- Let constructor be ConstructorMethod of
ClassBody . - If constructor is
empty , returnfalse . - Return HasDirectSuper of constructor.
- Let constructor be ConstructorMethod of
-
It is a Syntax Error if PrototypePropertyNameList of
ClassElementList contains more than one occurrence of"constructor".
-
It is a Syntax Error if PropName of
MethodDefinition is not"constructor"and HasDirectSuper ofMethodDefinition istrue . -
It is a Syntax Error if PropName of
MethodDefinition is"constructor"and SpecialMethod ofMethodDefinition istrue .
-
It is a Syntax Error if HasDirectSuper of
MethodDefinition istrue . -
It is a Syntax Error if PropName of
MethodDefinition is"prototype".
14.6.2 Static Semantics: BoundNames
- Return the BoundNames of
BindingIdentifier .
- Return «
"*default*"».
14.6.3 Static Semantics: ConstructorMethod
- If
ClassElement isClassElement : ; empty . - If IsStatic of
ClassElement istrue , returnempty . - If PropName of
ClassElement is not"constructor", returnempty . - Return
ClassElement .
- Let head be ConstructorMethod of
ClassElementList . - If head is not
empty , return head. - If
ClassElement isClassElement : ; empty . - If IsStatic of
ClassElement istrue , returnempty . - If PropName of
ClassElement is not"constructor", returnempty . - Return
ClassElement .
Early Error rules ensure that there is only one method definition named "constructor" and that it is not an
14.6.4 Static Semantics: Contains
With parameter symbol.
- If symbol is
ClassBody , returntrue . - If symbol is
ClassHeritage , then- If
ClassHeritage is present, returntrue ; otherwise returnfalse .
- If
- Let inHeritage be
ClassHeritage Contains symbol. - If inHeritage is
true , returntrue . - Return the result of ComputedPropertyContains for
ClassBody with argument symbol.
Static semantic rules that depend upon substructure generally do not look into class bodies except for
14.6.5 Static Semantics: ComputedPropertyContains
With parameter symbol.
- Let inList be the result of ComputedPropertyContains for
ClassElementList with argument symbol. - If inList is
true , returntrue . - Return the result of ComputedPropertyContains for
ClassElement with argument symbol.
- Return the result of ComputedPropertyContains for
MethodDefinition with argument symbol.
- Return the result of ComputedPropertyContains for
MethodDefinition with argument symbol.
- Return
false .
14.6.6 Static Semantics: HasName
- Return
false .
- Return
true .
14.6.7 Static Semantics: IsConstantDeclaration
- Return
false .
14.6.8 Static Semantics: IsFunctionDefinition
- Return
true .
14.6.9 Static Semantics: IsStatic
- Return
false .
- Return
true .
- Return
false .
14.6.10 Static Semantics: NonConstructorMethodDefinitions
- If
ClassElement isClassElement : ; List . - If IsStatic of
ClassElement isfalse and PropName ofClassElement is"constructor", return a new emptyList . - Return a
List containingClassElement .
- Let list be NonConstructorMethodDefinitions of
ClassElementList . - If
ClassElement isClassElement : ; - If IsStatic of
ClassElement isfalse and PropName ofClassElement is"constructor", return list. - Append
ClassElement to the end of list. - Return list.
14.6.11 Static Semantics: PrototypePropertyNameList
- If PropName of
ClassElement isempty , return a new emptyList . - If IsStatic of
ClassElement istrue , return a new emptyList . - Return a
List containing PropName ofClassElement .
- Let list be PrototypePropertyNameList of
ClassElementList . - If PropName of
ClassElement isempty , return list. - If IsStatic of
ClassElement istrue , return list. - Append PropName of
ClassElement to the end of list. - Return list.
14.6.12 Static Semantics: PropName
- Return
empty .
14.6.13 Runtime Semantics: ClassDefinitionEvaluation
With parameter className.
- Let lex be the LexicalEnvironment of the
running execution context . - Let classScope be
NewDeclarativeEnvironment (lex). - Let classScopeEnvRec be classScope's
EnvironmentRecord . - If className is not
undefined , then- Perform classScopeEnvRec.CreateImmutableBinding(className,
true ).
- Perform classScopeEnvRec.CreateImmutableBinding(className,
- If
ClassHeritage is not present, thenopt - Let protoParent be the intrinsic object
%ObjectPrototype% . - Let constructorParent be the intrinsic object
%FunctionPrototype% .
- Let protoParent be the intrinsic object
- Else,
- Set the
running execution context 's LexicalEnvironment to classScope. - Let superclass be the result of evaluating
ClassHeritage . - Set the
running execution context 's LexicalEnvironment to lex. ReturnIfAbrupt (superclass).- If superclass is
null , then- Let protoParent be
null . - Let constructorParent be the intrinsic object
%FunctionPrototype% .
- Let protoParent be
- Else if
IsConstructor (superclass) isfalse , throw aTypeError exception. - Else,
- Set the
- Let proto be
ObjectCreate (protoParent). - If
ClassBody is not present, let constructor beopt empty . - Else, let constructor be ConstructorMethod of
ClassBody . - If constructor is
empty , then- If
ClassHeritage is present, thenopt - Set constructor to the result of parsing the source text
constructor(... args){ super (...args);}goal symbol MethodDefinition .[~Yield, ~Await]
- Set constructor to the result of parsing the source text
- Else,
- Set constructor to the result of parsing the source text
constructor(){ }goal symbol MethodDefinition .[~Yield, ~Await]
- Set constructor to the result of parsing the source text
- If
- Set the
running execution context 's LexicalEnvironment to classScope. - Let constructorInfo be the result of performing DefineMethod for constructor with arguments proto and constructorParent as the optional functionPrototype argument.
Assert : constructorInfo is not anabrupt completion .- Let F be constructorInfo.[[Closure]].
- If
ClassHeritage is present, set F.[[ConstructorKind]] toopt "derived". - Perform
MakeConstructor (F,false , proto). - Perform
MakeClassConstructor (F). - Perform
CreateMethodProperty (proto,"constructor", F). - If
ClassBody is not present, let methods be a new emptyopt List . - Else, let methods be NonConstructorMethodDefinitions of
ClassBody . - For each
ClassElement m in order from methods, do- If IsStatic of m is
false , then- Let status be the result of performing PropertyDefinitionEvaluation for m with arguments proto and
false .
- Let status be the result of performing PropertyDefinitionEvaluation for m with arguments proto and
- Else,
- Let status be the result of performing PropertyDefinitionEvaluation for m with arguments F and
false .
- Let status be the result of performing PropertyDefinitionEvaluation for m with arguments F and
- If status is an
abrupt completion , then- Set the
running execution context 's LexicalEnvironment to lex. - Return
Completion (status).
- Set the
- If IsStatic of m is
- Set the
running execution context 's LexicalEnvironment to lex. - If className is not
undefined , then- Perform classScopeEnvRec.InitializeBinding(className, F).
- Return F.
14.6.14 Runtime Semantics: BindingClassDeclarationEvaluation
- Let className be StringValue of
BindingIdentifier . - Let value be the result of ClassDefinitionEvaluation of
ClassTail with argument className. ReturnIfAbrupt (value).- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , performSetFunctionName (value, className). - Let env be the
running execution context 's LexicalEnvironment. - Perform ?
InitializeBoundName (className, value, env). - Return value.
- Return the result of ClassDefinitionEvaluation of
ClassTail with argumentundefined .
14.6.15 Runtime Semantics: Evaluation
- Perform ? BindingClassDeclarationEvaluation of this
ClassDeclaration . - Return
NormalCompletion (empty ).
- If
BindingIdentifier is not present, let className beopt undefined . - Else, let className be StringValue of
BindingIdentifier . - Let value be the result of ClassDefinitionEvaluation of
ClassTail with argument className. ReturnIfAbrupt (value).- If className is not
undefined , then- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , then- Perform
SetFunctionName (value, className).
- Perform
- Let hasNameProperty be ?
- Return
NormalCompletion (value).
If the class definition included a name static method then that method is not over-written with a name
14.7 Async Function Definitions
Syntax
await is parsed as an
- In an
AsyncFunctionBody . - In the
FormalParameters of anAsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration , orAsyncGeneratorExpression .AwaitExpression in this position is a Syntax error viastatic semantics .
When await is parsed as a await may be parsed as an identifier when the [Await] parameter is absent. This includes the following contexts:
- Anywhere outside of an
AsyncFunctionBody orFormalParameters of anAsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration , orAsyncGeneratorExpression . - In the
BindingIdentifier of aFunctionExpression ,GeneratorExpression , orAsyncGeneratorExpression .
Unlike
14.7.1 Static Semantics: Early Errors
- It is a Syntax Error if ContainsUseStrict of
AsyncFunctionBody istrue and IsSimpleParameterList ofUniqueFormalParameters isfalse . - It is a Syntax Error if HasDirectSuper of
AsyncMethod istrue . - It is a Syntax Error if
UniqueFormalParameters ContainsAwaitExpression istrue . - It is a Syntax Error if any element of the BoundNames of
UniqueFormalParameters also occurs in the LexicallyDeclaredNames ofAsyncFunctionBody .
- It is a Syntax Error if ContainsUseStrict of
AsyncFunctionBody istrue and IsSimpleParameterList ofFormalParameters isfalse . - It is a Syntax Error if
FormalParameters ContainsAwaitExpression istrue . - If the source code matching this production is strict code, the Early Error rules for
UniqueFormalParameters : FormalParameters - If the source code matching this production is strict code, it is a Syntax Error if
BindingIdentifier is present and the StringValue ofBindingIdentifier is"eval"or"arguments". - It is a Syntax Error if any element of the BoundNames of
FormalParameters also occurs in the LexicallyDeclaredNames ofAsyncFunctionBody . - It is a Syntax Error if
FormalParameters ContainsSuperProperty istrue . - It is a Syntax Error if
AsyncFunctionBody ContainsSuperProperty istrue . - It is a Syntax Error if
FormalParameters ContainsSuperCall istrue . - It is a Syntax Error if
AsyncFunctionBody ContainsSuperCall istrue .
14.7.2 Static Semantics: BoundNames
- Return the BoundNames of
BindingIdentifier .
- Return «
"*default*"».
*default*" is used within this specification as a synthetic name for hoistable anonymous functions that are defined using export declarations.14.7.3 Static Semantics: ComputedPropertyContains
With parameter symbol.
- Return the result of ComputedPropertyContains for
PropertyName with argument symbol.
14.7.4 Static Semantics: Contains
With parameter symbol.
- Return
false .
14.7.5 Static Semantics: HasDirectSuper
- If
UniqueFormalParameters ContainsSuperCall istrue , returntrue . - Return
AsyncFunctionBody ContainsSuperCall .
14.7.6 Static Semantics: HasName
- Return
false .
- Return
true .
14.7.7 Static Semantics: IsConstantDeclaration
- Return
false .
14.7.8 Static Semantics: IsFunctionDefinition
- Return
true .
14.7.9 Static Semantics: PropName
- Return PropName of
PropertyName .
14.7.10 Runtime Semantics: InstantiateFunctionObject
With parameter scope.
- If the function code for
AsyncFunctionDeclaration isstrict mode code , let strict betrue . Otherwise, let strict befalse . - Let name be StringValue of
BindingIdentifier . - Let F be !
AsyncFunctionCreate (Normal ,FormalParameters ,AsyncFunctionBody , scope, strict). - Perform !
SetFunctionName (F, name). - Return F.
- If the function code for
AsyncFunctionDeclaration isstrict mode code , let strict betrue . Otherwise, let strict befalse . - Let F be !
AsyncFunctionCreate (Normal ,FormalParameters ,AsyncFunctionBody , scope, strict). - Perform !
SetFunctionName (F,"default"). - Return F.
14.7.11 Runtime Semantics: EvaluateBody
With parameters functionObject and
- Let promiseCapability be !
NewPromiseCapability (%Promise% ). - Let declResult be
FunctionDeclarationInstantiation (functionObject, argumentsList). - If declResult is not an
abrupt completion , then- Perform !
AsyncFunctionStart (promiseCapability,FunctionBody ).
- Perform !
- Else declResult is an
abrupt completion ,- Perform !
Call (promiseCapability.[[Reject]],undefined , « declResult.[[Value]] »).
- Perform !
- Return
Completion { [[Type]]:return , [[Value]]: promiseCapability.[[Promise]], [[Target]]:empty }.
14.7.12 Runtime Semantics: PropertyDefinitionEvaluation
With parameters object and enumerable.
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- If the function code for this
AsyncMethod isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let closure be !
AsyncFunctionCreate (Method ,UniqueFormalParameters ,AsyncFunctionBody , scope, strict). - Perform !
MakeMethod (closure, object). - Perform !
SetFunctionName (closure, propKey). - Let desc be the PropertyDescriptor { [[Value]]: closure, [[Writable]]:
true , [[Enumerable]]: enumerable, [[Configurable]]:true }. - Return ?
DefinePropertyOrThrow (object, propKey, desc).
14.7.13 Runtime Semantics: Evaluation
- Return
NormalCompletion (empty ).
- Return
NormalCompletion (empty ).
- If the function code for
AsyncFunctionExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let closure be !
AsyncFunctionCreate (Normal ,FormalParameters ,AsyncFunctionBody , scope, strict). - Return closure.
- If the function code for
AsyncFunctionExpression isstrict mode code , let strict betrue . Otherwise let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let funcEnv be !
NewDeclarativeEnvironment (scope). - Let envRec be funcEnv's
EnvironmentRecord . - Let name be StringValue of
BindingIdentifier . - Perform ! envRec.CreateImmutableBinding(name).
- Let closure be !
AsyncFunctionCreate (Normal ,FormalParameters ,AsyncFunctionBody , funcEnv, strict). - Perform !
SetFunctionName (closure, name). - Perform ! envRec.InitializeBinding(name, closure).
- Return closure.
- Let exprRef be the result of evaluating
UnaryExpression . - Let value be ?
GetValue (exprRef). - Return ?
Await (value).
14.8 Async Arrow Function Definitions
Syntax
Supplemental Syntax
When processing an instance of the production
14.8.1 Static Semantics: Early Errors
- It is a Syntax Error if any element of the BoundNames of
AsyncArrowBindingIdentifier also occurs in the LexicallyDeclaredNames ofAsyncConciseBody .
- It is a Syntax Error if
CoverCallExpressionAndAsyncArrowHead ContainsYieldExpression istrue . - It is a Syntax Error if
CoverCallExpressionAndAsyncArrowHead ContainsAwaitExpression istrue . - It is a Syntax Error if
CoverCallExpressionAndAsyncArrowHead is notcovering anAsyncArrowHead . - It is a Syntax Error if any element of the BoundNames of
CoverCallExpressionAndAsyncArrowHead also occurs in the LexicallyDeclaredNames ofAsyncConciseBody . - It is a Syntax Error if ContainsUseStrict of
AsyncConciseBody istrue and IsSimpleParameterList ofCoverCallExpressionAndAsyncArrowHead isfalse . - All Early Error rules for
AsyncArrowHead and its derived productions apply to CoveredAsyncArrowHead ofCoverCallExpressionAndAsyncArrowHead .
14.8.2 Static Semantics: CoveredAsyncArrowHead
- Return the
AsyncArrowHead that iscovered byCoverCallExpressionAndAsyncArrowHead .
14.8.3 Static Semantics: BoundNames
- Let head be CoveredAsyncArrowHead of
CoverCallExpressionAndAsyncArrowHead . - Return the BoundNames of head.
14.8.4 Static Semantics: Contains
With parameter symbol.
- If symbol is not one of
NewTarget ,SuperProperty ,SuperCall ,super, orthis, returnfalse . - Return
AsyncConciseBody Contains symbol.
- If symbol is not one of
NewTarget ,SuperProperty ,SuperCall ,super, orthis, returnfalse . - Let head be CoveredAsyncArrowHead of
CoverCallExpressionAndAsyncArrowHead . - If head Contains symbol is
true , returntrue . - Return
AsyncConciseBody Contains symbol.
new.target, this, and super usage within an AsyncArrowFunction.14.8.5 Static Semantics: ContainsExpression
- Return
false .
14.8.6 Static Semantics: ExpectedArgumentCount
- Return 1.
14.8.7 Static Semantics: HasName
- Return
false .
14.8.8 Static Semantics: IsSimpleParameterList
- Return
true .
- Let head be CoveredAsyncArrowHead of
CoverCallExpressionAndAsyncArrowHead . - Return IsSimpleParameterList of head.
14.8.9 Static Semantics: LexicallyDeclaredNames
- Return a new empty
List .
14.8.10 Static Semantics: LexicallyScopedDeclarations
- Return a new empty
List .
14.8.11 Static Semantics: VarDeclaredNames
- Return a new empty
List .
14.8.12 Static Semantics: VarScopedDeclarations
- Return a new empty
List .
14.8.13 Runtime Semantics: IteratorBindingInitialization
With parameters iteratorRecord and environment.
Assert : iteratorRecord.[[Done]] isfalse .- Let next be ?
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , set iteratorRecord.[[Done]] totrue . - Else,
- Let v be ?
IteratorValue (next). - If v is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (v).
- Let v be ?
- If iteratorRecord.[[Done]] is
true , let v beundefined . - Return the result of performing BindingInitialization for
BindingIdentifier using v and environment as the arguments.
14.8.14 Runtime Semantics: EvaluateBody
With parameters functionObject and
- Let promiseCapability be !
NewPromiseCapability (%Promise% ). - Let declResult be
FunctionDeclarationInstantiation (functionObject, argumentsList). - If declResult is not an
abrupt completion , then- Perform !
AsyncFunctionStart (promiseCapability,AssignmentExpression ).
- Perform !
- Else declResult is an
abrupt completion ,- Perform !
Call (promiseCapability.[[Reject]],undefined , « declResult.[[Value]] »).
- Perform !
- Return
Completion { [[Type]]:return , [[Value]]: promiseCapability.[[Promise]], [[Target]]:empty }.
- Return the result of EvaluateBody of
AsyncFunctionBody passing functionObject and argumentsList as the arguments.
14.8.15 Runtime Semantics: Evaluation
- If the function code for this
AsyncArrowFunction isstrict mode code , let strict betrue . Otherwise, let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let parameters be
AsyncArrowBindingIdentifier . - Let closure be !
AsyncFunctionCreate (Arrow , parameters,AsyncConciseBody , scope, strict). - Return closure.
- If the function code for this
AsyncArrowFunction isstrict mode code , let strict betrue . Otherwise, let strict befalse . - Let scope be the LexicalEnvironment of the
running execution context . - Let head be CoveredAsyncArrowHead of
CoverCallExpressionAndAsyncArrowHead . - Let parameters be the
ArrowFormalParameters of head. - Let closure be !
AsyncFunctionCreate (Arrow , parameters,AsyncConciseBody , scope, strict). - Return closure.
14.9 Tail Position Calls
14.9.1 Static Semantics: IsInTailPosition ( call )
The abstract operation IsInTailPosition with argument call performs the following steps:
Assert : call is aParse Node .- If the source code matching call is
non-strict code , returnfalse . - If call is not contained within a
FunctionBody ,ConciseBody , orAsyncConciseBody , returnfalse . - Let body be the
FunctionBody ,ConciseBody , orAsyncConciseBody that most closely contains call. - If body is the
FunctionBody of aGeneratorBody , returnfalse . - If body is the
FunctionBody of anAsyncFunctionBody , returnfalse . - If body is the
FunctionBody of anAsyncGeneratorBody , returnfalse . - If body is an
AsyncConciseBody , returnfalse . - Return the result of HasCallInTailPosition of body with argument call.
Tail Position calls are only defined in
14.9.2 Static Semantics: HasCallInTailPosition
With parameter call.
call is a
14.9.2.1 Statement Rules
- Return HasCallInTailPosition of
AssignmentExpression with argument call.
- Let has be HasCallInTailPosition of
StatementList with argument call. - If has is
true , returntrue . - Return HasCallInTailPosition of
StatementListItem with argument call.
- Return
false .
- Return HasCallInTailPosition of
Statement with argument call.
- Return HasCallInTailPosition of
LabelledItem with argument call.
- Return HasCallInTailPosition of
Expression with argument call.
- Return HasCallInTailPosition of
CaseBlock with argument call.
- Let has be
false . - If the first
CaseClauses is present, let has be HasCallInTailPosition of the firstCaseClauses with argument call. - If has is
true , returntrue . - Let has be HasCallInTailPosition of the
DefaultClause with argument call. - If has is
true , returntrue . - If the second
CaseClauses is present, let has be HasCallInTailPosition of the secondCaseClauses with argument call. - Return has.
- Let has be HasCallInTailPosition of
CaseClauses with argument call. - If has is
true , returntrue . - Return HasCallInTailPosition of
CaseClause with argument call.
- If
StatementList is present, return HasCallInTailPosition ofStatementList with argument call. - Return
false .
- Return HasCallInTailPosition of
Catch with argument call.
- Return HasCallInTailPosition of
Finally with argument call.
- Return HasCallInTailPosition of
Block with argument call.
14.9.2.2 Expression Rules
- Return
false .
- Return HasCallInTailPosition of
AssignmentExpression with argument call.
- Let has be HasCallInTailPosition of the first
AssignmentExpression with argument call. - If has is
true , returntrue . - Return HasCallInTailPosition of the second
AssignmentExpression with argument call.
- Return HasCallInTailPosition of
BitwiseORExpression with argument call.
- Return HasCallInTailPosition of
LogicalANDExpression with argument call.
- If this
CallExpression is call, returntrue . - Return
false .
- If this
MemberExpression is call, returntrue . - Return
false .
- Let expr be CoveredParenthesizedExpression of
CoverParenthesizedExpressionAndArrowParameterList . - Return HasCallInTailPosition of expr with argument call.
- Return HasCallInTailPosition of
Expression with argument call.
14.9.3 Runtime Semantics: PrepareForTailCall ( )
The abstract operation PrepareForTailCall performs the following steps:
- Let leafContext be the
running execution context . Suspend leafContext.- Pop leafContext from the
execution context stack . Theexecution context now on the top of the stack becomes therunning execution context . Assert : leafContext has no further use. It will never be activated as therunning execution context .
A tail position call must either release any transient internal resources associated with the currently executing function
For example, a tail position call should only grow an implementation's activation record stack by the amount that the size of the target function's activation record exceeds the size of the calling function's activation record. If the target function's activation record is smaller, then the total size of the stack should decrease.
15 ECMAScript Language: Scripts and Modules
15.1 Scripts
Syntax
15.1.1 Static Semantics: Early Errors
-
It is a Syntax Error if the LexicallyDeclaredNames of
ScriptBody contains any duplicate entries. -
It is a Syntax Error if any element of the LexicallyDeclaredNames of
ScriptBody also occurs in the VarDeclaredNames ofScriptBody .
-
It is a Syntax Error if
StatementList Containssuperunless the source code containingsuperis eval code that is being processed by adirect eval . Additionalearly error rules forsuperwithindirect eval are defined in18.2.1.1 . -
It is a Syntax Error if
StatementList ContainsNewTarget unless the source code containingNewTarget is eval code that is being processed by adirect eval . Additionalearly error rules forNewTarget indirect eval are defined in18.2.1.1 . -
It is a Syntax Error if ContainsDuplicateLabels of
StatementList with argument « » istrue . -
It is a Syntax Error if ContainsUndefinedBreakTarget of
StatementList with argument « » istrue . -
It is a Syntax Error if ContainsUndefinedContinueTarget of
StatementList with arguments « » and « » istrue .
15.1.2 Static Semantics: IsStrict
- If the
Directive Prologue ofStatementList contains aUse Strict Directive , returntrue ; otherwise, returnfalse .
15.1.3 Static Semantics: LexicallyDeclaredNames
- Return TopLevelLexicallyDeclaredNames of
StatementList .
At the top level of a
15.1.4 Static Semantics: LexicallyScopedDeclarations
- Return TopLevelLexicallyScopedDeclarations of
StatementList .
15.1.5 Static Semantics: VarDeclaredNames
- Return TopLevelVarDeclaredNames of
StatementList .
15.1.6 Static Semantics: VarScopedDeclarations
- Return TopLevelVarScopedDeclarations of
StatementList .
15.1.7 Runtime Semantics: Evaluation
- Return
NormalCompletion (undefined ).
15.1.8 Script Records
A Script Record encapsulates information about a script being evaluated. Each script record contains the fields listed in
| Field Name | Value Type | Meaning |
|---|---|---|
| [[Realm]] |
|
The |
| [[Environment]] |
|
The |
| [[ECMAScriptCode]] |
a |
The result of parsing the source text of this module using |
| [[HostDefined]] |
Any, default value is |
Field reserved for use by host environments that need to associate additional information with a script. |
15.1.9 ParseScript ( sourceText, realm, hostDefined )
The abstract operation ParseScript with arguments sourceText, realm, and hostDefined creates a
Assert : sourceText is an ECMAScript source text (see clause10 ).- Parse sourceText using
Script as thegoal symbol and analyse the parse result for any Early Error conditions. If the parse was successful and no early errors were found, let body be the resulting parse tree. Otherwise, let body be aList of one or moreSyntaxError orReferenceError objects representing the parsing errors and/or early errors. Parsing andearly error detection may be interweaved in an implementation-dependent manner. If more than one parsing error orearly error is present, the number and ordering of error objects in the list is implementation-dependent, but at least one must be present. - If body is a
List of errors, return body. - Return
Script Record { [[Realm]]: realm, [[Environment]]:undefined , [[ECMAScriptCode]]: body, [[HostDefined]]: hostDefined }.
An implementation may parse script source text and analyse it for Early Error conditions prior to evaluation of ParseScript for that script source text. However, the reporting of any errors must be deferred until the point where this specification actually performs ParseScript upon that source text.
15.1.10 ScriptEvaluation ( scriptRecord )
- Let globalEnv be scriptRecord.[[Realm]].[[GlobalEnv]].
- Let scriptCxt be a new ECMAScript code
execution context . - Set the Function of scriptCxt to
null . - Set the
Realm of scriptCxt to scriptRecord.[[Realm]]. - Set the ScriptOrModule of scriptCxt to scriptRecord.
- Set the VariableEnvironment of scriptCxt to globalEnv.
- Set the LexicalEnvironment of scriptCxt to globalEnv.
Suspend the currentlyrunning execution context .- Push scriptCxt on to the
execution context stack ; scriptCxt is now therunning execution context . - Let scriptBody be scriptRecord.[[ECMAScriptCode]].
- Let result be
GlobalDeclarationInstantiation (scriptBody, globalEnv). - If result.[[Type]] is
normal , then- Set result to the result of evaluating scriptBody.
- If result.[[Type]] is
normal and result.[[Value]] isempty , then- Set result to
NormalCompletion (undefined ).
- Set result to
Suspend scriptCxt and remove it from theexecution context stack .Assert : Theexecution context stack is not empty.- Resume the context that is now on the top of the
execution context stack as therunning execution context . - Return
Completion (result).
15.1.11 Runtime Semantics: GlobalDeclarationInstantiation ( script, env )
When an
GlobalDeclarationInstantiation is performed as follows using arguments script and env. script is the
- Let envRec be env's
EnvironmentRecord . Assert : envRec is a globalEnvironment Record .- Let lexNames be the LexicallyDeclaredNames of script.
- Let varNames be the VarDeclaredNames of script.
- For each name in lexNames, do
- If envRec.HasVarDeclaration(name) is
true , throw aSyntaxError exception. - If envRec.HasLexicalDeclaration(name) is
true , throw aSyntaxError exception. - Let hasRestrictedGlobal be ? envRec.HasRestrictedGlobalProperty(name).
- If hasRestrictedGlobal is
true , throw aSyntaxError exception.
- If envRec.HasVarDeclaration(name) is
- For each name in varNames, do
- If envRec.HasLexicalDeclaration(name) is
true , throw aSyntaxError exception.
- If envRec.HasLexicalDeclaration(name) is
- Let varDeclarations be the VarScopedDeclarations of script.
- Let functionsToInitialize be a new empty
List . - Let declaredFunctionNames be a new empty
List . - For each d in varDeclarations, in reverse list order, do
- If d is neither a
VariableDeclaration nor aForBinding nor aBindingIdentifier , thenAssert : d is either aFunctionDeclaration , aGeneratorDeclaration , anAsyncFunctionDeclaration , or anAsyncGeneratorDeclaration .- NOTE: If there are multiple function declarations for the same name, the last declaration is used.
- Let fn be the sole element of the BoundNames of d.
- If fn is not an element of declaredFunctionNames, then
- Let fnDefinable be ? envRec.CanDeclareGlobalFunction(fn).
- If fnDefinable is
false , throw aTypeError exception. - Append fn to declaredFunctionNames.
- Insert d as the first element of functionsToInitialize.
- If d is neither a
- Let declaredVarNames be a new empty
List . - For each d in varDeclarations, do
- If d is a
VariableDeclaration , aForBinding , or aBindingIdentifier , then- For each String vn in the BoundNames of d, do
- If vn is not an element of declaredFunctionNames, then
- Let vnDefinable be ? envRec.CanDeclareGlobalVar(vn).
- If vnDefinable is
false , throw aTypeError exception. - If vn is not an element of declaredVarNames, then
- Append vn to declaredVarNames.
- If vn is not an element of declaredFunctionNames, then
- For each String vn in the BoundNames of d, do
- If d is a
- NOTE: No abnormal terminations occur after this algorithm step if the
global object is an ordinary object. However, if theglobal object is a Proxyexotic object it may exhibit behaviours that cause abnormal terminations in some of the following steps. - NOTE: Annex
B.3.3.2 adds additional steps at this point. - Let lexDeclarations be the LexicallyScopedDeclarations of script.
- For each element d in lexDeclarations, do
- NOTE: Lexically declared names are only instantiated here but not initialized.
- For each element dn of the BoundNames of d, do
- If IsConstantDeclaration of d is
true , then- Perform ? envRec.CreateImmutableBinding(dn,
true ).
- Perform ? envRec.CreateImmutableBinding(dn,
- Else,
- Perform ? envRec.CreateMutableBinding(dn,
false ).
- Perform ? envRec.CreateMutableBinding(dn,
- If IsConstantDeclaration of d is
- For each
Parse Node f in functionsToInitialize, do- Let fn be the sole element of the BoundNames of f.
- Let fo be the result of performing InstantiateFunctionObject for f with argument env.
- Perform ? envRec.CreateGlobalFunctionBinding(fn, fo,
false ).
- For each String vn in declaredVarNames, in list order, do
- Perform ? envRec.CreateGlobalVarBinding(vn,
false ).
- Perform ? envRec.CreateGlobalVarBinding(vn,
- Return
NormalCompletion (empty ).
Early errors specified in
Unlike explicit var or function declarations, properties that are directly created on the
15.1.12 Runtime Semantics: ScriptEvaluationJob ( sourceText, hostDefined )
The job ScriptEvaluationJob with parameters sourceText and hostDefined parses, validates, and evaluates sourceText as a
Assert : sourceText is an ECMAScript source text (see clause10 ).- Let realm be
the current Realm Record . - Let s be
ParseScript (sourceText, realm, hostDefined). - If s is a
List of errors, then- Perform
HostReportErrors (s). - Return
NormalCompletion (undefined ).
- Perform
- Return ?
ScriptEvaluation (s).
15.2 Modules
Syntax
15.2.1 Module Semantics
15.2.1.1 Static Semantics: Early Errors
-
It is a Syntax Error if the LexicallyDeclaredNames of
ModuleItemList contains any duplicate entries. -
It is a Syntax Error if any element of the LexicallyDeclaredNames of
ModuleItemList also occurs in the VarDeclaredNames ofModuleItemList . -
It is a Syntax Error if the ExportedNames of
ModuleItemList contains any duplicate entries. -
It is a Syntax Error if any element of the ExportedBindings of
ModuleItemList does not also occur in either the VarDeclaredNames ofModuleItemList , or the LexicallyDeclaredNames ofModuleItemList . -
It is a Syntax Error if
ModuleItemList Containssuper. -
It is a Syntax Error if
ModuleItemList ContainsNewTarget . -
It is a Syntax Error if ContainsDuplicateLabels of
ModuleItemList with argument « » istrue . -
It is a Syntax Error if ContainsUndefinedBreakTarget of
ModuleItemList with argument « » istrue . -
It is a Syntax Error if ContainsUndefinedContinueTarget of
ModuleItemList with arguments « » and « » istrue .
The duplicate ExportedNames rule implies that multiple export default
15.2.1.2 Static Semantics: ContainsDuplicateLabels
With parameter labelSet.
- Let hasDuplicates be ContainsDuplicateLabels of
ModuleItemList with argument labelSet. - If hasDuplicates is
true , returntrue . - Return ContainsDuplicateLabels of
ModuleItem with argument labelSet.
- Return
false .
15.2.1.3 Static Semantics: ContainsUndefinedBreakTarget
With parameter labelSet.
- Let hasUndefinedLabels be ContainsUndefinedBreakTarget of
ModuleItemList with argument labelSet. - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedBreakTarget of
ModuleItem with argument labelSet.
- Return
false .
15.2.1.4 Static Semantics: ContainsUndefinedContinueTarget
With parameters iterationSet and labelSet.
- Let hasUndefinedLabels be ContainsUndefinedContinueTarget of
ModuleItemList with arguments iterationSet and « ». - If hasUndefinedLabels is
true , returntrue . - Return ContainsUndefinedContinueTarget of
ModuleItem with arguments iterationSet and « ».
- Return
false .
15.2.1.5 Static Semantics: ExportedBindings
ExportedBindings are the locally bound names that are explicitly associated with a
- Let names be ExportedBindings of
ModuleItemList . - Append to names the elements of the ExportedBindings of
ModuleItem . - Return names.
- Return a new empty
List .
15.2.1.6 Static Semantics: ExportedNames
ExportedNames are the externally visible names that a
- Let names be ExportedNames of
ModuleItemList . - Append to names the elements of the ExportedNames of
ModuleItem . - Return names.
- Return the ExportedNames of
ExportDeclaration .
- Return a new empty
List .
15.2.1.7 Static Semantics: ExportEntries
- Return a new empty
List .
- Let entries be ExportEntries of
ModuleItemList . - Append to entries the elements of the ExportEntries of
ModuleItem . - Return entries.
- Return a new empty
List .
15.2.1.8 Static Semantics: ImportEntries
- Return a new empty
List .
- Let entries be ImportEntries of
ModuleItemList . - Append to entries the elements of the ImportEntries of
ModuleItem . - Return entries.
- Return a new empty
List .
15.2.1.9 Static Semantics: ImportedLocalNames ( importEntries )
The abstract operation ImportedLocalNames with argument importEntries creates a
- Let localNames be a new empty
List . - For each
ImportEntry Record i in importEntries, do- Append i.[[LocalName]] to localNames.
- Return localNames.
15.2.1.10 Static Semantics: ModuleRequests
- Return a new empty
List .
- Return ModuleRequests of
ModuleItem .
- Let moduleNames be ModuleRequests of
ModuleItemList . - Let additionalNames be ModuleRequests of
ModuleItem . - Append to moduleNames each element of additionalNames that is not already an element of moduleNames.
- Return moduleNames.
- Return a new empty
List .
15.2.1.11 Static Semantics: LexicallyDeclaredNames
The LexicallyDeclaredNames of a
- Let names be LexicallyDeclaredNames of
ModuleItemList . - Append to names the elements of the LexicallyDeclaredNames of
ModuleItem . - Return names.
- Return the BoundNames of
ImportDeclaration .
- If
ExportDeclaration isexportVariableStatement , return a new emptyList . - Return the BoundNames of
ExportDeclaration .
- Return LexicallyDeclaredNames of
StatementListItem .
At the top level of a
15.2.1.12 Static Semantics: LexicallyScopedDeclarations
- Return a new empty
List .
- Let declarations be LexicallyScopedDeclarations of
ModuleItemList . - Append to declarations the elements of the LexicallyScopedDeclarations of
ModuleItem . - Return declarations.
- Return a new empty
List .
15.2.1.13 Static Semantics: VarDeclaredNames
- Return a new empty
List .
- Let names be VarDeclaredNames of
ModuleItemList . - Append to names the elements of the VarDeclaredNames of
ModuleItem . - Return names.
- Return a new empty
List .
- If
ExportDeclaration isexportVariableStatement , return BoundNames ofExportDeclaration . - Return a new empty
List .
15.2.1.14 Static Semantics: VarScopedDeclarations
- Return a new empty
List .
- Let declarations be VarScopedDeclarations of
ModuleItemList . - Append to declarations the elements of the VarScopedDeclarations of
ModuleItem . - Return declarations.
- Return a new empty
List .
- If
ExportDeclaration isexportVariableStatement , return VarScopedDeclarations ofVariableStatement . - Return a new empty
List .
15.2.1.15 Abstract Module Records
A Module Record encapsulates structural information about the imports and exports of a single module. This information is used to link the imports and exports of sets of connected modules. A Module Record includes four fields that are only used when evaluating a module.
For specification purposes Module Record values are values of the
Module Record defines the fields listed in
| Field Name | Value Type | Meaning |
|---|---|---|
| [[Realm]] |
|
The |
| [[Environment]] |
|
The |
| [[Namespace]] |
Object | |
The Module Namespace Object ( |
| [[HostDefined]] |
Any, default value is |
Field reserved for use by host environments that need to associate additional information with a module. |
| Method | Purpose |
|---|---|
| GetExportedNames(exportStarSet) | Return a list of all names that are either directly or indirectly exported from this module. |
| ResolveExport(exportName, resolveSet) |
Return the binding of a name exported by this module. Bindings are represented by a ResolvedBinding Record, of the form { [[Module]]: This operation must be idempotent if it completes normally. Each time it is called with a specific exportName, resolveSet pair as arguments it must return the same result. |
| Instantiate() |
Prepare the module for evaluation by transitively resolving all module dependencies and creating a module |
| Evaluate() |
If this module has already been evaluated successfully, return Instantiate must have completed successfully prior to invoking this method. |
15.2.1.16 Source Text Module Records
A Source Text Module Record is used to represent information about a module that was defined from ECMAScript source text (
A
In addition to the fields, defined in
| Field Name | Value Type | Meaning |
|---|---|---|
| [[ECMAScriptCode]] |
a |
The result of parsing the source text of this module using |
| [[RequestedModules]] |
|
A |
| [[ImportEntries]] |
|
A |
| [[LocalExportEntries]] |
|
A |
| [[IndirectExportEntries]] |
|
A |
| [[StarExportEntries]] |
|
A |
| [[Status]] | String |
Initially "uninstantiated". Transitions to "instantiating", "instantiated", "evaluating", "evaluated" (in that order) as the module progresses throughout its lifecycle.
|
| [[EvaluationError]] |
An |
A completion of type "evaluated".
|
| [[DFSIndex]] |
|
Auxiliary field used during Instantiate and Evaluate only.
If [[Status]] is "instantiating" or "evaluating", this non-negative number records the point at which the module was first visited during the ongoing depth-first traversal of the dependency graph.
|
| [[DFSAncestorIndex]] |
|
Auxiliary field used during Instantiate and Evaluate only. If [[Status]] is "instantiating" or "evaluating", this is either the module's own [[DFSIndex]] or that of an "earlier" module in the same strongly connected component.
|
An ImportEntry Record is a
| Field Name | Value Type | Meaning |
|---|---|---|
| [[ModuleRequest]] | String |
String value of the |
| [[ImportName]] | String |
The name under which the desired binding is exported by the module identified by [[ModuleRequest]]. The value "*" indicates that the import request is for the target module's namespace object.
|
| [[LocalName]] | String | The name that is used to locally access the imported value from within the importing module. |
| Import Statement Form | [[ModuleRequest]] | [[ImportName]] | [[LocalName]] |
|---|---|---|---|
import v from "mod";
|
"mod"
|
"default"
|
"v"
|
import * as ns from "mod";
|
"mod"
|
"*"
|
"ns"
|
import {x} from "mod";
|
"mod"
|
"x"
|
"x"
|
import {x as v} from "mod";
|
"mod"
|
"x"
|
"v"
|
import "mod";
|
An |
||
An ExportEntry Record is a
| Field Name | Value Type | Meaning |
|---|---|---|
| [[ExportName]] | String | The name used to export this binding by this module. |
| [[ModuleRequest]] | String | null |
The String value of the |
| [[ImportName]] | String | null |
The name under which the desired binding is exported by the module identified by [[ModuleRequest]]. "*" indicates that the export request is for all exported bindings.
|
| [[LocalName]] | String | null |
The name that is used to locally access the exported value from within the importing module. |
| Export Statement Form | [[ExportName]] | [[ModuleRequest]] | [[ImportName]] | [[LocalName]] |
|---|---|---|---|---|
export var v;
|
"v"
|
|
|
"v"
|
export default function f(){}
|
"default"
|
|
|
"f"
|
export default function(){}
|
"default"
|
|
|
"*default*"
|
export default 42;
|
"default"
|
|
|
"*default*"
|
export {x};
|
"x"
|
|
|
"x"
|
export {v as x};
|
"x"
|
|
|
"v"
|
export {x} from "mod";
|
"x"
|
"mod"
|
"x"
|
|
export {v as x} from "mod";
|
"x"
|
"mod"
|
"v"
|
|
export * from "mod";
|
|
"mod"
|
"*"
|
|
The following definitions specify the required concrete methods and other
15.2.1.16.1 ParseModule ( sourceText, realm, hostDefined )
The abstract operation ParseModule with arguments sourceText, realm, and hostDefined creates a
Assert : sourceText is an ECMAScript source text (see clause10 ).- Parse sourceText using
Module as thegoal symbol and analyse the parse result for any Early Error conditions. If the parse was successful and no early errors were found, let body be the resulting parse tree. Otherwise, let body be aList of one or moreSyntaxError orReferenceError objects representing the parsing errors and/or early errors. Parsing andearly error detection may be interweaved in an implementation-dependent manner. If more than one parsing error orearly error is present, the number and ordering of error objects in the list is implementation-dependent, but at least one must be present. - If body is a
List of errors, return body. - Let requestedModules be the ModuleRequests of body.
- Let importEntries be ImportEntries of body.
- Let importedBoundNames be
ImportedLocalNames (importEntries). - Let indirectExportEntries be a new empty
List . - Let localExportEntries be a new empty
List . - Let starExportEntries be a new empty
List . - Let exportEntries be ExportEntries of body.
- For each
ExportEntry Record ee in exportEntries, do- If ee.[[ModuleRequest]] is
null , then- If ee.[[LocalName]] is not an element of importedBoundNames, then
- Append ee to localExportEntries.
- Else,
- Let ie be the element of importEntries whose [[LocalName]] is the same as ee.[[LocalName]].
- If ie.[[ImportName]] is
"*", thenAssert : This is a re-export of an imported module namespace object.- Append ee to localExportEntries.
- Else this is a re-export of a single name,
- Append the
ExportEntry Record { [[ModuleRequest]]: ie.[[ModuleRequest]], [[ImportName]]: ie.[[ImportName]], [[LocalName]]:null , [[ExportName]]: ee.[[ExportName]] } to indirectExportEntries.
- Append the
- If ee.[[LocalName]] is not an element of importedBoundNames, then
- Else if ee.[[ImportName]] is
"*", then- Append ee to starExportEntries.
- Else,
- Append ee to indirectExportEntries.
- If ee.[[ModuleRequest]] is
- Return
Source Text Module Record { [[Realm]]: realm, [[Environment]]:undefined , [[Namespace]]:undefined , [[Status]]:"uninstantiated", [[EvaluationError]]:undefined , [[HostDefined]]: hostDefined, [[ECMAScriptCode]]: body, [[RequestedModules]]: requestedModules, [[ImportEntries]]: importEntries, [[LocalExportEntries]]: localExportEntries, [[IndirectExportEntries]]: indirectExportEntries, [[StarExportEntries]]: starExportEntries, [[DFSIndex]]:undefined , [[DFSAncestorIndex]]:undefined }.
An implementation may parse module source text and analyse it for Early Error conditions prior to the evaluation of ParseModule for that module source text. However, the reporting of any errors must be deferred until the point where this specification actually performs ParseModule upon that source text.
15.2.1.16.2 GetExportedNames ( exportStarSet ) Concrete Method
The GetExportedNames concrete method of a
It performs the following steps:
- Let module be this
Source Text Module Record . - If exportStarSet contains module, then
- Append module to exportStarSet.
- Let exportedNames be a new empty
List . - For each
ExportEntry Record e in module.[[LocalExportEntries]], doAssert : module provides the direct binding for this export.- Append e.[[ExportName]] to exportedNames.
- For each
ExportEntry Record e in module.[[IndirectExportEntries]], doAssert : module imports a specific binding for this export.- Append e.[[ExportName]] to exportedNames.
- For each
ExportEntry Record e in module.[[StarExportEntries]], do- Let requestedModule be ?
HostResolveImportedModule (module, e.[[ModuleRequest]]). - Let starNames be ? requestedModule.GetExportedNames(exportStarSet).
- For each element n of starNames, do
- If
SameValue (n,"default") isfalse , then- If n is not an element of exportedNames, then
- Append n to exportedNames.
- If n is not an element of exportedNames, then
- If
- Let requestedModule be ?
- Return exportedNames.
GetExportedNames does not filter out or throw an exception for names that have ambiguous star export bindings.
15.2.1.16.3 ResolveExport ( exportName, resolveSet ) Concrete Method
The ResolveExport concrete method of a
ResolveExport attempts to resolve an imported binding to the actual defining module and local binding name. The defining module may be the module represented by the
If a defining module is found, a "ambiguous" is returned.
This abstract method performs the following steps:
- Let module be this
Source Text Module Record . - For each
Record { [[Module]], [[ExportName]] } r in resolveSet, do- If module and r.[[Module]] are the same
Module Record andSameValue (exportName, r.[[ExportName]]) istrue , thenAssert : This is a circular import request.- Return
null .
- If module and r.[[Module]] are the same
- Append the
Record { [[Module]]: module, [[ExportName]]: exportName } to resolveSet. - For each
ExportEntry Record e in module.[[LocalExportEntries]], do- If
SameValue (exportName, e.[[ExportName]]) istrue , thenAssert : module provides the direct binding for this export.- Return
ResolvedBinding Record { [[Module]]: module, [[BindingName]]: e.[[LocalName]] }.
- If
- For each
ExportEntry Record e in module.[[IndirectExportEntries]], do- If
SameValue (exportName, e.[[ExportName]]) istrue , thenAssert : module imports a specific binding for this export.- Let importedModule be ?
HostResolveImportedModule (module, e.[[ModuleRequest]]). - Return importedModule.ResolveExport(e.[[ImportName]], resolveSet).
- If
- If
SameValue (exportName,"default") istrue , thenAssert : Adefaultexport was not explicitly defined by this module.- Return
null . - NOTE: A
defaultexport cannot be provided by anexport *.
- Let starResolution be
null . - For each
ExportEntry Record e in module.[[StarExportEntries]], do- Let importedModule be ?
HostResolveImportedModule (module, e.[[ModuleRequest]]). - Let resolution be ? importedModule.ResolveExport(exportName, resolveSet).
- If resolution is
"ambiguous", return"ambiguous". - If resolution is not
null , thenAssert : resolution is aResolvedBinding Record .- If starResolution is
null , set starResolution to resolution. - Else,
Assert : There is more than one*import that includes the requested name.- If resolution.[[Module]] and starResolution.[[Module]] are not the same
Module Record orSameValue (resolution.[[BindingName]], starResolution.[[BindingName]]) isfalse , return"ambiguous".
- Let importedModule be ?
- Return starResolution.
15.2.1.16.4 Instantiate ( ) Concrete Method
The Instantiate concrete method of a
On success, Instantiate transitions this module's [[Status]] from "uninstantiated" to "instantiated". On failure, an exception is thrown and this module's [[Status]] remains "uninstantiated".
This abstract method performs the following steps (most of the work is done by the auxiliary function
- Let module be this
Source Text Module Record . Assert : module.[[Status]] is not"instantiating"or"evaluating".- Let stack be a new empty
List . - Let result be
InnerModuleInstantiation (module, stack, 0). - If result is an
abrupt completion , then Assert : module.[[Status]] is"instantiated"or"evaluated".Assert : stack is empty.- Return
undefined .
15.2.1.16.4.1 InnerModuleInstantiation ( module, stack, index )
The InnerModuleInstantiation abstract operation is used by Instantiate to perform the actual instantiation process for the "instantiated" together.
This abstract operation performs the following steps:
- If module is not a
Source Text Module Record , then- Perform ? module.Instantiate().
- Return index.
- If module.[[Status]] is
"instantiating","instantiated", or"evaluated", then- Return index.
Assert : module.[[Status]] is"uninstantiated".- Set module.[[Status]] to
"instantiating". - Set module.[[DFSIndex]] to index.
- Set module.[[DFSAncestorIndex]] to index.
- Set index to index + 1.
- Append module to stack.
- For each String required that is an element of module.[[RequestedModules]], do
- Let requiredModule be ?
HostResolveImportedModule (module, required). - Set index to ?
InnerModuleInstantiation (requiredModule, stack, index). Assert : requiredModule.[[Status]] is either"instantiating","instantiated", or"evaluated".Assert : requiredModule.[[Status]] is"instantiating"if and only if requiredModule is in stack.- If requiredModule.[[Status]] is
"instantiating", thenAssert : requiredModule is aSource Text Module Record .- Set module.[[DFSAncestorIndex]] to
min (module.[[DFSAncestorIndex]], requiredModule.[[DFSAncestorIndex]]).
- Let requiredModule be ?
- Perform ?
ModuleDeclarationEnvironmentSetup (module). Assert : module occurs exactly once in stack.Assert : module.[[DFSAncestorIndex]] is less than or equal to module.[[DFSIndex]].- If module.[[DFSAncestorIndex]] equals module.[[DFSIndex]], then
- Let done be
false . - Repeat, while done is
false ,- Let requiredModule be the last element in stack.
- Remove the last element of stack.
- Set requiredModule.[[Status]] to
"instantiated". - If requiredModule and module are the same
Module Record , set done totrue .
- Let done be
- Return index.
15.2.1.16.4.2 ModuleDeclarationEnvironmentSetup ( module )
The ModuleDeclarationEnvironmentSetup abstract operation is used by
This abstract operation performs the following steps:
- For each
ExportEntry Record e in module.[[IndirectExportEntries]], do- Let resolution be ? module.ResolveExport(e.[[ExportName]], « »).
- If resolution is
null or"ambiguous", throw aSyntaxError exception. Assert : resolution is aResolvedBinding Record .
Assert : All named exports from module are resolvable.- Let realm be module.[[Realm]].
Assert : realm is notundefined .- Let env be
NewModuleEnvironment (realm.[[GlobalEnv]]). - Set module.[[Environment]] to env.
- Let envRec be env's
EnvironmentRecord . - For each
ImportEntry Record in in module.[[ImportEntries]], do- Let importedModule be !
HostResolveImportedModule (module, in.[[ModuleRequest]]). - NOTE: The above call cannot fail because imported module requests are a subset of module.[[RequestedModules]], and these have been resolved earlier in this algorithm.
- If in.[[ImportName]] is
"*", then- Let namespace be ?
GetModuleNamespace (importedModule). - Perform ! envRec.CreateImmutableBinding(in.[[LocalName]],
true ). - Call envRec.InitializeBinding(in.[[LocalName]], namespace).
- Let namespace be ?
- Else,
- Let resolution be ? importedModule.ResolveExport(in.[[ImportName]], « »).
- If resolution is
null or"ambiguous", throw aSyntaxError exception. - Call envRec.CreateImportBinding(in.[[LocalName]], resolution.[[Module]], resolution.[[BindingName]]).
- Let importedModule be !
- Let code be module.[[ECMAScriptCode]].
- Let varDeclarations be the VarScopedDeclarations of code.
- Let declaredVarNames be a new empty
List . - For each element d in varDeclarations, do
- For each element dn of the BoundNames of d, do
- If dn is not an element of declaredVarNames, then
- Perform ! envRec.CreateMutableBinding(dn,
false ). - Call envRec.InitializeBinding(dn,
undefined ). - Append dn to declaredVarNames.
- Perform ! envRec.CreateMutableBinding(dn,
- If dn is not an element of declaredVarNames, then
- For each element dn of the BoundNames of d, do
- Let lexDeclarations be the LexicallyScopedDeclarations of code.
- For each element d in lexDeclarations, do
- For each element dn of the BoundNames of d, do
- If IsConstantDeclaration of d is
true , then- Perform ! envRec.CreateImmutableBinding(dn,
true ).
- Perform ! envRec.CreateImmutableBinding(dn,
- Else,
- Perform ! envRec.CreateMutableBinding(dn,
false ).
- Perform ! envRec.CreateMutableBinding(dn,
- If d is a
FunctionDeclaration , aGeneratorDeclaration , anAsyncFunctionDeclaration , or anAsyncGeneratorDeclaration , then- Let fo be the result of performing InstantiateFunctionObject for d with argument env.
- Call envRec.InitializeBinding(dn, fo).
- If IsConstantDeclaration of d is
- For each element dn of the BoundNames of d, do
15.2.1.16.5 Evaluate ( ) Concrete Method
The Evaluate concrete method of a
Evaluate transitions this module's [[Status]] from "instantiated" to "evaluated".
If execution results in an exception, that exception is recorded in the [[EvaluationError]] field and rethrown by future invocations of Evaluate.
This abstract method performs the following steps (most of the work is done by the auxiliary function
- Let module be this
Source Text Module Record . Assert : module.[[Status]] is"instantiated"or"evaluated".- Let stack be a new empty
List . - Let result be
InnerModuleEvaluation (module, stack, 0). - If result is an
abrupt completion , then Assert : module.[[Status]] is"evaluated"and module.[[EvaluationError]] isundefined .Assert : stack is empty.- Return
undefined .
15.2.1.16.5.1 InnerModuleEvaluation ( module, stack, index )
The InnerModuleEvaluation abstract operation is used by Evaluate to perform the actual evaluation process for the
This abstract operation performs the following steps:
- If module is not a
Source Text Module Record , then- Perform ? module.Evaluate().
- Return index.
- If module.[[Status]] is
"evaluated", then- If module.[[EvaluationError]] is
undefined , return index. - Otherwise return module.[[EvaluationError]].
- If module.[[EvaluationError]] is
- If module.[[Status]] is
"evaluating", return index. Assert : module.[[Status]] is"instantiated".- Set module.[[Status]] to
"evaluating". - Set module.[[DFSIndex]] to index.
- Set module.[[DFSAncestorIndex]] to index.
- Set index to index + 1.
- Append module to stack.
- For each String required that is an element of module.[[RequestedModules]], do
- Let requiredModule be !
HostResolveImportedModule (module, required). - NOTE: Instantiate must be completed successfully prior to invoking this method, so every requested module is guaranteed to resolve successfully.
- Set index to ?
InnerModuleEvaluation (requiredModule, stack, index). Assert : requiredModule.[[Status]] is either"evaluating"or"evaluated".Assert : requiredModule.[[Status]] is"evaluating"if and only if requiredModule is in stack.- If requiredModule.[[Status]] is
"evaluating", thenAssert : requiredModule is aSource Text Module Record .- Set module.[[DFSAncestorIndex]] to
min (module.[[DFSAncestorIndex]], requiredModule.[[DFSAncestorIndex]]).
- Let requiredModule be !
- Perform ?
ModuleExecution (module). Assert : module occurs exactly once in stack.Assert : module.[[DFSAncestorIndex]] is less than or equal to module.[[DFSIndex]].- If module.[[DFSAncestorIndex]] equals module.[[DFSIndex]], then
- Let done be
false . - Repeat, while done is
false ,- Let requiredModule be the last element in stack.
- Remove the last element of stack.
- Set requiredModule.[[Status]] to
"evaluated". - If requiredModule and module are the same
Module Record , set done totrue .
- Let done be
- Return index.
15.2.1.16.5.2 ModuleExecution ( module )
The ModuleExecution abstract operation is used by
This abstract operation performs the following steps:
- Let moduleCxt be a new ECMAScript code
execution context . - Set the Function of moduleCxt to
null . Assert : module.[[Realm]] is notundefined .- Set the
Realm of moduleCxt to module.[[Realm]]. - Set the ScriptOrModule of moduleCxt to module.
Assert : module has been linked and declarations in itsmodule environment have been instantiated.- Set the VariableEnvironment of moduleCxt to module.[[Environment]].
- Set the LexicalEnvironment of moduleCxt to module.[[Environment]].
Suspend the currentlyrunning execution context .- Push moduleCxt on to the
execution context stack ; moduleCxt is now therunning execution context . - Let result be the result of evaluating module.[[ECMAScriptCode]].
Suspend moduleCxt and remove it from theexecution context stack .- Resume the context that is now on the top of the
execution context stack as therunning execution context . - Return
Completion (result).
15.2.1.16.6 Example Source Text Module Record Graphs
This non-normative section gives a series of examples of the instantiation and evaluation of a few common module graphs, with a specific focus on how errors can occur.
First consider the following simple module graph:

Let's first assume that there are no error conditions. When a host first calls A.Instantiate(), this will complete successfully by assumption, and recursively instantiate modules B and C as well, such that A.[[Status]] = B.[[Status]] = C.[[Status]] = "instantiated". This preparatory step can be performed at any time. Later, when the host is ready to incur any possible side effects of the modules, it can call A.Evaluate(), which will complete successfully (again by assumption), recursively having evaluated first C and then B. Each module's [[Status]] at this point will be "evaluated".
Consider then cases involving instantiation errors. If "uninstantiated". C's [[Status]] has become "instantiated", though.
Finally, consider a case involving evaluation errors. If "evaluated". C will also become "evaluated" but, in contrast to A and B, will remain without an [[EvaluationError]], as it successfully completed evaluation. Storing the exception ensures that any time a host tries to reuse A or B by calling their Evaluate() method, it will encounter the same exception. (Hosts are not required to reuse Source Text Module Records; similarly, hosts are not required to expose the exception objects thrown by these methods. However, the specification enables such uses.)
The difference here between instantiation and evaluation errors is due to how evaluation must be only performed once, as it can cause side effects; it is thus important to remember whether evaluation has already been performed, even if unsuccessfully. (In the error case, it makes sense to also remember the exception because otherwise subsequent Evaluate() calls would have to synthesize a new one.) Instantiation, on the other hand, is side-effect-free, and thus even if it fails, it can be retried at a later time with no issues.
Now consider a different type of error condition:

In this scenario, module A declares a dependency on some other module, but no "uninstantiated".
Lastly, consider a module graph with a cycle:

Here we assume that the entry point is module A, so that the host proceeds by calling A.Instantiate(), which performs "instantiating". B.[[Status]] itself remains "instantiating" when control gets back to A and "instantiated" , both A and B transition from "instantiating" to "instantiated" together; this is by design, since they form a strongly connected component.
An analogous story occurs for the evaluation phase of a cyclic module graph, in the success case.
Now consider a case where A has an instantiation error; for example, it tries to import a binding from C that does not exist. In that case, the above steps still occur, including the early return from the second call to "instantiating"). Hence both A and B become "uninstantiated". Note that C is left as "instantiated".
Finally, consider a case where A has an evaluation error; for example, its source code throws an exception. In that case, the evaluation-time analog of the above steps still occurs, including the early return from the second call to "evaluating"). Hence both A and B become "evaluated" and the exception is recorded in both A and B's [[EvaluationError]] fields, while C is left as "evaluated" with no [[EvaluationError]].
15.2.1.17 Runtime Semantics: HostResolveImportedModule ( referencingModule, specifier )
HostResolveImportedModule is an implementation-defined abstract operation that provides the concrete
The implementation of HostResolveImportedModule must conform to the following requirements:
-
The normal return value must be an instance of a concrete subclass of
Module Record . -
If a
Module Record corresponding to the pair referencingModule, specifier does not exist or cannot be created, an exception must be thrown. -
This operation must be idempotent if it completes normally. Each time it is called with a specific referencingModule, specifier pair as arguments it must return the same
Module Record instance.
Multiple different referencingModule, specifier pairs may map to the same
15.2.1.18 Runtime Semantics: GetModuleNamespace ( module )
The GetModuleNamespace abstract operation retrieves the Module Namespace
This abstract operation performs the following steps:
Assert : module is an instance of a concrete subclass ofModule Record .Assert : module.[[Status]] is not"uninstantiated".Assert : If module.[[Status]] is"evaluated", module.[[EvaluationError]] isundefined .- Let namespace be module.[[Namespace]].
- If namespace is
undefined , then- Let exportedNames be ? module.GetExportedNames(« »).
- Let unambiguousNames be a new empty
List . - For each name that is an element of exportedNames, do
- Let resolution be ? module.ResolveExport(name, « »).
- If resolution is a
ResolvedBinding Record , append name to unambiguousNames.
- Set namespace to
ModuleNamespaceCreate (module, unambiguousNames).
- Return namespace.
The only way GetModuleNamespace can throw is via one of the triggered
15.2.1.19 Runtime Semantics: TopLevelModuleEvaluationJob ( sourceText, hostDefined )
A TopLevelModuleEvaluationJob with parameters sourceText and hostDefined is a job that parses, validates, and evaluates sourceText as a
Assert : sourceText is an ECMAScript source text (see clause10 ).- Let realm be
the current Realm Record . - Let m be
ParseModule (sourceText, realm, hostDefined). - If m is a
List of errors, then- Perform
HostReportErrors (m). - Return
NormalCompletion (undefined ).
- Perform
- Perform ? m.Instantiate().
Assert : All dependencies of m have been transitively resolved and m is ready for evaluation.- Return ? m.Evaluate().
An implementation may parse a sourceText as a
15.2.1.20 Runtime Semantics: Evaluation
- Return
NormalCompletion (undefined ).
- Let result be the result of evaluating
ModuleItemList . - If result.[[Type]] is
normal and result.[[Value]] isempty , then- Return
NormalCompletion (undefined ).
- Return
- Return
Completion (result).
- Let sl be the result of evaluating
ModuleItemList . ReturnIfAbrupt (sl).- Let s be the result of evaluating
ModuleItem . - Return
Completion (UpdateEmpty (s, sl.[[Value]])).
The value of a
- Return
NormalCompletion (empty ).
15.2.2 Imports
Syntax
15.2.2.1 Static Semantics: Early Errors
-
It is a Syntax Error if the BoundNames of
ImportDeclaration contains any duplicate entries.
15.2.2.2 Static Semantics: BoundNames
- Return the BoundNames of
ImportClause .
- Return a new empty
List .
- Let names be the BoundNames of
ImportedDefaultBinding . - Append to names the elements of the BoundNames of
NameSpaceImport . - Return names.
- Let names be the BoundNames of
ImportedDefaultBinding . - Append to names the elements of the BoundNames of
NamedImports . - Return names.
- Return a new empty
List .
- Let names be the BoundNames of
ImportsList . - Append to names the elements of the BoundNames of
ImportSpecifier . - Return names.
- Return the BoundNames of
ImportedBinding .
15.2.2.3 Static Semantics: ImportEntries
- Let module be the sole element of ModuleRequests of
FromClause . - Return ImportEntriesForModule of
ImportClause with argument module.
- Return a new empty
List .
15.2.2.4 Static Semantics: ImportEntriesForModule
With parameter module.
- Let entries be ImportEntriesForModule of
ImportedDefaultBinding with argument module. - Append to entries the elements of the ImportEntriesForModule of
NameSpaceImport with argument module. - Return entries.
- Let entries be ImportEntriesForModule of
ImportedDefaultBinding with argument module. - Append to entries the elements of the ImportEntriesForModule of
NamedImports with argument module. - Return entries.
- Let localName be the sole element of BoundNames of
ImportedBinding . - Let defaultEntry be the
ImportEntry Record { [[ModuleRequest]]: module, [[ImportName]]:"default", [[LocalName]]: localName }. - Return a new
List containing defaultEntry.
- Let localName be the StringValue of
ImportedBinding . - Let entry be the
ImportEntry Record { [[ModuleRequest]]: module, [[ImportName]]:"*", [[LocalName]]: localName }. - Return a new
List containing entry.
- Return a new empty
List .
- Let specs be the ImportEntriesForModule of
ImportsList with argument module. - Append to specs the elements of the ImportEntriesForModule of
ImportSpecifier with argument module. - Return specs.
- Let localName be the sole element of BoundNames of
ImportedBinding . - Let entry be the
ImportEntry Record { [[ModuleRequest]]: module, [[ImportName]]: localName, [[LocalName]]: localName }. - Return a new
List containing entry.
- Let importName be the StringValue of
IdentifierName . - Let localName be the StringValue of
ImportedBinding . - Let entry be the
ImportEntry Record { [[ModuleRequest]]: module, [[ImportName]]: importName, [[LocalName]]: localName }. - Return a new
List containing entry.
15.2.2.5 Static Semantics: ModuleRequests
- Return ModuleRequests of
FromClause .
- Return a
List containing the StringValue ofStringLiteral .
15.2.3 Exports
Syntax
15.2.3.1 Static Semantics: Early Errors
-
For each
IdentifierName n in ReferencedBindings ofExportClause : It is a Syntax Error if StringValue of n is aReservedWord or if the StringValue of n is one of:"implements","interface","let","package","private","protected","public", or"static".
The above rule means that each ReferencedBindings of
15.2.3.2 Static Semantics: BoundNames
- Return a new empty
List .
- Return the BoundNames of
VariableStatement .
- Return the BoundNames of
Declaration .
- Let declarationNames be the BoundNames of
HoistableDeclaration . - If declarationNames does not include the element
"*default*", append"*default*"to declarationNames. - Return declarationNames.
- Let declarationNames be the BoundNames of
ClassDeclaration . - If declarationNames does not include the element
"*default*", append"*default*"to declarationNames. - Return declarationNames.
- Return «
"*default*"».
15.2.3.3 Static Semantics: ExportedBindings
- Return a new empty
List .
- Return the ExportedBindings of
ExportClause .
- Return the BoundNames of
VariableStatement .
- Return the BoundNames of
Declaration .
- Return the BoundNames of this
ExportDeclaration .
- Return a new empty
List .
- Let names be the ExportedBindings of
ExportsList . - Append to names the elements of the ExportedBindings of
ExportSpecifier . - Return names.
- Return a
List containing the StringValue ofIdentifierName .
- Return a
List containing the StringValue of the firstIdentifierName .
15.2.3.4 Static Semantics: ExportedNames
- Return a new empty
List .
- Return the ExportedNames of
ExportClause .
- Return the BoundNames of
VariableStatement .
- Return the BoundNames of
Declaration .
- Return «
"default"».
- Return a new empty
List .
- Let names be the ExportedNames of
ExportsList . - Append to names the elements of the ExportedNames of
ExportSpecifier . - Return names.
- Return a
List containing the StringValue ofIdentifierName .
- Return a
List containing the StringValue of the secondIdentifierName .
15.2.3.5 Static Semantics: ExportEntries
- Let module be the sole element of ModuleRequests of
FromClause . - Let entry be the
ExportEntry Record { [[ModuleRequest]]: module, [[ImportName]]:"*", [[LocalName]]:null , [[ExportName]]:null }. - Return a new
List containing entry.
- Let module be the sole element of ModuleRequests of
FromClause . - Return ExportEntriesForModule of
ExportClause with argument module.
- Return ExportEntriesForModule of
ExportClause with argumentnull .
- Let entries be a new empty
List . - Let names be the BoundNames of
VariableStatement . - For each name in names, do
- Append the
ExportEntry Record { [[ModuleRequest]]:null , [[ImportName]]:null , [[LocalName]]: name, [[ExportName]]: name } to entries.
- Append the
- Return entries.
- Let entries be a new empty
List . - Let names be the BoundNames of
Declaration . - For each name in names, do
- Append the
ExportEntry Record { [[ModuleRequest]]:null , [[ImportName]]:null , [[LocalName]]: name, [[ExportName]]: name } to entries.
- Append the
- Return entries.
- Let names be BoundNames of
HoistableDeclaration . - Let localName be the sole element of names.
- Return a new
List containing theExportEntry Record { [[ModuleRequest]]:null , [[ImportName]]:null , [[LocalName]]: localName, [[ExportName]]:"default"}.
- Let names be BoundNames of
ClassDeclaration . - Let localName be the sole element of names.
- Return a new
List containing theExportEntry Record { [[ModuleRequest]]:null , [[ImportName]]:null , [[LocalName]]: localName, [[ExportName]]:"default"}.
- Let entry be the
ExportEntry Record { [[ModuleRequest]]:null , [[ImportName]]:null , [[LocalName]]:"*default*", [[ExportName]]:"default"}. - Return a new
List containing entry.
"*default*" is used within this specification as a synthetic name for anonymous default export values.
15.2.3.6 Static Semantics: ExportEntriesForModule
With parameter module.
- Return a new empty
List .
- Let specs be the ExportEntriesForModule of
ExportsList with argument module. - Append to specs the elements of the ExportEntriesForModule of
ExportSpecifier with argument module. - Return specs.
- Let sourceName be the StringValue of
IdentifierName . - If module is
null , then- Let localName be sourceName.
- Let importName be
null .
- Else,
- Let localName be
null . - Let importName be sourceName.
- Let localName be
- Return a new
List containing theExportEntry Record { [[ModuleRequest]]: module, [[ImportName]]: importName, [[LocalName]]: localName, [[ExportName]]: sourceName }.
- Let sourceName be the StringValue of the first
IdentifierName . - Let exportName be the StringValue of the second
IdentifierName . - If module is
null , then- Let localName be sourceName.
- Let importName be
null .
- Else,
- Let localName be
null . - Let importName be sourceName.
- Let localName be
- Return a new
List containing theExportEntry Record { [[ModuleRequest]]: module, [[ImportName]]: importName, [[LocalName]]: localName, [[ExportName]]: exportName }.
15.2.3.7 Static Semantics: IsConstantDeclaration
- Return
false .
It is not necessary to treat export default
15.2.3.8 Static Semantics: LexicallyScopedDeclarations
- Return a new empty
List .
- Return a new
List containing DeclarationPart ofDeclaration .
- Return a new
List containing DeclarationPart ofHoistableDeclaration .
- Return a new
List containingClassDeclaration .
- Return a new
List containing thisExportDeclaration .
15.2.3.9 Static Semantics: ModuleRequests
- Return the ModuleRequests of
FromClause .
- Return a new empty
List .
15.2.3.10 Static Semantics: ReferencedBindings
- Return a new empty
List .
- Let names be the ReferencedBindings of
ExportsList . - Append to names the elements of the ReferencedBindings of
ExportSpecifier . - Return names.
- Return a
List containing theIdentifierName .
- Return a
List containing the firstIdentifierName .
15.2.3.11 Runtime Semantics: Evaluation
- Return
NormalCompletion (empty ).
- Return the result of evaluating
VariableStatement .
- Return the result of evaluating
Declaration .
- Return the result of evaluating
HoistableDeclaration .
- Let value be the result of BindingClassDeclarationEvaluation of
ClassDeclaration . ReturnIfAbrupt (value).- Let className be the sole element of BoundNames of
ClassDeclaration . - If className is
"*default*", then- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , performSetFunctionName (value,"default"). - Let env be the
running execution context 's LexicalEnvironment. - Perform ?
InitializeBoundName ("*default*", value, env).
- Let hasNameProperty be ?
- Return
NormalCompletion (empty ).
- Let rhs be the result of evaluating
AssignmentExpression . - Let value be ?
GetValue (rhs). - If
IsAnonymousFunctionDefinition (AssignmentExpression ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , performSetFunctionName (value,"default").
- Let hasNameProperty be ?
- Let env be the
running execution context 's LexicalEnvironment. - Perform ?
InitializeBoundName ("*default*", value, env). - Return
NormalCompletion (empty ).
16 Error Handling and Language Extensions
An implementation must report most errors at the time the relevant ECMAScript language construct is evaluated. An early error is an error that can be detected and reported prior to the evaluation of any construct in the eval is called and prevent evaluation of the eval code. All errors that are not early errors are runtime errors.
An implementation must report as an
An implementation shall not treat other kinds of errors as early errors even if the compiler can prove that a construct cannot execute without error under any circumstances. An implementation may issue an early warning in such a case, but it should not report the error until the relevant construct is actually executed.
An implementation shall report all errors as specified, except for the following:
-
Except as restricted in
16.2 , an implementation may extendScript syntax,Module syntax, and regular expression pattern or flag syntax. To permit this, all operations (such as callingeval, using a regular expression literal, or using theFunctionorRegExpconstructor ) that are allowed to throwSyntaxError are permitted to exhibit implementation-defined behaviour instead of throwingSyntaxError when they encounter an implementation-defined extension to the script syntax or regular expression pattern or flag syntax. -
Except as restricted in
16.2 , an implementation may provide additional types, values, objects, properties, and functions beyond those described in this specification. This may cause constructs (such as looking up a variable in the global scope) to have implementation-defined behaviour instead of throwing an error (such asReferenceError ).
16.1 HostReportErrors ( errorList )
HostReportErrors is an implementation-defined abstract operation that allows host environments to report parsing errors, early errors, and runtime errors.
An implementation of HostReportErrors must complete normally in all cases. The default implementation of HostReportErrors is to unconditionally return an empty normal completion.
errorList will be a
16.2 Forbidden Extensions
An implementation must not extend this specification in the following ways:
-
ECMAScript function objects defined using syntactic constructors in
strict mode code must not be created with own properties named"caller"or"arguments". Such own properties also must not be created for function objects defined using anArrowFunction ,MethodDefinition ,GeneratorDeclaration ,GeneratorExpression ,AsyncGeneratorDeclaration ,AsyncGeneratorExpression ,ClassDeclaration ,ClassExpression ,AsyncFunctionDeclaration ,AsyncFunctionExpression , orAsyncArrowFunction regardless of whether the definition is contained instrict mode code . Built-in functions, strict functions created using theFunctionconstructor , generator functions created using theGeneratorconstructor , async functions created using theAsyncFunctionconstructor , and functions created using thebindmethod also must not be created with such own properties. -
If an implementation extends any
function object with an own property named"caller"the value of that property, as observed using [[Get]] or [[GetOwnProperty]], must not be astrict function object. If it is anaccessor property , the function that is the value of the property's [[Get]] attribute must never return astrict function when called. -
Neither mapped nor unmapped arguments objects may be created with an own property named
"caller". -
The behaviour of the following methods must not be extended except as specified in ECMA-402:
Object.prototype.toLocaleString,Array.prototype.toLocaleString,Number.prototype.toLocaleString,Date.prototype.toLocaleDateString,Date.prototype.toLocaleString,Date.prototype.toLocaleTimeString,String.prototype.localeCompare,%TypedArray%.prototype.toLocaleString. -
The RegExp pattern grammars in
21.2.1 andB.1.4 must not be extended to recognize any of the source characters A-Z or a-z asIdentityEscape when the [U] grammar parameter is present.[+U] -
The Syntactic Grammar must not be extended in any manner that allows the token
:to immediately follow source text that matches theBindingIdentifier nonterminal symbol. -
When processing
strict mode code , the syntax ofNumericLiteral must not be extended to includeLegacyOctalIntegerLiteral DecimalIntegerLiteral must not be extended to includeNonOctalDecimalIntegerLiteral B.1.1 . -
TemplateCharacter must not be extended to includeLegacyOctalEscapeSequence B.1.2 . -
When processing
strict mode code , the extensions defined inB.3.2 ,B.3.3 ,B.3.4 , andB.3.6 must not be supported. -
When parsing for the
Module goal symbol , the lexical grammar extensions defined inB.1.3 must not be supported.
17 ECMAScript Standard Built-in Objects
There are certain built-in objects available whenever an ECMAScript
Unless specified otherwise, a built-in object that is callable as a function is a built-in
Many built-in objects are functions: they can be invoked with arguments. Some of them furthermore are constructors: they are functions intended for use with the new operator. For each built-in function, this specification describes the arguments required by that function and the properties of that new expression that invokes that
Unless otherwise specified in the description of a particular function, if a built-in function or this value” and “NewTarget” have the meanings given in
Unless otherwise specified in the description of a particular function, if a built-in function or
Implementations that add additional capabilities to the set of built-in functions are encouraged to do so by adding new functions rather than adding new parameters to existing functions.
Unless otherwise specified every built-in function and every built-in Function.prototype (
Unless otherwise specified every built-in prototype object has the Object prototype object, which is the initial value of the expression Object.prototype (
Built-in function objects that are not identified as constructors do not implement the [[Construct]] internal method unless otherwise specified in the description of a particular function.
Each built-in function defined in this specification is created by calling the
Every built-in length property whose value is an [ ]) or rest parameters (which are shown using the form «...name») are not included in the default argument count.
For example, the map property of the Array prototype object is described under the subclause heading «Array.prototype.map (callbackFn [ , thisArg])» which shows the two named arguments callbackFn and thisArg, the latter being optional; therefore the value of the length property of that
Unless otherwise specified, the length property of a built-in
Every built-in name property whose value is a String. Unless otherwise specified, this value is the name that is given to the function in this specification. For functions that are specified as properties of objects, the name value is the "get " or "set " prepended to the name property is explicitly specified for each built-in functions whose property key is a Symbol value.
Unless otherwise specified, the name property of a built-in
Every other
Every
18 The Global Object
The global object:
- is created before control enters any
execution context . - does not have a [[Construct]] internal method; it cannot be used as a
constructor with thenewoperator. - does not have a [[Call]] internal method; it cannot be invoked as a function.
- has a [[Prototype]] internal slot whose value is implementation-dependent.
- may have host defined properties in addition to the properties defined in this specification. This may include a property whose value is the global object itself; for example, in the HTML document object model the
windowproperty of the global object is the global object itself.
18.1 Value Properties of the Global Object
18.1.1 Infinity
The value of Infinity is
18.1.2 NaN
The value of NaN is
18.1.3 undefined
The value of undefined is
18.2 Function Properties of the Global Object
18.2.1 eval ( x )
The eval function is the %eval% intrinsic object. When the eval function is called with one argument x, the following steps are taken:
Assert : Theexecution context stack has at least two elements.- Let callerContext be the second to top element of the
execution context stack . - Let callerRealm be callerContext's
Realm . - Let calleeRealm be
the current Realm Record . - Perform ?
HostEnsureCanCompileStrings (callerRealm, calleeRealm). - Return ?
PerformEval (x, calleeRealm,false ,false ).
18.2.1.1 Runtime Semantics: PerformEval ( x, evalRealm, strictCaller, direct )
The abstract operation PerformEval with arguments x, evalRealm, strictCaller, and direct performs the following steps:
Assert : If direct isfalse , then strictCaller is alsofalse .- If
Type (x) is not String, return x. - Let thisEnvRec be !
GetThisEnvironment (). - If thisEnvRec is a
function Environment Record , then- Let F be thisEnvRec.[[FunctionObject]].
- Let inFunction be
true . - Let inMethod be thisEnvRec.HasSuperBinding().
- If F.[[ConstructorKind]] is
"derived", let inDerivedConstructor betrue ; otherwise, let inDerivedConstructor befalse .
- Else,
- Let inFunction be
false . - Let inMethod be
false . - Let inDerivedConstructor be
false .
- Let inFunction be
- Let script be the ECMAScript code that is the result of parsing x, interpreted as UTF-16 encoded Unicode text as described in
6.1.4 , for thegoal symbol Script . If inFunction isfalse , additionalearly error rules from18.2.1.1.1 are applied. If inMethod isfalse , additionalearly error rules from18.2.1.1.2 are applied. If inDerivedConstructor isfalse , additionalearly error rules from18.2.1.1.3 are applied. If the parse fails, throw aSyntaxError exception. If any early errors are detected, throw aSyntaxError or aReferenceError exception, depending on the type of the error (but see also clause16 ). Parsing andearly error detection may be interweaved in an implementation-dependent manner. - If script Contains
ScriptBody isfalse , returnundefined . - Let body be the
ScriptBody of script. - If strictCaller is
true , let strictEval betrue . - Else, let strictEval be IsStrict of script.
- Let ctx be the
running execution context . - NOTE: If direct is
true , ctx will be theexecution context that performed thedirect eval . If direct isfalse , ctx will be theexecution context for the invocation of theevalfunction. - If direct is
true , then- Let lexEnv be
NewDeclarativeEnvironment (ctx's LexicalEnvironment). - Let varEnv be ctx's VariableEnvironment.
- Let lexEnv be
- Else,
- Let lexEnv be
NewDeclarativeEnvironment (evalRealm.[[GlobalEnv]]). - Let varEnv be evalRealm.[[GlobalEnv]].
- Let lexEnv be
- If strictEval is
true , set varEnv to lexEnv. - If ctx is not already suspended, suspend ctx.
- Let evalCxt be a new ECMAScript code
execution context . - Set the evalCxt's Function to
null . - Set the evalCxt's
Realm to evalRealm. - Set the evalCxt's ScriptOrModule to ctx's ScriptOrModule.
- Set the evalCxt's VariableEnvironment to varEnv.
- Set the evalCxt's LexicalEnvironment to lexEnv.
- Push evalCxt on to the
execution context stack ; evalCxt is now therunning execution context . - Let result be
EvalDeclarationInstantiation (body, varEnv, lexEnv, strictEval). - If result.[[Type]] is
normal , then- Set result to the result of evaluating body.
- If result.[[Type]] is
normal and result.[[Value]] isempty , then- Set result to
NormalCompletion (undefined ).
- Set result to
Suspend evalCxt and remove it from theexecution context stack .- Resume the context that is now on the top of the
execution context stack as therunning execution context . - Return
Completion (result).
The eval code cannot instantiate variable or function bindings in the variable environment of the calling context that invoked the eval if the calling context is evaluating formal parameter initializers or if either the code of the calling context or the eval code is let, const, or class declarations are always instantiated in a new LexicalEnvironment.
18.2.1.1.1 Additional Early Error Rules for Eval Outside Functions
These
- It is a Syntax Error if
StatementList ContainsNewTarget .
18.2.1.1.2 Additional Early Error Rules for Eval Outside Methods
These
- It is a Syntax Error if
StatementList ContainsSuperProperty .
18.2.1.1.3 Additional Early Error Rules for Eval Outside Constructor Methods
These
- It is a Syntax Error if
StatementList ContainsSuperCall .
18.2.1.2 HostEnsureCanCompileStrings ( callerRealm, calleeRealm )
HostEnsureCanCompileStrings is an implementation-defined abstract operation that allows host environments to block certain ECMAScript functions which allow developers to compile strings into ECMAScript code.
An implementation of HostEnsureCanCompileStrings may complete normally or abruptly. Any abrupt completions will be propagated to its callers. The default implementation of HostEnsureCanCompileStrings is to unconditionally return an empty normal completion.
18.2.1.3 Runtime Semantics: EvalDeclarationInstantiation ( body, varEnv, lexEnv, strict )
When the abstract operation EvalDeclarationInstantiation is called with arguments body, varEnv, lexEnv, and strict, the following steps are taken:
- Let varNames be the VarDeclaredNames of body.
- Let varDeclarations be the VarScopedDeclarations of body.
- Let lexEnvRec be lexEnv's
EnvironmentRecord . - Let varEnvRec be varEnv's
EnvironmentRecord . - If strict is
false , then- If varEnvRec is a global
Environment Record , then- For each name in varNames, do
- If varEnvRec.HasLexicalDeclaration(name) is
true , throw aSyntaxError exception. - NOTE:
evalwill not create a global var declaration that would be shadowed by a global lexical declaration.
- If varEnvRec.HasLexicalDeclaration(name) is
- For each name in varNames, do
- Let thisLex be lexEnv.
Assert : The following loop will terminate.- Repeat, while thisLex is not the same as varEnv,
- Let thisEnvRec be thisLex's
EnvironmentRecord . - If thisEnvRec is not an object
Environment Record , then- NOTE: The environment of with statements cannot contain any lexical declaration so it doesn't need to be checked for var/let hoisting conflicts.
- For each name in varNames, do
- If thisEnvRec.HasBinding(name) is
true , then- Throw a
SyntaxError exception. - NOTE: Annex
B.3.5 defines alternate semantics for the above step.
- Throw a
- NOTE: A
direct eval will not hoist var declaration over a like-named lexical declaration.
- If thisEnvRec.HasBinding(name) is
- Set thisLex to thisLex's outer environment reference.
- Let thisEnvRec be thisLex's
- If varEnvRec is a global
- Let functionsToInitialize be a new empty
List . - Let declaredFunctionNames be a new empty
List . - For each d in varDeclarations, in reverse list order, do
- If d is neither a
VariableDeclaration nor aForBinding nor aBindingIdentifier , thenAssert : d is either aFunctionDeclaration , aGeneratorDeclaration , anAsyncFunctionDeclaration , or anAsyncGeneratorDeclaration .- NOTE: If there are multiple function declarations for the same name, the last declaration is used.
- Let fn be the sole element of the BoundNames of d.
- If fn is not an element of declaredFunctionNames, then
- If varEnvRec is a global
Environment Record , then- Let fnDefinable be ? varEnvRec.CanDeclareGlobalFunction(fn).
- If fnDefinable is
false , throw aTypeError exception.
- Append fn to declaredFunctionNames.
- Insert d as the first element of functionsToInitialize.
- If varEnvRec is a global
- If d is neither a
- NOTE: Annex
B.3.3.3 adds additional steps at this point. - Let declaredVarNames be a new empty
List . - For each d in varDeclarations, do
- If d is a
VariableDeclaration , aForBinding , or aBindingIdentifier , then- For each String vn in the BoundNames of d, do
- If vn is not an element of declaredFunctionNames, then
- If varEnvRec is a global
Environment Record , then- Let vnDefinable be ? varEnvRec.CanDeclareGlobalVar(vn).
- If vnDefinable is
false , throw aTypeError exception.
- If vn is not an element of declaredVarNames, then
- Append vn to declaredVarNames.
- If varEnvRec is a global
- If vn is not an element of declaredFunctionNames, then
- For each String vn in the BoundNames of d, do
- If d is a
- NOTE: No abnormal terminations occur after this algorithm step unless varEnvRec is a global
Environment Record and theglobal object is a Proxyexotic object . - Let lexDeclarations be the LexicallyScopedDeclarations of body.
- For each element d in lexDeclarations, do
- NOTE: Lexically declared names are only instantiated here but not initialized.
- For each element dn of the BoundNames of d, do
- If IsConstantDeclaration of d is
true , then- Perform ? lexEnvRec.CreateImmutableBinding(dn,
true ).
- Perform ? lexEnvRec.CreateImmutableBinding(dn,
- Else,
- Perform ? lexEnvRec.CreateMutableBinding(dn,
false ).
- Perform ? lexEnvRec.CreateMutableBinding(dn,
- If IsConstantDeclaration of d is
- For each
Parse Node f in functionsToInitialize, do- Let fn be the sole element of the BoundNames of f.
- Let fo be the result of performing InstantiateFunctionObject for f with argument lexEnv.
- If varEnvRec is a global
Environment Record , then- Perform ? varEnvRec.CreateGlobalFunctionBinding(fn, fo,
true ).
- Perform ? varEnvRec.CreateGlobalFunctionBinding(fn, fo,
- Else,
- Let bindingExists be varEnvRec.HasBinding(fn).
- If bindingExists is
false , then- Let status be ! varEnvRec.CreateMutableBinding(fn,
true ). Assert : status is not anabrupt completion because of validation preceding step 12.- Perform ! varEnvRec.InitializeBinding(fn, fo).
- Let status be ! varEnvRec.CreateMutableBinding(fn,
- Else,
- Perform ! varEnvRec.SetMutableBinding(fn, fo,
false ).
- Perform ! varEnvRec.SetMutableBinding(fn, fo,
- For each String vn in declaredVarNames, in list order, do
- If varEnvRec is a global
Environment Record , then- Perform ? varEnvRec.CreateGlobalVarBinding(vn,
true ).
- Perform ? varEnvRec.CreateGlobalVarBinding(vn,
- Else,
- Let bindingExists be varEnvRec.HasBinding(vn).
- If bindingExists is
false , then- Let status be ! varEnvRec.CreateMutableBinding(vn,
true ). Assert : status is not anabrupt completion because of validation preceding step 12.- Perform ! varEnvRec.InitializeBinding(vn,
undefined ).
- Let status be ! varEnvRec.CreateMutableBinding(vn,
- If varEnvRec is a global
- Return
NormalCompletion (empty ).
An alternative version of this algorithm is described in
18.2.2 isFinite ( number )
The isFinite function is the %isFinite% intrinsic object. When the isFinite function is called with one argument number, the following steps are taken:
- Let num be ?
ToNumber (number). - If num is
NaN ,+∞ , or-∞ , returnfalse . - Otherwise, return
true .
18.2.3 isNaN ( number )
The isNaN function is the %isNaN% intrinsic object. When the isNaN function is called with one argument number, the following steps are taken:
- Let num be ?
ToNumber (number). - If num is
NaN , returntrue . - Otherwise, return
false .
A reliable way for ECMAScript code to test if a value X is a X !== X. The result will be X is a
18.2.4 parseFloat ( string )
The parseFloat function produces a
The parseFloat function is the %parseFloat% intrinsic object. When the parseFloat function is called with one argument string, the following steps are taken:
- Let inputString be ?
ToString (string). - Let trimmedString be a substring of inputString consisting of the leftmost code unit that is not a
StrWhiteSpaceChar and all code units to the right of that code unit. (In other words, remove leading white space.) If inputString does not contain any such code units, let trimmedString be the empty string. - If neither trimmedString nor any prefix of trimmedString satisfies the syntax of a
StrDecimalLiteral (see7.1.3.1 ), returnNaN . - Let numberString be the longest prefix of trimmedString, which might be trimmedString itself, that satisfies the syntax of a
StrDecimalLiteral . - Let mathFloat be MV of numberString.
- If mathFloat=0, then
- If the first code unit of trimmedString is the code unit 0x002D (HYPHEN-MINUS), return
-0 . - Return
+0 .
- If the first code unit of trimmedString is the code unit 0x002D (HYPHEN-MINUS), return
- Return the
Number value for mathFloat.
parseFloat may interpret only a leading portion of string as a
18.2.5 parseInt ( string, radix )
The parseInt function produces an 0x or 0X, in which case a radix of 16 is assumed. If radix is 16, the number may also optionally begin with the code unit pairs 0x or 0X.
The parseInt function is the %parseInt% intrinsic object. When the parseInt function is called, the following steps are taken:
- Let inputString be ?
ToString (string). - Let S be a newly created substring of inputString consisting of the first code unit that is not a
StrWhiteSpaceChar and all code units following that code unit. (In other words, remove leading white space.) If inputString does not contain any such code unit, let S be the empty string. - Let sign be 1.
- If S is not empty and the first code unit of S is the code unit 0x002D (HYPHEN-MINUS), let sign be -1.
- If S is not empty and the first code unit of S is the code unit 0x002B (PLUS SIGN) or the code unit 0x002D (HYPHEN-MINUS), remove the first code unit from S.
- Let R be ?
ToInt32 (radix). - Let stripPrefix be
true . - If R ≠ 0, then
- If R < 2 or R > 36, return
NaN . - If R ≠ 16, let stripPrefix be
false .
- If R < 2 or R > 36, return
- Else R = 0,
- Let R be 10.
- If stripPrefix is
true , then- If the length of S is at least 2 and the first two code units of S are either
"0x"or"0X", remove the first two code units from S and let R be 16.
- If the length of S is at least 2 and the first two code units of S are either
- If S contains a code unit that is not a radix-R digit, let Z be the substring of S consisting of all code units before the first such code unit; otherwise, let Z be S.
- If Z is empty, return
NaN . - Let mathInt be the
mathematical integer value that is represented by Z in radix-R notation, using the letters A-Z and a-z for digits with values 10 through 35. (However, if R is 10 and Z contains more than 20 significant digits, every significant digit after the 20th may be replaced by a 0 digit, at the option of the implementation; and if R is not 2, 4, 8, 10, 16, or 32, then mathInt may be an implementation-dependent approximation to themathematical integer value that is represented by Z in radix-R notation.) - If mathInt = 0, then
- If sign = -1, return
-0 . - Return
+0 .
- If sign = -1, return
- Let number be the
Number value for mathInt. - Return sign × number.
18.2.6 URI Handling Functions
Uniform Resource Identifiers, or URIs, are Strings that identify resources (e.g. web pages or files) and transport protocols by which to access them (e.g. HTTP or FTP) on the Internet. The ECMAScript language itself does not provide any support for using URIs except for functions that encode and decode URIs as described in
Many implementations of ECMAScript provide additional functions and methods that manipulate web pages; these functions are beyond the scope of this standard.
18.2.6.1 URI Syntax and Semantics
A URI is composed of a sequence of components separated by component separators. The general form is:
: / ; ? where the italicized names represent components and “:”, “/”, “;” and “?” are reserved for use as separators. The encodeURI and decodeURI functions are intended to work with complete URIs; they assume that any reserved code units in the URI are intended to have special meaning and so are not encoded. The encodeURIComponent and decodeURIComponent functions are intended to work with the individual component parts of a URI; they assume that any reserved code units represent text and so must be encoded so that they are not interpreted as reserved code units when the component is part of a complete URI.
The following lexical grammar specifies the form of encoded URIs.
Syntax
The above syntax is based upon RFC 2396 and does not reflect changes introduced by the more recent RFC 3986.
Runtime Semantics
When a code unit to be included in a URI is not listed above or is not intended to have the special meaning sometimes given to the reserved code units, that code unit must be encoded. The code unit is transformed into its UTF-8 encoding, with "%xx".
18.2.6.1.1 Runtime Semantics: Encode ( string, unescapedSet )
The encoding and escaping process is described by the abstract operation Encode taking two String arguments string and unescapedSet.
- Let strLen be the number of code units in string.
- Let R be the empty String.
- Let k be 0.
- Repeat,
- If k equals strLen, return R.
- Let C be the code unit at index k within string.
- If C is in unescapedSet, then
- Let S be the String value containing only the code unit C.
- Set R to the
string-concatenation of the previous value of R and S.
- Else C is not in unescapedSet,
- If C is a
尾代理 , throw aURIError exception. - If C is not a
首代理 , then- Let V be the code point with the same numeric value as code unit C.
- Else,
- Increase k by 1.
- If k equals strLen, throw a
URIError exception. - Let kChar be the code unit at index k within string.
- If kChar is not a
尾代理 , throw aURIError exception. - Let V be
UTF16Decode (C, kChar).
- Let Octets be the
List of octets resulting by applying the UTF-8 transformation to V. - For each element octet of Octets in
List order, do- Let S be the
string-concatenation of:"%"- the String representation of octet, formatted as a two-digit uppercase hexadecimal number, padded to the left with a zero if necessary
- Set R to the
string-concatenation of the previous value of R and S.
- Let S be the
- If C is a
- Increase k by 1.
18.2.6.1.2 Runtime Semantics: Decode ( string, reservedSet )
The unescaping and decoding process is described by the abstract operation Decode taking two String arguments string and reservedSet.
- Let strLen be the number of code units in string.
- Let R be the empty String.
- Let k be 0.
- Repeat,
- If k equals strLen, return R.
- Let C be the code unit at index k within string.
- If C is not the code unit 0x0025 (PERCENT SIGN), then
- Let S be the String value containing only the code unit C.
- Else C is the code unit 0x0025 (PERCENT SIGN),
- Let start be k.
- If k + 2 is greater than or equal to strLen, throw a
URIError exception. - If the code units at index (k + 1) and (k + 2) within string do not represent hexadecimal digits, throw a
URIError exception. - Let B be the 8-bit value represented by the two hexadecimal digits at index (k + 1) and (k + 2).
- Increment k by 2.
- If the most significant bit in B is 0, then
- Let C be the code unit whose value is B.
- If C is not in reservedSet, then
- Let S be the String value containing only the code unit C.
- Else C is in reservedSet,
- Let S be the substring of string from index start to index k inclusive.
- Else the most significant bit in B is 1,
- Let n be the smallest nonnegative
integer such that (B << n) & 0x80 is equal to 0. - If n equals 1 or n is greater than 4, throw a
URIError exception. - Let Octets be a
List of 8-bit integers of size n. - Set Octets[0] to B.
- If k + (3 × (n - 1)) is greater than or equal to strLen, throw a
URIError exception. - Let j be 1.
- Repeat, while j < n
- Increment k by 1.
- If the code unit at index k within string is not the code unit 0x0025 (PERCENT SIGN), throw a
URIError exception. - If the code units at index (k + 1) and (k + 2) within string do not represent hexadecimal digits, throw a
URIError exception. - Let B be the 8-bit value represented by the two hexadecimal digits at index (k + 1) and (k + 2).
- If the two most significant bits in B are not 10, throw a
URIError exception. - Increment k by 2.
- Set Octets[j] to B.
- Increment j by 1.
- If Octets does not contain a valid UTF-8 encoding of a Unicode code point, throw a
URIError exception. - Let V be the value obtained by applying the UTF-8 transformation to Octets, that is, from a
List of octets into a 21-bit value. - Let S be the String value whose elements are, in order, the elements in
UTF16Encoding (V).
- Let n be the smallest nonnegative
- Set R to the
string-concatenation of the previous value of R and S. - Increase k by 1.
This syntax of Uniform Resource Identifiers is based upon RFC 2396 and does not reflect the more recent RFC 3986 which replaces RFC 2396. A formal description and implementation of UTF-8 is given in RFC 3629.
In UTF-8, characters are encoded using sequences of 1 to 6 octets. The only octet of a sequence of one has the higher-order bit set to 0, the remaining 7 bits being used to encode the character value. In a sequence of n octets, n>1, the initial octet has the n higher-order bits set to 1, followed by a bit set to 0. The remaining bits of that octet contain bits from the value of the character to be encoded. The following octets all have the higher-order bit set to 1 and the following bit set to 0, leaving 6 bits in each to contain bits from the character to be encoded. The possible UTF-8 encodings of ECMAScript characters are specified in
| Code Unit Value | Representation | 1st Octet | 2nd Octet | 3rd Octet | 4th Octet |
|---|---|---|---|---|---|
0x0000 - 0x007F
|
00000000 0zzzzzzz
|
0zzzzzzz
|
|||
0x0080 - 0x07FF
|
00000yyy yyzzzzzz
|
110yyyyy
|
10zzzzzz
|
||
0x0800 - 0xD7FF
|
xxxxyyyy yyzzzzzz
|
1110xxxx
|
10yyyyyy
|
10zzzzzz
|
|
0xD800 - 0xDBFF
followed by 0xDC00 - 0xDFFF
|
110110vv vvwwwwxx
followed by 110111yy yyzzzzzz
|
11110uuu
|
10uuwwww
|
10xxyyyy
|
10zzzzzz
|
0xD800 - 0xDBFF
not followed by 0xDC00 - 0xDFFF
|
causes URIError
|
||||
0xDC00 - 0xDFFF
|
causes URIError
|
||||
0xE000 - 0xFFFF
|
xxxxyyyy yyzzzzzz
|
1110xxxx
|
10yyyyyy
|
10zzzzzz
|
Where
uuuuu = vvvv + 1
to account for the addition of 0x10000 as in section 3.8 of the Unicode Standard (Surrogates).
The above transformation combines each
RFC 3629 prohibits the decoding of invalid UTF-8 octet sequences. For example, the invalid sequence C0 80 must not decode into the code unit 0x0000. Implementations of the Decode algorithm are required to throw a
18.2.6.2 decodeURI ( encodedURI )
The decodeURI function computes a new version of a URI in which each escape sequence and UTF-8 encoding of the sort that might be introduced by the encodeURI function is replaced with the UTF-16 encoding of the code points that it represents. Escape sequences that could not have been introduced by encodeURI are not replaced.
The decodeURI function is the %decodeURI% intrinsic object. When the decodeURI function is called with one argument encodedURI, the following steps are taken:
- Let uriString be ?
ToString (encodedURI). - Let reservedURISet be a String containing one instance of each code unit valid in
uriReserved plus"#". - Return ?
Decode (uriString, reservedURISet).
The code point "#" is not decoded from escape sequences even though it is not a reserved URI code point.
18.2.6.3 decodeURIComponent ( encodedURIComponent )
The decodeURIComponent function computes a new version of a URI in which each escape sequence and UTF-8 encoding of the sort that might be introduced by the encodeURIComponent function is replaced with the UTF-16 encoding of the code points that it represents.
The decodeURIComponent function is the %decodeURIComponent% intrinsic object. When the decodeURIComponent function is called with one argument encodedURIComponent, the following steps are taken:
18.2.6.4 encodeURI ( uri )
The encodeURI function computes a new version of a UTF-16 encoded (
The encodeURI function is the %encodeURI% intrinsic object. When the encodeURI function is called with one argument uri, the following steps are taken:
- Let uriString be ?
ToString (uri). - Let unescapedURISet be a String containing one instance of each code unit valid in
uriReserved anduriUnescaped plus"#". - Return ?
Encode (uriString, unescapedURISet).
The code unit "#" is not encoded to an escape sequence even though it is not a reserved or unescaped URI code point.
18.2.6.5 encodeURIComponent ( uriComponent )
The encodeURIComponent function computes a new version of a UTF-16 encoded (
The encodeURIComponent function is the %encodeURIComponent% intrinsic object. When the encodeURIComponent function is called with one argument uriComponent, the following steps are taken:
- Let componentString be ?
ToString (uriComponent). - Let unescapedURIComponentSet be a String containing one instance of each code unit valid in
uriUnescaped . - Return ?
Encode (componentString, unescapedURIComponentSet).
18.3 Constructor Properties of the Global Object
18.3.1 Array ( . . . )
See
18.3.2 ArrayBuffer ( . . . )
See
18.3.3 Boolean ( . . . )
See
18.3.4 DataView ( . . . )
See
18.3.5 Date ( . . . )
See
18.3.6 Error ( . . . )
See
18.3.7 EvalError ( . . . )
See
18.3.8 Float32Array ( . . . )
See
18.3.9 Float64Array ( . . . )
See
18.3.10 Function ( . . . )
See
18.3.11 Int8Array ( . . . )
See
18.3.12 Int16Array ( . . . )
See
18.3.13 Int32Array ( . . . )
See
18.3.14 Map ( . . . )
See
18.3.15 Number ( . . . )
See
18.3.16 Object ( . . . )
See
18.3.17 Promise ( . . . )
See
18.3.18 Proxy ( . . . )
See
18.3.19 RangeError ( . . . )
See
18.3.20 ReferenceError ( . . . )
See
18.3.21 RegExp ( . . . )
See
18.3.22 Set ( . . . )
See
18.3.23 SharedArrayBuffer ( . . . )
See
18.3.24 String ( . . . )
See
18.3.25 Symbol ( . . . )
See
18.3.26 SyntaxError ( . . . )
See
18.3.27 TypeError ( . . . )
See
18.3.28 Uint8Array ( . . . )
See
18.3.29 Uint8ClampedArray ( . . . )
See
18.3.30 Uint16Array ( . . . )
See
18.3.31 Uint32Array ( . . . )
See
18.3.32 URIError ( . . . )
See
18.3.33 WeakMap ( . . . )
See
18.3.34 WeakSet ( . . . )
See
18.4 Other Properties of the Global Object
18.4.1 Atomics
See
18.4.2 JSON
See
18.4.3 Math
See
18.4.4 Reflect
See
19 Fundamental Objects
19.1 Object Objects
19.1.1 The Object Constructor
The Object
- is the intrinsic object %Object%.
- is the initial value of the
Objectproperty of theglobal object . - creates a new ordinary object when called as a
constructor . - performs a type conversion when called as a function rather than as a
constructor . - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition.
19.1.1.1 Object ( [ value ] )
When Object function is called with optional argument value, the following steps are taken:
- If NewTarget is neither
undefined nor the active function, then- Return ?
OrdinaryCreateFromConstructor (NewTarget,"%ObjectPrototype%").
- Return ?
- If value is
null ,undefined or not supplied, returnObjectCreate (%ObjectPrototype% ). - Return !
ToObject (value).
The length property of the Object
19.1.2 Properties of the Object Constructor
The Object
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has a
lengthproperty. - has the following additional properties:
19.1.2.1 Object.assign ( target, ...sources )
The assign function is used to copy the values of all of the enumerable own properties from one or more source objects to a target object. When the assign function is called, the following steps are taken:
- Let to be ?
ToObject (target). - If only one argument was passed, return to.
- Let sources be the
List of argument values starting with the second argument. - For each element nextSource of sources, in ascending index order, do
- Return to.
The length property of the assign function is 2.
19.1.2.2 Object.create ( O, Properties )
The create function creates a new object with a specified prototype. When the create function is called, the following steps are taken:
- If
Type (O) is neither Object nor Null, throw aTypeError exception. - Let obj be
ObjectCreate (O). - If Properties is not
undefined , then- Return ?
ObjectDefineProperties (obj, Properties).
- Return ?
- Return obj.
19.1.2.3 Object.defineProperties ( O, Properties )
The defineProperties function is used to add own properties and/or update the attributes of existing own properties of an object. When the defineProperties function is called, the following steps are taken:
- Return ?
ObjectDefineProperties (O, Properties).
19.1.2.3.1 Runtime Semantics: ObjectDefineProperties ( O, Properties )
The abstract operation ObjectDefineProperties with arguments O and Properties performs the following steps:
- If
Type (O) is not Object, throw aTypeError exception. - Let props be ?
ToObject (Properties). - Let keys be ? props.[[OwnPropertyKeys]]().
- Let descriptors be a new empty
List . - For each element nextKey of keys in
List order, do- Let propDesc be ? props.[[GetOwnProperty]](nextKey).
- If propDesc is not
undefined and propDesc.[[Enumerable]] istrue , then- Let descObj be ?
Get (props, nextKey). - Let desc be ?
ToPropertyDescriptor (descObj). - Append the pair (a two element
List ) consisting of nextKey and desc to the end of descriptors.
- Let descObj be ?
- For each pair from descriptors in list order, do
- Let P be the first element of pair.
- Let desc be the second element of pair.
- Perform ?
DefinePropertyOrThrow (O, P, desc).
- Return O.
19.1.2.4 Object.defineProperty ( O, P, Attributes )
The defineProperty function is used to add an own property and/or update the attributes of an existing own property of an object. When the defineProperty function is called, the following steps are taken:
- If
Type (O) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (P). - Let desc be ?
ToPropertyDescriptor (Attributes). - Perform ?
DefinePropertyOrThrow (O, key, desc). - Return O.
19.1.2.5 Object.entries ( O )
When the entries function is called with argument O, the following steps are taken:
- Let obj be ?
ToObject (O). - Let nameList be ?
EnumerableOwnPropertyNames (obj,"key+value" ). - Return
CreateArrayFromList (nameList).
19.1.2.6 Object.freeze ( O )
When the freeze function is called, the following steps are taken:
- If
Type (O) is not Object, return O. - Let status be ?
SetIntegrityLevel (O,"frozen"). - If status is
false , throw aTypeError exception. - Return O.
19.1.2.7 Object.getOwnPropertyDescriptor ( O, P )
When the getOwnPropertyDescriptor function is called, the following steps are taken:
- Let obj be ?
ToObject (O). - Let key be ?
ToPropertyKey (P). - Let desc be ? obj.[[GetOwnProperty]](key).
- Return
FromPropertyDescriptor (desc).
19.1.2.8 Object.getOwnPropertyDescriptors ( O )
When the getOwnPropertyDescriptors function is called, the following steps are taken:
- Let obj be ?
ToObject (O). - Let ownKeys be ? obj.[[OwnPropertyKeys]]().
- Let descriptors be !
ObjectCreate (%ObjectPrototype% ). - For each element key of ownKeys in
List order, do- Let desc be ? obj.[[GetOwnProperty]](key).
- Let descriptor be !
FromPropertyDescriptor (desc). - If descriptor is not
undefined , perform !CreateDataProperty (descriptors, key, descriptor).
- Return descriptors.
19.1.2.9 Object.getOwnPropertyNames ( O )
When the getOwnPropertyNames function is called, the following steps are taken:
- Return ?
GetOwnPropertyKeys (O, String).
19.1.2.10 Object.getOwnPropertySymbols ( O )
When the getOwnPropertySymbols function is called with argument O, the following steps are taken:
- Return ?
GetOwnPropertyKeys (O, Symbol).
19.1.2.10.1 Runtime Semantics: GetOwnPropertyKeys ( O, Type )
The abstract operation GetOwnPropertyKeys is called with arguments O and Type where O is an Object and Type is one of the ECMAScript specification types String or Symbol. The following steps are taken:
- Let obj be ?
ToObject (O). - Let keys be ? obj.[[OwnPropertyKeys]]().
- Let nameList be a new empty
List . - For each element nextKey of keys in
List order, do- If
Type (nextKey) is Type, then- Append nextKey as the last element of nameList.
- If
- Return
CreateArrayFromList (nameList).
19.1.2.11 Object.getPrototypeOf ( O )
When the getPrototypeOf function is called with argument O, the following steps are taken:
- Let obj be ?
ToObject (O). - Return ? obj.[[GetPrototypeOf]]().
19.1.2.12 Object.is ( value1, value2 )
When the is function is called with arguments value1 and value2, the following steps are taken:
- Return
SameValue (value1, value2).
19.1.2.13 Object.isExtensible ( O )
When the isExtensible function is called with argument O, the following steps are taken:
- If
Type (O) is not Object, returnfalse . - Return ?
IsExtensible (O).
19.1.2.14 Object.isFrozen ( O )
When the isFrozen function is called with argument O, the following steps are taken:
- If
Type (O) is not Object, returntrue . - Return ?
TestIntegrityLevel (O,"frozen").
19.1.2.15 Object.isSealed ( O )
When the isSealed function is called with argument O, the following steps are taken:
- If
Type (O) is not Object, returntrue . - Return ?
TestIntegrityLevel (O,"sealed").
19.1.2.16 Object.keys ( O )
When the keys function is called with argument O, the following steps are taken:
- Let obj be ?
ToObject (O). - Let nameList be ?
EnumerableOwnPropertyNames (obj,"key" ). - Return
CreateArrayFromList (nameList).
19.1.2.17 Object.preventExtensions ( O )
When the preventExtensions function is called, the following steps are taken:
- If
Type (O) is not Object, return O. - Let status be ? O.[[PreventExtensions]]().
- If status is
false , throw aTypeError exception. - Return O.
19.1.2.18 Object.prototype
The initial value of Object.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
19.1.2.19 Object.seal ( O )
When the seal function is called, the following steps are taken:
- If
Type (O) is not Object, return O. - Let status be ?
SetIntegrityLevel (O,"sealed"). - If status is
false , throw aTypeError exception. - Return O.
19.1.2.20 Object.setPrototypeOf ( O, proto )
When the setPrototypeOf function is called with arguments O and proto, the following steps are taken:
- Let O be ?
RequireObjectCoercible (O). - If
Type (proto) is neither Object nor Null, throw aTypeError exception. - If
Type (O) is not Object, return O. - Let status be ? O.[[SetPrototypeOf]](proto).
- If status is
false , throw aTypeError exception. - Return O.
19.1.2.21 Object.values ( O )
When the values function is called with argument O, the following steps are taken:
- Let obj be ?
ToObject (O). - Let nameList be ?
EnumerableOwnPropertyNames (obj,"value" ). - Return
CreateArrayFromList (nameList).
19.1.3 Properties of the Object Prototype Object
The Object prototype object:
- is the intrinsic object %ObjectPrototype%.
- is an
immutable prototype exotic object . - has a [[Prototype]] internal slot whose value is
null .
19.1.3.1 Object.prototype.constructor
The initial value of Object.prototype.constructor is the intrinsic object
19.1.3.2 Object.prototype.hasOwnProperty ( V )
When the hasOwnProperty method is called with argument V, the following steps are taken:
- Let P be ?
ToPropertyKey (V). - Let O be ?
ToObject (this value). - Return ?
HasOwnProperty (O, P).
The ordering of steps 1 and 2 is chosen to ensure that any exception that would have been thrown by step 1 in previous editions of this specification will continue to be thrown even if the
19.1.3.3 Object.prototype.isPrototypeOf ( V )
When the isPrototypeOf method is called with argument V, the following steps are taken:
The ordering of steps 1 and 2 preserves the behaviour specified by previous editions of this specification for the case where V is not an object and the
19.1.3.4 Object.prototype.propertyIsEnumerable ( V )
When the propertyIsEnumerable method is called with argument V, the following steps are taken:
- Let P be ?
ToPropertyKey (V). - Let O be ?
ToObject (this value). - Let desc be ? O.[[GetOwnProperty]](P).
- If desc is
undefined , returnfalse . - Return desc.[[Enumerable]].
This method does not consider objects in the prototype chain.
The ordering of steps 1 and 2 is chosen to ensure that any exception that would have been thrown by step 1 in previous editions of this specification will continue to be thrown even if the
19.1.3.5 Object.prototype.toLocaleString ( [ reserved1 [ , reserved2 ] ] )
When the toLocaleString method is called, the following steps are taken:
- Let O be the
this value. - Return ?
Invoke (O,"toString").
The optional parameters to this function are not used but are intended to correspond to the parameter pattern used by ECMA-402 toLocaleString functions. Implementations that do not include ECMA-402 support must not use those parameter positions for other purposes.
This function provides a generic toLocaleString implementation for objects that have no locale-specific toString behaviour. Array, Number, Date, and Typed Arrays provide their own locale-sensitive toLocaleString methods.
ECMA-402 intentionally does not provide an alternative to this default implementation.
19.1.3.6 Object.prototype.toString ( )
When the toString method is called, the following steps are taken:
- If the
this value isundefined , return"[object Undefined]". - If the
this value isnull , return"[object Null]". - Let O be !
ToObject (this value). - Let isArray be ?
IsArray (O). - If isArray is
true , let builtinTag be"Array". - Else if O is a String
exotic object , let builtinTag be"String". - Else if O has a [[ParameterMap]] internal slot, let builtinTag be
"Arguments". - Else if O has a [[Call]] internal method, let builtinTag be
"Function". - Else if O has an [[ErrorData]] internal slot, let builtinTag be
"Error". - Else if O has a [[BooleanData]] internal slot, let builtinTag be
"Boolean". - Else if O has a [[NumberData]] internal slot, let builtinTag be
"Number". - Else if O has a [[DateValue]] internal slot, let builtinTag be
"Date". - Else if O has a [[RegExpMatcher]] internal slot, let builtinTag be
"RegExp". - Else, let builtinTag be
"Object". - Let tag be ?
Get (O, @@toStringTag). - If
Type (tag) is not String, let tag be builtinTag. - Return the
string-concatenation of"[object ", tag, and"]".
This function is the %ObjProto_toString% intrinsic object.
Historically, this function was occasionally used to access the String value of the [[Class]] internal slot that was used in previous editions of this specification as a nominal type tag for various built-in objects. The above definition of toString preserves compatibility for legacy code that uses toString as a test for those specific kinds of built-in objects. It does not provide a reliable type testing mechanism for other kinds of built-in or program defined objects. In addition, programs can use @@toStringTag in ways that will invalidate the reliability of such legacy type tests.
19.1.3.7 Object.prototype.valueOf ( )
When the valueOf method is called, the following steps are taken:
- Return ?
ToObject (this value).
This function is the %ObjProto_valueOf% intrinsic object.
19.1.4 Properties of Object Instances
Object instances have no special properties beyond those inherited from the Object prototype object.
19.2 Function Objects
19.2.1 The Function Constructor
The Function
- is the intrinsic object %Function%.
- is the initial value of the
Functionproperty of theglobal object . - creates and initializes a new
function object when called as a function rather than as aconstructor . Thus the function callFunction(…)is equivalent to the object creation expressionnew Function(…)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedFunctionbehaviour must include asupercall to theFunctionconstructor to create and initialize a subclass instance with the internal slots necessary for built-in function behaviour. All ECMAScript syntactic forms for defining function objects create instances ofFunction. There is no syntactic means to create instances ofFunctionsubclasses except for the built-inGeneratorFunction,AsyncFunction, andAsyncGeneratorFunctionsubclasses.
19.2.1.1 Function ( p1, p2, … , pn, body )
The last argument specifies the body (executable code) of a function; any preceding arguments specify formal parameters.
When the Function function is called with some arguments p1, p2, … , pn, body (where n might be 0, that is, there are no “ p ” arguments, and where body might also not be provided), the following steps are taken:
- Let C be the
active function object . - Let args be the argumentsList that was passed to this function by [[Call]] or [[Construct]].
- Return ?
CreateDynamicFunction (C, NewTarget,"normal", args).
It is permissible but not necessary to have one argument for each formal parameter to be specified. For example, all three of the following expressions produce the same result:
new Function("a", "b", "c", "return a+b+c")
new Function("a, b, c", "return a+b+c")
new Function("a,b", "c", "return a+b+c")19.2.1.1.1 Runtime Semantics: CreateDynamicFunction ( constructor, newTarget, kind, args )
The abstract operation CreateDynamicFunction is called with arguments constructor, newTarget, kind, and args. constructor is the new was initially applied to, kind is either "normal", "generator", "async", or "async generator", and args is a
Assert : Theexecution context stack has at least two elements.- Let callerContext be the second to top element of the
execution context stack . - Let callerRealm be callerContext's
Realm . - Let calleeRealm be
the current Realm Record . - Perform ?
HostEnsureCanCompileStrings (callerRealm, calleeRealm). - If newTarget is
undefined , set newTarget to constructor. - If kind is
"normal", then- Let goal be the grammar symbol
FunctionBody .[~Yield, ~Await] - Let parameterGoal be the grammar symbol
FormalParameters .[~Yield, ~Await] - Let fallbackProto be
"%FunctionPrototype%".
- Let goal be the grammar symbol
- Else if kind is
"generator", then- Let goal be the grammar symbol
GeneratorBody . - Let parameterGoal be the grammar symbol
FormalParameters .[+Yield, ~Await] - Let fallbackProto be
"%Generator%".
- Let goal be the grammar symbol
- Else if kind is
"async", thenAssert : kind is"async".- Let goal be the grammar symbol
AsyncFunctionBody . - Let parameterGoal be the grammar symbol
FormalParameters .[~Yield, +Await] - Let fallbackProto be
"%AsyncFunctionPrototype%".
- Else,
Assert : kind is"async generator".- Let goal be the grammar symbol
AsyncGeneratorBody . - Let parameterGoal be the grammar symbol
FormalParameters .[+Yield, +Await] - Let fallbackProto be
"%AsyncGenerator%".
- Let argCount be the number of elements in args.
- Let P be the empty String.
- If argCount = 0, let bodyText be the empty String.
- Else if argCount = 1, let bodyText be args[0].
- Else argCount > 1,
- Let firstArg be args[0].
- Set P to ?
ToString (firstArg). - Let k be 1.
- Repeat, while k < argCount-1
- Let nextArg be args[k].
- Let nextArgString be ?
ToString (nextArg). - Set P to the
string-concatenation of the previous value of P,","(a comma), and nextArgString. - Increase k by 1.
- Let bodyText be args[k].
- Set bodyText to ?
ToString (bodyText). - Let parameters be the result of parsing P, interpreted as UTF-16 encoded Unicode text as described in
6.1.4 , using parameterGoal as thegoal symbol . Throw aSyntaxError exception if the parse fails. - Let body be the result of parsing bodyText, interpreted as UTF-16 encoded Unicode text as described in
6.1.4 , using goal as thegoal symbol . Throw aSyntaxError exception if the parse fails. - Let strict be ContainsUseStrict of body.
- If any
static semantics errors are detected for parameters or body, throw aSyntaxError or aReferenceError exception, depending on the type of the error. If strict istrue , the Early Error rules forUniqueFormalParameters : FormalParameters early error detection may be interweaved in an implementation-dependent manner. - If strict is
true and IsSimpleParameterList of parameters isfalse , throw aSyntaxError exception. - If any element of the BoundNames of parameters also occurs in the LexicallyDeclaredNames of body, throw a
SyntaxError exception. - If body Contains
SuperCall istrue , throw aSyntaxError exception. - If parameters Contains
SuperCall istrue , throw aSyntaxError exception. - If body Contains
SuperProperty istrue , throw aSyntaxError exception. - If parameters Contains
SuperProperty istrue , throw aSyntaxError exception. - If kind is
"generator"or"async generator", then- If parameters Contains
YieldExpression istrue , throw aSyntaxError exception.
- If parameters Contains
- If kind is
"async"or"async generator", then- If parameters Contains
AwaitExpression istrue , throw aSyntaxError exception.
- If parameters Contains
- If strict is
true , then- If BoundNames of parameters contains any duplicate elements, throw a
SyntaxError exception.
- If BoundNames of parameters contains any duplicate elements, throw a
- Let proto be ?
GetPrototypeFromConstructor (newTarget, fallbackProto). - Let F be
FunctionAllocate (proto, strict, kind). - Let realmF be F.[[Realm]].
- Let scope be realmF.[[GlobalEnv]].
- Perform
FunctionInitialize (F,Normal , parameters, body, scope). - If kind is
"generator", then- Let prototype be
ObjectCreate (%GeneratorPrototype% ). - Perform
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }).
- Let prototype be
- Else if kind is
"async generator", then- Let prototype be
ObjectCreate (%AsyncGeneratorPrototype% ). - Perform
DefinePropertyOrThrow (F,"prototype", PropertyDescriptor { [[Value]]: prototype, [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }).
- Let prototype be
- Else if kind is
"normal", performMakeConstructor (F). - NOTE: Async functions are not constructable and do not have a [[Construct]] internal method or a
"prototype"property. - Perform
SetFunctionName (F,"anonymous"). - Return F.
A prototype property is created for every non-async function created using CreateDynamicFunction to provide for the possibility that the function will be used as a
19.2.2 Properties of the Function Constructor
The Function
- is itself a built-in
function object . - has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
19.2.2.1 Function.length
This is a
19.2.2.2 Function.prototype
The value of Function.prototype is
This property has the attributes { [[Writable]]:
19.2.3 Properties of the Function Prototype Object
The Function prototype object:
- is the intrinsic object %FunctionPrototype%.
- is itself a built-in
function object . - accepts any arguments and returns
undefined when invoked. - does not have a [[Construct]] internal method; it cannot be used as a
constructor with thenewoperator. - has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - does not have a
prototypeproperty. - has a
lengthproperty whose value is 0. - has a
nameproperty whose value is the empty String.
The Function prototype object is specified to be a
19.2.3.1 Function.prototype.apply ( thisArg, argArray )
When the apply method is called on an object func with arguments thisArg and argArray, the following steps are taken:
- If
IsCallable (func) isfalse , throw aTypeError exception. - If argArray is
undefined ornull , then- Perform
PrepareForTailCall (). - Return ?
Call (func, thisArg).
- Perform
- Let argList be ?
CreateListFromArrayLike (argArray). - Perform
PrepareForTailCall (). - Return ?
Call (func, thisArg, argList).
The thisArg value is passed without modification as the
If func is an arrow function or a
19.2.3.2 Function.prototype.bind ( thisArg, ...args )
When the bind method is called with argument thisArg and zero or more args, it performs the following steps:
- Let Target be the
this value. - If
IsCallable (Target) isfalse , throw aTypeError exception. - Let args be a new (possibly empty)
List consisting of all of the argument values provided after thisArg in order. - Let F be ?
BoundFunctionCreate (Target, thisArg, args). - Let targetHasLength be ?
HasOwnProperty (Target,"length"). - If targetHasLength is
true , then - Else, let L be 0.
- Perform !
SetFunctionLength (F, L). - Let targetName be ?
Get (Target,"name"). - If
Type (targetName) is not String, let targetName be the empty string. - Perform
SetFunctionName (F, targetName,"bound"). - Return F.
Function objects created using Function.prototype.bind are exotic objects. They also do not have a prototype property.
If Target is an arrow function or a
19.2.3.3 Function.prototype.call ( thisArg, ...args )
When the call method is called on an object func with argument, thisArg and zero or more args, the following steps are taken:
- If
IsCallable (func) isfalse , throw aTypeError exception. - Let argList be a new empty
List . - If this method was called with more than one argument, then in left to right order, starting with the second argument, append each argument as the last element of argList.
- Perform
PrepareForTailCall (). - Return ?
Call (func, thisArg, argList).
The thisArg value is passed without modification as the
If func is an arrow function or a
19.2.3.4 Function.prototype.constructor
The initial value of Function.prototype.constructor is the intrinsic object
19.2.3.5 Function.prototype.toString ( )
When the toString method is called on an object func, the following steps are taken:
- If func is a Bound Function
exotic object , then- Return an implementation-dependent String source code representation of func. The representation must conform to the rules below. It is implementation-dependent whether the representation includes
bound function information or information about the target function.
- Return an implementation-dependent String source code representation of func. The representation must conform to the rules below. It is implementation-dependent whether the representation includes
- If
Type (func) is Object and is either a built-infunction object or has an [[ECMAScriptCode]] internal slot, then- Return an implementation-dependent String source code representation of func. The representation must conform to the rules below.
- Throw a
TypeError exception.
toString Representation Requirements:
-
The string representation must have the syntax of a
FunctionDeclaration ,FunctionExpression ,GeneratorDeclaration ,GeneratorExpression ,AsyncFunctionDeclaration ,AsyncFunctionExpression ,AsyncGeneratorDeclaration ,AsyncGeneratorExpression ,ClassDeclaration ,ClassExpression ,ArrowFunction ,AsyncArrowFunction , orMethodDefinition depending upon the actual characteristics of the object. - The use and placement of white space, line terminators, and semicolons within the representation String is implementation-dependent.
-
If the object was defined using ECMAScript code and the returned string representation is not in the form of a
MethodDefinition orGeneratorMethod then the representation must be such that if the string is evaluated, usingevalin a lexical context that is equivalent to the lexical context used to create the original object, it will result in a new functionally equivalent object. In that case the returned source code must not mention freely any variables that were not mentioned freely by the original function's source code, even if these “extra” names were originally in scope. -
If the implementation cannot produce a source code string that meets these criteria then it must return a string for which
evalwill throw aSyntaxError exception.
19.2.3.6 Function.prototype [ @@hasInstance ] ( V )
When the @@hasInstance method of an object F is called with value V, the following steps are taken:
- Let F be the
this value. - Return ?
OrdinaryHasInstance (F, V).
The value of the name property of this function is "[Symbol.hasInstance]".
This property has the attributes { [[Writable]]:
This is the default implementation of @@hasInstance that most functions inherit. @@hasInstance is called by the instanceof operator to determine whether a value is an instance of a specific
v instanceof Fevaluates as
F[@@hasInstance](v)A instanceof by exposing a different @@hasInstance method on the function.
This property is non-writable and non-configurable to prevent tampering that could be used to globally expose the target function of a
19.2.4 Function Instances
Every Function instance is an ECMAScript Function.prototype.bind method (
Function instances have the following properties:
19.2.4.1 length
The value of the length property is an length property depends on the function. This property has the attributes { [[Writable]]:
19.2.4.2 name
The value of the name property is a String that is descriptive of the function. The name has no semantic significance but is typically a variable or
Anonymous functions objects that do not have a contextual name associated with them by this specification do not have a name own property but inherit the name property of
19.2.4.3 prototype
Function instances that can be used as a prototype property. Whenever such a Function instance is created another ordinary object is also created and is the initial value of the function's prototype property. Unless otherwise specified, the value of the prototype property is used to initialize the [[Prototype]] internal slot of the object created when that function is invoked as a
This property has the attributes { [[Writable]]:
Function objects created using Function.prototype.bind, or by evaluating a prototype property.
19.3 Boolean Objects
19.3.1 The Boolean Constructor
The Boolean
- is the intrinsic object %Boolean%.
- is the initial value of the
Booleanproperty of theglobal object . - creates and initializes a new Boolean object when called as a
constructor . - performs a type conversion when called as a function rather than as a
constructor . - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedBooleanbehaviour must include asupercall to theBooleanconstructor to create and initialize the subclass instance with a [[BooleanData]] internal slot.
19.3.1.1 Boolean ( value )
When Boolean is called with argument value, the following steps are taken:
- Let b be
ToBoolean (value). - If NewTarget is
undefined , return b. - Let O be ?
OrdinaryCreateFromConstructor (NewTarget,"%BooleanPrototype%", « [[BooleanData]] »). - Set O.[[BooleanData]] to b.
- Return O.
19.3.2 Properties of the Boolean Constructor
The Boolean
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
19.3.2.1 Boolean.prototype
The initial value of Boolean.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
19.3.3 Properties of the Boolean Prototype Object
The Boolean prototype object:
- is the intrinsic object %BooleanPrototype%.
- is an ordinary object.
- is itself a Boolean object; it has a [[BooleanData]] internal slot with the value
false . - has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
The abstract operation thisBooleanValue(value) performs the following steps:
19.3.3.1 Boolean.prototype.constructor
The initial value of Boolean.prototype.constructor is the intrinsic object
19.3.3.2 Boolean.prototype.toString ( )
The following steps are taken:
- Let b be ?
thisBooleanValue (this value). - If b is
true , return"true"; else return"false".
19.3.3.3 Boolean.prototype.valueOf ( )
The following steps are taken:
- Return ?
thisBooleanValue (this value).
19.3.4 Properties of Boolean Instances
Boolean instances are ordinary objects that inherit properties from the Boolean prototype object. Boolean instances have a [[BooleanData]] internal slot. The [[BooleanData]] internal slot is the Boolean value represented by this Boolean object.
19.4 Symbol Objects
19.4.1 The Symbol Constructor
The Symbol
- is the intrinsic object %Symbol%.
- is the initial value of the
Symbolproperty of theglobal object . - returns a new Symbol value when called as a function.
- is not intended to be used with the
newoperator. - is not intended to be subclassed.
- may be used as the value of an
extendsclause of a class definition but asupercall to it will cause an exception.
19.4.1.1 Symbol ( [ description ] )
When Symbol is called with optional argument description, the following steps are taken:
- If NewTarget is not
undefined , throw aTypeError exception. - If description is
undefined , let descString beundefined . - Else, let descString be ?
ToString (description). - Return a new unique Symbol value whose [[Description]] value is descString.
19.4.2 Properties of the Symbol Constructor
The Symbol
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
19.4.2.1 Symbol.asyncIterator
The initial value of Symbol.asyncIterator is the well known symbol @@asyncIterator (
This property has the attributes { [[Writable]]:
19.4.2.2 Symbol.for ( key )
When Symbol.for is called with argument key it performs the following steps:
- Let stringKey be ?
ToString (key). - For each element e of the GlobalSymbolRegistry
List , do- If
SameValue (e.[[Key]], stringKey) istrue , return e.[[Symbol]].
- If
Assert : GlobalSymbolRegistry does not currently contain an entry for stringKey.- Let newSymbol be a new unique Symbol value whose [[Description]] value is stringKey.
- Append the
Record { [[Key]]: stringKey, [[Symbol]]: newSymbol } to the GlobalSymbolRegistryList . - Return newSymbol.
The GlobalSymbolRegistry is a
19.4.2.3 Symbol.hasInstance
The initial value of Symbol.hasInstance is the well-known symbol @@hasInstance (
This property has the attributes { [[Writable]]:
19.4.2.4 Symbol.isConcatSpreadable
The initial value of Symbol.isConcatSpreadable is the well-known symbol @@isConcatSpreadable (
This property has the attributes { [[Writable]]:
19.4.2.5 Symbol.iterator
The initial value of Symbol.iterator is the well-known symbol @@iterator (
This property has the attributes { [[Writable]]:
19.4.2.6 Symbol.keyFor ( sym )
When Symbol.keyFor is called with argument sym it performs the following steps:
19.4.2.7 Symbol.match
The initial value of Symbol.match is the well-known symbol @@match (
This property has the attributes { [[Writable]]:
19.4.2.8 Symbol.prototype
The initial value of Symbol.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
19.4.2.9 Symbol.replace
The initial value of Symbol.replace is the well-known symbol @@replace (
This property has the attributes { [[Writable]]:
19.4.2.10 Symbol.search
The initial value of Symbol.search is the well-known symbol @@search (
This property has the attributes { [[Writable]]:
19.4.2.11 Symbol.species
The initial value of Symbol.species is the well-known symbol @@species (
This property has the attributes { [[Writable]]:
19.4.2.12 Symbol.split
The initial value of Symbol.split is the well-known symbol @@split (
This property has the attributes { [[Writable]]:
19.4.2.13 Symbol.toPrimitive
The initial value of Symbol.toPrimitive is the well-known symbol @@toPrimitive (
This property has the attributes { [[Writable]]:
19.4.2.14 Symbol.toStringTag
The initial value of Symbol.toStringTag is the well-known symbol @@toStringTag (
This property has the attributes { [[Writable]]:
19.4.2.15 Symbol.unscopables
The initial value of Symbol.unscopables is the well-known symbol @@unscopables (
This property has the attributes { [[Writable]]:
19.4.3 Properties of the Symbol Prototype Object
The Symbol prototype object:
- is the intrinsic object %SymbolPrototype%.
- is an ordinary object.
- is not a Symbol instance and does not have a [[SymbolData]] internal slot.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
The abstract operation thisSymbolValue(value) performs the following steps:
19.4.3.1 Symbol.prototype.constructor
The initial value of Symbol.prototype.constructor is the intrinsic object
19.4.3.2 Symbol.prototype.toString ( )
The following steps are taken:
- Let sym be ?
thisSymbolValue (this value). - Return
SymbolDescriptiveString (sym).
19.4.3.2.1 Runtime Semantics: SymbolDescriptiveString ( sym )
When the abstract operation SymbolDescriptiveString is called with argument sym, the following steps are taken:
Assert :Type (sym) is Symbol.- Let desc be sym's [[Description]] value.
- If desc is
undefined , let desc be the empty string. Assert :Type (desc) is String.- Return the
string-concatenation of"Symbol(", desc, and")".
19.4.3.3 Symbol.prototype.valueOf ( )
The following steps are taken:
- Return ?
thisSymbolValue (this value).
19.4.3.4 Symbol.prototype [ @@toPrimitive ] ( hint )
This function is called by ECMAScript language operators to convert a Symbol object to a primitive value. The allowed values for hint are "default", "number", and "string".
When the @@toPrimitive method is called with argument hint, the following steps are taken:
- Return ?
thisSymbolValue (this value).
The value of the name property of this function is "[Symbol.toPrimitive]".
This property has the attributes { [[Writable]]:
19.4.3.5 Symbol.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Symbol".
This property has the attributes { [[Writable]]:
19.4.4 Properties of Symbol Instances
Symbol instances are ordinary objects that inherit properties from the Symbol prototype object. Symbol instances have a [[SymbolData]] internal slot. The [[SymbolData]] internal slot is the Symbol value represented by this Symbol object.
19.5 Error Objects
Instances of Error objects are thrown as exceptions when runtime errors occur. The Error objects may also serve as base objects for user-defined exception classes.
19.5.1 The Error Constructor
The Error
- is the intrinsic object %Error%.
- is the initial value of the
Errorproperty of theglobal object . - creates and initializes a new Error object when called as a function rather than as a
constructor . Thus the function callError(…)is equivalent to the object creation expressionnew Error(…)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedErrorbehaviour must include asupercall to theErrorconstructor to create and initialize subclass instances with an [[ErrorData]] internal slot.
19.5.1.1 Error ( message )
When the Error function is called with argument message, the following steps are taken:
- If NewTarget is
undefined , let newTarget be theactive function object , else let newTarget be NewTarget. - Let O be ?
OrdinaryCreateFromConstructor (newTarget,"%ErrorPrototype%", « [[ErrorData]] »). - If message is not
undefined , then- Let msg be ?
ToString (message). - Let msgDesc be the PropertyDescriptor { [[Value]]: msg, [[Writable]]:
true , [[Enumerable]]:false , [[Configurable]]:true }. - Perform !
DefinePropertyOrThrow (O,"message", msgDesc).
- Let msg be ?
- Return O.
19.5.2 Properties of the Error Constructor
The Error
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
19.5.2.1 Error.prototype
The initial value of Error.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
19.5.3 Properties of the Error Prototype Object
The Error prototype object:
- is the intrinsic object %ErrorPrototype%.
- is an ordinary object.
- is not an Error instance and does not have an [[ErrorData]] internal slot.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
19.5.3.1 Error.prototype.constructor
The initial value of Error.prototype.constructor is the intrinsic object
19.5.3.2 Error.prototype.message
The initial value of Error.prototype.message is the empty String.
19.5.3.3 Error.prototype.name
The initial value of Error.prototype.name is "Error".
19.5.3.4 Error.prototype.toString ( )
The following steps are taken:
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - Let name be ?
Get (O,"name"). - If name is
undefined , let name be"Error"; otherwise let name be ?ToString (name). - Let msg be ?
Get (O,"message"). - If msg is
undefined , let msg be the empty String; otherwise let msg be ?ToString (msg). - If name is the empty String, return msg.
- If msg is the empty String, return name.
- Return the
string-concatenation of name, the code unit 0x003A (COLON), the code unit 0x0020 (SPACE), and msg.
19.5.4 Properties of Error Instances
Error instances are ordinary objects that inherit properties from the Error prototype object and have an [[ErrorData]] internal slot whose value is Object.prototype.toString.
19.5.5 Native Error Types Used in This Standard
A new instance of one of the NativeError objects below is thrown when a runtime error is detected. All of these objects share the same structure, as described in
19.5.5.1 EvalError
This exception is not currently used within this specification. This object remains for compatibility with previous editions of this specification.
19.5.5.2 RangeError
Indicates a value that is not in the set or range of allowable values.
19.5.5.3 ReferenceError
Indicate that an invalid reference value has been detected.
19.5.5.4 SyntaxError
Indicates that a parsing error has occurred.
19.5.5.5 TypeError
TypeError is used to indicate an unsuccessful operation when none of the other NativeError objects are an appropriate indication of the failure cause.
19.5.5.6 URIError
Indicates that one of the global URI handling functions was used in a way that is incompatible with its definition.
19.5.6 NativeError Object Structure
When an ECMAScript implementation detects a runtime error, it throws a new instance of one of the NativeError objects defined in name property of the prototype object, and in the implementation-defined message property of the prototype object.
For each error object, references to NativeError in the definition should be replaced with the appropriate error object name from
19.5.6.1 The NativeError Constructors
Each NativeError
- creates and initializes a new NativeError object when called as a function rather than as a
constructor . A call of the object as a function is equivalent to calling it as aconstructor with the same arguments. Thus the function callNativeError(…)is equivalent to the object creation expressionnew NativeError(…)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specified NativeError behaviour must include asupercall to the NativeErrorconstructor to create and initialize subclass instances with an [[ErrorData]] internal slot.
19.5.6.1.1 NativeError ( message )
When a NativeError function is called with argument message, the following steps are taken:
- If NewTarget is
undefined , let newTarget be theactive function object , else let newTarget be NewTarget. - Let O be ?
OrdinaryCreateFromConstructor (newTarget,"%NativeErrorPrototype%", « [[ErrorData]] »). - If message is not
undefined , then- Let msg be ?
ToString (message). - Let msgDesc be the PropertyDescriptor { [[Value]]: msg, [[Writable]]:
true , [[Enumerable]]:false , [[Configurable]]:true }. - Perform !
DefinePropertyOrThrow (O,"message", msgDesc).
- Let msg be ?
- Return O.
The actual value of the string passed in step 2 is either "%EvalErrorPrototype%", "%RangeErrorPrototype%", "%ReferenceErrorPrototype%", "%SyntaxErrorPrototype%", "%TypeErrorPrototype%", or "%URIErrorPrototype%" corresponding to which NativeError
19.5.6.2 Properties of the NativeError Constructors
Each NativeError
- has a [[Prototype]] internal slot whose value is the intrinsic object
%Error% . - has a
nameproperty whose value is the String value `"NativeError"`. - has the following properties:
19.5.6.2.1 NativeError.prototype
The initial value of NativeError.prototype is a NativeError prototype object (
This property has the attributes { [[Writable]]:
19.5.6.3 Properties of the NativeError Prototype Objects
Each NativeError prototype object:
- is an ordinary object.
- is not an Error instance and does not have an [[ErrorData]] internal slot.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ErrorPrototype% .
19.5.6.3.1 NativeError.prototype.constructor
The initial value of the constructor property of the prototype for a given NativeError
19.5.6.3.2 NativeError.prototype.message
The initial value of the message property of the prototype for a given NativeError
19.5.6.3.3 NativeError.prototype.name
The initial value of the name property of the prototype for a given NativeError
19.5.6.4 Properties of NativeError Instances
NativeError instances are ordinary objects that inherit properties from their NativeError prototype object and have an [[ErrorData]] internal slot whose value is Object.prototype.toString (
20 Numbers and Dates
20.1 Number Objects
20.1.1 The Number Constructor
The Number
- is the intrinsic object %Number%.
- is the initial value of the
Numberproperty of theglobal object . - creates and initializes a new Number object when called as a
constructor . - performs a type conversion when called as a function rather than as a
constructor . - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedNumberbehaviour must include asupercall to theNumberconstructor to create and initialize the subclass instance with a [[NumberData]] internal slot.
20.1.1.1 Number ( value )
When Number is called with argument value, the following steps are taken:
- If no arguments were passed to this function invocation, let n be
+0 . - Else, let n be ?
ToNumber (value). - If NewTarget is
undefined , return n. - Let O be ?
OrdinaryCreateFromConstructor (NewTarget,"%NumberPrototype%", « [[NumberData]] »). - Set O.[[NumberData]] to n.
- Return O.
20.1.2 Properties of the Number Constructor
The Number
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
20.1.2.1 Number.EPSILON
The value of Number.EPSILON is the difference between 1 and the smallest value greater than 1 that is representable as a
This property has the attributes { [[Writable]]:
20.1.2.2 Number.isFinite ( number )
When Number.isFinite is called with one argument number, the following steps are taken:
- If
Type (number) is not Number, returnfalse . - If number is
NaN ,+∞ , or-∞ , returnfalse . - Otherwise, return
true .
20.1.2.3 Number.isInteger ( number )
When Number.isInteger is called with one argument number, the following steps are taken:
20.1.2.4 Number.isNaN ( number )
When Number.isNaN is called with one argument number, the following steps are taken:
- If
Type (number) is not Number, returnfalse . - If number is
NaN , returntrue . - Otherwise, return
false .
This function differs from the global isNaN function (
20.1.2.5 Number.isSafeInteger ( number )
When Number.isSafeInteger is called with one argument number, the following steps are taken:
20.1.2.6 Number.MAX_SAFE_INTEGER
The value of Number.MAX_SAFE_INTEGER is the largest
The value of Number.MAX_SAFE_INTEGER is 9007199254740991 (253-1).
This property has the attributes { [[Writable]]:
20.1.2.7 Number.MAX_VALUE
The value of Number.MAX_VALUE is the largest positive finite value of the Number type, which is approximately
This property has the attributes { [[Writable]]:
20.1.2.8 Number.MIN_SAFE_INTEGER
The value of Number.MIN_SAFE_INTEGER is the smallest
The value of Number.MIN_SAFE_INTEGER is -9007199254740991 (-(253-1)).
This property has the attributes { [[Writable]]:
20.1.2.9 Number.MIN_VALUE
The value of Number.MIN_VALUE is the smallest positive value of the Number type, which is approximately
In the IEEE 754-2008 double precision binary representation, the smallest possible value is a denormalized number. If an implementation does not support denormalized values, the value of Number.MIN_VALUE must be the smallest non-zero positive value that can actually be represented by the implementation.
This property has the attributes { [[Writable]]:
20.1.2.10 Number.NaN
The value of Number.NaN is
This property has the attributes { [[Writable]]:
20.1.2.11 Number.NEGATIVE_INFINITY
The value of Number.NEGATIVE_INFINITY is
This property has the attributes { [[Writable]]:
20.1.2.12 Number.parseFloat ( string )
The value of the Number.parseFloat parseFloat property of the
20.1.2.13 Number.parseInt ( string, radix )
The value of the Number.parseInt parseInt property of the
20.1.2.14 Number.POSITIVE_INFINITY
The value of Number.POSITIVE_INFINITY is
This property has the attributes { [[Writable]]:
20.1.2.15 Number.prototype
The initial value of Number.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
20.1.3 Properties of the Number Prototype Object
The Number prototype object:
- is the intrinsic object %NumberPrototype%.
- is an ordinary object.
- is itself a Number object; it has a [[NumberData]] internal slot with the value
+0 . - has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
Unless explicitly stated otherwise, the methods of the Number prototype object defined below are not generic and the
The abstract operation thisNumberValue(value) performs the following steps:
- If
Type (value) is Number, return value. - If
Type (value) is Object and value has a [[NumberData]] internal slot, thenAssert : value.[[NumberData]] is aNumber value .- Return value.[[NumberData]].
- Throw a
TypeError exception.
The phrase “this
20.1.3.1 Number.prototype.constructor
The initial value of Number.prototype.constructor is the intrinsic object
20.1.3.2 Number.prototype.toExponential ( fractionDigits )
Return a String containing this
- Let x be ?
thisNumberValue (this value). - Let f be ?
ToInteger (fractionDigits). Assert : f is 0, when fractionDigits isundefined .- If x is
NaN , return the String"NaN". - Let s be the empty String.
- If x < 0, then
- Let s be
"-". - Let x be -x.
- Let s be
- If x =
+∞ , then- Return the
string-concatenation of s and"Infinity".
- Return the
- If f < 0 or f > 100, throw a
RangeError exception. - If x = 0, then
- Let m be the String value consisting of f+1 occurrences of the code unit 0x0030 (DIGIT ZERO).
- Let e be 0.
- Else x ≠ 0,
- If fractionDigits is not
undefined , then- Let e and n be integers such that 10f ≤ n < 10f+1 and for which the exact
mathematical value of n × 10e-f - x is as close to zero as possible. If there are two such sets of e and n, pick the e and n for which n × 10e-f is larger.
- Let e and n be integers such that 10f ≤ n < 10f+1 and for which the exact
- Else fractionDigits is
undefined ,- Let e, n, and f be integers such that f ≥ 0, 10f ≤ n < 10f+1, the
Number value for n × 10e-f is x, and f is as small as possible. Note that the decimal representation of n has f+1 digits, n is not divisible by 10, and the least significant digit of n is not necessarily uniquely determined by these criteria.
- Let e, n, and f be integers such that f ≥ 0, 10f ≤ n < 10f+1, the
- Let m be the String value consisting of the digits of the decimal representation of n (in order, with no leading zeroes).
- If fractionDigits is not
- If f ≠ 0, then
- Let a be the first element of m, and let b be the remaining f elements of m.
- Let m be the
string-concatenation of a,".", and b.
- If e = 0, then
- Let c be
"+". - Let d be
"0".
- Let c be
- Else,
- If e > 0, let c be
"+". - Else e ≤ 0,
- Let c be
"-". - Let e be -e.
- Let c be
- Let d be the String value consisting of the digits of the decimal representation of e (in order, with no leading zeroes).
- If e > 0, let c be
- Let m be the
string-concatenation of m,"e", c, and d. - Return the
string-concatenation of s and m.
For implementations that provide more accurate conversions than required by the rules above, it is recommended that the following alternative version of step 10.b.i be used as a guideline:
- Let e, n, and f be integers such that f ≥ 0, 10f ≤ n < 10f+1, the
Number value for n × 10e-f is x, and f is as small as possible. If there are multiple possibilities for n, choose the value of n for which n × 10e-f is closest in value to x. If there are two such possible values of n, choose the one that is even.
20.1.3.3 Number.prototype.toFixed ( fractionDigits )
toFixed returns a String containing this
The following steps are performed:
- Let x be ?
thisNumberValue (this value). - Let f be ?
ToInteger (fractionDigits). (If fractionDigits isundefined , this step produces the value 0.) - If f < 0 or f > 100, throw a
RangeError exception. - If x is
NaN , return the String"NaN". - Let s be the empty String.
- If x < 0, then
- Let s be
"-". - Let x be -x.
- Let s be
- If x ≥ 1021, then
- Let m be !
ToString (x).
- Let m be !
- Else x < 1021,
- Let n be an
integer for which the exactmathematical value of n ÷ 10f - x is as close to zero as possible. If there are two such n, pick the larger n. - If n = 0, let m be the String
"0". Otherwise, let m be the String value consisting of the digits of the decimal representation of n (in order, with no leading zeroes). - If f ≠ 0, then
- Let k be the length of m.
- If k ≤ f, then
- Let z be the String value consisting of f+1-k occurrences of the code unit 0x0030 (DIGIT ZERO).
- Let m be the
string-concatenation of z and m. - Let k be f + 1.
- Let a be the first k-f elements of m, and let b be the remaining f elements of m.
- Let m be the
string-concatenation of a,".", and b.
- Let n be an
- Return the
string-concatenation of s and m.
The output of toFixed may be more precise than toString for some values because toString only prints enough significant digits to distinguish the number from adjacent number values. For example,
(1000000000000000128).toString() returns "1000000000000000100", while
(1000000000000000128).toFixed(0) returns "1000000000000000128".
20.1.3.4 Number.prototype.toLocaleString ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the Number.prototype.toLocaleString method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleString method is used.
Produces a String value that represents this toString.
The meanings of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
20.1.3.5 Number.prototype.toPrecision ( precision )
Return a String containing this
- Let x be ?
thisNumberValue (this value). - If precision is
undefined , return !ToString (x). - Let p be ?
ToInteger (precision). - If x is
NaN , return the String"NaN". - Let s be the empty String.
- If x < 0, then
- Let s be the code unit 0x002D (HYPHEN-MINUS).
- Let x be -x.
- If x =
+∞ , then- Return the
string-concatenation of s and"Infinity".
- Return the
- If p < 1 or p > 100, throw a
RangeError exception. - If x = 0, then
- Let m be the String value consisting of p occurrences of the code unit 0x0030 (DIGIT ZERO).
- Let e be 0.
- Else x ≠ 0,
- Let e and n be integers such that 10p-1 ≤ n < 10p and for which the exact
mathematical value of n × 10e-p+1 - x is as close to zero as possible. If there are two such sets of e and n, pick the e and n for which n × 10e-p+1 is larger. - Let m be the String value consisting of the digits of the decimal representation of n (in order, with no leading zeroes).
- If e < -6 or e ≥ p, then
Assert : e ≠ 0.- If p ≠ 1, then
- Let a be the first element of m, and let b be the remaining p-1 elements of m.
- Let m be the
string-concatenation of a,".", and b.
- If e > 0, then
- Let c be the code unit 0x002B (PLUS SIGN).
- Else e < 0,
- Let c be the code unit 0x002D (HYPHEN-MINUS).
- Let e be -e.
- Let d be the String value consisting of the digits of the decimal representation of e (in order, with no leading zeroes).
- Return the
string-concatenation of s, m, the code unit 0x0065 (LATIN SMALL LETTER E), c, and d.
- Let e and n be integers such that 10p-1 ≤ n < 10p and for which the exact
- If e = p-1, return the
string-concatenation of s and m. - If e ≥ 0, then
- Let m be the
string-concatenation of the first e+1 elements of m, the code unit 0x002E (FULL STOP), and the remaining p- (e+1) elements of m.
- Let m be the
- Else e < 0,
- Let m be the
string-concatenation of the code unit 0x0030 (DIGIT ZERO), the code unit 0x002E (FULL STOP), -(e+1) occurrences of the code unit 0x0030 (DIGIT ZERO), and the String m.
- Let m be the
- Return the
string-concatenation of s and m.
20.1.3.6 Number.prototype.toString ( [ radix ] )
The optional radix should be an
The following steps are performed:
- Let x be ?
thisNumberValue (this value). - If radix is not present, let radixNumber be 10.
- Else if radix is
undefined , let radixNumber be 10. - Else, let radixNumber be ?
ToInteger (radix). - If radixNumber < 2 or radixNumber > 36, throw a
RangeError exception. - If radixNumber = 10, return !
ToString (x). - Return the String representation of this
Number value using the radix specified by radixNumber. Lettersa-zare used for digits with values 10 through 35. The precise algorithm is implementation-dependent, however the algorithm should be a generalization of that specified in7.1.12.1 .
The toString function is not generic; it throws a
The length property of the toString method is 1.
20.1.3.7 Number.prototype.valueOf ( )
- Return ?
thisNumberValue (this value).
20.1.4 Properties of Number Instances
Number instances are ordinary objects that inherit properties from the Number prototype object. Number instances also have a [[NumberData]] internal slot. The [[NumberData]] internal slot is the
20.2 The Math Object
The Math object:
- is the intrinsic object %Math%.
- is the initial value of the
Mathproperty of theglobal object . - is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is not a
function object . - does not have a [[Construct]] internal method; it cannot be used as a
constructor with thenewoperator. - does not have a [[Call]] internal method; it cannot be invoked as a function.
In this specification, the phrase “the
20.2.1 Value Properties of the Math Object
20.2.1.1 Math.E
The
This property has the attributes { [[Writable]]:
20.2.1.2 Math.LN10
The
This property has the attributes { [[Writable]]:
20.2.1.3 Math.LN2
The
This property has the attributes { [[Writable]]:
20.2.1.4 Math.LOG10E
The
This property has the attributes { [[Writable]]:
The value of Math.LOG10E is approximately the reciprocal of the value of Math.LN10.
20.2.1.5 Math.LOG2E
The
This property has the attributes { [[Writable]]:
The value of Math.LOG2E is approximately the reciprocal of the value of Math.LN2.
20.2.1.6 Math.PI
The
This property has the attributes { [[Writable]]:
20.2.1.7 Math.SQRT1_2
The
This property has the attributes { [[Writable]]:
The value of Math.SQRT1_2 is approximately the reciprocal of the value of Math.SQRT2.
20.2.1.8 Math.SQRT2
The
This property has the attributes { [[Writable]]:
20.2.1.9 Math [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Math".
This property has the attributes { [[Writable]]:
20.2.2 Function Properties of the Math Object
Each of the following Math object functions applies the
In the function descriptions below, the symbols
The behaviour of the functions acos, acosh, asin, asinh, atan, atanh, atan2, cbrt, cos, cosh, exp, expm1, hypot, log,log1p, log2, log10, pow, random, sin, sinh, sqrt, tan, and tanh is not precisely specified here except to require specific results for certain argument values that represent boundary cases of interest. For other argument values, these functions are intended to compute approximations to the results of familiar mathematical functions, but some latitude is allowed in the choice of approximation algorithms. The general intent is that an implementer should be able to use the same mathematical library for ECMAScript on a given hardware platform that is available to C programmers on that platform.
Although the choice of algorithms is left to the implementation, it is recommended (but not specified by this standard) that implementations use the approximation algorithms for IEEE 754-2008 arithmetic contained in fdlibm, the freely distributable mathematical library from Sun Microsystems (http://www.netlib.org/fdlibm).
20.2.2.1 Math.abs ( x )
Returns the absolute value of x; the result has the same magnitude as x but has positive sign.
-
If x is
NaN , the result isNaN . -
If x is
-0 , the result is+0 . -
If x is
-∞ , the result is+∞ .
20.2.2.2 Math.acos ( x )
Returns an implementation-dependent approximation to the arc cosine of x. The result is expressed in radians and ranges from
-
If x is
NaN , the result isNaN . -
If x is greater than 1, the result is
NaN . -
If x is less than -1, the result is
NaN . -
If x is exactly 1, the result is
+0 .
20.2.2.3 Math.acosh ( x )
Returns an implementation-dependent approximation to the inverse hyperbolic cosine of x.
-
If x is
NaN , the result isNaN . -
If x is less than 1, the result is
NaN . -
If x is 1, the result is
+0 . -
If x is
+∞ , the result is+∞ .
20.2.2.4 Math.asin ( x )
Returns an implementation-dependent approximation to the arc sine of x. The result is expressed in radians and ranges from -π/2 to +π/2.
-
If x is
NaN , the result isNaN . -
If x is greater than 1, the result is
NaN . -
If x is less than -1, the result is
NaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 .
20.2.2.5 Math.asinh ( x )
Returns an implementation-dependent approximation to the inverse hyperbolic sine of x.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ .
20.2.2.6 Math.atan ( x )
Returns an implementation-dependent approximation to the arc tangent of x. The result is expressed in radians and ranges from -π/2 to +π/2.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is an implementation-dependent approximation to +π/2. -
If x is
-∞ , the result is an implementation-dependent approximation to -π/2.
20.2.2.7 Math.atanh ( x )
Returns an implementation-dependent approximation to the inverse hyperbolic tangent of x.
-
If x is
NaN , the result isNaN . -
If x is less than -1, the result is
NaN . -
If x is greater than 1, the result is
NaN . -
If x is -1, the result is
-∞ . -
If x is +1, the result is
+∞ . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 .
20.2.2.8 Math.atan2 ( y, x )
Returns an implementation-dependent approximation to the arc tangent of the quotient
-
If either x or y is
NaN , the result isNaN . -
If y>0 and x is
+0 , the result is an implementation-dependent approximation to +π/2. -
If y>0 and x is
-0 , the result is an implementation-dependent approximation to +π/2. -
If y is
+0 and x>0, the result is+0 . -
If y is
+0 and x is+0 , the result is+0 . -
If y is
+0 and x is-0 , the result is an implementation-dependent approximation to +π. -
If y is
+0 and x<0, the result is an implementation-dependent approximation to +π. -
If y is
-0 and x>0, the result is-0 . -
If y is
-0 and x is+0 , the result is-0 . -
If y is
-0 and x is-0 , the result is an implementation-dependent approximation to -π. -
If y is
-0 and x<0, the result is an implementation-dependent approximation to -π. -
If y<0 and x is
+0 , the result is an implementation-dependent approximation to -π/2. -
If y<0 and x is
-0 , the result is an implementation-dependent approximation to -π/2. -
If y>0 and y is finite and x is
+∞ , the result is+0 . -
If y>0 and y is finite and x is
-∞ , the result is an implementation-dependent approximation to +π. -
If y<0 and y is finite and x is
+∞ , the result is-0 . -
If y<0 and y is finite and x is
-∞ , the result is an implementation-dependent approximation to -π. -
If y is
+∞ and x is finite, the result is an implementation-dependent approximation to +π/2. -
If y is
-∞ and x is finite, the result is an implementation-dependent approximation to -π/2. -
If y is
+∞ and x is+∞ , the result is an implementation-dependent approximation to +π/4. -
If y is
+∞ and x is-∞ , the result is an implementation-dependent approximation to +3π/4. -
If y is
-∞ and x is+∞ , the result is an implementation-dependent approximation to -π/4. -
If y is
-∞ and x is-∞ , the result is an implementation-dependent approximation to -3π/4.
20.2.2.9 Math.cbrt ( x )
Returns an implementation-dependent approximation to the cube root of x.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ .
20.2.2.10 Math.ceil ( x )
Returns the smallest (closest to
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ . -
If x is less than 0 but greater than -1, the result is
-0 .
The value of Math.ceil(x) is the same as the value of -Math.floor(-x).
20.2.2.11 Math.clz32 ( x )
When Math.clz32 is called with one argument x, the following steps are taken:
- Let n be
ToUint32 (x). - Let p be the number of leading zero bits in the 32-bit binary representation of n.
- Return p.
If n is 0, p will be 32. If the most significant bit of the 32-bit binary encoding of n is 1, p will be 0.
20.2.2.12 Math.cos ( x )
Returns an implementation-dependent approximation to the cosine of x. The argument is expressed in radians.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is 1. -
If x is
-0 , the result is 1. -
If x is
+∞ , the result isNaN . -
If x is
-∞ , the result isNaN .
20.2.2.13 Math.cosh ( x )
Returns an implementation-dependent approximation to the hyperbolic cosine of x.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is 1. -
If x is
-0 , the result is 1. -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is+∞ .
The value of cosh(x) is the same as (exp(x) + exp(-x))/2.
20.2.2.14 Math.exp ( x )
Returns an implementation-dependent approximation to the exponential function of x (e raised to the power of x, where e is the base of the natural logarithms).
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is 1. -
If x is
-0 , the result is 1. -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is+0 .
20.2.2.15 Math.expm1 ( x )
Returns an implementation-dependent approximation to subtracting 1 from the exponential function of x (e raised to the power of x, where e is the base of the natural logarithms). The result is computed in a way that is accurate even when the value of x is close 0.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is -1.
20.2.2.16 Math.floor ( x )
Returns the greatest (closest to
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ . -
If x is greater than 0 but less than 1, the result is
+0 .
The value of Math.floor(x) is the same as the value of -Math.ceil(-x).
20.2.2.17 Math.fround ( x )
When Math.fround is called with argument x, the following steps are taken:
- If x is
NaN , returnNaN . - If x is one of
+0 ,-0 ,+∞ ,-∞ , return x. - Let x32 be the result of converting x to a value in IEEE 754-2008 binary32 format using roundTiesToEven.
- Let x64 be the result of converting x32 to a value in IEEE 754-2008 binary64 format.
- Return the ECMAScript
Number value corresponding to x64.
20.2.2.18 Math.hypot ( value1, value2, ...values )
Math.hypot returns an implementation-dependent approximation of the square root of the sum of squares of its arguments.
-
If no arguments are passed, the result is
+0 . -
If any argument is
+∞ , the result is+∞ . -
If any argument is
-∞ , the result is+∞ . -
If no argument is
+∞ or-∞ , and any argument isNaN , the result isNaN . -
If all arguments are either
+0 or-0 , the result is+0 .
Implementations should take care to avoid the loss of precision from overflows and underflows that are prone to occur in naive implementations when this function is called with two or more arguments.
20.2.2.19 Math.imul ( x, y )
When Math.imul is called with arguments x and y, the following steps are taken:
20.2.2.20 Math.log ( x )
Returns an implementation-dependent approximation to the natural logarithm of x.
-
If x is
NaN , the result isNaN . -
If x is less than 0, the result is
NaN . -
If x is
+0 or-0 , the result is-∞ . -
If x is 1, the result is
+0 . -
If x is
+∞ , the result is+∞ .
20.2.2.21 Math.log1p ( x )
Returns an implementation-dependent approximation to the natural logarithm of 1 + x. The result is computed in a way that is accurate even when the value of x is close to zero.
-
If x is
NaN , the result isNaN . -
If x is less than -1, the result is
NaN . -
If x is -1, the result is
-∞ . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ .
20.2.2.22 Math.log10 ( x )
Returns an implementation-dependent approximation to the base 10 logarithm of x.
-
If x is
NaN , the result isNaN . -
If x is less than 0, the result is
NaN . -
If x is
+0 , the result is-∞ . -
If x is
-0 , the result is-∞ . -
If x is 1, the result is
+0 . -
If x is
+∞ , the result is+∞ .
20.2.2.23 Math.log2 ( x )
Returns an implementation-dependent approximation to the base 2 logarithm of x.
-
If x is
NaN , the result isNaN . -
If x is less than 0, the result is
NaN . -
If x is
+0 , the result is-∞ . -
If x is
-0 , the result is-∞ . -
If x is 1, the result is
+0 . -
If x is
+∞ , the result is+∞ .
20.2.2.24 Math.max ( value1, value2, ...values )
Given zero or more arguments, calls
-
If no arguments are given, the result is
-∞ . -
If any value is
NaN , the result isNaN . -
The comparison of values to determine the largest value is done using the
Abstract Relational Comparison algorithm except that+0 is considered to be larger than-0 .
20.2.2.25 Math.min ( value1, value2, ...values )
Given zero or more arguments, calls
-
If no arguments are given, the result is
+∞ . -
If any value is
NaN , the result isNaN . -
The comparison of values to determine the smallest value is done using the
Abstract Relational Comparison algorithm except that+0 is considered to be larger than-0 .
20.2.2.26 Math.pow ( base, exponent )
-
Return the result of
Applying the ** operator with base and exponent as specified in12.6.4 .
20.2.2.27 Math.random ( )
Returns a
Each Math.random function created for distinct realms must produce a distinct sequence of values from successive calls.
20.2.2.28 Math.round ( x )
Returns the
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ . -
If x is greater than 0 but less than 0.5, the result is
+0 . -
If x is less than 0 but greater than or equal to -0.5, the result is
-0 .
Math.round(3.5) returns 4, but Math.round(-3.5) returns -3.
The value of Math.round(x) is not always the same as the value of Math.floor(x+0.5). When x is Math.round(x) returns Math.floor(x+0.5) returns Math.round(x) may also differ from the value of Math.floor(x+0.5)because of internal rounding when computing x+0.5.
20.2.2.29 Math.sign ( x )
Returns the sign of x, indicating whether x is positive, negative, or zero.
-
If x is
NaN , the result isNaN . -
If x is
-0 , the result is-0 . -
If x is
+0 , the result is+0 . -
If x is negative and not
-0 , the result is -1. -
If x is positive and not
+0 , the result is +1.
20.2.2.30 Math.sin ( x )
Returns an implementation-dependent approximation to the sine of x. The argument is expressed in radians.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ or-∞ , the result isNaN .
20.2.2.31 Math.sinh ( x )
Returns an implementation-dependent approximation to the hyperbolic sine of x.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ .
The value of sinh(x) is the same as (exp(x) - exp(-x))/2.
20.2.2.32 Math.sqrt ( x )
Returns an implementation-dependent approximation to the square root of x.
-
If x is
NaN , the result isNaN . -
If x is less than 0, the result is
NaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is+∞ .
20.2.2.33 Math.tan ( x )
Returns an implementation-dependent approximation to the tangent of x. The argument is expressed in radians.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ or-∞ , the result isNaN .
20.2.2.34 Math.tanh ( x )
Returns an implementation-dependent approximation to the hyperbolic tangent of x.
-
If x is
NaN , the result isNaN . -
If x is
+0 , the result is+0 . -
If x is
-0 , the result is-0 . -
If x is
+∞ , the result is +1. -
If x is
-∞ , the result is -1.
The value of tanh(x) is the same as (exp(x) - exp(-x))/(exp(x) + exp(-x)).
20.2.2.35 Math.trunc ( x )
Returns the integral part of the number x, removing any fractional digits. If x is already an
-
If x is
NaN , the result isNaN . -
If x is
-0 , the result is-0 . -
If x is
+0 , the result is+0 . -
If x is
+∞ , the result is+∞ . -
If x is
-∞ , the result is-∞ . -
If x is greater than 0 but less than 1, the result is
+0 . -
If x is less than 0 but greater than -1, the result is
-0 .
20.3 Date Objects
20.3.1 Overview of Date Objects and Definitions of Abstract Operations
The following functions are
20.3.1.1 Time Values and Time Range
A Date object contains a Number indicating a particular instant in time to within a millisecond. Such a Number is called a time value. A time value may also be
Time is measured in ECMAScript in milliseconds since 01 January, 1970 UTC. In time values leap seconds are ignored. It is assumed that there are exactly 86,400,000 milliseconds per day. ECMAScript Number values can represent all integers from -9,007,199,254,740,992 to 9,007,199,254,740,992; this range suffices to measure times to millisecond precision for any instant that is within approximately 285,616 years, either forward or backward, from 01 January, 1970 UTC.
The actual range of times supported by ECMAScript Date objects is slightly smaller: exactly -100,000,000 days to 100,000,000 days measured relative to midnight at the beginning of 01 January, 1970 UTC. This gives a range of 8,640,000,000,000,000 milliseconds to either side of 01 January, 1970 UTC.
The exact moment of midnight at the beginning of 01 January, 1970 UTC is represented by the value
20.3.1.2 Day Number and Time within Day
A given
where the number of milliseconds per day is
The remainder is called the time within the day:
20.3.1.3 Year Number
ECMAScript uses a proleptic Gregorian calendar to map a day number to a year number and to determine the month and date within that year. In this calendar, leap years are precisely those which are (divisible by 4) and ((not divisible by 100) or (divisible by 400)). The number of days in year number y is therefore defined by
All non-leap years have 365 days with the usual number of days per month and leap years have an extra day in February. The day number of the first day of year y is given by:
The
A
The leap-year function is 1 for a time within a leap year and otherwise is zero:
20.3.1.4 Month Number
Months are identified by an
where
A month value of 0 specifies January; 1 specifies February; 2 specifies March; 3 specifies April; 4 specifies May; 5 specifies June; 6 specifies July; 7 specifies August; 8 specifies September; 9 specifies October; 10 specifies November; and 11 specifies December. Note that
20.3.1.5 Date Number
A date number is identified by an
20.3.1.6 Week Day
The weekday for a particular
A weekday value of 0 specifies Sunday; 1 specifies Monday; 2 specifies Tuesday; 3 specifies Wednesday; 4 specifies Thursday; 5 specifies Friday; and 6 specifies Saturday. Note that
20.3.1.7 LocalTZA ( t, isUTC )
LocalTZA( t, isUTC ) is an implementation-defined algorithm that must return a number representing milliseconds suitable for adding to a Time Value. The local political rules for standard time and daylight saving time in effect at t should be used to determine the result in the way specified in the following three paragraphs.
When isUTC is true, LocalTZA( t, true ) should return the offset of the local time zone from UTC measured in milliseconds at time represented by
When isUTC is false, LocalTZA( t, false ) should return the offset of the local time zone from UTC measured in milliseconds at local time represented by
When
If an implementation does not support a conversion described above or if political rules for time t are not available within the implementation, the result must be 0.
It is recommended that implementations use the time zone information of the IANA Time Zone Database https://www.iana.org/time-zones/.
1:30 AM on November 5, 2017 in America/New_York is repeated twice (fall backward), but it must be interpreted as 1:30 AM UTC-04 instead of 1:30 AM UTC-05. LocalTZA(
2:30 AM on March 12, 2017 in America/New_York does not exist, but it must be interpreted as 2:30 AM UTC-05 (equivalent to 3:30 AM UTC-04). LocalTZA(
20.3.1.8 LocalTime ( t )
The abstract operation LocalTime with argument t converts t from UTC to local time by performing the following steps:
- Return t + LocalTZA(t,
true ).
Two different time values (t (UTC)) are converted to the same local time
20.3.1.9 UTC ( t )
The abstract operation UTC with argument t converts t from local time to UTC. It performs the following steps:
- Return t - LocalTZA(t,
false ).
20.3.1.10 Hours, Minutes, Second, and Milliseconds
The following
where
20.3.1.11 MakeTime ( hour, min, sec, ms )
The abstract operation MakeTime calculates a number of milliseconds from its four arguments, which must be ECMAScript Number values. This operator functions as follows:
- If hour is not finite or min is not finite or sec is not finite or ms is not finite, return
NaN . - Let h be !
ToInteger (hour). - Let m be !
ToInteger (min). - Let s be !
ToInteger (sec). - Let milli be !
ToInteger (ms). - Let t be h
*msPerHour +m*msPerMinute +s*msPerSecond +milli, performing the arithmetic according to IEEE 754-2008 rules (that is, as if using the ECMAScript operators*and+). - Return t.
20.3.1.12 MakeDay ( year, month, date )
The abstract operation MakeDay calculates a number of days from its three arguments, which must be ECMAScript Number values. This operator functions as follows:
- If year is not finite or month is not finite or date is not finite, return
NaN . - Let y be !
ToInteger (year). - Let m be !
ToInteger (month). - Let dt be !
ToInteger (date). - Let ym be y +
floor (m / 12). - Let mn be m
modulo 12. - Find a value t such that
YearFromTime (t) is ym andMonthFromTime (t) is mn andDateFromTime (t) is 1; but if this is not possible (because some argument is out of range), returnNaN . - Return
Day (t) + dt - 1.
20.3.1.13 MakeDate ( day, time )
The abstract operation MakeDate calculates a number of milliseconds from its two arguments, which must be ECMAScript Number values. This operator functions as follows:
- If day is not finite or time is not finite, return
NaN . - Return day ×
msPerDay + time.
20.3.1.14 TimeClip ( time )
The abstract operation TimeClip calculates a number of milliseconds from its argument, which must be an ECMAScript
The point of step 4 is that an implementation is permitted a choice of internal representations of time values, for example as a 64-bit signed
20.3.1.15 Date Time String Format
ECMAScript defines a string interchange format for date-times based upon a simplification of the ISO 8601 Extended Format. The format is as follows: YYYY-MM-DDTHH:mm:ss.sssZ
Where the fields are as follows:
YYYY
|
is the decimal digits of the year 0000 to 9999 in the proleptic Gregorian calendar. |
-
|
"-" (hyphen) appears literally twice in the string.
|
MM
|
is the month of the year from 01 (January) to 12 (December). |
DD
|
is the day of the month from 01 to 31. |
T
|
"T" appears literally in the string, to indicate the beginning of the time element.
|
HH
|
is the number of complete hours that have passed since midnight as two decimal digits from 00 to 24. |
:
|
":" (colon) appears literally twice in the string.
|
mm
|
is the number of complete minutes since the start of the hour as two decimal digits from 00 to 59. |
ss
|
is the number of complete seconds since the start of the minute as two decimal digits from 00 to 59. |
.
|
"." (dot) appears literally in the string.
|
sss
|
is the number of complete milliseconds since the start of the second as three decimal digits. |
Z
|
is the time zone offset specified as "Z" (for UTC) or either "+" or "-" followed by a time expression HH:mm
|
This format includes date-only forms:
YYYY
YYYY-MM
YYYY-MM-DD
It also includes “date-time” forms that consist of one of the above date-only forms immediately followed by one of the following time forms with an optional time zone offset appended:
THH:mm
THH:mm:ss
THH:mm:ss.sss
All numbers must be base 10. If the MM or DD fields are absent "01" is used as the value. If the HH, mm, or ss fields are absent "00" is used as the value and the value of an absent sss field is "000". When the time zone offset is absent, date-only forms are interpreted as a UTC time and date-time forms are interpreted as a local time.
Illegal values (out-of-bounds as well as syntax errors) in a format string means that the format string is not a valid instance of this format.
As every day both starts and ends with midnight, the two notations 00:00 and 24:00 are available to distinguish the two midnights that can be associated with one date. This means that the following two notations refer to exactly the same point in time: 1995-02-04T24:00 and 1995-02-05T00:00
There exists no international standard that specifies abbreviations for civil time zones like CET, EST, etc. and sometimes the same abbreviation is even used for two very different time zones. For this reason, ISO 8601 and this format specifies numeric representations of date and time.
20.3.1.15.1 Extended Years
ECMAScript requires the ability to specify 6 digit years (extended years); approximately 285,426 years, either forward or backward, from 01 January, 1970 UTC. To represent years before 0 or after 9999, ISO 8601 permits the expansion of the year representation, but only by prior agreement between the sender and the receiver. In the simplified ECMAScript format such an expanded year representation shall have 2 extra year digits and is always prefixed with a + or - sign. The year 0 is considered positive and hence prefixed with a + sign.
Examples of extended years:
| -283457-03-21T15:00:59.008Z | 283458 B.C. |
| -000001-01-01T00:00:00Z | 2 B.C. |
| +000000-01-01T00:00:00Z | 1 B.C. |
| +000001-01-01T00:00:00Z | 1 A.D. |
| +001970-01-01T00:00:00Z | 1970 A.D. |
| +002009-12-15T00:00:00Z | 2009 A.D. |
| +287396-10-12T08:59:00.992Z | 287396 A.D. |
20.3.2 The Date Constructor
The Date
- is the intrinsic object %Date%.
- is the initial value of the
Dateproperty of theglobal object . - creates and initializes a new Date object when called as a
constructor . - returns a String representing the current time (UTC) when called as a function rather than as a
constructor . - is a single function whose behaviour is overloaded based upon the number and types of its arguments.
- is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedDatebehaviour must include asupercall to theDateconstructor to create and initialize the subclass instance with a [[DateValue]] internal slot. - has a
lengthproperty whose value is 7.
20.3.2.1 Date ( year, month [ , date [ , hours [ , minutes [ , seconds [ , ms ] ] ] ] ] )
This description applies only if the Date
When the Date function is called, the following steps are taken:
- Let numberOfArgs be the number of arguments passed to this function call.
Assert : numberOfArgs ≥ 2.- If NewTarget is
undefined , then- Let now be the Number that is the
time value (UTC) identifying the current time. - Return
ToDateString (now).
- Let now be the Number that is the
- Else,
- Let y be ?
ToNumber (year). - Let m be ?
ToNumber (month). - If date is present, let dt be ?
ToNumber (date); else let dt be 1. - If hours is present, let h be ?
ToNumber (hours); else let h be 0. - If minutes is present, let min be ?
ToNumber (minutes); else let min be 0. - If seconds is present, let s be ?
ToNumber (seconds); else let s be 0. - If ms is present, let milli be ?
ToNumber (ms); else let milli be 0. - If y is not
NaN and 0 ≤ToInteger (y) ≤ 99, let yr be 1900+ToInteger (y); otherwise, let yr be y. - Let finalDate be
MakeDate (MakeDay (yr, m, dt),MakeTime (h, min, s, milli)). - Let O be ?
OrdinaryCreateFromConstructor (NewTarget,"%DatePrototype%", « [[DateValue]] »). - Set O.[[DateValue]] to
TimeClip (UTC (finalDate)). - Return O.
- Let y be ?
20.3.2.2 Date ( value )
This description applies only if the Date
When the Date function is called, the following steps are taken:
- Let numberOfArgs be the number of arguments passed to this function call.
Assert : numberOfArgs = 1.- If NewTarget is
undefined , then- Let now be the Number that is the
time value (UTC) identifying the current time. - Return
ToDateString (now).
- Let now be the Number that is the
- Else,
- If
Type (value) is Object and value has a [[DateValue]] internal slot, then- Let tv be
thisTimeValue (value).
- Let tv be
- Else,
- Let v be ?
ToPrimitive (value). - If
Type (v) is String, thenAssert : The next step never returns anabrupt completion because v is a String value.- Let tv be the result of parsing v as a date, in exactly the same manner as for the
parsemethod (20.3.3.2 ).
- Else,
- Let tv be ?
ToNumber (v).
- Let tv be ?
- Let v be ?
- Let O be ?
OrdinaryCreateFromConstructor (NewTarget,"%DatePrototype%", « [[DateValue]] »). - Set O.[[DateValue]] to
TimeClip (tv). - Return O.
- If
20.3.2.3 Date ( )
This description applies only if the Date
When the Date function is called, the following steps are taken:
- Let numberOfArgs be the number of arguments passed to this function call.
Assert : numberOfArgs = 0.- If NewTarget is
undefined , then- Let now be the Number that is the
time value (UTC) identifying the current time. - Return
ToDateString (now).
- Let now be the Number that is the
- Else,
- Let O be ?
OrdinaryCreateFromConstructor (NewTarget,"%DatePrototype%", « [[DateValue]] »). - Set O.[[DateValue]] to the
time value (UTC) identifying the current time. - Return O.
- Let O be ?
20.3.3 Properties of the Date Constructor
The Date
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
20.3.3.1 Date.now ( )
The now function returns a now.
20.3.3.2 Date.parse ( string )
The parse function applies the parse interprets the resulting String as a date and time; it returns a Number, the UTC Date.parse to return
If x is any Date object whose milliseconds amount is zero within a particular implementation of ECMAScript, then all of the following expressions should produce the same numeric value in that implementation, if all the properties referenced have their initial values:
x.valueOf()
Date.parse(x.toString())
Date.parse(x.toUTCString())
Date.parse(x.toISOString())However, the expression
Date.parse(x.toLocaleString())is not required to produce the same Date.parse is implementation-dependent when given any String value that does not conform to the Date Time String Format (toString or toUTCString method.
20.3.3.3 Date.prototype
The initial value of Date.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
20.3.3.4 Date.UTC ( year [ , month [ , date [ , hours [ , minutes [ , seconds [ , ms ] ] ] ] ] ] )
When the UTC function is called, the following steps are taken:
- Let y be ?
ToNumber (year). - If month is present, let m be ?
ToNumber (month); else let m be 0. - If date is present, let dt be ?
ToNumber (date); else let dt be 1. - If hours is present, let h be ?
ToNumber (hours); else let h be 0. - If minutes is present, let min be ?
ToNumber (minutes); else let min be 0. - If seconds is present, let s be ?
ToNumber (seconds); else let s be 0. - If ms is present, let milli be ?
ToNumber (ms); else let milli be 0. - If y is not
NaN and 0 ≤ToInteger (y) ≤ 99, let yr be 1900+ToInteger (y); otherwise, let yr be y. - Return
TimeClip (MakeDate (MakeDay (yr, m, dt),MakeTime (h, min, s, milli))).
The length property of the UTC function is 7.
The UTC function differs from the Date
20.3.4 Properties of the Date Prototype Object
The Date prototype object:
- is the intrinsic object %DatePrototype%.
- is itself an ordinary object.
- is not a Date instance and does not have a [[DateValue]] internal slot.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
Unless explicitly defined otherwise, the methods of the Date prototype object defined below are not generic and the
The abstract operation thisTimeValue(value) performs the following steps:
- If
Type (value) is Object and value has a [[DateValue]] internal slot, then- Return value.[[DateValue]].
- Throw a
TypeError exception.
In following descriptions of functions that are properties of the Date prototype object, the phrase “this Date object” refers to the object that is the
20.3.4.1 Date.prototype.constructor
The initial value of Date.prototype.constructor is the intrinsic object
20.3.4.2 Date.prototype.getDate ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
DateFromTime (LocalTime (t)).
20.3.4.3 Date.prototype.getDay ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
WeekDay (LocalTime (t)).
20.3.4.4 Date.prototype.getFullYear ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
YearFromTime (LocalTime (t)).
20.3.4.5 Date.prototype.getHours ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
HourFromTime (LocalTime (t)).
20.3.4.6 Date.prototype.getMilliseconds ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
msFromTime (LocalTime (t)).
20.3.4.7 Date.prototype.getMinutes ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
MinFromTime (LocalTime (t)).
20.3.4.8 Date.prototype.getMonth ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
MonthFromTime (LocalTime (t)).
20.3.4.9 Date.prototype.getSeconds ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
SecFromTime (LocalTime (t)).
20.3.4.10 Date.prototype.getTime ( )
The following steps are performed:
- Return ?
thisTimeValue (this value).
20.3.4.11 Date.prototype.getTimezoneOffset ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return (t -
LocalTime (t)) /msPerMinute .
20.3.4.12 Date.prototype.getUTCDate ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
DateFromTime (t).
20.3.4.13 Date.prototype.getUTCDay ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
WeekDay (t).
20.3.4.14 Date.prototype.getUTCFullYear ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
YearFromTime (t).
20.3.4.15 Date.prototype.getUTCHours ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
HourFromTime (t).
20.3.4.16 Date.prototype.getUTCMilliseconds ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
msFromTime (t).
20.3.4.17 Date.prototype.getUTCMinutes ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
MinFromTime (t).
20.3.4.18 Date.prototype.getUTCMonth ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
MonthFromTime (t).
20.3.4.19 Date.prototype.getUTCSeconds ( )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
SecFromTime (t).
20.3.4.20 Date.prototype.setDate ( date )
The following steps are performed:
- Let t be
LocalTime (?thisTimeValue (this value)). - Let dt be ?
ToNumber (date). - Let newDate be
MakeDate (MakeDay (YearFromTime (t),MonthFromTime (t), dt),TimeWithinDay (t)). - Let u be
TimeClip (UTC (newDate)). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
20.3.4.21 Date.prototype.setFullYear ( year [ , month [ , date ] ] )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , let t be+0 ; otherwise, let t beLocalTime (t). - Let y be ?
ToNumber (year). - If month is not present, let m be
MonthFromTime (t); otherwise, let m be ?ToNumber (month). - If date is not present, let dt be
DateFromTime (t); otherwise, let dt be ?ToNumber (date). - Let newDate be
MakeDate (MakeDay (y, m, dt),TimeWithinDay (t)). - Let u be
TimeClip (UTC (newDate)). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
The length property of the setFullYear method is 3.
If month is not present, this method behaves as if month was present with the value getMonth(). If date is not present, it behaves as if date was present with the value getDate().
20.3.4.22 Date.prototype.setHours ( hour [ , min [ , sec [ , ms ] ] ] )
The following steps are performed:
- Let t be
LocalTime (?thisTimeValue (this value)). - Let h be ?
ToNumber (hour). - If min is not present, let m be
MinFromTime (t); otherwise, let m be ?ToNumber (min). - If sec is not present, let s be
SecFromTime (t); otherwise, let s be ?ToNumber (sec). - If ms is not present, let milli be
msFromTime (t); otherwise, let milli be ?ToNumber (ms). - Let date be
MakeDate (Day (t),MakeTime (h, m, s, milli)). - Let u be
TimeClip (UTC (date)). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
The length property of the setHours method is 4.
If min is not present, this method behaves as if min was present with the value getMinutes(). If sec is not present, it behaves as if sec was present with the value getSeconds(). If ms is not present, it behaves as if ms was present with the value getMilliseconds().
20.3.4.23 Date.prototype.setMilliseconds ( ms )
The following steps are performed:
- Let t be
LocalTime (?thisTimeValue (this value)). - Let ms be ?
ToNumber (ms). - Let time be
MakeTime (HourFromTime (t),MinFromTime (t),SecFromTime (t), ms). - Let u be
TimeClip (UTC (MakeDate (Day (t), time))). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
20.3.4.24 Date.prototype.setMinutes ( min [ , sec [ , ms ] ] )
The following steps are performed:
- Let t be
LocalTime (?thisTimeValue (this value)). - Let m be ?
ToNumber (min). - If sec is not present, let s be
SecFromTime (t); otherwise, let s be ?ToNumber (sec). - If ms is not present, let milli be
msFromTime (t); otherwise, let milli be ?ToNumber (ms). - Let date be
MakeDate (Day (t),MakeTime (HourFromTime (t), m, s, milli)). - Let u be
TimeClip (UTC (date)). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
The length property of the setMinutes method is 3.
If sec is not present, this method behaves as if sec was present with the value getSeconds(). If ms is not present, this behaves as if ms was present with the value getMilliseconds().
20.3.4.25 Date.prototype.setMonth ( month [ , date ] )
The following steps are performed:
- Let t be
LocalTime (?thisTimeValue (this value)). - Let m be ?
ToNumber (month). - If date is not present, let dt be
DateFromTime (t); otherwise, let dt be ?ToNumber (date). - Let newDate be
MakeDate (MakeDay (YearFromTime (t), m, dt),TimeWithinDay (t)). - Let u be
TimeClip (UTC (newDate)). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
The length property of the setMonth method is 2.
If date is not present, this method behaves as if date was present with the value getDate().
20.3.4.26 Date.prototype.setSeconds ( sec [ , ms ] )
The following steps are performed:
- Let t be
LocalTime (?thisTimeValue (this value)). - Let s be ?
ToNumber (sec). - If ms is not present, let milli be
msFromTime (t); otherwise, let milli be ?ToNumber (ms). - Let date be
MakeDate (Day (t),MakeTime (HourFromTime (t),MinFromTime (t), s, milli)). - Let u be
TimeClip (UTC (date)). - Set the [[DateValue]] internal slot of
this Date object to u. - Return u.
The length property of the setSeconds method is 2.
If ms is not present, this method behaves as if ms was present with the value getMilliseconds().
20.3.4.27 Date.prototype.setTime ( time )
The following steps are performed:
- Perform ?
thisTimeValue (this value). - Let t be ?
ToNumber (time). - Let v be
TimeClip (t). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
20.3.4.28 Date.prototype.setUTCDate ( date )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - Let dt be ?
ToNumber (date). - Let newDate be
MakeDate (MakeDay (YearFromTime (t),MonthFromTime (t), dt),TimeWithinDay (t)). - Let v be
TimeClip (newDate). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
20.3.4.29 Date.prototype.setUTCFullYear ( year [ , month [ , date ] ] )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , let t be+0 . - Let y be ?
ToNumber (year). - If month is not present, let m be
MonthFromTime (t); otherwise, let m be ?ToNumber (month). - If date is not present, let dt be
DateFromTime (t); otherwise, let dt be ?ToNumber (date). - Let newDate be
MakeDate (MakeDay (y, m, dt),TimeWithinDay (t)). - Let v be
TimeClip (newDate). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
The length property of the setUTCFullYear method is 3.
If month is not present, this method behaves as if month was present with the value getUTCMonth(). If date is not present, it behaves as if date was present with the value getUTCDate().
20.3.4.30 Date.prototype.setUTCHours ( hour [ , min [ , sec [ , ms ] ] ] )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - Let h be ?
ToNumber (hour). - If min is not present, let m be
MinFromTime (t); otherwise, let m be ?ToNumber (min). - If sec is not present, let s be
SecFromTime (t); otherwise, let s be ?ToNumber (sec). - If ms is not present, let milli be
msFromTime (t); otherwise, let milli be ?ToNumber (ms). - Let newDate be
MakeDate (Day (t),MakeTime (h, m, s, milli)). - Let v be
TimeClip (newDate). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
The length property of the setUTCHours method is 4.
If min is not present, this method behaves as if min was present with the value getUTCMinutes(). If sec is not present, it behaves as if sec was present with the value getUTCSeconds(). If ms is not present, it behaves as if ms was present with the value getUTCMilliseconds().
20.3.4.31 Date.prototype.setUTCMilliseconds ( ms )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - Let milli be ?
ToNumber (ms). - Let time be
MakeTime (HourFromTime (t),MinFromTime (t),SecFromTime (t), milli). - Let v be
TimeClip (MakeDate (Day (t), time)). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
20.3.4.32 Date.prototype.setUTCMinutes ( min [ , sec [ , ms ] ] )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - Let m be ?
ToNumber (min). - If sec is not present, let s be
SecFromTime (t). - Else,
- Let s be ?
ToNumber (sec).
- Let s be ?
- If ms is not present, let milli be
msFromTime (t). - Else,
- Let milli be ?
ToNumber (ms).
- Let milli be ?
- Let date be
MakeDate (Day (t),MakeTime (HourFromTime (t), m, s, milli)). - Let v be
TimeClip (date). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
The length property of the setUTCMinutes method is 3.
If sec is not present, this method behaves as if sec was present with the value getUTCSeconds(). If ms is not present, it function behaves as if ms was present with the value return by getUTCMilliseconds().
20.3.4.33 Date.prototype.setUTCMonth ( month [ , date ] )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - Let m be ?
ToNumber (month). - If date is not present, let dt be
DateFromTime (t). - Else,
- Let dt be ?
ToNumber (date).
- Let dt be ?
- Let newDate be
MakeDate (MakeDay (YearFromTime (t), m, dt),TimeWithinDay (t)). - Let v be
TimeClip (newDate). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
The length property of the setUTCMonth method is 2.
If date is not present, this method behaves as if date was present with the value getUTCDate().
20.3.4.34 Date.prototype.setUTCSeconds ( sec [ , ms ] )
The following steps are performed:
- Let t be ?
thisTimeValue (this value). - Let s be ?
ToNumber (sec). - If ms is not present, let milli be
msFromTime (t). - Else,
- Let milli be ?
ToNumber (ms).
- Let milli be ?
- Let date be
MakeDate (Day (t),MakeTime (HourFromTime (t),MinFromTime (t), s, milli)). - Let v be
TimeClip (date). - Set the [[DateValue]] internal slot of
this Date object to v. - Return v.
The length property of the setUTCSeconds method is 2.
If ms is not present, this method behaves as if ms was present with the value getUTCMilliseconds().
20.3.4.35 Date.prototype.toDateString ( )
The following steps are performed:
- Let O be
this Date object . - Let tv be ?
thisTimeValue (O). - If tv is
NaN , return"Invalid Date". - Let t be
LocalTime (tv). - Return
DateString (t).
20.3.4.36 Date.prototype.toISOString ( )
This function returns a String value representing the instance in time corresponding to
20.3.4.37 Date.prototype.toJSON ( key )
This function provides a String representation of a Date object for use by JSON.stringify (
When the toJSON method is called with argument key, the following steps are taken:
- Let O be ?
ToObject (this value). - Let tv be ?
ToPrimitive (O, hint Number). - If
Type (tv) is Number and tv is not finite, returnnull . - Return ?
Invoke (O,"toISOString").
The argument is ignored.
The toJSON function is intentionally generic; it does not require that its toISOString method.
20.3.4.38 Date.prototype.toLocaleDateString ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the Date.prototype.toLocaleDateString method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleDateString method is used.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to represent the “date” portion of the Date in the current time zone in a convenient, human-readable form that corresponds to the conventions of the host environment's current locale.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
20.3.4.39 Date.prototype.toLocaleString ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the Date.prototype.toLocaleString method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleString method is used.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to represent the Date in the current time zone in a convenient, human-readable form that corresponds to the conventions of the host environment's current locale.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
20.3.4.40 Date.prototype.toLocaleTimeString ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the Date.prototype.toLocaleTimeString method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleTimeString method is used.
This function returns a String value. The contents of the String are implementation-dependent, but are intended to represent the “time” portion of the Date in the current time zone in a convenient, human-readable form that corresponds to the conventions of the host environment's current locale.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
20.3.4.41 Date.prototype.toString ( )
The following steps are performed:
- Let tv be ?
thisTimeValue (this value). - Return
ToDateString (tv).
For any Date object d whose milliseconds amount is zero, the result of Date.parse(d.toString()) is equal to d.valueOf(). See
The toString function is intentionally generic; it does not require that its
20.3.4.41.1 Runtime Semantics: TimeString ( tv )
The following steps are performed:
Assert :Type (tv) is Number.Assert : tv is notNaN .- Let hour be the String representation of
HourFromTime (tv), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Let minute be the String representation of
MinFromTime (tv), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Let second be the String representation of
SecFromTime (tv), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Return the
string-concatenation of hour,":", minute,":", second, the code unit 0x0020 (SPACE), and"GMT".
20.3.4.41.2 Runtime Semantics: DateString ( tv )
The following steps are performed:
Assert :Type (tv) is Number.Assert : tv is notNaN .- Let weekday be the Name of the entry in
Table 46 with the NumberWeekDay (tv). - Let month be the Name of the entry in
Table 47 with the NumberMonthFromTime (tv). - Let day be the String representation of
DateFromTime (tv), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Let year be the String representation of
YearFromTime (tv), formatted as a decimal number of at least four digits, padded to the left with zeroes if necessary. - Return the
string-concatenation of weekday, the code unit 0x0020 (SPACE), month, the code unit 0x0020 (SPACE), day, the code unit 0x0020 (SPACE), and year.
| Number | Name |
|---|---|
| 0 |
"Sun"
|
| 1 |
"Mon"
|
| 2 |
"Tue"
|
| 3 |
"Wed"
|
| 4 |
"Thu"
|
| 5 |
"Fri"
|
| 6 |
"Sat"
|
| Number | Name |
|---|---|
| 0 |
"Jan"
|
| 1 |
"Feb"
|
| 2 |
"Mar"
|
| 3 |
"Apr"
|
| 4 |
"May"
|
| 5 |
"Jun"
|
| 6 |
"Jul"
|
| 7 |
"Aug"
|
| 8 |
"Sep"
|
| 9 |
"Oct"
|
| 10 |
"Nov"
|
| 11 |
"Dec"
|
20.3.4.41.3 Runtime Semantics: TimeZoneString ( tv )
The following steps are performed:
Assert :Type (tv) is Number.Assert : tv is notNaN .- Let offset be LocalTZA(tv,
true ). - If offset ≥ 0, let offsetSign be
"+"; otherwise, let offsetSign be"-". - Let offsetMin be the String representation of
MinFromTime (abs (offset)), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Let offsetHour be the String representation of
HourFromTime (abs (offset)), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Let tzName be an implementation-defined string that is either the empty string or the
string-concatenation of the code unit 0x0020 (SPACE), the code unit 0x0028 (LEFT PARENTHESIS), an implementation-dependent timezone name, and the code unit 0x0029 (RIGHT PARENTHESIS). - Return the
string-concatenation of offsetSign, offsetHour, offsetMin, and tzName.
20.3.4.41.4 Runtime Semantics: ToDateString ( tv )
The following steps are performed:
Assert :Type (tv) is Number.- If tv is
NaN , return"Invalid Date". - Let t be
LocalTime (tv). - Return the
string-concatenation ofDateString (t), the code unit 0x0020 (SPACE),TimeString (t), andTimeZoneString (tv).
20.3.4.42 Date.prototype.toTimeString ( )
The following steps are performed:
- Let O be
this Date object . - Let tv be ?
thisTimeValue (O). - If tv is
NaN , return"Invalid Date". - Let t be
LocalTime (tv). - Return the
string-concatenation ofTimeString (t) andTimeZoneString (tv).
20.3.4.43 Date.prototype.toUTCString ( )
The following steps are performed:
- Let O be
this Date object . - Let tv be ?
thisTimeValue (O). - If tv is
NaN , return"Invalid Date". - Let weekday be the Name of the entry in
Table 46 with the NumberWeekDay (tv). - Let month be the Name of the entry in
Table 47 with the NumberMonthFromTime (tv). - Let day be the String representation of
DateFromTime (tv), formatted as a two-digit decimal number, padded to the left with a zero if necessary. - Let year be the String representation of
YearFromTime (tv), formatted as a decimal number of at least four digits, padded to the left with zeroes if necessary. - Return the
string-concatenation of weekday,",", the code unit 0x0020 (SPACE), day, the code unit 0x0020 (SPACE), month, the code unit 0x0020 (SPACE), year, the code unit 0x0020 (SPACE), andTimeString (tv).
20.3.4.44 Date.prototype.valueOf ( )
The following steps are performed:
- Return ?
thisTimeValue (this value).
20.3.4.45 Date.prototype [ @@toPrimitive ] ( hint )
This function is called by ECMAScript language operators to convert a Date object to a primitive value. The allowed values for hint are "default", "number", and "string". Date objects, are unique among built-in ECMAScript object in that they treat "default" as being equivalent to "string", All other built-in ECMAScript objects treat "default" as being equivalent to "number".
When the @@toPrimitive method is called with argument hint, the following steps are taken:
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If hint is the String value
"string"or the String value"default", then- Let tryFirst be
"string".
- Let tryFirst be
- Else if hint is the String value
"number", then- Let tryFirst be
"number".
- Let tryFirst be
- Else, throw a
TypeError exception. - Return ?
OrdinaryToPrimitive (O, tryFirst).
The value of the name property of this function is "[Symbol.toPrimitive]".
This property has the attributes { [[Writable]]:
20.3.5 Properties of Date Instances
Date instances are ordinary objects that inherit properties from the Date prototype object. Date instances also have a [[DateValue]] internal slot. The [[DateValue]] internal slot is the
21 Text Processing
21.1 String Objects
21.1.1 The String Constructor
The String
- is the intrinsic object %String%.
- is the initial value of the
Stringproperty of theglobal object . - creates and initializes a new String object when called as a
constructor . - performs a type conversion when called as a function rather than as a
constructor . - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedStringbehaviour must include asupercall to theStringconstructor to create and initialize the subclass instance with a [[StringData]] internal slot.
21.1.1.1 String ( value )
When String is called with argument value, the following steps are taken:
- If no arguments were passed to this function invocation, let s be
"". - Else,
- If NewTarget is
undefined andType (value) is Symbol, returnSymbolDescriptiveString (value). - Let s be ?
ToString (value).
- If NewTarget is
- If NewTarget is
undefined , return s. - Return ?
StringCreate (s, ?GetPrototypeFromConstructor (NewTarget,"%StringPrototype%")).
21.1.2 Properties of the String Constructor
The String
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
21.1.2.1 String.fromCharCode ( ...codeUnits )
The String.fromCharCode function may be called with any number of arguments which form the rest parameter codeUnits. The following steps are taken:
- Let codeUnits be a
List containing the arguments passed to this function. - Let length be the number of elements in codeUnits.
- Let elements be a new empty
List . - Let nextIndex be 0.
- Repeat, while nextIndex < length
- Let next be codeUnits[nextIndex].
- Let nextCU be ?
ToUint16 (next). - Append nextCU to the end of elements.
- Let nextIndex be nextIndex + 1.
- Return the String value whose elements are, in order, the elements in the
List elements. If length is 0, the empty string is returned.
The length property of the fromCharCode function is 1.
21.1.2.2 String.fromCodePoint ( ...codePoints )
The String.fromCodePoint function may be called with any number of arguments which form the rest parameter codePoints. The following steps are taken:
- Let codePoints be a
List containing the arguments passed to this function. - Let length be the number of elements in codePoints.
- Let elements be a new empty
List . - Let nextIndex be 0.
- Repeat, while nextIndex < length
- Let next be codePoints[nextIndex].
- Let nextCP be ?
ToNumber (next). - If
SameValue (nextCP,ToInteger (nextCP)) isfalse , throw aRangeError exception. - If nextCP < 0 or nextCP > 0x10FFFF, throw a
RangeError exception. - Append the elements of the
UTF16Encoding of nextCP to the end of elements. - Let nextIndex be nextIndex + 1.
- Return the String value whose elements are, in order, the elements in the
List elements. If length is 0, the empty string is returned.
The length property of the fromCodePoint function is 1.
21.1.2.3 String.prototype
The initial value of String.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
21.1.2.4 String.raw ( template, ...substitutions )
The String.raw function may be called with a variable number of arguments. The first argument is template and the remainder of the arguments form the
- Let substitutions be a
List consisting of all of the arguments passed to this function, starting with the second argument. If fewer than two arguments were passed, theList is empty. - Let numberOfSubstitutions be the number of elements in substitutions.
- Let cooked be ?
ToObject (template). - Let raw be ?
ToObject (?Get (cooked,"raw")). - Let literalSegments be ?
ToLength (?Get (raw,"length")). - If literalSegments ≤ 0, return the empty string.
- Let stringElements be a new empty
List . - Let nextIndex be 0.
- Repeat,
- Let nextKey be !
ToString (nextIndex). - Let nextSeg be ?
ToString (?Get (raw, nextKey)). - Append in order the code unit elements of nextSeg to the end of stringElements.
- If nextIndex + 1 = literalSegments, then
- Return the String value whose code units are, in order, the elements in the
List stringElements. If stringElements has no elements, the empty string is returned.
- Return the String value whose code units are, in order, the elements in the
- If nextIndex < numberOfSubstitutions, let next be substitutions[nextIndex].
- Else, let next be the empty String.
- Let nextSub be ?
ToString (next). - Append in order the code unit elements of nextSub to the end of stringElements.
- Let nextIndex be nextIndex + 1.
- Let nextKey be !
String.raw is intended for use as a tag function of a Tagged Template (
21.1.3 Properties of the String Prototype Object
The String prototype object:
- is the intrinsic object %StringPrototype%.
- is a String
exotic object and has the internal methods specified for such objects. - has a [[StringData]] internal slot whose value is the empty String.
- has a
lengthproperty whose initial value is 0 and whose attributes are { [[Writable]]:false , [[Enumerable]]:false , [[Configurable]]:false }. - has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
Unless explicitly stated otherwise, the methods of the String prototype object defined below are not generic and the
The abstract operation thisStringValue(value) performs the following steps:
21.1.3.1 String.prototype.charAt ( pos )
Returns a single element String containing the code unit at index pos within the String value resulting from converting this object to a String. If there is no element at that index, the result is the empty String. The result is a String value, not a String object.
If pos is a value of Number type that is an x.charAt(pos) is equal to the result of x.substring(pos, pos+1).
When the charAt method is called with one argument pos, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let position be ?
ToInteger (pos). - Let size be the length of S.
- If position < 0 or position ≥ size, return the empty String.
- Return the String value of length 1, containing one code unit from S, namely the code unit at index position.
The charAt function is intentionally generic; it does not require that its
21.1.3.2 String.prototype.charCodeAt ( pos )
Returns a Number (a nonnegative
When the charCodeAt method is called with one argument pos, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let position be ?
ToInteger (pos). - Let size be the length of S.
- If position < 0 or position ≥ size, return
NaN . - Return a value of Number type, whose value is the numeric value of the code unit at index position within the String S.
The charCodeAt function is intentionally generic; it does not require that its
21.1.3.3 String.prototype.codePointAt ( pos )
Returns a nonnegative
When the codePointAt method is called with one argument pos, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let position be ?
ToInteger (pos). - Let size be the length of S.
- If position < 0 or position ≥ size, return
undefined . - Let first be the numeric value of the code unit at index position within the String S.
- If first < 0xD800 or first > 0xDBFF or position+1 = size, return first.
- Let second be the numeric value of the code unit at index position+1 within the String S.
- If second < 0xDC00 or second > 0xDFFF, return first.
- Return
UTF16Decode (first, second).
The codePointAt function is intentionally generic; it does not require that its
21.1.3.4 String.prototype.concat ( ...args )
When the concat method is called it returns the String value consisting of the code units of the this object (converted to a String) followed by the code units of each of the arguments converted to a String. The result is a String value, not a String object.
When the concat method is called with zero or more arguments, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let args be a
List whose elements are the arguments passed to this function. - Let R be S.
- Repeat, while args is not empty
- Remove the first element from args and let next be the value of that element.
- Let nextString be ?
ToString (next). - Set R to the
string-concatenation of the previous value of R and nextString.
- Return R.
The length property of the concat method is 1.
The concat function is intentionally generic; it does not require that its
21.1.3.5 String.prototype.constructor
The initial value of String.prototype.constructor is the intrinsic object
21.1.3.6 String.prototype.endsWith ( searchString [ , endPosition ] )
The following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let isRegExp be ?
IsRegExp (searchString). - If isRegExp is
true , throw aTypeError exception. - Let searchStr be ?
ToString (searchString). - Let len be the length of S.
- If endPosition is
undefined , let pos be len, else let pos be ?ToInteger (endPosition). - Let end be
min (max (pos, 0), len). - Let searchLength be the length of searchStr.
- Let start be end - searchLength.
- If start is less than 0, return
false . - If the sequence of elements of S starting at start of length searchLength is the same as the full element sequence of searchStr, return
true . - Otherwise, return
false .
Returns
Throwing an exception if the first argument is a RegExp is specified in order to allow future editions to define extensions that allow such argument values.
The endsWith function is intentionally generic; it does not require that its
21.1.3.7 String.prototype.includes ( searchString [ , position ] )
The includes method takes two arguments, searchString and position, and performs the following steps:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let isRegExp be ?
IsRegExp (searchString). - If isRegExp is
true , throw aTypeError exception. - Let searchStr be ?
ToString (searchString). - Let pos be ?
ToInteger (position). (If position isundefined , this step produces the value 0.) - Let len be the length of S.
- Let start be
min (max (pos, 0), len). - Let searchLen be the length of searchStr.
- If there exists any
integer k not smaller than start such that k + searchLen is not greater than len, and for all nonnegative integers j less than searchLen, the code unit at index k+j within S is the same as the code unit at index j within searchStr, returntrue ; but if there is no suchinteger k, returnfalse .
If searchString appears as a substring of the result of converting this object to a String, at one or more indices that are greater than or equal to position, return
Throwing an exception if the first argument is a RegExp is specified in order to allow future editions to define extensions that allow such argument values.
The includes function is intentionally generic; it does not require that its
21.1.3.8 String.prototype.indexOf ( searchString [ , position ] )
If searchString appears as a substring of the result of converting this object to a String, at one or more indices that are greater than or equal to position, then the smallest such index is returned; otherwise, -1 is returned. If position is
The indexOf method takes two arguments, searchString and position, and performs the following steps:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let searchStr be ?
ToString (searchString). - Let pos be ?
ToInteger (position). (If position isundefined , this step produces the value 0.) - Let len be the length of S.
- Let start be
min (max (pos, 0), len). - Let searchLen be the length of searchStr.
- Return the smallest possible
integer k not smaller than start such that k+searchLen is not greater than len, and for all nonnegative integers j less than searchLen, the code unit at index k+j within S is the same as the code unit at index j within searchStr; but if there is no suchinteger k, return the value -1.
The indexOf function is intentionally generic; it does not require that its
21.1.3.9 String.prototype.lastIndexOf ( searchString [ , position ] )
If searchString appears as a substring of the result of converting this object to a String at one or more indices that are smaller than or equal to position, then the greatest such index is returned; otherwise, -1 is returned. If position is
The lastIndexOf method takes two arguments, searchString and position, and performs the following steps:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let searchStr be ?
ToString (searchString). - Let numPos be ?
ToNumber (position). (If position isundefined , this step produces the valueNaN .) - If numPos is
NaN , let pos be+∞ ; otherwise, let pos beToInteger (numPos). - Let len be the length of S.
- Let start be
min (max (pos, 0), len). - Let searchLen be the length of searchStr.
- Return the largest possible nonnegative
integer k not larger than start such that k+searchLen is not greater than len, and for all nonnegative integers j less than searchLen, the code unit at index k+j within S is the same as the code unit at index j within searchStr; but if there is no suchinteger k, return the value -1.
The lastIndexOf function is intentionally generic; it does not require that its
21.1.3.10 String.prototype.localeCompare ( that [ , reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the localeCompare method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the localeCompare method is used.
When the localeCompare method is called with argument that, it returns a Number other than
Before performing the comparisons, the following steps are performed to prepare the Strings:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let That be ?
ToString (that).
The meaning of the optional second and third parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not assign any other interpretation to those parameter positions.
The localeCompare method, if considered as a function of two arguments
The actual return values are implementation-defined to permit implementers to encode additional information in the value, but the function is required to define a total ordering on all Strings. This function must treat Strings that are canonically equivalent according to the Unicode standard as identical and must return 0 when comparing Strings that are considered canonically equivalent.
The localeCompare method itself is not directly suitable as an argument to Array.prototype.sort because the latter requires a function of two arguments.
This function is intended to rely on whatever language-sensitive comparison functionality is available to the ECMAScript environment from the host environment, and to compare according to the rules of the host environment's current locale. However, regardless of the host provided comparison capabilities, this function must treat Strings that are canonically equivalent according to the Unicode standard as identical. It is recommended that this function should not honour Unicode compatibility equivalences or decompositions. For a definition and discussion of canonical equivalence see the Unicode Standard, chapters 2 and 3, as well as Unicode Standard Annex #15, Unicode Normalization Forms (https://unicode.org/reports/tr15/) and Unicode Technical Note #5, Canonical Equivalence in Applications (https://www.unicode.org/notes/tn5/). Also see Unicode Technical Standard #10, Unicode Collation Algorithm (https://unicode.org/reports/tr10/).
The localeCompare function is intentionally generic; it does not require that its
21.1.3.11 String.prototype.match ( regexp )
When the match method is called with argument regexp, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - If regexp is neither
undefined nornull , then - Let S be ?
ToString (O). - Let rx be ?
RegExpCreate (regexp,undefined ). - Return ?
Invoke (rx, @@match, « S »).
The match function is intentionally generic; it does not require that its
21.1.3.12 String.prototype.normalize ( [ form ] )
When the normalize method is called with one argument form, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - If form is not present or form is
undefined , let form be"NFC". - Let f be ?
ToString (form). - If f is not one of
"NFC","NFD","NFKC", or"NFKD", throw aRangeError exception. - Let ns be the String value that is the result of normalizing S into the normalization form named by f as specified in https://unicode.org/reports/tr15/.
- Return ns.
The normalize function is intentionally generic; it does not require that its
21.1.3.13 String.prototype.padEnd ( maxLength [ , fillString ] )
When the padEnd method is called, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let intMaxLength be ?
ToLength (maxLength). - Let stringLength be the length of S.
- If intMaxLength is not greater than stringLength, return S.
- If fillString is
undefined , let filler be the String value consisting solely of the code unit 0x0020 (SPACE). - Else, let filler be ?
ToString (fillString). - If filler is the empty String, return S.
- Let fillLen be intMaxLength - stringLength.
- Let truncatedStringFiller be the String value consisting of repeated concatenations of filler truncated to length fillLen.
- Return the
string-concatenation of S and truncatedStringFiller.
The first argument maxLength will be clamped such that it can be no smaller than the length of the
The optional second argument fillString defaults to
21.1.3.14 String.prototype.padStart ( maxLength [ , fillString ] )
When the padStart method is called, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let intMaxLength be ?
ToLength (maxLength). - Let stringLength be the length of S.
- If intMaxLength is not greater than stringLength, return S.
- If fillString is
undefined , let filler be the String value consisting solely of the code unit 0x0020 (SPACE). - Else, let filler be ?
ToString (fillString). - If filler is the empty String, return S.
- Let fillLen be intMaxLength - stringLength.
- Let truncatedStringFiller be the String value consisting of repeated concatenations of filler truncated to length fillLen.
- Return the
string-concatenation of truncatedStringFiller and S.
The first argument maxLength will be clamped such that it can be no smaller than the length of the
The optional second argument fillString defaults to
21.1.3.15 String.prototype.repeat ( count )
The following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let n be ?
ToInteger (count). - If n < 0, throw a
RangeError exception. - If n is
+∞ , throw aRangeError exception. - Let T be the String value that is made from n copies of S appended together. If n is 0, T is the empty String.
- Return T.
This method creates the String value consisting of the code units of the this object (converted to String) repeated count times.
The repeat function is intentionally generic; it does not require that its
21.1.3.16 String.prototype.replace ( searchValue, replaceValue )
When the replace method is called with arguments searchValue and replaceValue, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - If searchValue is neither
undefined nornull , then - Let string be ?
ToString (O). - Let searchString be ?
ToString (searchValue). - Let functionalReplace be
IsCallable (replaceValue). - If functionalReplace is
false , then- Let replaceValue be ?
ToString (replaceValue).
- Let replaceValue be ?
- Search string for the first occurrence of searchString and let pos be the index within string of the first code unit of the matched substring and let matched be searchString. If no occurrences of searchString were found, return string.
- If functionalReplace is
true , then - Else,
- Let captures be a new empty
List . - Let replStr be
GetSubstitution (matched, string, pos, captures,undefined , replaceValue).
- Let captures be a new empty
- Let tailPos be pos + the number of code units in matched.
- Let newString be the
string-concatenation of the first pos code units of string, replStr, and the trailing substring of string starting at index tailPos. If pos is 0, the first element of the concatenation will be the empty String. - Return newString.
The replace function is intentionally generic; it does not require that its
21.1.3.16.1 Runtime Semantics: GetSubstitution ( matched, str, position, captures, namedCaptures, replacement )
The abstract operation GetSubstitution performs the following steps:
Assert :Type (matched) is String.- Let matchLength be the number of code units in matched.
Assert :Type (str) is String.- Let stringLength be the number of code units in str.
Assert : position is a nonnegativeinteger .Assert : position ≤ stringLength.Assert : captures is a possibly emptyList of Strings.Assert :Type (replacement) is String.- Let tailPos be position + matchLength.
- Let m be the number of elements in captures.
- If namedCaptures is not
undefined , then- Set namedCaptures to ?
ToObject (namedCaptures).
- Set namedCaptures to ?
- Let result be the String value derived from replacement by copying code unit elements from replacement to result while performing replacements as specified in
Table 48 . These$replacements are done left-to-right, and, once such a replacement is performed, the new replacement text is not subject to further replacements. - Return result.
| Code units | Unicode Characters | Replacement text |
|---|---|---|
| 0x0024, 0x0024 |
$$
|
$
|
| 0x0024, 0x0026 |
$&
|
matched |
| 0x0024, 0x0060 |
$`
|
If position is 0, the replacement is the empty String. Otherwise the replacement is the substring of str that starts at index 0 and whose last code unit is at index position - 1. |
| 0x0024, 0x0027 |
$'
|
If tailPos ≥ stringLength, the replacement is the empty String. Otherwise the replacement is the substring of str that starts at index tailPos and continues to the end of str. |
|
0x0024, N
Where 0x0031 ≤ N ≤ 0x0039 |
$n where
n is one of 1 2 3 4 5 6 7 8 9 and $n is not followed by a decimal digit
|
The nth element of captures, where n is a single digit in the range 1 to 9. If n≤m and the nth element of captures is |
|
0x0024, N, N
Where 0x0030 ≤ N ≤ 0x0039 |
$nn where
n is one of 0 1 2 3 4 5 6 7 8 9
|
The nnth element of captures, where nn is a two-digit decimal number in the range 01 to 99. If nn≤m and the nnth element of captures is |
| 0x0024, 0x003C |
$<
|
|
| 0x0024 |
$ in any context that does not match any of the above.
|
$
|
21.1.3.17 String.prototype.search ( regexp )
When the search method is called with argument regexp, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - If regexp is neither
undefined nornull , then - Let string be ?
ToString (O). - Let rx be ?
RegExpCreate (regexp,undefined ). - Return ?
Invoke (rx, @@search, « string »).
The search function is intentionally generic; it does not require that its
21.1.3.18 String.prototype.slice ( start, end )
The slice method takes two arguments, start and end, and returns a substring of the result of converting this object to a String, starting from index start and running to, but not including, index end (or through the end of the String if end is
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let len be the length of S.
- Let intStart be ?
ToInteger (start). - If end is
undefined , let intEnd be len; else let intEnd be ?ToInteger (end). - If intStart < 0, let from be
max (len + intStart, 0); otherwise let from bemin (intStart, len). - If intEnd < 0, let to be
max (len + intEnd, 0); otherwise let to bemin (intEnd, len). - Let span be
max (to - from, 0). - Return the String value containing span consecutive elements from S beginning with the element at index from.
The slice function is intentionally generic; it does not require that its
21.1.3.19 String.prototype.split ( separator, limit )
Returns an Array object into which substrings of the result of converting this object to a String have been stored. The substrings are determined by searching from left to right for occurrences of separator; these occurrences are not part of any substring in the returned array, but serve to divide up the String value. The value of separator may be a String of any length or it may be an object, such as a RegExp, that has a @@split method.
When the split method is called, the following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - If separator is neither
undefined nornull , then - Let S be ?
ToString (O). - Let A be !
ArrayCreate (0). - Let lengthA be 0.
- If limit is
undefined , let lim be 232-1; else let lim be ?ToUint32 (limit). - Let s be the length of S.
- Let p be 0.
- Let R be ?
ToString (separator). - If lim = 0, return A.
- If separator is
undefined , then- Perform !
CreateDataProperty (A,"0", S). - Return A.
- Perform !
- If s = 0, then
- Let z be
SplitMatch (S, 0, R). - If z is not
false , return A. - Perform !
CreateDataProperty (A,"0", S). - Return A.
- Let z be
- Let q be p.
- Repeat, while q ≠ s
- Let e be
SplitMatch (S, q, R). - If e is
false , let q be q+1. - Else e is an
integer index ≤ s,- If e = p, let q be q+1.
- Else e ≠ p,
- Let T be the String value equal to the substring of S consisting of the code units at indices p (inclusive) through q (exclusive).
- Perform !
CreateDataProperty (A, !ToString (lengthA), T). - Increment lengthA by 1.
- If lengthA = lim, return A.
- Let p be e.
- Let q be p.
- Let e be
- Let T be the String value equal to the substring of S consisting of the code units at indices p (inclusive) through s (exclusive).
- Perform !
CreateDataProperty (A, !ToString (lengthA), T). - Return A.
The value of separator may be an empty String. In this case, separator does not match the empty substring at the beginning or end of the input String, nor does it match the empty substring at the end of the previous separator match. If separator is the empty String, the String is split up into individual code unit elements; the length of the result array equals the length of the String, and each substring contains one code unit.
If the
If separator is
The split function is intentionally generic; it does not require that its
21.1.3.19.1 Runtime Semantics: SplitMatch ( S, q, R )
The abstract operation SplitMatch takes three parameters, a String S, an
Assert :Type (R) is String.- Let r be the number of code units in R.
- Let s be the number of code units in S.
- If q+r > s, return
false . - If there exists an
integer i between 0 (inclusive) and r (exclusive) such that the code unit at index q+i within S is different from the code unit at index i within R, returnfalse . - Return q+r.
21.1.3.20 String.prototype.startsWith ( searchString [ , position ] )
The following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let isRegExp be ?
IsRegExp (searchString). - If isRegExp is
true , throw aTypeError exception. - Let searchStr be ?
ToString (searchString). - Let pos be ?
ToInteger (position). (If position isundefined , this step produces the value 0.) - Let len be the length of S.
- Let start be
min (max (pos, 0), len). - Let searchLength be the length of searchStr.
- If searchLength+start is greater than len, return
false . - If the sequence of elements of S starting at start of length searchLength is the same as the full element sequence of searchStr, return
true . - Otherwise, return
false .
This method returns
Throwing an exception if the first argument is a RegExp is specified in order to allow future editions to define extensions that allow such argument values.
The startsWith function is intentionally generic; it does not require that its
21.1.3.21 String.prototype.substring ( start, end )
The substring method takes two arguments, start and end, and returns a substring of the result of converting this object to a String, starting from index start and running to, but not including, index end of the String (or through the end of the String if end is
If either argument is
If start is larger than end, they are swapped.
The following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let len be the length of S.
- Let intStart be ?
ToInteger (start). - If end is
undefined , let intEnd be len; else let intEnd be ?ToInteger (end). - Let finalStart be
min (max (intStart, 0), len). - Let finalEnd be
min (max (intEnd, 0), len). - Let from be
min (finalStart, finalEnd). - Let to be
max (finalStart, finalEnd). - Return the String value whose length is to - from, containing code units from S, namely the code units with indices from through to - 1, in ascending order.
The substring function is intentionally generic; it does not require that its
21.1.3.22 String.prototype.toLocaleLowerCase ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the toLocaleLowerCase method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleLowerCase method is used.
This function interprets a String value as a sequence of UTF-16 encoded code points, as described in
This function works exactly the same as toLowerCase except that its result is intended to yield the correct result for the host environment's current locale, rather than a locale-independent result. There will only be a difference in the few cases (such as Turkish) where the rules for that language conflict with the regular Unicode case mappings.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
The toLocaleLowerCase function is intentionally generic; it does not require that its
21.1.3.23 String.prototype.toLocaleUpperCase ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the toLocaleUpperCase method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleUpperCase method is used.
This function interprets a String value as a sequence of UTF-16 encoded code points, as described in
This function works exactly the same as toUpperCase except that its result is intended to yield the correct result for the host environment's current locale, rather than a locale-independent result. There will only be a difference in the few cases (such as Turkish) where the rules for that language conflict with the regular Unicode case mappings.
The meaning of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
The toLocaleUpperCase function is intentionally generic; it does not require that its
21.1.3.24 String.prototype.toLowerCase ( )
This function interprets a String value as a sequence of UTF-16 encoded code points, as described in
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let cpList be a
List containing in order the code points as defined in6.1.4 of S, starting at the first element of S. - Let cuList be a
List where the elements are the result of toLowercase(cplist), according to the Unicode Default Case Conversion algorithm. - Let L be the String value whose elements are the
UTF16Encoding of the code points of cuList. - Return L.
The result must be derived according to the locale-insensitive case mappings in the Unicode Character Database (this explicitly includes not only the UnicodeData.txt file, but also all locale-insensitive mappings in the SpecialCasings.txt file that accompanies it).
The case mapping of some code points may produce multiple code points. In this case the result String may not be the same length as the source String. Because both toUpperCase and toLowerCase have context-sensitive behaviour, the functions are not symmetrical. In other words, s.toUpperCase().toLowerCase() is not necessarily equal to s.toLowerCase().
The toLowerCase function is intentionally generic; it does not require that its
21.1.3.25 String.prototype.toString ( )
When the toString method is called, the following steps are taken:
- Return ?
thisStringValue (this value).
For a String object, the toString method happens to return the same thing as the valueOf method.
21.1.3.26 String.prototype.toUpperCase ( )
This function interprets a String value as a sequence of UTF-16 encoded code points, as described in
This function behaves in exactly the same way as String.prototype.toLowerCase, except that the String is mapped using the toUppercase algorithm of the Unicode Default Case Conversion.
The toUpperCase function is intentionally generic; it does not require that its
21.1.3.27 String.prototype.trim ( )
This function interprets a String value as a sequence of UTF-16 encoded code points, as described in
The following steps are taken:
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let T be the String value that is a copy of S with both leading and trailing white space removed. The definition of white space is the union of
WhiteSpace andLineTerminator . When determining whether a Unicode code point is in Unicode general category “Space_Separator” (“Zs”), code unit sequences are interpreted as UTF-16 encoded code point sequences as specified in6.1.4 . - Return T.
The trim function is intentionally generic; it does not require that its
21.1.3.28 String.prototype.valueOf ( )
When the valueOf method is called, the following steps are taken:
- Return ?
thisStringValue (this value).
21.1.3.29 String.prototype [ @@iterator ] ( )
When the @@iterator method is called it returns an Iterator object (
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Return
CreateStringIterator (S).
The value of the name property of this function is "[Symbol.iterator]".
21.1.4 Properties of String Instances
String instances are String exotic objects and have the internal methods specified for such objects. String instances inherit properties from the String prototype object. String instances also have a [[StringData]] internal slot.
String instances have a length property, and a set of enumerable properties with
21.1.4.1 length
The number of elements in the String value represented by this String object.
Once a String object is initialized, this property is unchanging. It has the attributes { [[Writable]]:
21.1.5 String Iterator Objects
A String Iterator is an object, that represents a specific iteration over some specific String instance object. There is not a named
21.1.5.1 CreateStringIterator ( string )
Several methods of String objects return Iterator objects. The abstract operation CreateStringIterator with argument string is used to create such iterator objects. It performs the following steps:
Assert :Type (string) is String.- Let iterator be
ObjectCreate (%StringIteratorPrototype% , « [[IteratedString]], [[StringIteratorNextIndex]] »). - Set iterator.[[IteratedString]] to string.
- Set iterator.[[StringIteratorNextIndex]] to 0.
- Return iterator.
21.1.5.2 The %StringIteratorPrototype% Object
The %StringIteratorPrototype% object:
- has properties that are inherited by all String Iterator Objects.
- is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%IteratorPrototype% . - has the following properties:
21.1.5.2.1 %StringIteratorPrototype%.next ( )
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have all of the internal slots of a String Iterator Instance (
21.1.5.3 ), throw aTypeError exception. - Let s be O.[[IteratedString]].
- If s is
undefined , returnCreateIterResultObject (undefined ,true ). - Let position be O.[[StringIteratorNextIndex]].
- Let len be the length of s.
- If position ≥ len, then
- Set O.[[IteratedString]] to
undefined . - Return
CreateIterResultObject (undefined ,true ).
- Set O.[[IteratedString]] to
- Let first be the numeric value of the code unit at index position within s.
- If first < 0xD800 or first > 0xDBFF or position+1 = len, let resultString be the String value consisting of the single code unit first.
- Else,
- Let second be the numeric value of the code unit at index position+1 within the String S.
- If second < 0xDC00 or second > 0xDFFF, let resultString be the String value consisting of the single code unit first.
- Else, let resultString be the
string-concatenation of the code unit first and the code unit second.
- Let resultSize be the number of code units in resultString.
- Set O.[[StringIteratorNextIndex]] to position + resultSize.
- Return
CreateIterResultObject (resultString,false ).
21.1.5.2.2 %StringIteratorPrototype% [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "String Iterator".
This property has the attributes { [[Writable]]:
21.1.5.3 Properties of String Iterator Instances
String Iterator instances are ordinary objects that inherit properties from the
| Internal Slot | Description |
|---|---|
| [[IteratedString]] | The String value whose elements are being iterated. |
| [[StringIteratorNextIndex]] |
The |
21.2 RegExp (Regular Expression) Objects
A RegExp object contains a regular expression and the associated flags.
The form and functionality of regular expressions is modelled after the regular expression facility in the Perl 5 programming language.
21.2.1 Patterns
The RegExp
Syntax
Each \u u u \u
21.2.1.1 Static Semantics: Early Errors
- It is a Syntax Error if NcapturingParens ≥ 232-1.
-
It is a Syntax Error if
Pattern contains multipleGroupSpecifier s whose enclosedRegExpIdentifierName s have the same StringValue.
-
It is a Syntax Error if the MV of the first
DecimalDigits is larger than the MV of the secondDecimalDigits .
-
It is a Syntax Error if the enclosing
Pattern does not contain aGroupSpecifier with an enclosedRegExpIdentifierName whose StringValue equals the StringValue of theRegExpIdentifierName of this production'sGroupName .
-
It is a Syntax Error if the CapturingGroupNumber of
DecimalEscape is larger than NcapturingParens (21.2.2.1 ).
-
It is a Syntax Error if IsCharacterClass of the first
ClassAtom istrue or IsCharacterClass of the secondClassAtom istrue . -
It is a Syntax Error if IsCharacterClass of the first
ClassAtom isfalse and IsCharacterClass of the secondClassAtom isfalse and the CharacterValue of the firstClassAtom is larger than the CharacterValue of the secondClassAtom .
-
It is a Syntax Error if IsCharacterClass of
ClassAtomNoDash istrue or IsCharacterClass ofClassAtom istrue . -
It is a Syntax Error if IsCharacterClass of
ClassAtomNoDash isfalse and IsCharacterClass ofClassAtom isfalse and the CharacterValue ofClassAtomNoDash is larger than the CharacterValue ofClassAtom .
-
It is a Syntax Error if SV(
RegExpUnicodeEscapeSequence ) is none of"$", or"_", or theUTF16Encoding of a code point matched by theUnicodeIDStart lexical grammar production.
-
It is a Syntax Error if SV(
RegExpUnicodeEscapeSequence ) is none of"$", or"_", or theUTF16Encoding of either <ZWNJ> or <ZWJ>, or theUTF16Encoding of a Unicode code point that would be matched by theUnicodeIDContinue lexical grammar production.
-
It is a Syntax Error if the
List of Unicode code points that is SourceText ofUnicodePropertyName is not identical to aList of Unicode code points that is a Unicodeproperty name or property alias listed in the “Property name and aliases” column ofTable 51 . -
It is a Syntax Error if the
List of Unicode code points that is SourceText ofUnicodePropertyValue is not identical to aList of Unicode code points that is a value or value alias for the Unicode property or property alias given by SourceText ofUnicodePropertyName listed in the “Property value and aliases” column of the corresponding tablesTable 53 orTable 54 .
-
It is a Syntax Error if the
List of Unicode code points that is SourceText ofLoneUnicodePropertyNameOrValue is not identical to aList of Unicode code points that is a Unicode general category or general category alias listed in the “Property value and aliases” column ofTable 53 , nor a binary property or binary property alias listed in the “Property name and aliases” column ofTable 52 .
21.2.1.2 Static Semantics: CapturingGroupNumber
- Return the MV of
NonZeroDigit .
- Let n be the number of code points in
DecimalDigits . - Return (the MV of
NonZeroDigit × 10n) plus the MV ofDecimalDigits .
The definitions of “the MV of
21.2.1.3 Static Semantics: IsCharacterClass
- Return
false .
- Return
true .
21.2.1.4 Static Semantics: CharacterValue
- Return the code point value of U+002D (HYPHEN-MINUS).
- Let ch be the code point matched by
SourceCharacter . - Return the code point value of ch.
- Return the code point value of U+0008 (BACKSPACE).
- Return the code point value of U+002D (HYPHEN-MINUS).
- Return the code point value according to
Table 50 .
| ControlEscape | Code Point Value | Code Point | Unicode Name | Symbol |
|---|---|---|---|---|
t
|
9 |
U+0009
|
CHARACTER TABULATION | <HT> |
n
|
10 |
U+000A
|
LINE FEED (LF) | <LF> |
v
|
11 |
U+000B
|
LINE TABULATION | <VT> |
f
|
12 |
U+000C
|
FORM FEED (FF) | <FF> |
r
|
13 |
U+000D
|
CARRIAGE RETURN (CR) | <CR> |
- Let ch be the code point matched by
ControlLetter . - Let i be ch's code point value.
- Return the remainder of dividing i by 32.
- Return the code point value of U+0000 (NULL).
\0 represents the <NUL> character and cannot be followed by a decimal digit.
- Return the numeric value of the code unit that is the SV of
HexEscapeSequence .
- Let lead be the CharacterValue of
LeadSurrogate . - Let trail be the CharacterValue of
TrailSurrogate . - Let cp be
UTF16Decode (lead, trail). - Return the code point value of cp.
- Return the CharacterValue of
LeadSurrogate .
- Return the CharacterValue of
TrailSurrogate .
- Return the CharacterValue of
NonSurrogate .
- Return the MV of
Hex4Digits .
- Return the MV of
CodePoint .
- Return the MV of
HexDigits .
- Let ch be the code point matched by
IdentityEscape . - Return the code point value of ch.
21.2.1.5 Static Semantics: SourceText
- Return the
List , in source text order, of Unicode code points in thesource text matched by this production.
21.2.1.6 Static Semantics: StringValue
- Return the String value consisting of the sequence of code units corresponding to
RegExpIdentifierName . In determining the sequence any occurrences of\RegExpUnicodeEscapeSequence are first replaced with the code point represented by theRegExpUnicodeEscapeSequence and then the code points of the entireRegExpIdentifierName are converted to code units byUTF16Encoding each code point.
21.2.2 Pattern Semantics
A regular expression pattern is converted into an internal procedure using the process described below. An implementation is encouraged to use more efficient algorithms than the ones listed below, as long as the results are the same. The internal procedure is used as the value of a RegExp object's [[RegExpMatcher]] internal slot.
A "u". A BMP pattern matches against a String interpreted as consisting of a sequence of 16-bit values that are Unicode code points in the range of the Basic Multilingual Plane. A Unicode pattern matches against a String interpreted as consisting of Unicode code points encoded using UTF-16. In the context of describing the behaviour of a BMP pattern “character” means a single 16-bit Unicode BMP code point. In the context of describing the behaviour of a Unicode pattern “character” means a UTF-16 encoded code point (
The syntax and semantics of
For example, consider a pattern expressed in source text as the single non-BMP character U+1D11E (MUSICAL SYMBOL G CLEF). Interpreted as a Unicode pattern, it would be a single element (character)
Patterns are passed to the RegExp
An implementation may not actually perform such translations to or from UTF-16, but the semantics of this specification requires that the result of pattern matching be as if such translations were performed.
21.2.2.1 Notation
The descriptions below use the following variables:
-
Input is a
List consisting of all of the characters, in order, of the String being matched by the regular expression pattern. Each character is either a code unit or a code point, depending upon the kind of pattern involved. The notation Input[n] means the nth character of Input, where n can range between 0 (inclusive) and InputLength (exclusive). - InputLength is the number of characters in Input.
-
NcapturingParens is the total number of left-capturing parentheses (i.e. the total number of
Atom :: ( GroupSpecifier Disjunction ) (pattern character that is matched by the(terminal of theAtom :: ( GroupSpecifier Disjunction ) -
DotAll is
true if the RegExp object's [[OriginalFlags]] internal slot contains"s"and otherwise isfalse . -
IgnoreCase is
true if the RegExp object's [[OriginalFlags]] internal slot contains"i"and otherwise isfalse . -
Multiline is
true if the RegExp object's [[OriginalFlags]] internal slot contains"m"and otherwise isfalse . -
Unicode is
true if the RegExp object's [[OriginalFlags]] internal slot contains"u"and otherwise isfalse .
Furthermore, the descriptions below use the following internal data structures:
- A CharSet is a mathematical set of characters, either code units or code points depending up the state of the Unicode flag. “All characters” means either all code unit values or all code point values also depending upon the state of Unicode.
-
A State is an ordered pair (endIndex, captures) where endIndex is an
integer and captures is aList of NcapturingParens values. States are used to represent partial match states in the regular expression matching algorithms. The endIndex is one plus the index of the last input character matched so far by the pattern, while captures holds the results of capturing parentheses. The nth element of captures is either aList that represents the value obtained by the nth set of capturing parentheses orundefined if the nth set of capturing parentheses hasn't been reached yet. Due to backtracking, many States may be in use at any time during the matching process. -
A MatchResult is either a State or the special token
failure that indicates that the match failed. -
A Continuation procedure is an internal closure (i.e. an internal procedure with some arguments already bound to values) that takes one State argument and returns a MatchResult result. If an internal closure references variables which are bound in the function that creates the closure, the closure uses the values that these variables had at the time the closure was created. The Continuation attempts to match the remaining portion (specified by the closure's already-bound arguments) of the pattern against Input, starting at the intermediate state given by its State argument. If the match succeeds, the Continuation returns the final State that it reached; if the match fails, the Continuation returns
failure . - A Matcher procedure is an internal closure that takes two arguments — a State and a Continuation — and returns a MatchResult result. A Matcher attempts to match a middle subpattern (specified by the closure's already-bound arguments) of the pattern against Input, starting at the intermediate state given by its State argument. The Continuation argument should be a closure that matches the rest of the pattern. After matching the subpattern of a pattern to obtain a new State, the Matcher then calls Continuation on that new State to test if the rest of the pattern can match as well. If it can, the Matcher returns the State returned by Continuation; if not, the Matcher may try different choices at its choice points, repeatedly calling Continuation until it either succeeds or all possibilities have been exhausted.
-
An AssertionTester procedure is an internal closure that takes a State argument and returns a Boolean result. The assertion tester tests a specific condition (specified by the closure's already-bound arguments) against the current place in Input and returns
true if the condition matched orfalse if not.
21.2.2.2 Pattern
The production
- Evaluate
Disjunction with +1 as its direction argument to obtain a Matcher m. - Return an internal closure that takes two arguments, a String str and an
integer index, and performs the following steps:Assert : index ≤ the length of str.- If Unicode is
true , let Input be aList consisting of the sequence of code points of str interpreted as a UTF-16 encoded (6.1.4 ) Unicode string. Otherwise, let Input be aList consisting of the sequence of code units that are the elements of str. Input will be used throughout the algorithms in21.2.2 . Each element of Input is considered to be a character. - Let InputLength be the number of characters contained in Input. This variable will be used throughout the algorithms in
21.2.2 . - Let listIndex be the index into Input of the character that was obtained from element index of str.
- Let c be a Continuation that always returns its State argument as a successful MatchResult.
- Let cap be a
List of NcapturingParensundefined values, indexed 1 through NcapturingParens. - Let x be the State (listIndex, cap).
- Call m(x, c) and return its result.
A Pattern evaluates (“compiles”) to an internal procedure value.
21.2.2.3 Disjunction
With parameter direction.
The production
- Evaluate
Alternative to obtain a Matcher m. - Return m.
The production
- Evaluate
Alternative with argument direction to obtain a Matcher m1. - Evaluate
Disjunction with argument direction to obtain a Matcher m2. - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Call m1(x, c) and let r be its result.
- If r is not
failure , return r. - Call m2(x, c) and return its result.
The | regular expression operator separates two alternatives. The pattern first tries to match the left | produce
/a|ab/.exec("abc")returns the result "a" and not "ab". Moreover,
/((a)|(ab))((c)|(bc))/.exec("abc")returns the array
["abc", "a", "a", undefined, "bc", undefined, "bc"]and not
["abc", "ab", undefined, "ab", "c", "c", undefined]The order in which the two alternatives are tried is independent of the value of direction.
21.2.2.4 Alternative
With parameter direction.
The production
- Return a Matcher that takes two arguments, a State x and a Continuation c, and returns the result of calling c(x).
The production
- Evaluate
Alternative with argument direction to obtain a Matcher m1. - Evaluate
Term with argument direction to obtain a Matcher m2. - If direction is equal to +1, then
- Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Let d be a Continuation that takes a State argument y and returns the result of calling m2(y, c).
- Call m1(x, d) and return its result.
- Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Else,
Assert : direction is equal to -1.- Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Let d be a Continuation that takes a State argument y and returns the result of calling m1(y, c).
- Call m2(x, d) and return its result.
Consecutive
21.2.2.5 Term
With parameter direction.
The production
- Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Evaluate
Assertion to obtain an AssertionTester t. - Call t(x) and let r be the resulting Boolean value.
- If r is
false , returnfailure . - Call c(x) and return its result.
- Evaluate
The AssertionTester is independent of direction.
The production
- Return the Matcher that is the result of evaluating
Atom with argument direction.
The production
- Evaluate
Atom with argument direction to obtain a Matcher m. - Evaluate
Quantifier to obtain the three results: aninteger min, aninteger (or ∞) max, and Boolean greedy. Assert : If max is finite, then max is not less than min.- Let parenIndex be the number of left-capturing parentheses in the entire regular expression that occur to the left of this
Term . This is the total number ofAtom :: ( GroupSpecifier Disjunction ) Term . - Let parenCount be the number of left-capturing parentheses in
Atom . This is the total number ofAtom :: ( GroupSpecifier Disjunction ) Atom . - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Call
RepeatMatcher (m, min, max, greedy, x, c, parenIndex, parenCount) and return its result.
- Call
21.2.2.5.1 Runtime Semantics: RepeatMatcher ( m, min, max, greedy, x, c, parenIndex, parenCount )
The abstract operation RepeatMatcher takes eight parameters, a Matcher m, an
- If max is zero, return c(x).
- Let d be an internal Continuation closure that takes one State argument y and performs the following steps when evaluated:
- If min is zero and y's endIndex is equal to x's endIndex, return
failure . - If min is zero, let min2 be zero; otherwise let min2 be min-1.
- If max is ∞, let max2 be ∞; otherwise let max2 be max-1.
- Call
RepeatMatcher (m, min2, max2, greedy, y, c, parenIndex, parenCount) and return its result.
- If min is zero and y's endIndex is equal to x's endIndex, return
- Let cap be a copy of x's captures
List . - For each
integer k that satisfies parenIndex < k and k ≤ parenIndex+parenCount, set cap[k] toundefined . - Let e be x's endIndex.
- Let xr be the State (e, cap).
- If min is not zero, return m(xr, d).
- If greedy is
false , then- Call c(x) and let z be its result.
- If z is not
failure , return z. - Call m(xr, d) and return its result.
- Call m(xr, d) and let z be its result.
- If z is not
failure , return z. - Call c(x) and return its result.
An
If the
Compare
/a[a-z]{2,4}/.exec("abcdefghi")which returns "abcde" with
/a[a-z]{2,4}?/.exec("abcdefghi")which returns "abc".
Consider also
/(aa|aabaac|ba|b|c)*/.exec("aabaac")which, by the choice point ordering above, returns the array
["aaba", "ba"]and not any of:
["aabaac", "aabaac"]
["aabaac", "c"]The above ordering of choice points can be used to write a regular expression that calculates the greatest common divisor of two numbers (represented in unary notation). The following example calculates the gcd of 10 and 15:
"aaaaaaaaaa,aaaaaaaaaaaaaaa".replace(/^(a+)\1*,\1+$/, "$1")which returns the gcd in unary notation "aaaaa".
Step 4 of the RepeatMatcher clears
/(z)((a+)?(b+)?(c))*/.exec("zaacbbbcac")which returns the array
["zaacbbbcac", "z", "ac", "a", undefined, "c"]and not
["zaacbbbcac", "z", "ac", "a", "bbb", "c"]because each iteration of the outermost * clears all captured Strings contained in the quantified
Step 1 of the RepeatMatcher's d closure states that, once the minimum number of repetitions has been satisfied, any more expansions of
/(a*)*/.exec("b")or the slightly more complicated:
/(a*)b\1+/.exec("baaaac")which returns the array
["b", ""]21.2.2.6 Assertion
The production
- Return an internal AssertionTester closure that takes a State argument x and performs the following steps when evaluated:
- Let e be x's endIndex.
- If e is zero, return
true . - If Multiline is
false , returnfalse . - If the character Input[e-1] is one of
LineTerminator , returntrue . - Return
false .
Even when the y flag is used with a pattern, ^ always matches only at the beginning of Input, or (if Multiline is
The production
- Return an internal AssertionTester closure that takes a State argument x and performs the following steps when evaluated:
- Let e be x's endIndex.
- If e is equal to InputLength, return
true . - If Multiline is
false , returnfalse . - If the character Input[e] is one of
LineTerminator , returntrue . - Return
false .
The production
- Return an internal AssertionTester closure that takes a State argument x and performs the following steps when evaluated:
- Let e be x's endIndex.
- Call
IsWordChar (e-1) and let a be the Boolean result. - Call
IsWordChar (e) and let b be the Boolean result. - If a is
true and b isfalse , returntrue . - If a is
false and b istrue , returntrue . - Return
false .
The production
- Return an internal AssertionTester closure that takes a State argument x and performs the following steps when evaluated:
- Let e be x's endIndex.
- Call
IsWordChar (e-1) and let a be the Boolean result. - Call
IsWordChar (e) and let b be the Boolean result. - If a is
true and b isfalse , returnfalse . - If a is
false and b istrue , returnfalse . - Return
true .
The production
- Evaluate
Disjunction with +1 as its direction argument to obtain a Matcher m. - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps:
- Let d be a Continuation that always returns its State argument as a successful MatchResult.
- Call m(x, d) and let r be its result.
- If r is
failure , returnfailure . - Let y be r's State.
- Let cap be y's captures
List . - Let xe be x's endIndex.
- Let z be the State (xe, cap).
- Call c(z) and return its result.
The production
- Evaluate
Disjunction with +1 as its direction argument to obtain a Matcher m. - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps:
- Let d be a Continuation that always returns its State argument as a successful MatchResult.
- Call m(x, d) and let r be its result.
- If r is not
failure , returnfailure . - Call c(x) and return its result.
The production
- Evaluate
Disjunction with -1 as its direction argument to obtain a Matcher m. - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps:
- Let d be a Continuation that always returns its State argument as a successful MatchResult.
- Call m(x, d) and let r be its result.
- If r is
failure , returnfailure . - Let y be r's State.
- Let cap be y's captures
List . - Let xe be x's endIndex.
- Let z be the State (xe, cap).
- Call c(z) and return its result.
The production
- Evaluate
Disjunction with -1 as its direction argument to obtain a Matcher m. - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps:
- Let d be a Continuation that always returns its State argument as a successful MatchResult.
- Call m(x, d) and let r be its result.
- If r is not
failure , returnfailure . - Call c(x) and return its result.
21.2.2.6.1 Runtime Semantics: WordCharacters ( )
The abstract operation WordCharacters performs the following steps:
- Let A be a set of characters containing the sixty-three characters:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_ - Let U be an empty set.
- For each character c not in set A where
Canonicalize (c) is in A, add c to U. Assert : Unless Unicode and IgnoreCase are bothtrue , U is empty.- Add the characters in set U to set A.
- Return A.
21.2.2.6.2 Runtime Semantics: IsWordChar ( e )
The abstract operation IsWordChar takes an
- If e is -1 or e is InputLength, return
false . - Let c be the character Input[e].
- Let wordChars be the result of !
WordCharacters (). - If c is in wordChars, return
true . - Return
false .
21.2.2.7 Quantifier
The production
- Evaluate
QuantifierPrefix to obtain the two results: aninteger min and aninteger (or ∞) max. - Return the three results min, max, and
true .
The production
- Evaluate
QuantifierPrefix to obtain the two results: aninteger min and aninteger (or ∞) max. - Return the three results min, max, and
false .
The production
- Return the two results 0 and ∞.
The production
- Return the two results 1 and ∞.
The production
- Return the two results 0 and 1.
The production
- Let i be the MV of
DecimalDigits (see11.8.3 ). - Return the two results i and i.
The production
- Let i be the MV of
DecimalDigits . - Return the two results i and ∞.
The production
- Let i be the MV of the first
DecimalDigits . - Let j be the MV of the second
DecimalDigits . - Return the two results i and j.
21.2.2.8 Atom
With parameter direction.
The production
- Let ch be the character matched by
PatternCharacter . - Let A be a one-element CharSet containing the character ch.
- Call
CharacterSetMatcher (A,false , direction) and return its Matcher result.
The production
- If DotAll is
true , then- Let A be the set of all characters.
- Otherwise, let A be the set of all characters except
LineTerminator . - Call
CharacterSetMatcher (A,false , direction) and return its Matcher result.
The production
- Return the Matcher that is the result of evaluating
AtomEscape with argument direction.
The production
- Evaluate
CharacterClass to obtain a CharSet A and a Boolean invert. - Call
CharacterSetMatcher (A, invert, direction) and return its Matcher result.
The production
- Evaluate
Disjunction with argument direction to obtain a Matcher m. - Let parenIndex be the number of left-capturing parentheses in the entire regular expression that occur to the left of this
Atom . This is the total number ofAtom :: ( GroupSpecifier Disjunction ) Atom . - Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps:
- Let d be an internal Continuation closure that takes one State argument y and performs the following steps:
- Let cap be a copy of y's captures
List . - Let xe be x's endIndex.
- Let ye be y's endIndex.
- If direction is equal to +1, then
- Else,
- Set cap[parenIndex+1] to s.
- Let z be the State (ye, cap).
- Call c(z) and return its result.
- Let cap be a copy of y's captures
- Call m(x, d) and return its result.
- Let d be an internal Continuation closure that takes one State argument y and performs the following steps:
The production
- Return the Matcher that is the result of evaluating
Disjunction with argument direction.
21.2.2.8.1 Runtime Semantics: CharacterSetMatcher ( A, invert, direction )
The abstract operation CharacterSetMatcher takes three arguments, a CharSet A, a Boolean flag invert, and an
- Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps when evaluated:
- Let e be x's endIndex.
- Let f be e + direction.
- If f < 0 or f > InputLength, return
failure . - Let index be
min (e, f). - Let ch be the character Input[index].
- Let cc be
Canonicalize (ch). - If invert is
false , then- If there does not exist a member a of set A such that
Canonicalize (a) is cc, returnfailure .
- If there does not exist a member a of set A such that
- Else,
Assert : invert istrue .- If there exists a member a of set A such that
Canonicalize (a) is cc, returnfailure .
- Let cap be x's captures
List . - Let y be the State (f, cap).
- Call c(y) and return its result.
21.2.2.8.2 Runtime Semantics: Canonicalize ( ch )
The abstract operation Canonicalize takes a character parameter ch and performs the following steps:
- If IgnoreCase is
false , return ch. - If Unicode is
true , then- If the file CaseFolding.txt of the Unicode Character Database provides a simple or common case folding mapping for ch, return the result of applying that mapping to ch.
- Return ch.
- Else,
Assert : ch is a UTF-16 code unit.- Let s be the String value consisting of the single code unit ch.
- Let u be the same result produced as if by performing the algorithm for
String.prototype.toUpperCaseusing s as thethis value. Assert : u is a String value.- If u does not consist of a single code unit, return ch.
- Let cu be u's single code unit element.
- If the numeric value of ch ≥ 128 and the numeric value of cu < 128, return ch.
- Return cu.
Parentheses of the form ( ) serve both to group the components of the \ followed by a nonzero decimal number), referenced in a replace String, or returned as part of an array from the regular expression matching internal procedure. To inhibit the capturing behaviour of parentheses, use the form (?: ) instead.
The form (?= ) specifies a zero-width positive lookahead. In order for it to succeed, the pattern inside (?= form (this unusual behaviour is inherited from Perl). This only matters when the
For example,
/(?=(a+))/.exec("baaabac")matches the empty String immediately after the first b and therefore returns the array:
["", "aaa"]To illustrate the lack of backtracking into the lookahead, consider:
/(?=(a+))a*b\1/.exec("baaabac")This expression returns
["aba", "a"]and not:
["aaaba", "a"]The form (?! ) specifies a zero-width negative lookahead. In order for it to succeed, the pattern inside
/(.*?)a(?!(a+)b\2c)\2(.*)/.exec("baaabaac")looks for an a not immediately followed by some positive number n of a's, a b, another n a's (specified by the first \2) and a c. The second \2 is outside the negative lookahead, so it matches against
["baaabaac", "ba", undefined, "abaac"]In case-insignificant matches when Unicode is "ß" (U+00DF) to "SS". It may however map a code point outside the Basic Latin range to a character within, for example, "ſ" (U+017F) to "s". Such characters are not mapped if Unicode is /[a-z]/i, but they will match /[a-z]/ui.
21.2.2.8.3 Runtime Semantics: UnicodeMatchProperty ( p )
The abstract operation UnicodeMatchProperty takes a parameter p that is a
Assert : p is aList of Unicode code points that is identical to aList of Unicode code points that is a Unicodeproperty name or property alias listed in the “Property name and aliases” column ofTable 51 orTable 52 .- Let c be the canonical
property name of p as given in the “Canonicalproperty name ” column of the corresponding row. - Return the
List of Unicode code points of c.
Implementations must support the Unicode property names and aliases listed in
For example, Script_Extensions (scx (property alias) are valid, but script_extensions or Scx aren't.
The listed properties form a superset of what UTS18 RL1.2 requires.
| Canonical |
|
|---|---|
|
General_Category |
|
Script |
|
Script_Extensions |
| Canonical |
|
|---|---|
ASCII |
ASCII |
|
ASCII_Hex_Digit |
|
Alphabetic |
Any |
Any |
Assigned |
Assigned |
|
Bidi_Control |
|
Bidi_Mirrored |
|
Case_Ignorable |
Cased |
Cased |
|
Changes_When_Casefolded |
|
Changes_When_Casemapped |
|
Changes_When_Lowercased |
|
Changes_When_NFKC_Casefolded |
|
Changes_When_Titlecased |
|
Changes_When_Uppercased |
Dash |
Dash |
|
Default_Ignorable_Code_Point |
|
Deprecated |
|
Diacritic |
Emoji |
Emoji |
Emoji_Component |
Emoji_Component |
Emoji_Modifier |
Emoji_Modifier |
Emoji_Modifier_Base |
Emoji_Modifier_Base |
Emoji_Presentation |
Emoji_Presentation |
|
Extender |
|
Grapheme_Base |
|
Grapheme_Extend |
|
Hex_Digit |
|
IDS_Binary_Operator |
|
IDS_Trinary_Operator |
|
ID_Continue |
|
ID_Start |
|
Ideographic |
|
Join_Control |
|
Logical_Order_Exception |
|
Lowercase |
Math |
Math |
|
Noncharacter_Code_Point |
|
Pattern_Syntax |
|
Pattern_White_Space |
|
Quotation_Mark |
Radical |
Radical |
|
Regional_Indicator |
|
Sentence_Terminal |
|
Soft_Dotted |
|
Terminal_Punctuation |
|
Unified_Ideograph |
|
Uppercase |
|
Variation_Selector |
|
White_Space |
|
XID_Continue |
|
XID_Start |
21.2.2.8.4 Runtime Semantics: UnicodeMatchPropertyValue ( p, v )
The abstract operation UnicodeMatchPropertyValue takes two parameters p and v, each of which is a
Assert : p is aList of Unicode code points that is identical to aList of Unicode code points that is a canonical, unaliased Unicodeproperty name listed in the “Canonicalproperty name ” column ofTable 51 .Assert : v is aList of Unicode code points that is identical to aList of Unicode code points that is a property value or property value alias for Unicode property p listed in the “Property value and aliases” column ofTable 53 orTable 54 .- Let value be the canonical property value of v as given in the “Canonical property value” column of the corresponding row.
- Return the
List of Unicode code points of value.
Implementations must support the Unicode property value names and aliases listed in
For example, Xpeo and Old_Persian are valid Script_Extension values, but xpeo and Old Persian aren't.
This algorithm differs from the matching rules for symbolic values listed in UAX44: case, Is prefix is not supported.
General_Category| Property value and aliases | Canonical property value |
|---|---|
|
Cased_Letter |
|
Close_Punctuation |
|
Connector_Punctuation |
|
Control |
|
Currency_Symbol |
|
Dash_Punctuation |
|
Decimal_Number |
|
Enclosing_Mark |
|
Final_Punctuation |
|
Format |
|
Initial_Punctuation |
|
Letter |
|
Letter_Number |
|
Line_Separator |
|
Lowercase_Letter |
|
Mark |
|
Math_Symbol |
|
Modifier_Letter |
|
Modifier_Symbol |
|
Nonspacing_Mark |
|
Number |
|
Open_Punctuation |
|
Other |
|
Other_Letter |
|
Other_Number |
|
Other_Punctuation |
|
Other_Symbol |
|
Paragraph_Separator |
|
Private_Use |
|
Punctuation |
|
Separator |
|
Space_Separator |
|
Spacing_Mark |
|
Surrogate |
|
Symbol |
|
Titlecase_Letter |
|
Unassigned |
|
Uppercase_Letter |
Script and Script_Extensions| Property value and aliases | Canonical property value |
|---|---|
|
Adlam |
|
Ahom |
|
Anatolian_Hieroglyphs |
|
Arabic |
|
Armenian |
|
Avestan |
|
Balinese |
|
Bamum |
|
Bassa_Vah |
|
Batak |
|
Bengali |
|
Bhaiksuki |
|
Bopomofo |
|
Brahmi |
|
Braille |
|
Buginese |
|
Buhid |
|
Canadian_Aboriginal |
|
Carian |
|
Caucasian_Albanian |
|
Chakma |
|
Cham |
|
Cherokee |
|
Common |
|
Coptic |
|
Cuneiform |
|
Cypriot |
|
Cyrillic |
|
Deseret |
|
Devanagari |
|
Duployan |
|
Egyptian_Hieroglyphs |
|
Elbasan |
|
Ethiopic |
|
Georgian |
|
Glagolitic |
|
Gothic |
|
Grantha |
|
Greek |
|
Gujarati |
|
Gurmukhi |
|
Han |
|
Hangul |
|
Hanunoo |
|
Hatran |
|
Hebrew |
|
Hiragana |
|
Imperial_Aramaic |
|
Inherited |
|
Inscriptional_Pahlavi |
|
Inscriptional_Parthian |
|
Javanese |
|
Kaithi |
|
Kannada |
|
Katakana |
|
Kayah_Li |
|
Kharoshthi |
|
Khmer |
|
Khojki |
|
Khudawadi |
|
Lao |
|
Latin |
|
Lepcha |
|
Limbu |
|
Linear_A |
|
Linear_B |
|
Lisu |
|
Lycian |
|
Lydian |
|
Mahajani |
|
Malayalam |
|
Mandaic |
|
Manichaean |
|
Marchen |
|
Masaram_Gondi |
|
Meetei_Mayek |
|
Mende_Kikakui |
|
Meroitic_Cursive |
|
Meroitic_Hieroglyphs |
|
Miao |
|
Modi |
|
Mongolian |
|
Mro |
|
Multani |
|
Myanmar |
|
Nabataean |
|
New_Tai_Lue |
|
Newa |
|
Nko |
|
Nushu |
|
Ogham |
|
Ol_Chiki |
|
Old_Hungarian |
|
Old_Italic |
|
Old_North_Arabian |
|
Old_Permic |
|
Old_Persian |
|
Old_South_Arabian |
|
Old_Turkic |
|
Oriya |
|
Osage |
|
Osmanya |
|
Pahawh_Hmong |
|
Palmyrene |
|
Pau_Cin_Hau |
|
Phags_Pa |
|
Phoenician |
|
Psalter_Pahlavi |
|
Rejang |
|
Runic |
|
Samaritan |
|
Saurashtra |
|
Sharada |
|
Shavian |
|
Siddham |
|
SignWriting |
|
Sinhala |
|
Sora_Sompeng |
|
Soyombo |
|
Sundanese |
|
Syloti_Nagri |
|
Syriac |
|
Tagalog |
|
Tagbanwa |
|
Tai_Le |
|
Tai_Tham |
|
Tai_Viet |
|
Takri |
|
Tamil |
|
Tangut |
|
Telugu |
|
Thaana |
|
Thai |
|
Tibetan |
|
Tifinagh |
|
Tirhuta |
|
Ugaritic |
|
Vai |
|
Warang_Citi |
|
Yi |
|
Zanabazar_Square |
21.2.2.9 AtomEscape
With parameter direction.
The production
- Evaluate
DecimalEscape to obtain aninteger n. Assert : n ≤ NcapturingParens.- Call
BackreferenceMatcher (n, direction) and return its Matcher result.
The production
- Evaluate
CharacterEscape to obtain a character ch. - Let A be a one-element CharSet containing the character ch.
- Call
CharacterSetMatcher (A,false , direction) and return its Matcher result.
The production
- Evaluate
CharacterClassEscape to obtain a CharSet A. - Call
CharacterSetMatcher (A,false , direction) and return its Matcher result.
An escape sequence of the form \ followed by a nonzero decimal number n matches the result of the nth set of capturing parentheses (
The production
- Search the enclosing
Pattern for an instance of aGroupSpecifier for aRegExpIdentifierName which has a StringValue equal to the StringValue of theRegExpIdentifierName contained inGroupName . Assert : A unique suchGroupSpecifier is found.- Let parenIndex be the number of left-capturing parentheses in the entire regular expression that occur to the left of the located
GroupSpecifier . This is the total number ofAtom :: ( GroupSpecifier Disjunction ) GroupSpecifier . - Call
BackreferenceMatcher (parenIndex, direction) and return its Matcher result.
21.2.2.9.1 Runtime Semantics: BackreferenceMatcher ( n, direction )
The abstract operation BackreferenceMatcher takes two arguments, an
- Return an internal Matcher closure that takes two arguments, a State x and a Continuation c, and performs the following steps:
- Let cap be x's captures
List . - Let s be cap[n].
- If s is
undefined , return c(x). - Let e be x's endIndex.
- Let len be the number of elements in s.
- Let f be e + direction × len.
- If f < 0 or f > InputLength, return
failure . - Let g be
min (e, f). - If there exists an
integer i between 0 (inclusive) and len (exclusive) such thatCanonicalize (s[i]) is not the same character value asCanonicalize (Input[g + i]), returnfailure . - Let y be the State (f, cap).
- Call c(y) and return its result.
- Let cap be x's captures
21.2.2.10 CharacterEscape
The
- Let cv be the CharacterValue of this
CharacterEscape . - Return the character whose character value is cv.
21.2.2.11 DecimalEscape
The
- Return the CapturingGroupNumber of this
DecimalEscape .
If \ is followed by a decimal number n whose first digit is not 0, then the escape sequence is considered to be a backreference. It is an error if n is greater than the total number of left-capturing parentheses in the entire regular expression.
21.2.2.12 CharacterClassEscape
The production
- Return the ten-element set of characters containing the characters
0through9inclusive.
The production
- Return the set of all characters not included in the set returned by
CharacterClassEscape :: d
The production
- Return the set of characters containing the characters that are on the right-hand side of the
WhiteSpace orLineTerminator productions.
The production
- Return the set of all characters not included in the set returned by
CharacterClassEscape :: s
The production
- Return the set of all characters returned by
WordCharacters ().
The production
- Return the set of all characters not included in the set returned by
CharacterClassEscape :: w
The production
The production
The production
- Let ps be SourceText of
UnicodePropertyName . - Let p be !
UnicodeMatchProperty (ps). Assert : p is a Unicodeproperty name or property alias listed in the “Property name and aliases” column ofTable 51 .- Let vs be SourceText of
UnicodePropertyValue . - Let v be !
UnicodeMatchPropertyValue (p, vs). - Return the CharSet containing all Unicode code points whose character database definition includes the property p with value v.
The production
- Let s be SourceText of
LoneUnicodePropertyNameOrValue . - If !
UnicodeMatchPropertyValue ("General_Category", s) is identical to aList of Unicode code points that is the name of a Unicode general category or general category alias listed in the “Property value and aliases” column ofTable 53 , then- Return the CharSet containing all Unicode code points whose character database definition includes the property “General_Category” with value s.
- Let p be !
UnicodeMatchProperty (s). Assert : p is a binary Unicode property or binary property alias listed in the “Property name and aliases” column ofTable 52 .- Return the CharSet containing all Unicode code points whose character database definition includes the property p with value “True”.
21.2.2.13 CharacterClass
The production
- Evaluate
ClassRanges to obtain a CharSet A. - Return the two results A and
false .
The production
- Evaluate
ClassRanges to obtain a CharSet A. - Return the two results A and
true .
21.2.2.14 ClassRanges
The production
- Return the empty CharSet.
The production
- Return the CharSet that is the result of evaluating
NonemptyClassRanges .
21.2.2.15 NonemptyClassRanges
The production
- Return the CharSet that is the result of evaluating
ClassAtom .
The production
- Evaluate
ClassAtom to obtain a CharSet A. - Evaluate
NonemptyClassRangesNoDash to obtain a CharSet B. - Return the union of CharSets A and B.
The production
- Evaluate the first
ClassAtom to obtain a CharSet A. - Evaluate the second
ClassAtom to obtain a CharSet B. - Evaluate
ClassRanges to obtain a CharSet C. - Call
CharacterRange (A, B) and let D be the resulting CharSet. - Return the union of CharSets D and C.
21.2.2.15.1 Runtime Semantics: CharacterRange ( A, B )
The abstract operation CharacterRange takes two CharSet parameters A and B and performs the following steps:
Assert : A and B each contain exactly one character.- Let a be the one character in CharSet A.
- Let b be the one character in CharSet B.
- Let i be the character value of character a.
- Let j be the character value of character b.
Assert : i ≤ j.- Return the set containing all characters numbered i through j, inclusive.
21.2.2.16 NonemptyClassRangesNoDash
The production
- Return the CharSet that is the result of evaluating
ClassAtom .
The production
- Evaluate
ClassAtomNoDash to obtain a CharSet A. - Evaluate
NonemptyClassRangesNoDash to obtain a CharSet B. - Return the union of CharSets A and B.
The production
- Evaluate
ClassAtomNoDash to obtain a CharSet A. - Evaluate
ClassAtom to obtain a CharSet B. - Evaluate
ClassRanges to obtain a CharSet C. - Call
CharacterRange (A, B) and let D be the resulting CharSet. - Return the union of CharSets D and C.
Even if the pattern ignores case, the case of the two ends of a range is significant in determining which characters belong to the range. Thus, for example, the pattern /[E-F]/i matches only the letters E, F, e, and f, while the pattern /[E-f]/i matches all upper and lower-case letters in the Unicode Basic Latin block as well as the symbols [, \, ], ^, _, and `.
A - character can be treated literally or it can denote a range. It is treated literally if it is the first or last character of
21.2.2.17 ClassAtom
The production
- Return the CharSet containing the single character
-U+002D (HYPHEN-MINUS).
The production
- Return the CharSet that is the result of evaluating
ClassAtomNoDash .
21.2.2.18 ClassAtomNoDash
The production
- Return the CharSet containing the character matched by
SourceCharacter .
The production
- Return the CharSet that is the result of evaluating
ClassEscape .
21.2.2.19 ClassEscape
The
- Let cv be the CharacterValue of this
ClassEscape . - Let c be the character whose character value is cv.
- Return the CharSet containing the single character c.
- Return the CharSet that is the result of evaluating
CharacterClassEscape .
A \b, \B, and backreferences. Inside a \b means the backspace character, while \B and backreferences raise errors. Using a backreference inside a
21.2.3 The RegExp Constructor
The RegExp
- is the intrinsic object %RegExp%.
- is the initial value of the
RegExpproperty of theglobal object . - creates and initializes a new RegExp object when called as a function rather than as a
constructor . Thus the function callRegExp(…)is equivalent to the object creation expressionnew RegExp(…)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedRegExpbehaviour must include asupercall to theRegExpconstructor to create and initialize subclass instances with the necessary internal slots.
21.2.3.1 RegExp ( pattern, flags )
The following steps are taken:
- Let patternIsRegExp be ?
IsRegExp (pattern). - If NewTarget is
undefined , then- Let newTarget be the
active function object . - If patternIsRegExp is
true and flags isundefined , then
- Let newTarget be the
- Else, let newTarget be NewTarget.
- If
Type (pattern) is Object and pattern has a [[RegExpMatcher]] internal slot, then- Let P be pattern.[[OriginalSource]].
- If flags is
undefined , let F be pattern.[[OriginalFlags]]. - Else, let F be flags.
- Else if patternIsRegExp is
true , then - Else,
- Let P be pattern.
- Let F be flags.
- Let O be ?
RegExpAlloc (newTarget). - Return ?
RegExpInitialize (O, P, F).
If pattern is supplied using a
21.2.3.2 Abstract Operations for the RegExp Constructor
21.2.3.2.1 Runtime Semantics: RegExpAlloc ( newTarget )
When the abstract operation RegExpAlloc with argument newTarget is called, the following steps are taken:
- Let obj be ?
OrdinaryCreateFromConstructor (newTarget,"%RegExpPrototype%", « [[RegExpMatcher]], [[OriginalSource]], [[OriginalFlags]] »). - Perform !
DefinePropertyOrThrow (obj,"lastIndex", PropertyDescriptor { [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }). - Return obj.
21.2.3.2.2 Runtime Semantics: RegExpInitialize ( obj, pattern, flags )
When the abstract operation RegExpInitialize with arguments obj, pattern, and flags is called, the following steps are taken:
- If pattern is
undefined , let P be the empty String. - Else, let P be ?
ToString (pattern). - If flags is
undefined , let F be the empty String. - Else, let F be ?
ToString (flags). - If F contains any code unit other than
"g","i","m","s","u", or"y"or if it contains the same code unit more than once, throw aSyntaxError exception. - If F contains
"u", let BMP befalse ; else let BMP betrue . - If BMP is
true , then- Parse P using the grammars in
21.2.1 and interpreting each of its 16-bit elements as a Unicode BMP code point. UTF-16 decoding is not applied to the elements. Thegoal symbol for the parse isPattern . If the result of parsing contains a[~U, ~N] GroupName , reparse with thegoal symbol Pattern and use this result instead. Throw a[~U, +N] SyntaxError exception if P did not conform to the grammar, if any elements of P were not matched by the parse, or if any Early Error conditions exist. - Let patternCharacters be a
List whose elements are the code unit elements of P.
- Parse P using the grammars in
- Else,
- Parse P using the grammars in
21.2.1 and interpreting P as UTF-16 encoded Unicode code points (6.1.4 ). Thegoal symbol for the parse isPattern . Throw a[+U, +N] SyntaxError exception if P did not conform to the grammar, if any elements of P were not matched by the parse, or if any Early Error conditions exist. - Let patternCharacters be a
List whose elements are the code points resulting from applying UTF-16 decoding to P's sequence of elements.
- Parse P using the grammars in
- Set obj.[[OriginalSource]] to P.
- Set obj.[[OriginalFlags]] to F.
- Set obj.[[RegExpMatcher]] to the internal procedure that evaluates the above parse of P by applying the semantics provided in
21.2.2 using patternCharacters as the pattern'sList ofSourceCharacter values and F as the flag parameters. - Perform ?
Set (obj,"lastIndex", 0,true ). - Return obj.
21.2.3.2.3 Runtime Semantics: RegExpCreate ( P, F )
When the abstract operation RegExpCreate with arguments P and F is called, the following steps are taken:
- Let obj be ?
RegExpAlloc (%RegExp% ). - Return ?
RegExpInitialize (obj, P, F).
21.2.3.2.4 Runtime Semantics: EscapeRegExpPattern ( P, F )
When the abstract operation EscapeRegExpPattern with arguments P and F is called, the following occurs:
- Let S be a String in the form of a
Pattern ([~U] Pattern if F contains[+U] "u") equivalent to P interpreted as UTF-16 encoded Unicode code points (6.1.4 ), in which certain code points are escaped as described below. S may or may not be identical to P; however, the internal procedure that would result from evaluating S as aPattern ([~U] Pattern if F contains[+U] "u") must behave identically to the internal procedure given by the constructed object's [[RegExpMatcher]] internal slot. Multiple calls to this abstract operation using the same values for P and F must produce identical results. - The code points
/or anyLineTerminator occurring in the pattern shall be escaped in S as necessary to ensure that thestring-concatenation of"/", S,"/", and F can be parsed (in an appropriate lexical context) as aRegularExpressionLiteral that behaves identically to the constructed regular expression. For example, if P is"/", then S could be"\/"or"\u002F", among other possibilities, but not"/", because///followed by F would be parsed as aSingleLineComment rather than aRegularExpressionLiteral . If P is the empty String, this specification can be met by letting S be"(?:)". - Return S.
21.2.4 Properties of the RegExp Constructor
The RegExp
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
21.2.4.1 RegExp.prototype
The initial value of RegExp.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
21.2.4.2 get RegExp [ @@species ]
RegExp[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
RegExp prototype methods normally use their this object's
21.2.5 Properties of the RegExp Prototype Object
The RegExp prototype object:
- is the intrinsic object %RegExpPrototype%.
- is an ordinary object.
- is not a RegExp instance and does not have a [[RegExpMatcher]] internal slot or any of the other internal slots of RegExp instance objects.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
The RegExp prototype object does not have a valueOf property of its own; however, it inherits the valueOf property from the Object prototype object.
21.2.5.1 RegExp.prototype.constructor
The initial value of RegExp.prototype.constructor is the intrinsic object
21.2.5.2 RegExp.prototype.exec ( string )
Performs a regular expression match of string against the regular expression and returns an Array object containing the results of the match, or
The String
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have a [[RegExpMatcher]] internal slot, throw a
TypeError exception. - Let S be ?
ToString (string). - Return ?
RegExpBuiltinExec (R, S).
21.2.5.2.1 Runtime Semantics: RegExpExec ( R, S )
The abstract operation RegExpExec with arguments R and S performs the following steps:
Assert :Type (R) is Object.Assert :Type (S) is String.- Let exec be ?
Get (R,"exec"). - If
IsCallable (exec) istrue , then - If R does not have a [[RegExpMatcher]] internal slot, throw a
TypeError exception. - Return ?
RegExpBuiltinExec (R, S).
If a callable exec property is not found this algorithm falls back to attempting to use the built-in RegExp matching algorithm. This provides compatible behaviour for code written for prior editions where most built-in algorithms that use regular expressions did not perform a dynamic property lookup of exec.
21.2.5.2.2 Runtime Semantics: RegExpBuiltinExec ( R, S )
The abstract operation RegExpBuiltinExec with arguments R and S performs the following steps:
Assert : R is an initialized RegExp instance.Assert :Type (S) is String.- Let length be the number of code units in S.
- Let lastIndex be ?
ToLength (?Get (R,"lastIndex")). - Let flags be R.[[OriginalFlags]].
- If flags contains
"g", let global betrue , else let global befalse . - If flags contains
"y", let sticky betrue , else let sticky befalse . - If global is
false and sticky isfalse , set lastIndex to 0. - Let matcher be R.[[RegExpMatcher]].
- If flags contains
"u", let fullUnicode betrue , else let fullUnicode befalse . - Let matchSucceeded be
false . - Repeat, while matchSucceeded is
false - If lastIndex > length, then
- If global is
true or sticky istrue , then- Perform ?
Set (R,"lastIndex", 0,true ).
- Perform ?
- Return
null .
- If global is
- Let r be matcher(S, lastIndex).
- If r is
failure , then- If sticky is
true , then- Perform ?
Set (R,"lastIndex", 0,true ). - Return
null .
- Perform ?
- Set lastIndex to
AdvanceStringIndex (S, lastIndex, fullUnicode).
- If sticky is
- Else,
Assert : r is a State.- Set matchSucceeded to
true .
- If lastIndex > length, then
- Let e be r's endIndex value.
- If fullUnicode is
true , then- e is an index into the Input character list, derived from S, matched by matcher. Let eUTF be the smallest index into S that corresponds to the character at element e of Input. If e is greater than or equal to the number of elements in Input, then eUTF is the number of code units in S.
- Set e to eUTF.
- If global is
true or sticky istrue , then- Perform ?
Set (R,"lastIndex", e,true ).
- Perform ?
- Let n be the number of elements in r's captures
List . (This is the same value as21.2.2.1 's NcapturingParens.) Assert : n < 232-1.- Let A be !
ArrayCreate (n + 1). Assert : The value of A's"length"property is n + 1.- Perform !
CreateDataProperty (A,"index", lastIndex). - Perform !
CreateDataProperty (A,"input", S). - Let matchedSubstr be the matched substring (i.e. the portion of S between offset lastIndex inclusive and offset e exclusive).
- Perform !
CreateDataProperty (A,"0", matchedSubstr). - If R contains any
GroupName , then- Let groups be
ObjectCreate (null ).
- Let groups be
- Else,
- Let groups be
undefined .
- Let groups be
- Perform !
CreateDataProperty (A,"groups", groups). - For each
integer i such that i > 0 and i ≤ n, do- Let captureI be ith element of r's captures
List . - If captureI is
undefined , let capturedValue beundefined . - Else if fullUnicode is
true , thenAssert : captureI is aList of code points.- Let capturedValue be the String value whose code units are the
UTF16Encoding of the code points of captureI.
- Else fullUnicode is
false , - Perform !
CreateDataProperty (A, !ToString (i), capturedValue). - If the ith capture of R was defined with a
GroupName , then- Let s be the StringValue of the corresponding
RegExpIdentifierName . - Perform !
CreateDataProperty (groups, s, capturedValue).
- Let s be the StringValue of the corresponding
- Let captureI be ith element of r's captures
- Return A.
21.2.5.2.3 AdvanceStringIndex ( S, index, unicode )
The abstract operation AdvanceStringIndex with arguments S, index, and unicode performs the following steps:
Assert :Type (S) is String.Assert : index is aninteger such that 0≤index≤253-1.Assert :Type (unicode) is Boolean.- If unicode is
false , return index+1. - Let length be the number of code units in S.
- If index+1 ≥ length, return index+1.
- Let first be the numeric value of the code unit at index index within S.
- If first < 0xD800 or first > 0xDBFF, return index+1.
- Let second be the numeric value of the code unit at index index+1 within S.
- If second < 0xDC00 or second > 0xDFFF, return index+1.
- Return index+2.
21.2.5.3 get RegExp.prototype.dotAll
RegExp.prototype.dotAll is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalFlags]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , returnundefined . - Otherwise, throw a
TypeError exception.
- If
- Let flags be R.[[OriginalFlags]].
- If flags contains the code unit 0x0073 (LATIN SMALL LETTER S), return
true . - Return
false .
21.2.5.4 get RegExp.prototype.flags
RegExp.prototype.flags is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - Let result be the empty String.
- Let global be
ToBoolean (?Get (R,"global")). - If global is
true , append the code unit 0x0067 (LATIN SMALL LETTER G) as the last code unit of result. - Let ignoreCase be
ToBoolean (?Get (R,"ignoreCase")). - If ignoreCase is
true , append the code unit 0x0069 (LATIN SMALL LETTER I) as the last code unit of result. - Let multiline be
ToBoolean (?Get (R,"multiline")). - If multiline is
true , append the code unit 0x006D (LATIN SMALL LETTER M) as the last code unit of result. - Let dotAll be
ToBoolean (?Get (R,"dotAll")). - If dotAll is
true , append the code unit 0x0073 (LATIN SMALL LETTER S) as the last code unit of result. - Let unicode be
ToBoolean (?Get (R,"unicode")). - If unicode is
true , append the code unit 0x0075 (LATIN SMALL LETTER U) as the last code unit of result. - Let sticky be
ToBoolean (?Get (R,"sticky")). - If sticky is
true , append the code unit 0x0079 (LATIN SMALL LETTER Y) as the last code unit of result. - Return result.
21.2.5.5 get RegExp.prototype.global
RegExp.prototype.global is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalFlags]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , returnundefined . - Otherwise, throw a
TypeError exception.
- If
- Let flags be R.[[OriginalFlags]].
- If flags contains the code unit 0x0067 (LATIN SMALL LETTER G), return
true . - Return
false .
21.2.5.6 get RegExp.prototype.ignoreCase
RegExp.prototype.ignoreCase is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalFlags]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , returnundefined . - Otherwise, throw a
TypeError exception.
- If
- Let flags be R.[[OriginalFlags]].
- If flags contains the code unit 0x0069 (LATIN SMALL LETTER I), return
true . - Return
false .
21.2.5.7 RegExp.prototype [ @@match ] ( string )
When the @@match method is called with argument string, the following steps are taken:
- Let rx be the
this value. - If
Type (rx) is not Object, throw aTypeError exception. - Let S be ?
ToString (string). - Let global be
ToBoolean (?Get (rx,"global")). - If global is
false , then- Return ?
RegExpExec (rx, S).
- Return ?
- Else global is
true ,- Let fullUnicode be
ToBoolean (?Get (rx,"unicode")). - Perform ?
Set (rx,"lastIndex", 0,true ). - Let A be !
ArrayCreate (0). - Let n be 0.
- Repeat,
- Let result be ?
RegExpExec (rx, S). - If result is
null , then- If n=0, return
null . - Return A.
- If n=0, return
- Else result is not
null ,- Let matchStr be ?
ToString (?Get (result,"0")). - Let status be
CreateDataProperty (A, !ToString (n), matchStr). Assert : status istrue .- If matchStr is the empty String, then
- Let thisIndex be ?
ToLength (?Get (rx,"lastIndex")). - Let nextIndex be
AdvanceStringIndex (S, thisIndex, fullUnicode). - Perform ?
Set (rx,"lastIndex", nextIndex,true ).
- Let thisIndex be ?
- Increment n.
- Let matchStr be ?
- Let result be ?
- Let fullUnicode be
The value of the name property of this function is "[Symbol.match]".
The @@match property is used by the
21.2.5.8 get RegExp.prototype.multiline
RegExp.prototype.multiline is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalFlags]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , returnundefined . - Otherwise, throw a
TypeError exception.
- If
- Let flags be R.[[OriginalFlags]].
- If flags contains the code unit 0x006D (LATIN SMALL LETTER M), return
true . - Return
false .
21.2.5.9 RegExp.prototype [ @@replace ] ( string, replaceValue )
When the @@replace method is called with arguments string and replaceValue, the following steps are taken:
- Let rx be the
this value. - If
Type (rx) is not Object, throw aTypeError exception. - Let S be ?
ToString (string). - Let lengthS be the number of code unit elements in S.
- Let functionalReplace be
IsCallable (replaceValue). - If functionalReplace is
false , then- Let replaceValue be ?
ToString (replaceValue).
- Let replaceValue be ?
- Let global be
ToBoolean (?Get (rx,"global")). - If global is
true , then - Let results be a new empty
List . - Let done be
false . - Repeat, while done is
false - Let result be ?
RegExpExec (rx, S). - If result is
null , set done totrue . - Else result is not
null ,- Append result to the end of results.
- If global is
false , set done totrue . - Else,
- Let result be ?
- Let accumulatedResult be the empty String value.
- Let nextSourcePosition be 0.
- For each result in results, do
- Let nCaptures be ?
ToLength (?Get (result,"length")). - Let nCaptures be
max (nCaptures - 1, 0). - Let matched be ?
ToString (?Get (result,"0")). - Let matchLength be the number of code units in matched.
- Let position be ?
ToInteger (?Get (result,"index")). - Let position be
max (min (position, lengthS), 0). - Let n be 1.
- Let captures be a new empty
List . - Repeat, while n ≤ nCaptures
- Let namedCaptures be ?
Get (result,"groups"). - If functionalReplace is
true , then- Let replacerArgs be « matched ».
- Append in list order the elements of captures to the end of the
List replacerArgs. - Append position and S to replacerArgs.
- If namedCaptures is not
undefined , then- Append namedCaptures as the last element of replacerArgs.
- Let replValue be ?
Call (replaceValue,undefined , replacerArgs). - Let replacement be ?
ToString (replValue).
- Else,
- Let replacement be
GetSubstitution (matched, S, position, captures, namedCaptures, replaceValue).
- Let replacement be
- If position ≥ nextSourcePosition, then
- NOTE: position should not normally move backwards. If it does, it is an indication of an ill-behaving RegExp subclass or use of an access triggered side-effect to change the global flag or other characteristics of rx. In such cases, the corresponding substitution is ignored.
- Let accumulatedResult be the
string-concatenation of the current value of accumulatedResult, the substring of S consisting of the code units from nextSourcePosition (inclusive) up to position (exclusive), and replacement. - Let nextSourcePosition be position + matchLength.
- Let nCaptures be ?
- If nextSourcePosition ≥ lengthS, return accumulatedResult.
- Return the
string-concatenation of accumulatedResult and the substring of S consisting of the code units from nextSourcePosition (inclusive) up through the final code unit of S (inclusive).
The value of the name property of this function is "[Symbol.replace]".
21.2.5.10 RegExp.prototype [ @@search ] ( string )
When the @@search method is called with argument string, the following steps are taken:
- Let rx be the
this value. - If
Type (rx) is not Object, throw aTypeError exception. - Let S be ?
ToString (string). - Let previousLastIndex be ?
Get (rx,"lastIndex"). - If
SameValue (previousLastIndex, 0) isfalse , then- Perform ?
Set (rx,"lastIndex", 0,true ).
- Perform ?
- Let result be ?
RegExpExec (rx, S). - Let currentLastIndex be ?
Get (rx,"lastIndex"). - If
SameValue (currentLastIndex, previousLastIndex) isfalse , then- Perform ?
Set (rx,"lastIndex", previousLastIndex,true ).
- Perform ?
- If result is
null , return -1. - Return ?
Get (result,"index").
The value of the name property of this function is "[Symbol.search]".
The lastIndex and global properties of this RegExp object are ignored when performing the search. The lastIndex property is left unchanged.
21.2.5.11 get RegExp.prototype.source
RegExp.prototype.source is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalSource]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , return"(?:)". - Otherwise, throw a
TypeError exception.
- If
Assert : R has an [[OriginalFlags]] internal slot.- Let src be R.[[OriginalSource]].
- Let flags be R.[[OriginalFlags]].
- Return
EscapeRegExpPattern (src, flags).
21.2.5.12 RegExp.prototype [ @@split ] ( string, limit )
Returns an Array object into which substrings of the result of converting string to a String have been stored. The substrings are determined by searching from left to right for matches of the
The /a*?/[Symbol.split]("ab") evaluates to the array ["a", "b"], while /a*/[Symbol.split]("ab") evaluates to the array ["","b"].)
If the string is (or converts to) the empty String, the result depends on whether the regular expression can match the empty String. If it can, the result array contains no elements. Otherwise, the result array contains one element, which is the empty String.
If the regular expression contains capturing parentheses, then each time separator is matched the results (including any
/<(\/)?([^<>]+)>/[Symbol.split]("A<B>bold</B>and<CODE>coded</CODE>")evaluates to the array
["A", undefined, "B", "bold", "/", "B", "and", undefined, "CODE", "coded", "/", "CODE", ""]If limit is not
When the @@split method is called, the following steps are taken:
- Let rx be the
this value. - If
Type (rx) is not Object, throw aTypeError exception. - Let S be ?
ToString (string). - Let C be ?
SpeciesConstructor (rx,%RegExp% ). - Let flags be ?
ToString (?Get (rx,"flags")). - If flags contains
"u", let unicodeMatching betrue . - Else, let unicodeMatching be
false . - If flags contains
"y", let newFlags be flags. - Else, let newFlags be the
string-concatenation of flags and"y". - Let splitter be ?
Construct (C, « rx, newFlags »). - Let A be !
ArrayCreate (0). - Let lengthA be 0.
- If limit is
undefined , let lim be 232-1; else let lim be ?ToUint32 (limit). - Let size be the length of S.
- Let p be 0.
- If lim = 0, return A.
- If size = 0, then
- Let z be ?
RegExpExec (splitter, S). - If z is not
null , return A. - Perform !
CreateDataProperty (A,"0", S). - Return A.
- Let z be ?
- Let q be p.
- Repeat, while q < size
- Perform ?
Set (splitter,"lastIndex", q,true ). - Let z be ?
RegExpExec (splitter, S). - If z is
null , let q beAdvanceStringIndex (S, q, unicodeMatching). - Else z is not
null ,- Let e be ?
ToLength (?Get (splitter,"lastIndex")). - Let e be
min (e, size). - If e = p, let q be
AdvanceStringIndex (S, q, unicodeMatching). - Else e ≠ p,
- Let T be the String value equal to the substring of S consisting of the elements at indices p (inclusive) through q (exclusive).
- Perform !
CreateDataProperty (A, !ToString (lengthA), T). - Let lengthA be lengthA + 1.
- If lengthA = lim, return A.
- Let p be e.
- Let numberOfCaptures be ?
ToLength (?Get (z,"length")). - Let numberOfCaptures be
max (numberOfCaptures-1, 0). - Let i be 1.
- Repeat, while i ≤ numberOfCaptures,
- Let nextCapture be ?
Get (z, !ToString (i)). - Perform !
CreateDataProperty (A, !ToString (lengthA), nextCapture). - Let i be i + 1.
- Let lengthA be lengthA + 1.
- If lengthA = lim, return A.
- Let nextCapture be ?
- Let q be p.
- Let e be ?
- Perform ?
- Let T be the String value equal to the substring of S consisting of the elements at indices p (inclusive) through size (exclusive).
- Perform !
CreateDataProperty (A, !ToString (lengthA), T). - Return A.
The value of the name property of this function is "[Symbol.split]".
The @@split method ignores the value of the global and sticky properties of this RegExp object.
21.2.5.13 get RegExp.prototype.sticky
RegExp.prototype.sticky is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalFlags]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , returnundefined . - Otherwise, throw a
TypeError exception.
- If
- Let flags be R.[[OriginalFlags]].
- If flags contains the code unit 0x0079 (LATIN SMALL LETTER Y), return
true . - Return
false .
21.2.5.14 RegExp.prototype.test ( S )
The following steps are taken:
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - Let string be ?
ToString (S). - Let match be ?
RegExpExec (R, string). - If match is not
null , returntrue ; else returnfalse .
21.2.5.15 RegExp.prototype.toString ( )
The returned String has the form of a
21.2.5.16 get RegExp.prototype.unicode
RegExp.prototype.unicode is an
- Let R be the
this value. - If
Type (R) is not Object, throw aTypeError exception. - If R does not have an [[OriginalFlags]] internal slot, then
- If
SameValue (R,%RegExpPrototype% ) istrue , returnundefined . - Otherwise, throw a
TypeError exception.
- If
- Let flags be R.[[OriginalFlags]].
- If flags contains the code unit 0x0075 (LATIN SMALL LETTER U), return
true . - Return
false .
21.2.6 Properties of RegExp Instances
RegExp instances are ordinary objects that inherit properties from the RegExp prototype object. RegExp instances have internal slots [[RegExpMatcher]], [[OriginalSource]], and [[OriginalFlags]]. The value of the [[RegExpMatcher]] internal slot is an implementation-dependent representation of the
Prior to ECMAScript 2015, RegExp instances were specified as having the own data properties source, global, ignoreCase, and multiline. Those properties are now specified as accessor properties of RegExp.prototype.
RegExp instances also have the following property:
21.2.6.1 lastIndex
The value of the lastIndex property specifies the String index at which to start the next match. It is coerced to an
22 Indexed Collections
22.1 Array Objects
Array objects are exotic objects that give special treatment to a certain class of property names. See
22.1.1 The Array Constructor
The Array
- is the intrinsic object %Array%.
- is the initial value of the
Arrayproperty of theglobal object . - creates and initializes a new Array
exotic object when called as aconstructor . - also creates and initializes a new Array object when called as a function rather than as a
constructor . Thus the function callArray(…)is equivalent to the object creation expressionnew Array(…)with the same arguments. - is a single function whose behaviour is overloaded based upon the number and types of its arguments.
- is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the exoticArraybehaviour must include asupercall to theArrayconstructor to initialize subclass instances that are Array exotic objects. However, most of theArray.prototypemethods are generic methods that are not dependent upon theirthisvalue being an Arrayexotic object . - has a
lengthproperty whose value is 1.
22.1.1.1 Array ( )
This description applies if and only if the Array
- Let numberOfArgs be the number of arguments passed to this function call.
Assert : numberOfArgs = 0.- If NewTarget is
undefined , let newTarget be theactive function object , else let newTarget be NewTarget. - Let proto be ?
GetPrototypeFromConstructor (newTarget,"%ArrayPrototype%"). - Return !
ArrayCreate (0, proto).
22.1.1.2 Array ( len )
This description applies if and only if the Array
- Let numberOfArgs be the number of arguments passed to this function call.
Assert : numberOfArgs = 1.- If NewTarget is
undefined , let newTarget be theactive function object , else let newTarget be NewTarget. - Let proto be ?
GetPrototypeFromConstructor (newTarget,"%ArrayPrototype%"). - Let array be !
ArrayCreate (0, proto). - If
Type (len) is not Number, then- Let defineStatus be
CreateDataProperty (array,"0", len). Assert : defineStatus istrue .- Let intLen be 1.
- Let defineStatus be
- Else,
- Let intLen be
ToUint32 (len). - If intLen ≠ len, throw a
RangeError exception.
- Let intLen be
- Perform !
Set (array,"length", intLen,true ). - Return array.
22.1.1.3 Array ( ...items )
This description applies if and only if the Array
When the Array function is called, the following steps are taken:
- Let numberOfArgs be the number of arguments passed to this function call.
Assert : numberOfArgs ≥ 2.- If NewTarget is
undefined , let newTarget be theactive function object , else let newTarget be NewTarget. - Let proto be ?
GetPrototypeFromConstructor (newTarget,"%ArrayPrototype%"). - Let array be ?
ArrayCreate (numberOfArgs, proto). - Let k be 0.
- Let items be a zero-origined
List containing the argument items in order. - Repeat, while k < numberOfArgs
- Let Pk be !
ToString (k). - Let itemK be items[k].
- Let defineStatus be
CreateDataProperty (array, Pk, itemK). Assert : defineStatus istrue .- Increase k by 1.
- Let Pk be !
Assert : The value of array'slengthproperty is numberOfArgs.- Return array.
22.1.2 Properties of the Array Constructor
The Array
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
22.1.2.1 Array.from ( items [ , mapfn [ , thisArg ] ] )
When the from method is called with argument items and optional arguments mapfn and thisArg, the following steps are taken:
- Let C be the
this value. - If mapfn is
undefined , let mapping befalse . - Else,
- If
IsCallable (mapfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let mapping be
true .
- If
- Let usingIterator be ?
GetMethod (items, @@iterator). - If usingIterator is not
undefined , then- If
IsConstructor (C) istrue , then- Let A be ?
Construct (C).
- Let A be ?
- Else,
- Let A be !
ArrayCreate (0).
- Let A be !
- Let iteratorRecord be ?
GetIterator (items,sync , usingIterator). - Let k be 0.
- Repeat,
- If k ≥ 253-1, then
- Let error be
ThrowCompletion (a newly createdTypeError object). - Return ?
IteratorClose (iteratorRecord, error).
- Let error be
- Let Pk be !
ToString (k). - Let next be ?
IteratorStep (iteratorRecord). - If next is
false , then- Perform ?
Set (A,"length", k,true ). - Return A.
- Perform ?
- Let nextValue be ?
IteratorValue (next). - If mapping is
true , then- Let mappedValue be
Call (mapfn, T, « nextValue, k »). - If mappedValue is an
abrupt completion , return ?IteratorClose (iteratorRecord, mappedValue). - Let mappedValue be mappedValue.[[Value]].
- Let mappedValue be
- Else, let mappedValue be nextValue.
- Let defineStatus be
CreateDataPropertyOrThrow (A, Pk, mappedValue). - If defineStatus is an
abrupt completion , return ?IteratorClose (iteratorRecord, defineStatus). - Increase k by 1.
- If k ≥ 253-1, then
- If
- NOTE: items is not an Iterable so assume it is an
array-like object . - Let arrayLike be !
ToObject (items). - Let len be ?
ToLength (?Get (arrayLike,"length")). - If
IsConstructor (C) istrue , then- Let A be ?
Construct (C, « len »).
- Let A be ?
- Else,
- Let A be ?
ArrayCreate (len).
- Let A be ?
- Let k be 0.
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kValue be ?
Get (arrayLike, Pk). - If mapping is
true , then- Let mappedValue be ?
Call (mapfn, T, « kValue, k »).
- Let mappedValue be ?
- Else, let mappedValue be kValue.
- Perform ?
CreateDataPropertyOrThrow (A, Pk, mappedValue). - Increase k by 1.
- Let Pk be !
- Perform ?
Set (A,"length", len,true ). - Return A.
The from function is an intentionally generic factory method; it does not require that its
22.1.2.2 Array.isArray ( arg )
The isArray function takes one argument arg, and performs the following steps:
- Return ?
IsArray (arg).
22.1.2.3 Array.of ( ...items )
When the of method is called with any number of arguments, the following steps are taken:
- Let len be the actual number of arguments passed to this function.
- Let items be the
List of arguments passed to this function. - Let C be the
this value. - If
IsConstructor (C) istrue , then- Let A be ?
Construct (C, « len »).
- Let A be ?
- Else,
- Let A be ?
ArrayCreate (len).
- Let A be ?
- Let k be 0.
- Repeat, while k < len
- Let kValue be items[k].
- Let Pk be !
ToString (k). - Perform ?
CreateDataPropertyOrThrow (A, Pk, kValue). - Increase k by 1.
- Perform ?
Set (A,"length", len,true ). - Return A.
The items argument is assumed to be a well-formed rest argument value.
The of function is an intentionally generic factory method; it does not require that its
22.1.2.4 Array.prototype
The value of Array.prototype is
This property has the attributes { [[Writable]]:
22.1.2.5 get Array [ @@species ]
Array[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
Array prototype methods normally use their this object's
22.1.3 Properties of the Array Prototype Object
The Array prototype object:
- is the intrinsic object %ArrayPrototype%.
- is an Array
exotic object and has the internal methods specified for such objects. - has a
lengthproperty whose initial value is 0 and whose attributes are { [[Writable]]:true , [[Enumerable]]:false , [[Configurable]]:false }. - has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% .
The Array prototype object is specified to be an Array
22.1.3.1 Array.prototype.concat ( ...arguments )
When the concat method is called with zero or more arguments, it returns an array containing the array elements of the object followed by the array elements of each argument in order.
The following steps are taken:
- Let O be ?
ToObject (this value). - Let A be ?
ArraySpeciesCreate (O, 0). - Let n be 0.
- Let items be a
List whose first element is O and whose subsequent elements are, in left to right order, the arguments that were passed to this function invocation. - Repeat, while items is not empty
- Remove the first element from items and let E be the value of the element.
- Let spreadable be ?
IsConcatSpreadable (E). - If spreadable is
true , then- Let k be 0.
- Let len be ?
ToLength (?Get (E,"length")). - If n + len > 253-1, throw a
TypeError exception. - Repeat, while k < len
- Let P be !
ToString (k). - Let exists be ?
HasProperty (E, P). - If exists is
true , then- Let subElement be ?
Get (E, P). - Perform ?
CreateDataPropertyOrThrow (A, !ToString (n), subElement).
- Let subElement be ?
- Increase n by 1.
- Increase k by 1.
- Let P be !
- Else E is added as a single item rather than spread,
- If n≥253-1, throw a
TypeError exception. - Perform ?
CreateDataPropertyOrThrow (A, !ToString (n), E). - Increase n by 1.
- If n≥253-1, throw a
- Perform ?
Set (A,"length", n,true ). - Return A.
The length property of the concat method is 1.
The explicit setting of the length property in step 6 is necessary to ensure that its value is correct in situations where the trailing elements of the result Array are not present.
The concat function is intentionally generic; it does not require that its
22.1.3.1.1 Runtime Semantics: IsConcatSpreadable ( O )
The abstract operation IsConcatSpreadable with argument O performs the following steps:
22.1.3.2 Array.prototype.constructor
The initial value of Array.prototype.constructor is the intrinsic object
22.1.3.3 Array.prototype.copyWithin ( target, start [ , end ] )
The copyWithin method takes up to three arguments target, start and end.
The end argument is optional with the length of the
The following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let relativeTarget be ?
ToInteger (target). - If relativeTarget < 0, let to be
max ((len + relativeTarget), 0); else let to bemin (relativeTarget, len). - Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let from be
max ((len + relativeStart), 0); else let from bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Let count be
min (final-from, len-to). - If from<to and to<from+count, then
- Let direction be -1.
- Let from be from + count - 1.
- Let to be to + count - 1.
- Else,
- Let direction be 1.
- Repeat, while count > 0
- Let fromKey be !
ToString (from). - Let toKey be !
ToString (to). - Let fromPresent be ?
HasProperty (O, fromKey). - If fromPresent is
true , then - Else fromPresent is
false ,- Perform ?
DeletePropertyOrThrow (O, toKey).
- Perform ?
- Let from be from + direction.
- Let to be to + direction.
- Let count be count - 1.
- Let fromKey be !
- Return O.
The copyWithin function is intentionally generic; it does not require that its
22.1.3.4 Array.prototype.entries ( )
The following steps are taken:
- Let O be ?
ToObject (this value). - Return
CreateArrayIterator (O,"key+value").
This function is the %ArrayProto_entries% intrinsic object.
22.1.3.5 Array.prototype.every ( callbackfn [ , thisArg ] )
callbackfn should be a function that accepts three arguments and returns a value that is coercible to the Boolean value every calls callbackfn once for each element present in the array, in ascending order, until it finds one where callbackfn returns every immediately returns every will return
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the value of the element, the index of the element, and the object being traversed.
every does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
The range of elements processed by every is set before the first call to callbackfn. Elements which are appended to the array after the call to every begins will not be visited by callbackfn. If existing elements of the array are changed, their value as passed to callbackfn will be the value at the time every visits them; elements that are deleted after the call to every begins and before being visited are not visited. every acts like the "for all" quantifier in mathematics. In particular, for an empty array, it returns
When the every method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let k be 0.
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then - Increase k by 1.
- Let Pk be !
- Return
true .
The every function is intentionally generic; it does not require that its
22.1.3.6 Array.prototype.fill ( value [ , start [ , end ] ] )
The fill method takes up to three arguments value, start and end.
The start and end arguments are optional with default values of 0 and the length of the
The following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let k be
max ((len + relativeStart), 0); else let k bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Repeat, while k < final
- Return O.
The fill function is intentionally generic; it does not require that its
22.1.3.7 Array.prototype.filter ( callbackfn [ , thisArg ] )
callbackfn should be a function that accepts three arguments and returns a value that is coercible to the Boolean value filter calls callbackfn once for each element in the array, in ascending order, and constructs a new array of all the values for which callbackfn returns
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the value of the element, the index of the element, and the object being traversed.
filter does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
The range of elements processed by filter is set before the first call to callbackfn. Elements which are appended to the array after the call to filter begins will not be visited by callbackfn. If existing elements of the array are changed their value as passed to callbackfn will be the value at the time filter visits them; elements that are deleted after the call to filter begins and before being visited are not visited.
When the filter method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let A be ?
ArraySpeciesCreate (O, 0). - Let k be 0.
- Let to be 0.
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then- Let kValue be ?
Get (O, Pk). - Let selected be
ToBoolean (?Call (callbackfn, T, « kValue, k, O »)). - If selected is
true , then- Perform ?
CreateDataPropertyOrThrow (A, !ToString (to), kValue). - Increase to by 1.
- Perform ?
- Let kValue be ?
- Increase k by 1.
- Let Pk be !
- Return A.
The filter function is intentionally generic; it does not require that its
22.1.3.8 Array.prototype.find ( predicate [ , thisArg ] )
The find method is called with one or two arguments, predicate and thisArg.
predicate should be a function that accepts three arguments and returns a value that is coercible to a Boolean value. find calls predicate once for each element of the array, in ascending order, until it finds one where predicate returns find immediately returns that element value. Otherwise, find returns
If a thisArg parameter is provided, it will be used as the
predicate is called with three arguments: the value of the element, the index of the element, and the object being traversed.
find does not directly mutate the object on which it is called but the object may be mutated by the calls to predicate.
The range of elements processed by find is set before the first call to predicate. Elements that are appended to the array after the call to find begins will not be visited by predicate. If existing elements of the array are changed, their value as passed to predicate will be the value at the time that find visits them.
When the find method is called, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (predicate) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let k be 0.
- Repeat, while k < len
- Return
undefined .
The find function is intentionally generic; it does not require that its
22.1.3.9 Array.prototype.findIndex ( predicate [ , thisArg ] )
predicate should be a function that accepts three arguments and returns a value that is coercible to the Boolean value findIndex calls predicate once for each element of the array, in ascending order, until it finds one where predicate returns findIndex immediately returns the index of that element value. Otherwise, findIndex returns -1.
If a thisArg parameter is provided, it will be used as the
predicate is called with three arguments: the value of the element, the index of the element, and the object being traversed.
findIndex does not directly mutate the object on which it is called but the object may be mutated by the calls to predicate.
The range of elements processed by findIndex is set before the first call to predicate. Elements that are appended to the array after the call to findIndex begins will not be visited by predicate. If existing elements of the array are changed, their value as passed to predicate will be the value at the time that findIndex visits them.
When the findIndex method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (predicate) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let k be 0.
- Repeat, while k < len
- Return -1.
The findIndex function is intentionally generic; it does not require that its
22.1.3.10 Array.prototype.forEach ( callbackfn [ , thisArg ] )
callbackfn should be a function that accepts three arguments. forEach calls callbackfn once for each element present in the array, in ascending order. callbackfn is called only for elements of the array which actually exist; it is not called for missing elements of the array.
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the value of the element, the index of the element, and the object being traversed.
forEach does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
When the forEach method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let k be 0.
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then - Increase k by 1.
- Let Pk be !
- Return
undefined .
This function is the %ArrayProto_forEach% intrinsic object.
The forEach function is intentionally generic; it does not require that its
22.1.3.11 Array.prototype.includes ( searchElement [ , fromIndex ] )
includes compares searchElement to the elements of the array, in ascending order, using the
The optional second argument fromIndex defaults to 0 (i.e. the whole array is searched). If it is greater than or equal to the length of the array,
When the includes method is called, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If len is 0, return
false . - Let n be ?
ToInteger (fromIndex). (If fromIndex isundefined , this step produces the value 0.) - If n ≥ 0, then
- Let k be n.
- Else n < 0,
- Let k be len + n.
- If k < 0, let k be 0.
- Repeat, while k < len
- Let elementK be the result of ?
Get (O, !ToString (k)). - If
SameValueZero (searchElement, elementK) istrue , returntrue . - Increase k by 1.
- Let elementK be the result of ?
- Return
false .
The includes function is intentionally generic; it does not require that its
The includes method intentionally differs from the similar indexOf method in two ways. First, it uses the
22.1.3.12 Array.prototype.indexOf ( searchElement [ , fromIndex ] )
indexOf compares searchElement to the elements of the array, in ascending order, using the
The optional second argument fromIndex defaults to 0 (i.e. the whole array is searched). If it is greater than or equal to the length of the array, -1 is returned, i.e. the array will not be searched. If it is negative, it is used as the offset from the end of the array to compute fromIndex. If the computed index is less than 0, the whole array will be searched.
When the indexOf method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If len is 0, return -1.
- Let n be ?
ToInteger (fromIndex). (If fromIndex isundefined , this step produces the value 0.) - If n ≥ len, return -1.
- If n ≥ 0, then
- If n is
-0 , let k be+0 ; else let k be n.
- If n is
- Else n < 0,
- Let k be len + n.
- If k < 0, let k be 0.
- Repeat, while k < len
- Let kPresent be ?
HasProperty (O, !ToString (k)). - If kPresent is
true , then- Let elementK be ?
Get (O, !ToString (k)). - Let same be the result of performing
Strict Equality Comparison searchElement === elementK. - If same is
true , return k.
- Let elementK be ?
- Increase k by 1.
- Let kPresent be ?
- Return -1.
The indexOf function is intentionally generic; it does not require that its
22.1.3.13 Array.prototype.join ( separator )
The elements of the array are converted to Strings, and these Strings are then concatenated, separated by occurrences of the separator. If no separator is provided, a single comma is used as the separator.
The join method takes one argument, separator, and performs the following steps:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If separator is
undefined , let sep be the single-element String",". - Else, let sep be ?
ToString (separator). - Let R be the empty String.
- Let k be 0.
- Repeat, while k < len
- If k > 0, let R be the
string-concatenation of R and sep. - Let element be ?
Get (O, !ToString (k)). - If element is
undefined ornull , let next be the empty String; otherwise, let next be ?ToString (element). - Set R to the
string-concatenation of R and next. - Increase k by 1.
- If k > 0, let R be the
- Return R.
The join function is intentionally generic; it does not require that its
22.1.3.14 Array.prototype.keys ( )
The following steps are taken:
- Let O be ?
ToObject (this value). - Return
CreateArrayIterator (O,"key").
This function is the %ArrayProto_keys% intrinsic object.
22.1.3.15 Array.prototype.lastIndexOf ( searchElement [ , fromIndex ] )
lastIndexOf compares searchElement to the elements of the array in descending order using the
The optional second argument fromIndex defaults to the array's length minus one (i.e. the whole array is searched). If it is greater than or equal to the length of the array, the whole array will be searched. If it is negative, it is used as the offset from the end of the array to compute fromIndex. If the computed index is less than 0, -1 is returned.
When the lastIndexOf method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If len is 0, return -1.
- If fromIndex is present, let n be ?
ToInteger (fromIndex); else let n be len-1. - If n ≥ 0, then
- If n is
-0 , let k be+0 ; else let k bemin (n, len - 1).
- If n is
- Else n < 0,
- Let k be len + n.
- Repeat, while k ≥ 0
- Let kPresent be ?
HasProperty (O, !ToString (k)). - If kPresent is
true , then- Let elementK be ?
Get (O, !ToString (k)). - Let same be the result of performing
Strict Equality Comparison searchElement === elementK. - If same is
true , return k.
- Let elementK be ?
- Decrease k by 1.
- Let kPresent be ?
- Return -1.
The lastIndexOf function is intentionally generic; it does not require that its
22.1.3.16 Array.prototype.map ( callbackfn [ , thisArg ] )
callbackfn should be a function that accepts three arguments. map calls callbackfn once for each element in the array, in ascending order, and constructs a new Array from the results. callbackfn is called only for elements of the array which actually exist; it is not called for missing elements of the array.
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the value of the element, the index of the element, and the object being traversed.
map does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
The range of elements processed by map is set before the first call to callbackfn. Elements which are appended to the array after the call to map begins will not be visited by callbackfn. If existing elements of the array are changed, their value as passed to callbackfn will be the value at the time map visits them; elements that are deleted after the call to map begins and before being visited are not visited.
When the map method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let A be ?
ArraySpeciesCreate (O, len). - Let k be 0.
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then- Let kValue be ?
Get (O, Pk). - Let mappedValue be ?
Call (callbackfn, T, « kValue, k, O »). - Perform ?
CreateDataPropertyOrThrow (A, Pk, mappedValue).
- Let kValue be ?
- Increase k by 1.
- Let Pk be !
- Return A.
The map function is intentionally generic; it does not require that its
22.1.3.17 Array.prototype.pop ( )
The last element of the array is removed from the array and returned.
When the pop method is called, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If len is zero, then
- Perform ?
Set (O,"length", 0,true ). - Return
undefined .
- Perform ?
- Else len > 0,
- Let newLen be len-1.
- Let index be !
ToString (newLen). - Let element be ?
Get (O, index). - Perform ?
DeletePropertyOrThrow (O, index). - Perform ?
Set (O,"length", newLen,true ). - Return element.
The pop function is intentionally generic; it does not require that its
22.1.3.18 Array.prototype.push ( ...items )
The arguments are appended to the end of the array, in the order in which they appear. The new length of the array is returned as the result of the call.
When the push method is called with zero or more arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let items be a
List whose elements are, in left to right order, the arguments that were passed to this function invocation. - Let argCount be the number of elements in items.
- If len + argCount > 253-1, throw a
TypeError exception. - Repeat, while items is not empty
- Perform ?
Set (O,"length", len,true ). - Return len.
The length property of the push method is 1.
The push function is intentionally generic; it does not require that its
22.1.3.19 Array.prototype.reduce ( callbackfn [ , initialValue ] )
callbackfn should be a function that takes four arguments. reduce calls the callback, as a function, once for each element after the first element present in the array, in ascending order.
callbackfn is called with four arguments: the previousValue (value from the previous call to callbackfn), the currentValue (value of the current element), the currentIndex, and the object being traversed. The first time that callback is called, the previousValue and currentValue can be one of two values. If an initialValue was supplied in the call to reduce, then previousValue will be equal to initialValue and currentValue will be equal to the first value in the array. If no initialValue was supplied, then previousValue will be equal to the first value in the array and currentValue will be equal to the second. It is a
reduce does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
The range of elements processed by reduce is set before the first call to callbackfn. Elements that are appended to the array after the call to reduce begins will not be visited by callbackfn. If existing elements of the array are changed, their value as passed to callbackfn will be the value at the time reduce visits them; elements that are deleted after the call to reduce begins and before being visited are not visited.
When the reduce method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If len is 0 and initialValue is not present, throw a
TypeError exception. - Let k be 0.
- Let accumulator be
undefined . - If initialValue is present, then
- Set accumulator to initialValue.
- Else initialValue is not present,
- Let kPresent be
false . - Repeat, while kPresent is
false and k < len- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then- Set accumulator to ?
Get (O, Pk).
- Set accumulator to ?
- Increase k by 1.
- Let Pk be !
- If kPresent is
false , throw aTypeError exception.
- Let kPresent be
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then - Increase k by 1.
- Let Pk be !
- Return accumulator.
The reduce function is intentionally generic; it does not require that its
22.1.3.20 Array.prototype.reduceRight ( callbackfn [ , initialValue ] )
callbackfn should be a function that takes four arguments. reduceRight calls the callback, as a function, once for each element after the first element present in the array, in descending order.
callbackfn is called with four arguments: the previousValue (value from the previous call to callbackfn), the currentValue (value of the current element), the currentIndex, and the object being traversed. The first time the function is called, the previousValue and currentValue can be one of two values. If an initialValue was supplied in the call to reduceRight, then previousValue will be equal to initialValue and currentValue will be equal to the last value in the array. If no initialValue was supplied, then previousValue will be equal to the last value in the array and currentValue will be equal to the second-to-last value. It is a
reduceRight does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
The range of elements processed by reduceRight is set before the first call to callbackfn. Elements that are appended to the array after the call to reduceRight begins will not be visited by callbackfn. If existing elements of the array are changed by callbackfn, their value as passed to callbackfn will be the value at the time reduceRight visits them; elements that are deleted after the call to reduceRight begins and before being visited are not visited.
When the reduceRight method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If len is 0 and initialValue is not present, throw a
TypeError exception. - Let k be len-1.
- Let accumulator be
undefined . - If initialValue is present, then
- Set accumulator to initialValue.
- Else initialValue is not present,
- Let kPresent be
false . - Repeat, while kPresent is
false and k ≥ 0- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then- Set accumulator to ?
Get (O, Pk).
- Set accumulator to ?
- Decrease k by 1.
- Let Pk be !
- If kPresent is
false , throw aTypeError exception.
- Let kPresent be
- Repeat, while k ≥ 0
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then - Decrease k by 1.
- Let Pk be !
- Return accumulator.
The reduceRight function is intentionally generic; it does not require that its this value be an Array object. Therefore it can be transferred to other kinds of objects for use as a method.
22.1.3.21 Array.prototype.reverse ( )
The elements of the array are rearranged so as to reverse their order. The object is returned as the result of the call.
When the reverse method is called, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let middle be
floor (len/2). - Let lower be 0.
- Repeat, while lower ≠ middle
- Let upper be len - lower - 1.
- Let upperP be !
ToString (upper). - Let lowerP be !
ToString (lower). - Let lowerExists be ?
HasProperty (O, lowerP). - If lowerExists is
true , then- Let lowerValue be ?
Get (O, lowerP).
- Let lowerValue be ?
- Let upperExists be ?
HasProperty (O, upperP). - If upperExists is
true , then- Let upperValue be ?
Get (O, upperP).
- Let upperValue be ?
- If lowerExists is
true and upperExists istrue , then - Else if lowerExists is
false and upperExists istrue , then- Perform ?
Set (O, lowerP, upperValue,true ). - Perform ?
DeletePropertyOrThrow (O, upperP).
- Perform ?
- Else if lowerExists is
true and upperExists isfalse , then- Perform ?
DeletePropertyOrThrow (O, lowerP). - Perform ?
Set (O, upperP, lowerValue,true ).
- Perform ?
- Else both lowerExists and upperExists are
false ,- No action is required.
- Increase lower by 1.
- Return O.
The reverse function is intentionally generic; it does not require that its
22.1.3.22 Array.prototype.shift ( )
The first element of the array is removed from the array and returned.
When the shift method is called, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If len is zero, then
- Perform ?
Set (O,"length", 0,true ). - Return
undefined .
- Perform ?
- Let first be ?
Get (O,"0"). - Let k be 1.
- Repeat, while k < len
- Let from be !
ToString (k). - Let to be !
ToString (k-1). - Let fromPresent be ?
HasProperty (O, from). - If fromPresent is
true , then - Else fromPresent is
false ,- Perform ?
DeletePropertyOrThrow (O, to).
- Perform ?
- Increase k by 1.
- Let from be !
- Perform ?
DeletePropertyOrThrow (O, !ToString (len-1)). - Perform ?
Set (O,"length", len-1,true ). - Return first.
The shift function is intentionally generic; it does not require that its
22.1.3.23 Array.prototype.slice ( start, end )
The slice method takes two arguments, start and end, and returns an array containing the elements of the array from element start up to, but not including, element end (or through the end of the array if end is
The following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let k be
max ((len + relativeStart), 0); else let k bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Let count be
max (final - k, 0). - Let A be ?
ArraySpeciesCreate (O, count). - Let n be 0.
- Repeat, while k < final
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then- Let kValue be ?
Get (O, Pk). - Perform ?
CreateDataPropertyOrThrow (A, !ToString (n), kValue).
- Let kValue be ?
- Increase k by 1.
- Increase n by 1.
- Let Pk be !
- Perform ?
Set (A,"length", n,true ). - Return A.
The explicit setting of the length property of the result Array in step 11 was necessary in previous editions of ECMAScript to ensure that its length was correct in situations where the trailing elements of the result Array were not present. Setting length became unnecessary starting in ES2015 when the result Array was initialized to its proper length rather than an empty Array but is carried forward to preserve backward compatibility.
The slice function is intentionally generic; it does not require that its
22.1.3.24 Array.prototype.some ( callbackfn [ , thisArg ] )
callbackfn should be a function that accepts three arguments and returns a value that is coercible to the Boolean value some calls callbackfn once for each element present in the array, in ascending order, until it finds one where callbackfn returns some immediately returns some returns
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the value of the element, the index of the element, and the object being traversed.
some does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
The range of elements processed by some is set before the first call to callbackfn. Elements that are appended to the array after the call to some begins will not be visited by callbackfn. If existing elements of the array are changed, their value as passed to callbackfn will be the value at the time that some visits them; elements that are deleted after the call to some begins and before being visited are not visited. some acts like the "exists" quantifier in mathematics. In particular, for an empty array, it returns
When the some method is called with one or two arguments, the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let k be 0.
- Repeat, while k < len
- Let Pk be !
ToString (k). - Let kPresent be ?
HasProperty (O, Pk). - If kPresent is
true , then - Increase k by 1.
- Let Pk be !
- Return
false .
The some function is intentionally generic; it does not require that its
22.1.3.25 Array.prototype.sort ( comparefn )
The elements of this array are sorted. The sort is not necessarily stable (that is, elements that compare equal do not necessarily remain in their original order). If comparefn is not
Upon entry, the following steps are performed to initialize evaluation of the sort function:
- If comparefn is not
undefined andIsCallable (comparefn) isfalse , throw aTypeError exception. - Let obj be ?
ToObject (this value). - Let len be ?
ToLength (?Get (obj,"length")).
Within this specification of the sort method, an object, obj, is said to be sparse if the following algorithm returns
The sort order is the ordering, after completion of this function, of the sort function is then determined as follows:
If comparefn is not
Let proto be obj.[[GetPrototypeOf]](). If proto is not
- obj is sparse
- 0 ≤ j < len
-
HasProperty (proto,ToString (j)) istrue .
The sort order is also implementation-defined if obj is sparse and any of the following conditions are true:
-
IsExtensible (obj) isfalse . -
Any
integer index property of obj whose name is a nonnegativeinteger less than len is adata property whose [[Configurable]] attribute isfalse .
The sort order is also implementation-defined if any of the following conditions are true:
-
If obj is an
exotic object (including Proxy exotic objects) whose behaviour for [[Get]], [[Set]], [[Delete]], and [[GetOwnProperty]] is not the ordinary object implementation of these internal methods. -
If any index property of obj whose name is a nonnegative
integer less than len is anaccessor property or is adata property whose [[Writable]] attribute isfalse . -
If comparefn is
undefined and the application ofToString to any value passed as an argument toSortCompare modifies obj or any object on obj's prototype chain. -
If comparefn is
undefined and all applications ofToString , to any specific value passed as an argument toSortCompare , do not produce the same result.
The following steps are taken:
- Perform an implementation-dependent sequence of calls to the [[Get]] and [[Set]] internal methods of obj, to the
DeletePropertyOrThrow andHasOwnProperty abstract operation with obj as the first argument, and toSortCompare (described below), such that:- The property key argument for each call to [[Get]], [[Set]],
HasOwnProperty , orDeletePropertyOrThrow is the string representation of a nonnegativeinteger less than len. - The arguments for calls to
SortCompare are values returned by a previous call to the [[Get]] internal method, unless the properties accessed by those previous calls did not exist according toHasOwnProperty . If both prospective arguments toSortCompare correspond to non-existent properties, use+0 instead of callingSortCompare . If only the first prospective argument is non-existent use +1. If only the second prospective argument is non-existent use -1. - If obj is not sparse then
DeletePropertyOrThrow must not be called. - If any [[Set]] call returns
false aTypeError exception is thrown. - If an
abrupt completion is returned from any of these operations, it is immediately returned as the value of this function.
- The property key argument for each call to [[Get]], [[Set]],
- Return obj.
Unless the sort order is specified above to be implementation-defined, the returned object must have the following two characteristics:
-
There must be some mathematical permutation π of the nonnegative integers less than len, such that for every nonnegative
integer j less than len, if propertyold[j] existed, thennew[π(j)] is exactly the same value asold[j] . But if propertyold[j] did not exist, thennew[π(j)] does not exist. -
Then for all nonnegative integers j and k, each less than len, if
SortCompare (old[j], old[k]) < 0SortCompare below), thennew[π(j)] < new[π(k)] .
Here the notation
A function comparefn is a consistent comparison function for a set of values S if all of the requirements below are met for all values a, b, and c (possibly the same value) in the set S: The notation
-
Calling comparefn(a, b) always returns the same value v when given a specific pair of values a and b as its two arguments. Furthermore,
Type (v) is Number, and v is notNaN . Note that this implies that exactly one of a <CF b, a =CF b, and a >CF b will be true for a given pair of a and b. - Calling comparefn(a, b) does not modify obj or any object on obj's prototype chain.
- a =CF a (reflexivity)
- If a =CF b, then b =CF a (symmetry)
- If a =CF b and b =CF c, then a =CF c (transitivity of =CF)
- If a <CF b and b <CF c, then a <CF c (transitivity of <CF)
- If a >CF b and b >CF c, then a >CF c (transitivity of >CF)
The above conditions are necessary and sufficient to ensure that comparefn divides the set S into equivalence classes and that these equivalence classes are totally ordered.
The sort function is intentionally generic; it does not require that its
22.1.3.25.1 Runtime Semantics: SortCompare ( x, y )
The SortCompare abstract operation is called with two arguments x and y. It also has access to the comparefn argument passed to the current invocation of the sort method. The following steps are taken:
- If x and y are both
undefined , return+0 . - If x is
undefined , return 1. - If y is
undefined , return -1. - If comparefn is not
undefined , then - Let xString be ?
ToString (x). - Let yString be ?
ToString (y). - Let xSmaller be the result of performing
Abstract Relational Comparison xString < yString. - If xSmaller is
true , return -1. - Let ySmaller be the result of performing
Abstract Relational Comparison yString < xString. - If ySmaller is
true , return 1. - Return
+0 .
Because non-existent property values always compare greater than
Method calls performed by the
22.1.3.26 Array.prototype.splice ( start, deleteCount, ...items )
When the splice method is called with two or more arguments start, deleteCount and zero or more items, the deleteCount elements of the array starting at
The following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let actualStart be
max ((len + relativeStart), 0); else let actualStart bemin (relativeStart, len). - If the number of actual arguments is 0, then
- Let insertCount be 0.
- Let actualDeleteCount be 0.
- Else if the number of actual arguments is 1, then
- Let insertCount be 0.
- Let actualDeleteCount be len - actualStart.
- Else,
- If len+insertCount-actualDeleteCount > 253-1, throw a
TypeError exception. - Let A be ?
ArraySpeciesCreate (O, actualDeleteCount). - Let k be 0.
- Repeat, while k < actualDeleteCount
- Let from be !
ToString (actualStart+k). - Let fromPresent be ?
HasProperty (O, from). - If fromPresent is
true , then- Let fromValue be ?
Get (O, from). - Perform ?
CreateDataPropertyOrThrow (A, !ToString (k), fromValue).
- Let fromValue be ?
- Increment k by 1.
- Let from be !
- Perform ?
Set (A,"length", actualDeleteCount,true ). - Let items be a
List whose elements are, in left to right order, the portion of the actual argument list starting with the third argument. The list is empty if fewer than three arguments were passed. - Let itemCount be the number of elements in items.
- If itemCount < actualDeleteCount, then
- Let k be actualStart.
- Repeat, while k < (len - actualDeleteCount)
- Let from be !
ToString (k+actualDeleteCount). - Let to be !
ToString (k+itemCount). - Let fromPresent be ?
HasProperty (O, from). - If fromPresent is
true , then - Else fromPresent is
false ,- Perform ?
DeletePropertyOrThrow (O, to).
- Perform ?
- Increase k by 1.
- Let from be !
- Let k be len.
- Repeat, while k > (len - actualDeleteCount + itemCount)
- Perform ?
DeletePropertyOrThrow (O, !ToString (k-1)). - Decrease k by 1.
- Perform ?
- Else if itemCount > actualDeleteCount, then
- Let k be (len - actualDeleteCount).
- Repeat, while k > actualStart
- Let from be !
ToString (k + actualDeleteCount - 1). - Let to be !
ToString (k + itemCount - 1). - Let fromPresent be ?
HasProperty (O, from). - If fromPresent is
true , then - Else fromPresent is
false ,- Perform ?
DeletePropertyOrThrow (O, to).
- Perform ?
- Decrease k by 1.
- Let from be !
- Let k be actualStart.
- Repeat, while items is not empty
- Perform ?
Set (O,"length", len - actualDeleteCount + itemCount,true ). - Return A.
The explicit setting of the length property of the result Array in step 19 was necessary in previous editions of ECMAScript to ensure that its length was correct in situations where the trailing elements of the result Array were not present. Setting length became unnecessary starting in ES2015 when the result Array was initialized to its proper length rather than an empty Array but is carried forward to preserve backward compatibility.
The splice function is intentionally generic; it does not require that its
22.1.3.27 Array.prototype.toLocaleString ( [ reserved1 [ , reserved2 ] ] )
An ECMAScript implementation that includes the ECMA-402 Internationalization API must implement the Array.prototype.toLocaleString method as specified in the ECMA-402 specification. If an ECMAScript implementation does not include the ECMA-402 API the following specification of the toLocaleString method is used.
The first edition of ECMA-402 did not include a replacement specification for the Array.prototype.toLocaleString method.
The meanings of the optional parameters to this method are defined in the ECMA-402 specification; implementations that do not include ECMA-402 support must not use those parameter positions for anything else.
The following steps are taken:
- Let array be ?
ToObject (this value). - Let len be ?
ToLength (?Get (array,"length")). - Let separator be the String value for the list-separator String appropriate for the host environment's current locale (this is derived in an implementation-defined way).
- Let R be the empty String.
- Let k be 0.
- Repeat, while k < len
- If k > 0, then
- Set R to the
string-concatenation of R and separator.
- Set R to the
- Let nextElement be ?
Get (array, !ToString (k)). - If nextElement is not
undefined ornull , then- Let S be ?
ToString (?Invoke (nextElement,"toLocaleString")). - Set R to the
string-concatenation of R and S.
- Let S be ?
- Increase k by 1.
- If k > 0, then
- Return R.
The elements of the array are converted to Strings using their toLocaleString methods, and these Strings are then concatenated, separated by occurrences of a separator String that has been derived in an implementation-defined locale-specific way. The result of calling this function is intended to be analogous to the result of toString, except that the result of this function is intended to be locale-specific.
The toLocaleString function is intentionally generic; it does not require that its
22.1.3.28 Array.prototype.toString ( )
When the toString method is called, the following steps are taken:
- Let array be ?
ToObject (this value). - Let func be ?
Get (array,"join"). - If
IsCallable (func) isfalse , let func be the intrinsic function%ObjProto_toString% . - Return ?
Call (func, array).
The toString function is intentionally generic; it does not require that its
22.1.3.29 Array.prototype.unshift ( ...items )
The arguments are prepended to the start of the array, such that their order within the array is the same as the order in which they appear in the argument list.
When the unshift method is called with zero or more arguments item1, item2, etc., the following steps are taken:
- Let O be ?
ToObject (this value). - Let len be ?
ToLength (?Get (O,"length")). - Let argCount be the number of actual arguments.
- If argCount > 0, then
- If len+argCount > 253-1, throw a
TypeError exception. - Let k be len.
- Repeat, while k > 0,
- Let from be !
ToString (k-1). - Let to be !
ToString (k+argCount-1). - Let fromPresent be ?
HasProperty (O, from). - If fromPresent is
true , then - Else fromPresent is
false ,- Perform ?
DeletePropertyOrThrow (O, to).
- Perform ?
- Decrease k by 1.
- Let from be !
- Let j be 0.
- Let items be a
List whose elements are, in left to right order, the arguments that were passed to this function invocation. - Repeat, while items is not empty
- If len+argCount > 253-1, throw a
- Perform ?
Set (O,"length", len+argCount,true ). - Return len+argCount.
The length property of the unshift method is 1.
The unshift function is intentionally generic; it does not require that its
22.1.3.30 Array.prototype.values ( )
The following steps are taken:
- Let O be ?
ToObject (this value). - Return
CreateArrayIterator (O,"value").
This function is the %ArrayProto_values% intrinsic object.
22.1.3.31 Array.prototype [ @@iterator ] ( )
The initial value of the @@iterator property is the same Array.prototype.values property.
22.1.3.32 Array.prototype [ @@unscopables ]
The initial value of the @@unscopables
- Let unscopableList be
ObjectCreate (null ). - Perform
CreateDataProperty (unscopableList,"copyWithin",true ). - Perform
CreateDataProperty (unscopableList,"entries",true ). - Perform
CreateDataProperty (unscopableList,"fill",true ). - Perform
CreateDataProperty (unscopableList,"find",true ). - Perform
CreateDataProperty (unscopableList,"findIndex",true ). - Perform
CreateDataProperty (unscopableList,"includes",true ). - Perform
CreateDataProperty (unscopableList,"keys",true ). - Perform
CreateDataProperty (unscopableList,"values",true ). Assert : Each of the above calls will returntrue .- Return unscopableList.
This property has the attributes { [[Writable]]:
The own property names of this object are property names that were not included as standard properties of Array.prototype prior to the ECMAScript 2015 specification. These names are ignored for with statement binding purposes in order to preserve the behaviour of existing code that might use one of these names as a binding in an outer scope that is shadowed by a with statement whose binding object is an Array object.
22.1.4 Properties of Array Instances
Array instances are Array exotic objects and have the internal methods specified for such objects. Array instances inherit properties from the Array prototype object.
Array instances have a length property, and a set of enumerable properties with
22.1.4.1 length
The length property of an Array instance is a
The length property initially has the attributes { [[Writable]]:
Reducing the value of the length property has the side-effect of deleting own array elements whose
22.1.5 Array Iterator Objects
An Array Iterator is an object, that represents a specific iteration over some specific Array instance object. There is not a named
22.1.5.1 CreateArrayIterator ( array, kind )
Several methods of Array objects return Iterator objects. The abstract operation CreateArrayIterator with arguments array and kind is used to create such iterator objects. It performs the following steps:
Assert :Type (array) is Object.- Let iterator be
ObjectCreate (%ArrayIteratorPrototype% , « [[IteratedObject]], [[ArrayIteratorNextIndex]], [[ArrayIterationKind]] »). - Set iterator.[[IteratedObject]] to array.
- Set iterator.[[ArrayIteratorNextIndex]] to 0.
- Set iterator.[[ArrayIterationKind]] to kind.
- Return iterator.
22.1.5.2 The %ArrayIteratorPrototype% Object
The %ArrayIteratorPrototype% object:
- has properties that are inherited by all Array Iterator Objects.
- is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%IteratorPrototype% . - has the following properties:
22.1.5.2.1 %ArrayIteratorPrototype%.next ( )
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have all of the internal slots of an Array Iterator Instance (
22.1.5.3 ), throw aTypeError exception. - Let a be O.[[IteratedObject]].
- If a is
undefined , returnCreateIterResultObject (undefined ,true ). - Let index be O.[[ArrayIteratorNextIndex]].
- Let itemKind be O.[[ArrayIterationKind]].
- If a has a [[TypedArrayName]] internal slot, then
- If
IsDetachedBuffer (a.[[ViewedArrayBuffer]]) istrue , throw aTypeError exception. - Let len be a.[[ArrayLength]].
- If
- Else,
- If index ≥ len, then
- Set O.[[IteratedObject]] to
undefined . - Return
CreateIterResultObject (undefined ,true ).
- Set O.[[IteratedObject]] to
- Set O.[[ArrayIteratorNextIndex]] to index+1.
- If itemKind is
"key", returnCreateIterResultObject (index,false ). - Let elementKey be !
ToString (index). - Let elementValue be ?
Get (a, elementKey). - If itemKind is
"value", let result be elementValue. - Else,
Assert : itemKind is"key+value".- Let result be
CreateArrayFromList (« index, elementValue »).
- Return
CreateIterResultObject (result,false ).
22.1.5.2.2 %ArrayIteratorPrototype% [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Array Iterator".
This property has the attributes { [[Writable]]:
22.1.5.3 Properties of Array Iterator Instances
Array Iterator instances are ordinary objects that inherit properties from the
| Internal Slot | Description |
|---|---|
| [[IteratedObject]] | The object whose array elements are being iterated. |
| [[ArrayIteratorNextIndex]] |
The |
| [[ArrayIterationKind]] |
A String value that identifies what is returned for each element of the iteration. The possible values are: "key", "value", "key+value".
|
22.2 TypedArray Objects
TypedArray objects present an array-like view of an underlying binary data buffer (
|
|
Element Type | Element Size | Conversion Operation | Description | Equivalent C Type |
|---|---|---|---|---|---|
|
Int8Array
%Int8Array% |
Int8 | 1 |
|
8-bit 2's complement signed |
signed char |
|
Uint8Array
%Uint8Array% |
Uint8 | 1 |
|
8-bit unsigned |
unsigned char |
|
Uint8ClampedArray
%Uint8ClampedArray% |
Uint8C | 1 |
|
8-bit unsigned |
unsigned char |
|
Int16Array
%Int16Array% |
Int16 | 2 |
|
16-bit 2's complement signed |
short |
|
Uint16Array
%Uint16Array% |
Uint16 | 2 |
|
16-bit unsigned |
unsigned short |
|
Int32Array
%Int32Array% |
Int32 | 4 |
|
32-bit 2's complement signed |
int |
|
Uint32Array
%Uint32Array% |
Uint32 | 4 |
|
32-bit unsigned |
unsigned int |
|
Float32Array
%Float32Array% |
Float32 | 4 | 32-bit IEEE floating point | float | |
|
Float64Array
%Float64Array% |
Float64 | 8 | 64-bit IEEE floating point | double |
In the definitions below, references to TypedArray should be replaced with the appropriate
22.2.1 The %TypedArray% Intrinsic Object
The %TypedArray% intrinsic object:
- is a
constructor function object that all of the TypedArrayconstructor objects inherit from. - along with its corresponding prototype object, provides common properties that are inherited by all TypedArray constructors and their instances.
- does not have a global name or appear as a property of the
global object . - acts as the abstract superclass of the various TypedArray constructors.
- will throw an error when invoked, because it is an abstract class
constructor . The TypedArray constructors do not perform asupercall to it.
22.2.1.1 %TypedArray% ( )
The
- Throw a
TypeError exception.
The length property of the
22.2.2 Properties of the %TypedArray% Intrinsic Object
The
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has a
nameproperty whose value is"TypedArray". - has the following properties:
22.2.2.1 %TypedArray%.from ( source [ , mapfn [ , thisArg ] ] )
When the from method is called with argument source, and optional arguments mapfn and thisArg, the following steps are taken:
- Let C be the
this value. - If
IsConstructor (C) isfalse , throw aTypeError exception. - If mapfn is present and mapfn is not
undefined , then- If
IsCallable (mapfn) isfalse , throw aTypeError exception. - Let mapping be
true .
- If
- Else, let mapping be
false . - If thisArg is present, let T be thisArg; else let T be
undefined . - Let usingIterator be ?
GetMethod (source, @@iterator). - If usingIterator is not
undefined , then- Let values be ?
IterableToList (source, usingIterator). - Let len be the number of elements in values.
- Let targetObj be ?
TypedArrayCreate (C, « len »). - Let k be 0.
- Repeat, while k < len
Assert : values is now an emptyList .- Return targetObj.
- Let values be ?
- NOTE: source is not an Iterable so assume it is already an
array-like object . - Let arrayLike be !
ToObject (source). - Let len be ?
ToLength (?Get (arrayLike,"length")). - Let targetObj be ?
TypedArrayCreate (C, « len »). - Let k be 0.
- Repeat, while k < len
- Return targetObj.
22.2.2.1.1 Runtime Semantics: IterableToList ( items, method )
The abstract operation IterableToList performs the following steps:
- Let iteratorRecord be ?
GetIterator (items,sync , method). - Let values be a new empty
List . - Let next be
true . - Repeat, while next is not
false - Set next to ?
IteratorStep (iteratorRecord). - If next is not
false , then- Let nextValue be ?
IteratorValue (next). - Append nextValue to the end of the
List values.
- Let nextValue be ?
- Set next to ?
- Return values.
22.2.2.2 %TypedArray%.of ( ...items )
When the of method is called with any number of arguments, the following steps are taken:
- Let len be the actual number of arguments passed to this function.
- Let items be the
List of arguments passed to this function. - Let C be the
this value. - If
IsConstructor (C) isfalse , throw aTypeError exception. - Let newObj be ?
TypedArrayCreate (C, « len »). - Let k be 0.
- Repeat, while k < len
- Return newObj.
The items argument is assumed to be a well-formed rest argument value.
22.2.2.3 %TypedArray%.prototype
The initial value of
This property has the attributes { [[Writable]]:
22.2.2.4 get %TypedArray% [ @@species ]
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
this object's
22.2.3 Properties of the %TypedArrayPrototype% Object
The %TypedArrayPrototype% object:
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[ViewedArrayBuffer]] or any other of the internal slots that are specific to TypedArray instance objects.
22.2.3.1 get %TypedArray%.prototype.buffer
prototype.buffer is an
22.2.3.2 get %TypedArray%.prototype.byteLength
prototype.byteLength is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : O has a [[ViewedArrayBuffer]] internal slot.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , return 0. - Let size be O.[[ByteLength]].
- Return size.
22.2.3.3 get %TypedArray%.prototype.byteOffset
prototype.byteOffset is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : O has a [[ViewedArrayBuffer]] internal slot.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , return 0. - Let offset be O.[[ByteOffset]].
- Return offset.
22.2.3.4 %TypedArray%.prototype.constructor
The initial value of
22.2.3.5 %TypedArray%.prototype.copyWithin ( target, start [ , end ] )
The interpretation and use of the arguments of .prototype.copyWithin are the same as for Array.prototype.copyWithin as defined in
The following steps are taken:
- Let O be
this value. - Perform ?
ValidateTypedArray (O). - Let len be O.[[ArrayLength]].
- Let relativeTarget be ?
ToInteger (target). - If relativeTarget < 0, let to be
max ((len + relativeTarget), 0); else let to bemin (relativeTarget, len). - Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let from be
max ((len + relativeStart), 0); else let from bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Let count be
min (final-from, len-to). - If count > 0, then
- NOTE: The copying must be performed in a manner that preserves the bit-level encoding of the source data.
- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let typedArrayName be the String value of O.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for typedArrayName. - Let byteOffset be O.[[ByteOffset]].
- Let toByteIndex be to × elementSize + byteOffset.
- Let fromByteIndex be from × elementSize + byteOffset.
- Let countBytes be count × elementSize.
- If fromByteIndex<toByteIndex and toByteIndex<fromByteIndex+countBytes, then
- Let direction be -1.
- Let fromByteIndex be fromByteIndex + countBytes - 1.
- Let toByteIndex be toByteIndex + countBytes - 1.
- Else,
- Let direction be 1.
- Repeat, while countBytes > 0
- Let value be
GetValueFromBuffer (buffer, fromByteIndex,"Uint8",true ,"Unordered"). - Perform
SetValueInBuffer (buffer, toByteIndex,"Uint8", value,true ,"Unordered"). - Let fromByteIndex be fromByteIndex + direction.
- Let toByteIndex be toByteIndex + direction.
- Let countBytes be countBytes - 1.
- Let value be
- Return O.
22.2.3.5.1 Runtime Semantics: ValidateTypedArray ( O )
When called with argument O, the following steps are taken:
- If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : O has a [[ViewedArrayBuffer]] internal slot.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Return buffer.
22.2.3.6 %TypedArray%.prototype.entries ( )
The following steps are taken:
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Return
CreateArrayIterator (O,"key+value").
22.2.3.7 %TypedArray%.prototype.every ( callbackfn [ , thisArg ] )
.prototype.every is a distinct function that implements the same algorithm as Array.prototype.every as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.8 %TypedArray%.prototype.fill ( value [ , start [ , end ] ] )
The interpretation and use of the arguments of .prototype.fill are the same as for Array.prototype.fill as defined in
The following steps are taken:
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Let len be O.[[ArrayLength]].
- Let value be ?
ToNumber (value). - Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let k be
max ((len + relativeStart), 0); else let k bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - If
IsDetachedBuffer (O.[[ViewedArrayBuffer]]) istrue , throw aTypeError exception. - Repeat, while k < final
- Return O.
22.2.3.9 %TypedArray%.prototype.filter ( callbackfn [ , thisArg ] )
The interpretation and use of the arguments of .prototype.filter are the same as for Array.prototype.filter as defined in
When the filter method is called with one or two arguments, the following steps are taken:
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Let len be O.[[ArrayLength]].
- If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let kept be a new empty
List . - Let k be 0.
- Let captured be 0.
- Repeat, while k < len
- Let A be ?
TypedArraySpeciesCreate (O, « captured »). - Let n be 0.
- For each element e of kept, do
- Return A.
This function is not generic. The
22.2.3.10 %TypedArray%.prototype.find ( predicate [ , thisArg ] )
.prototype.find is a distinct function that implements the same algorithm as Array.prototype.find as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.11 %TypedArray%.prototype.findIndex ( predicate [ , thisArg ] )
.prototype.findIndex is a distinct function that implements the same algorithm as Array.prototype.findIndex as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.12 %TypedArray%.prototype.forEach ( callbackfn [ , thisArg ] )
.prototype.forEach is a distinct function that implements the same algorithm as Array.prototype.forEach as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.13 %TypedArray%.prototype.includes ( searchElement [ , fromIndex ] )
%TypedArray%.prototype.includes is a distinct function that implements the same algorithm as Array.prototype.includes as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.14 %TypedArray%.prototype.indexOf ( searchElement [ , fromIndex ] )
.prototype.indexOf is a distinct function that implements the same algorithm as Array.prototype.indexOf as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.15 %TypedArray%.prototype.join ( separator )
.prototype.join is a distinct function that implements the same algorithm as Array.prototype.join as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.16 %TypedArray%.prototype.keys ( )
The following steps are taken:
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Return
CreateArrayIterator (O,"key").
22.2.3.17 %TypedArray%.prototype.lastIndexOf ( searchElement [ , fromIndex ] )
.prototype.lastIndexOf is a distinct function that implements the same algorithm as Array.prototype.lastIndexOf as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.18 get %TypedArray%.prototype.length
prototype.length is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : O has [[ViewedArrayBuffer]] and [[ArrayLength]] internal slots.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , return 0. - Let length be O.[[ArrayLength]].
- Return length.
This function is not generic. The
22.2.3.19 %TypedArray%.prototype.map ( callbackfn [ , thisArg ] )
The interpretation and use of the arguments of .prototype.map are the same as for Array.prototype.map as defined in
When the map method is called with one or two arguments, the following steps are taken:
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Let len be O.[[ArrayLength]].
- If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let A be ?
TypedArraySpeciesCreate (O, « len »). - Let k be 0.
- Repeat, while k < len
- Return A.
This function is not generic. The
22.2.3.20 %TypedArray%.prototype.reduce ( callbackfn [ , initialValue ] )
.prototype.reduce is a distinct function that implements the same algorithm as Array.prototype.reduce as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.21 %TypedArray%.prototype.reduceRight ( callbackfn [ , initialValue ] )
.prototype.reduceRight is a distinct function that implements the same algorithm as Array.prototype.reduceRight as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.22 %TypedArray%.prototype.reverse ( )
.prototype.reverse is a distinct function that implements the same algorithm as Array.prototype.reverse as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.23 %TypedArray%.prototype.set ( overloaded [ , offset ] )
.prototype.set is a single function whose behaviour is overloaded based upon the type of its first argument.
This function is not generic. The
22.2.3.23.1 %TypedArray%.prototype.set ( array [ , offset ] )
Sets multiple values in this TypedArray, reading the values from the object array. The optional offset value indicates the first element index in this TypedArray where values are written. If omitted, it is assumed to be 0.
Assert : array is anyECMAScript language value other than an Object with a [[TypedArrayName]] internal slot. If it is such an Object, the definition in22.2.3.23.2 applies.- Let target be the
this value. - If
Type (target) is not Object, throw aTypeError exception. - If target does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : target has a [[ViewedArrayBuffer]] internal slot.- Let targetOffset be ?
ToInteger (offset). - If targetOffset < 0, throw a
RangeError exception. - Let targetBuffer be target.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (targetBuffer) istrue , throw aTypeError exception. - Let targetLength be target.[[ArrayLength]].
- Let targetName be the String value of target.[[TypedArrayName]].
- Let targetElementSize be the
Number value of the Element Size value specified inTable 56 for targetName. - Let targetType be the String value of the Element Type value in
Table 56 for targetName. - Let targetByteOffset be target.[[ByteOffset]].
- Let src be ?
ToObject (array). - Let srcLength be ?
ToLength (?Get (src,"length")). - If srcLength + targetOffset > targetLength, throw a
RangeError exception. - Let targetByteIndex be targetOffset × targetElementSize + targetByteOffset.
- Let k be 0.
- Let limit be targetByteIndex + targetElementSize × srcLength.
- Repeat, while targetByteIndex < limit
- Let Pk be !
ToString (k). - Let kNumber be ?
ToNumber (?Get (src, Pk)). - If
IsDetachedBuffer (targetBuffer) istrue , throw aTypeError exception. - Perform
SetValueInBuffer (targetBuffer, targetByteIndex, targetType, kNumber,true ,"Unordered"). - Set k to k + 1.
- Set targetByteIndex to targetByteIndex + targetElementSize.
- Let Pk be !
- Return
undefined .
22.2.3.23.2 %TypedArray%.prototype.set ( typedArray [ , offset ] )
Sets multiple values in this TypedArray, reading the values from the typedArray argument object. The optional offset value indicates the first element index in this TypedArray where values are written. If omitted, it is assumed to be 0.
Assert : typedArray has a [[TypedArrayName]] internal slot. If it does not, the definition in22.2.3.23.1 applies.- Let target be the
this value. - If
Type (target) is not Object, throw aTypeError exception. - If target does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : target has a [[ViewedArrayBuffer]] internal slot.- Let targetOffset be ?
ToInteger (offset). - If targetOffset < 0, throw a
RangeError exception. - Let targetBuffer be target.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (targetBuffer) istrue , throw aTypeError exception. - Let targetLength be target.[[ArrayLength]].
- Let srcBuffer be typedArray.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (srcBuffer) istrue , throw aTypeError exception. - Let targetName be the String value of target.[[TypedArrayName]].
- Let targetType be the String value of the Element Type value in
Table 56 for targetName. - Let targetElementSize be the
Number value of the Element Size value specified inTable 56 for targetName. - Let targetByteOffset be target.[[ByteOffset]].
- Let srcName be the String value of typedArray.[[TypedArrayName]].
- Let srcType be the String value of the Element Type value in
Table 56 for srcName. - Let srcElementSize be the
Number value of the Element Size value specified inTable 56 for srcName. - Let srcLength be typedArray.[[ArrayLength]].
- Let srcByteOffset be typedArray.[[ByteOffset]].
- If srcLength + targetOffset > targetLength, throw a
RangeError exception. - If both
IsSharedArrayBuffer (srcBuffer) andIsSharedArrayBuffer (targetBuffer) aretrue , then- If srcBuffer.[[ArrayBufferData]] and targetBuffer.[[ArrayBufferData]] are the same
Shared Data Block values, let same betrue ; else let same befalse .
- If srcBuffer.[[ArrayBufferData]] and targetBuffer.[[ArrayBufferData]] are the same
- Else, let same be
SameValue (srcBuffer, targetBuffer). - If same is
true , then- Let srcByteLength be typedArray.[[ByteLength]].
- Let srcBuffer be ?
CloneArrayBuffer (srcBuffer, srcByteOffset, srcByteLength,%ArrayBuffer% ). - NOTE:
%ArrayBuffer% is used to clone srcBuffer because is it known to not have any observable side-effects. - Let srcByteIndex be 0.
- Else, let srcByteIndex be srcByteOffset.
- Let targetByteIndex be targetOffset × targetElementSize + targetByteOffset.
- Let limit be targetByteIndex + targetElementSize × srcLength.
- If
SameValue (srcType, targetType) istrue , then- NOTE: If srcType and targetType are the same, the transfer must be performed in a manner that preserves the bit-level encoding of the source data.
- Repeat, while targetByteIndex < limit
- Let value be
GetValueFromBuffer (srcBuffer, srcByteIndex,"Uint8",true ,"Unordered"). - Perform
SetValueInBuffer (targetBuffer, targetByteIndex,"Uint8", value,true ,"Unordered"). - Set srcByteIndex to srcByteIndex + 1.
- Set targetByteIndex to targetByteIndex + 1.
- Let value be
- Else,
- Repeat, while targetByteIndex < limit
- Let value be
GetValueFromBuffer (srcBuffer, srcByteIndex, srcType,true ,"Unordered"). - Perform
SetValueInBuffer (targetBuffer, targetByteIndex, targetType, value,true ,"Unordered"). - Set srcByteIndex to srcByteIndex + srcElementSize.
- Set targetByteIndex to targetByteIndex + targetElementSize.
- Let value be
- Repeat, while targetByteIndex < limit
- Return
undefined .
22.2.3.24 %TypedArray%.prototype.slice ( start, end )
The interpretation and use of the arguments of .prototype.slice are the same as for Array.prototype.slice as defined in
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Let len be O.[[ArrayLength]].
- Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let k be
max ((len + relativeStart), 0); else let k bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Let count be
max (final - k, 0). - Let A be ?
TypedArraySpeciesCreate (O, « count »). - Let srcName be the String value of O.[[TypedArrayName]].
- Let srcType be the String value of the Element Type value in
Table 56 for srcName. - Let targetName be the String value of A.[[TypedArrayName]].
- Let targetType be the String value of the Element Type value in
Table 56 for targetName. - If
SameValue (srcType, targetType) isfalse , then - Else if count > 0, then
- Let srcBuffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (srcBuffer) istrue , throw aTypeError exception. - Let targetBuffer be A.[[ViewedArrayBuffer]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for srcType. - NOTE: If srcType and targetType are the same, the transfer must be performed in a manner that preserves the bit-level encoding of the source data.
- Let srcByteOffet be O.[[ByteOffset]].
- Let targetByteIndex be A.[[ByteOffset]].
- Let srcByteIndex be (k × elementSize) + srcByteOffet.
- Let limit be targetByteIndex + count × elementSize.
- Repeat, while targetByteIndex < limit
- Let value be
GetValueFromBuffer (srcBuffer, srcByteIndex,"Uint8",true ,"Unordered"). - Perform
SetValueInBuffer (targetBuffer, targetByteIndex,"Uint8", value,true ,"Unordered"). - Increase srcByteIndex by 1.
- Increase targetByteIndex by 1.
- Let value be
- Return A.
This function is not generic. The
22.2.3.25 %TypedArray%.prototype.some ( callbackfn [ , thisArg ] )
.prototype.some is a distinct function that implements the same algorithm as Array.prototype.some as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
22.2.3.26 %TypedArray%.prototype.sort ( comparefn )
.prototype.sort is a distinct function that, except as described below, implements the same requirements as those of Array.prototype.sort as defined in .prototype.sort specification may be optimized with the knowledge that the
This function is not generic. The
Upon entry, the following steps are performed to initialize evaluation of the sort function. These steps are used instead of the entry steps in
- If comparefn is not
undefined andIsCallable (comparefn) isfalse , throw aTypeError exception. - Let obj be the
this value. - Let buffer be ?
ValidateTypedArray (obj). - Let len be obj.[[ArrayLength]].
The implementation-defined sort order condition for exotic objects is not applied by .prototype.sort.
The following version of .prototype.sort. It performs a numeric comparison rather than the string comparison used in sort method.
When the TypedArray
Assert : BothType (x) andType (y) is Number.- If comparefn is not
undefined , then- Let v be ?
ToNumber (?Call (comparefn,undefined , « x, y »)). - If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - If v is
NaN , return+0 . - Return v.
- Let v be ?
- If x and y are both
NaN , return+0 . - If x is
NaN , return 1. - If y is
NaN , return -1. - If x < y, return -1.
- If x > y, return 1.
- If x is
-0 and y is+0 , return -1. - If x is
+0 and y is-0 , return 1. - Return
+0 .
Because
22.2.3.27 %TypedArray%.prototype.subarray ( begin, end )
Returns a new TypedArray object whose element type is the same as this TypedArray and whose ArrayBuffer is the same as the ArrayBuffer of this TypedArray, referencing the elements at begin, inclusive, up to end, exclusive. If either begin or end is negative, it refers to an index from the end of the array, as opposed to from the beginning.
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. Assert : O has a [[ViewedArrayBuffer]] internal slot.- Let buffer be O.[[ViewedArrayBuffer]].
- Let srcLength be O.[[ArrayLength]].
- Let relativeBegin be ?
ToInteger (begin). - If relativeBegin < 0, let beginIndex be
max ((srcLength + relativeBegin), 0); else let beginIndex bemin (relativeBegin, srcLength). - If end is
undefined , let relativeEnd be srcLength; else, let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let endIndex be
max ((srcLength + relativeEnd), 0); else let endIndex bemin (relativeEnd, srcLength). - Let newLength be
max (endIndex - beginIndex, 0). - Let constructorName be the String value of O.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for constructorName. - Let srcByteOffset be O.[[ByteOffset]].
- Let beginByteOffset be srcByteOffset + beginIndex × elementSize.
- Let argumentsList be « buffer, beginByteOffset, newLength ».
- Return ?
TypedArraySpeciesCreate (O, argumentsList).
This function is not generic. The
22.2.3.28 %TypedArray%.prototype.toLocaleString ( [ reserved1 [ , reserved2 ] ] )
.prototype.toLocaleString is a distinct function that implements the same algorithm as Array.prototype.toLocaleString as defined in "length". The implementation of the algorithm may be optimized with the knowledge that the
This function is not generic.
If the ECMAScript implementation includes the ECMA-402 Internationalization API this function is based upon the algorithm for Array.prototype.toLocaleString that is in the ECMA-402 specification.
22.2.3.29 %TypedArray%.prototype.toString ( )
The initial value of the .prototype.toString Array.prototype.toString method defined in
22.2.3.30 %TypedArray%.prototype.values ( )
The following steps are taken:
- Let O be the
this value. - Perform ?
ValidateTypedArray (O). - Return
CreateArrayIterator (O,"value").
22.2.3.31 %TypedArray%.prototype [ @@iterator ] ( )
The initial value of the @@iterator property is the same .prototype.values property.
22.2.3.32 get %TypedArray%.prototype [ @@toStringTag ]
prototype[@@toStringTag] is an
This property has the attributes { [[Enumerable]]:
The initial value of the name property of this function is "get [Symbol.toStringTag]".
22.2.4 The TypedArray Constructors
Each TypedArray
- is an intrinsic object that has the structure described below, differing only in the name used as the
constructor name instead of TypedArray, inTable 56 . - is a single function whose behaviour is overloaded based upon the number and types of its arguments. The actual behaviour of a call of TypedArray depends upon the number and kind of arguments that are passed to it.
- is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specified TypedArray behaviour must include asupercall to the TypedArrayconstructor to create and initialize the subclass instance with the internal state necessary to support the%TypedArray%.prototypebuilt-in methods. - has a
lengthproperty whose value is 3.
22.2.4.1 TypedArray ( )
This description applies only if the TypedArray function is called with no arguments.
- If NewTarget is
undefined , throw aTypeError exception. - Let constructorName be the String value of the
Constructor Name value specified inTable 56 for this TypedArrayconstructor . - Return ?
AllocateTypedArray (constructorName, NewTarget,"%TypedArrayPrototype%", 0).
22.2.4.2 TypedArray ( length )
This description applies only if the TypedArray function is called with at least one argument and the Type of the first argument is not Object.
TypedArray called with argument length performs the following steps:
Assert :Type (length) is not Object.- If NewTarget is
undefined , throw aTypeError exception. - Let elementLength be ?
ToIndex (length). - Let constructorName be the String value of the
Constructor Name value specified inTable 56 for this TypedArrayconstructor . - Return ?
AllocateTypedArray (constructorName, NewTarget,"%TypedArrayPrototype%", elementLength).
22.2.4.2.1 Runtime Semantics: AllocateTypedArray ( constructorName, newTarget, defaultProto [ , length ] )
The abstract operation AllocateTypedArray with arguments constructorName, newTarget, defaultProto and optional argument length is used to validate and create an instance of a TypedArray
- Let proto be ?
GetPrototypeFromConstructor (newTarget, defaultProto). - Let obj be
IntegerIndexedObjectCreate (proto, « [[ViewedArrayBuffer]], [[TypedArrayName]], [[ByteLength]], [[ByteOffset]], [[ArrayLength]] »). Assert : obj.[[ViewedArrayBuffer]] isundefined .- Set obj.[[TypedArrayName]] to constructorName.
- If length is not present, then
- Set obj.[[ByteLength]] to 0.
- Set obj.[[ByteOffset]] to 0.
- Set obj.[[ArrayLength]] to 0.
- Else,
- Perform ?
AllocateTypedArrayBuffer (obj, length).
- Perform ?
- Return obj.
22.2.4.2.2 Runtime Semantics: AllocateTypedArrayBuffer ( O, length )
The abstract operation AllocateTypedArrayBuffer with arguments O and length allocates and associates an ArrayBuffer with the TypedArray instance O. It performs the following steps:
Assert : O is an Object that has a [[ViewedArrayBuffer]] internal slot.Assert : O.[[ViewedArrayBuffer]] isundefined .Assert : length ≥ 0.- Let constructorName be the String value of O.[[TypedArrayName]].
- Let elementSize be the Element Size value in
Table 56 for constructorName. - Let byteLength be elementSize × length.
- Let data be ?
AllocateArrayBuffer (%ArrayBuffer% , byteLength). - Set O.[[ViewedArrayBuffer]] to data.
- Set O.[[ByteLength]] to byteLength.
- Set O.[[ByteOffset]] to 0.
- Set O.[[ArrayLength]] to length.
- Return O.
22.2.4.3 TypedArray ( typedArray )
This description applies only if the TypedArray function is called with at least one argument and the Type of the first argument is Object and that object has a [[TypedArrayName]] internal slot.
TypedArray called with argument typedArray performs the following steps:
Assert :Type (typedArray) is Object and typedArray has a [[TypedArrayName]] internal slot.- If NewTarget is
undefined , throw aTypeError exception. - Let constructorName be the String value of the
Constructor Name value specified inTable 56 for this TypedArrayconstructor . - Let O be ?
AllocateTypedArray (constructorName, NewTarget,"%TypedArrayPrototype%"). - Let srcArray be typedArray.
- Let srcData be srcArray.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (srcData) istrue , throw aTypeError exception. - Let elementType be the String value of the Element Type value in
Table 56 for constructorName. - Let elementLength be srcArray.[[ArrayLength]].
- Let srcName be the String value of srcArray.[[TypedArrayName]].
- Let srcType be the String value of the Element Type value in
Table 56 for srcName. - Let srcElementSize be the Element Size value in
Table 56 for srcName. - Let srcByteOffset be srcArray.[[ByteOffset]].
- Let elementSize be the Element Size value in
Table 56 for constructorName. - Let byteLength be elementSize × elementLength.
- If
IsSharedArrayBuffer (srcData) isfalse , then- Let bufferConstructor be ?
SpeciesConstructor (srcData,%ArrayBuffer% ).
- Let bufferConstructor be ?
- Else,
- Let bufferConstructor be
%ArrayBuffer% .
- Let bufferConstructor be
- If
SameValue (elementType, srcType) istrue , then- If
IsDetachedBuffer (srcData) istrue , throw aTypeError exception. - Let data be ?
CloneArrayBuffer (srcData, srcByteOffset, byteLength, bufferConstructor).
- If
- Else,
- Let data be ?
AllocateArrayBuffer (bufferConstructor, byteLength). - If
IsDetachedBuffer (srcData) istrue , throw aTypeError exception. - Let srcByteIndex be srcByteOffset.
- Let targetByteIndex be 0.
- Let count be elementLength.
- Repeat, while count > 0
- Let value be
GetValueFromBuffer (srcData, srcByteIndex, srcType,true ,"Unordered"). - Perform
SetValueInBuffer (data, targetByteIndex, elementType, value,true ,"Unordered"). - Set srcByteIndex to srcByteIndex + srcElementSize.
- Set targetByteIndex to targetByteIndex + elementSize.
- Decrement count by 1.
- Let value be
- Let data be ?
- Set O.[[ViewedArrayBuffer]] to data.
- Set O.[[ByteLength]] to byteLength.
- Set O.[[ByteOffset]] to 0.
- Set O.[[ArrayLength]] to elementLength.
- Return O.
22.2.4.4 TypedArray ( object )
This description applies only if the TypedArray function is called with at least one argument and the Type of the first argument is Object and that object does not have either a [[TypedArrayName]] or an [[ArrayBufferData]] internal slot.
TypedArray called with argument object performs the following steps:
Assert :Type (object) is Object and object does not have either a [[TypedArrayName]] or an [[ArrayBufferData]] internal slot.- If NewTarget is
undefined , throw aTypeError exception. - Let constructorName be the String value of the
Constructor Name value specified inTable 56 for this TypedArrayconstructor . - Let O be ?
AllocateTypedArray (constructorName, NewTarget,"%TypedArrayPrototype%"). - Let usingIterator be ?
GetMethod (object, @@iterator). - If usingIterator is not
undefined , then- Let values be ?
IterableToList (object, usingIterator). - Let len be the number of elements in values.
- Perform ?
AllocateTypedArrayBuffer (O, len). - Let k be 0.
- Repeat, while k < len
Assert : values is now an emptyList .- Return O.
- Let values be ?
- NOTE: object is not an Iterable so assume it is already an
array-like object . - Let arrayLike be object.
- Let len be ?
ToLength (?Get (arrayLike,"length")). - Perform ?
AllocateTypedArrayBuffer (O, len). - Let k be 0.
- Repeat, while k < len
- Return O.
22.2.4.5 TypedArray ( buffer [ , byteOffset [ , length ] ] )
This description applies only if the TypedArray function is called with at least one argument and the Type of the first argument is Object and that object has an [[ArrayBufferData]] internal slot.
TypedArray called with at least one argument buffer performs the following steps:
Assert :Type (buffer) is Object and buffer has an [[ArrayBufferData]] internal slot.- If NewTarget is
undefined , throw aTypeError exception. - Let constructorName be the String value of the
Constructor Name value specified inTable 56 for this TypedArrayconstructor . - Let O be ?
AllocateTypedArray (constructorName, NewTarget,"%TypedArrayPrototype%"). - Let elementSize be the
Number value of the Element Size value inTable 56 for constructorName. - Let offset be ?
ToIndex (byteOffset). - If offset
modulo elementSize ≠ 0, throw aRangeError exception. - If length is present and length is not
undefined , then- Let newLength be ?
ToIndex (length).
- Let newLength be ?
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let bufferByteLength be buffer.[[ArrayBufferByteLength]].
- If length is either not present or
undefined , then- If bufferByteLength
modulo elementSize ≠ 0, throw aRangeError exception. - Let newByteLength be bufferByteLength - offset.
- If newByteLength < 0, throw a
RangeError exception.
- If bufferByteLength
- Else,
- Let newByteLength be newLength × elementSize.
- If offset+newByteLength > bufferByteLength, throw a
RangeError exception.
- Set O.[[ViewedArrayBuffer]] to buffer.
- Set O.[[ByteLength]] to newByteLength.
- Set O.[[ByteOffset]] to offset.
- Set O.[[ArrayLength]] to newByteLength / elementSize.
- Return O.
22.2.4.6 TypedArrayCreate ( constructor, argumentList )
The abstract operation TypedArrayCreate with arguments constructor and argumentList is used to specify the creation of a new TypedArray object using a
- Let newTypedArray be ?
Construct (constructor, argumentList). - Perform ?
ValidateTypedArray (newTypedArray). - If argumentList is a
List of a single Number, then- If newTypedArray.[[ArrayLength]] < argumentList[0], throw a
TypeError exception.
- If newTypedArray.[[ArrayLength]] < argumentList[0], throw a
- Return newTypedArray.
22.2.4.7 TypedArraySpeciesCreate ( exemplar, argumentList )
The abstract operation TypedArraySpeciesCreate with arguments exemplar and argumentList is used to specify the creation of a new TypedArray object using a
Assert : exemplar is an Object that has a [[TypedArrayName]] internal slot.- Let defaultConstructor be the intrinsic object listed in column one of
Table 56 for exemplar.[[TypedArrayName]]. - Let constructor be ?
SpeciesConstructor (exemplar, defaultConstructor). - Return ?
TypedArrayCreate (constructor, argumentList).
22.2.5 Properties of the TypedArray Constructors
Each TypedArray
- has a [[Prototype]] internal slot whose value is the intrinsic object
%TypedArray% . - has a
nameproperty whose value is the String value of theconstructor name specified for it inTable 56 . - has the following properties:
22.2.5.1 TypedArray.BYTES_PER_ELEMENT
The value of TypedArray.BYTES_PER_ELEMENT is the
This property has the attributes { [[Writable]]:
22.2.5.2 TypedArray.prototype
The initial value of TypedArray.prototype is the corresponding TypedArray prototype intrinsic object (
This property has the attributes { [[Writable]]:
22.2.6 Properties of the TypedArray Prototype Objects
Each TypedArray prototype object:
- has a [[Prototype]] internal slot whose value is the intrinsic object
%TypedArrayPrototype% . - is an ordinary object.
- does not have a [[ViewedArrayBuffer]] or any other of the internal slots that are specific to TypedArray instance objects.
22.2.6.1 TypedArray.prototype.BYTES_PER_ELEMENT
The value of TypedArray.prototype.BYTES_PER_ELEMENT is the
This property has the attributes { [[Writable]]:
22.2.6.2 TypedArray.prototype.constructor
The initial value of a TypedArray.prototype.constructor is the corresponding %TypedArray% intrinsic object.
22.2.7 Properties of TypedArray Instances
TypedArray instances are
23 Keyed Collections
23.1 Map Objects
Map objects are collections of key/value pairs where both the keys and values may be arbitrary ECMAScript language values. A distinct key value may only occur in one key/value pair within the Map's collection. Distinct key values are discriminated using the
Map object must be implemented using either hash tables or other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The data structures used in this Map objects specification is only intended to describe the required observable semantics of Map objects. It is not intended to be a viable implementation model.
23.1.1 The Map Constructor
The Map
- is the intrinsic object %Map%.
- is the initial value of the
Mapproperty of theglobal object . - creates and initializes a new Map object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value in an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedMapbehaviour must include asupercall to theMapconstructor to create and initialize the subclass instance with the internal state necessary to support theMap.prototypebuilt-in methods.
23.1.1.1 Map ( [ iterable ] )
When the Map function is called with optional argument, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - Let map be ?
OrdinaryCreateFromConstructor (NewTarget,"%MapPrototype%", « [[MapData]] »). - Set map.[[MapData]] to a new empty
List . - If iterable is not present, let iterable be
undefined . - If iterable is either
undefined ornull , return map. - Let adder be ?
Get (map,"set"). - If
IsCallable (adder) isfalse , throw aTypeError exception. - Let iteratorRecord be ?
GetIterator (iterable). - Repeat,
- Let next be ?
IteratorStep (iteratorRecord). - If next is
false , return map. - Let nextItem be ?
IteratorValue (next). - If
Type (nextItem) is not Object, then- Let error be
ThrowCompletion (a newly createdTypeError object). - Return ?
IteratorClose (iteratorRecord, error).
- Let error be
- Let k be
Get (nextItem,"0"). - If k is an
abrupt completion , return ?IteratorClose (iteratorRecord, k). - Let v be
Get (nextItem,"1"). - If v is an
abrupt completion , return ?IteratorClose (iteratorRecord, v). - Let status be
Call (adder, map, « k.[[Value]], v.[[Value]] »). - If status is an
abrupt completion , return ?IteratorClose (iteratorRecord, status).
- Let next be ?
If the parameter iterable is present, it is expected to be an object that implements an @@iterator method that returns an iterator object that produces a two element
23.1.2 Properties of the Map Constructor
The Map
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
23.1.2.1 Map.prototype
The initial value of Map.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
23.1.2.2 get Map [ @@species ]
Map[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
Methods that create derived collection objects should call @@species to determine the
23.1.3 Properties of the Map Prototype Object
The Map prototype object:
- is the intrinsic object %MapPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[MapData]] internal slot.
23.1.3.1 Map.prototype.clear ( )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[MapData]]. - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- Set p.[[Key]] to
empty . - Set p.[[Value]] to
empty .
- Set p.[[Key]] to
- Return
undefined .
23.1.3.2 Map.prototype.constructor
The initial value of Map.prototype.constructor is the intrinsic object
23.1.3.3 Map.prototype.delete ( key )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[MapData]]. - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValueZero (p.[[Key]], key) istrue , then- Set p.[[Key]] to
empty . - Set p.[[Value]] to
empty . - Return
true .
- Set p.[[Key]] to
- If p.[[Key]] is not
- Return
false .
The value
23.1.3.4 Map.prototype.entries ( )
The following steps are taken:
- Let M be the
this value. - Return ?
CreateMapIterator (M,"key+value").
23.1.3.5 Map.prototype.forEach ( callbackfn [ , thisArg ] )
When the forEach method is called with one or two arguments, the following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let entries be the
List that is M.[[MapData]]. - For each
Record { [[Key]], [[Value]] } e that is an element of entries, in original key insertion order, do- If e.[[Key]] is not
empty , then- Perform ?
Call (callbackfn, T, « e.[[Value]], e.[[Key]], M »).
- Perform ?
- If e.[[Key]] is not
- Return
undefined .
callbackfn should be a function that accepts three arguments. forEach calls callbackfn once for each key/value pair present in the map object, in key insertion order. callbackfn is called only for keys of the map which actually exist; it is not called for keys that have been deleted from the map.
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the value of the item, the key of the item, and the Map object being traversed.
forEach does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn. Each entry of a map's [[MapData]] is only visited once. New keys added after the call to forEach begins are visited. A key will be revisited if it is deleted after it has been visited and then re-added before the forEach call completes. Keys that are deleted after the call to forEach begins and before being visited are not visited unless the key is added again before the forEach call completes.
23.1.3.6 Map.prototype.get ( key )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[MapData]]. - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValueZero (p.[[Key]], key) istrue , return p.[[Value]].
- If p.[[Key]] is not
- Return
undefined .
23.1.3.7 Map.prototype.has ( key )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[MapData]]. - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValueZero (p.[[Key]], key) istrue , returntrue .
- If p.[[Key]] is not
- Return
false .
23.1.3.8 Map.prototype.keys ( )
The following steps are taken:
- Let M be the
this value. - Return ?
CreateMapIterator (M,"key").
23.1.3.9 Map.prototype.set ( key, value )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[MapData]]. - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValueZero (p.[[Key]], key) istrue , then- Set p.[[Value]] to value.
- Return M.
- If p.[[Key]] is not
- If key is
-0 , let key be+0 . - Let p be the
Record { [[Key]]: key, [[Value]]: value }. - Append p as the last element of entries.
- Return M.
23.1.3.10 get Map.prototype.size
Map.prototype.size is an
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[MapData]]. - Let count be 0.
- For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty , set count to count+1.
- If p.[[Key]] is not
- Return count.
23.1.3.11 Map.prototype.values ( )
The following steps are taken:
- Let M be the
this value. - Return ?
CreateMapIterator (M,"value").
23.1.3.12 Map.prototype [ @@iterator ] ( )
The initial value of the @@iterator property is the same entries property.
23.1.3.13 Map.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Map".
This property has the attributes { [[Writable]]:
23.1.4 Properties of Map Instances
Map instances are ordinary objects that inherit properties from the Map prototype. Map instances also have a [[MapData]] internal slot.
23.1.5 Map Iterator Objects
A Map Iterator is an object, that represents a specific iteration over some specific Map instance object. There is not a named
23.1.5.1 CreateMapIterator ( map, kind )
Several methods of Map objects return Iterator objects. The abstract operation CreateMapIterator with arguments map and kind is used to create such iterator objects. It performs the following steps:
- If
Type (map) is not Object, throw aTypeError exception. - If map does not have a [[MapData]] internal slot, throw a
TypeError exception. - Let iterator be
ObjectCreate (%MapIteratorPrototype% , « [[Map]], [[MapNextIndex]], [[MapIterationKind]] »). - Set iterator.[[Map]] to map.
- Set iterator.[[MapNextIndex]] to 0.
- Set iterator.[[MapIterationKind]] to kind.
- Return iterator.
23.1.5.2 The %MapIteratorPrototype% Object
The %MapIteratorPrototype% object:
- has properties that are inherited by all Map Iterator Objects.
- is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%IteratorPrototype% . - has the following properties:
23.1.5.2.1 %MapIteratorPrototype%.next ( )
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have all of the internal slots of a Map Iterator Instance (
23.1.5.3 ), throw aTypeError exception. - Let m be O.[[Map]].
- Let index be O.[[MapNextIndex]].
- Let itemKind be O.[[MapIterationKind]].
- If m is
undefined , returnCreateIterResultObject (undefined ,true ). Assert : m has a [[MapData]] internal slot.- Let entries be the
List that is m.[[MapData]]. - Let numEntries be the number of elements of entries.
- NOTE: numEntries must be redetermined each time this method is evaluated.
- Repeat, while index is less than numEntries,
- Let e be the
Record { [[Key]], [[Value]] } that is the value of entries[index]. - Set index to index+1.
- Set O.[[MapNextIndex]] to index.
- If e.[[Key]] is not
empty , then- If itemKind is
"key", let result be e.[[Key]]. - Else if itemKind is
"value", let result be e.[[Value]]. - Else,
Assert : itemKind is"key+value".- Let result be
CreateArrayFromList (« e.[[Key]], e.[[Value]] »).
- Return
CreateIterResultObject (result,false ).
- If itemKind is
- Let e be the
- Set O.[[Map]] to
undefined . - Return
CreateIterResultObject (undefined ,true ).
23.1.5.2.2 %MapIteratorPrototype% [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Map Iterator".
This property has the attributes { [[Writable]]:
23.1.5.3 Properties of Map Iterator Instances
Map Iterator instances are ordinary objects that inherit properties from the
| Internal Slot | Description |
|---|---|
| [[Map]] | The Map object that is being iterated. |
| [[MapNextIndex]] |
The |
| [[MapIterationKind]] |
A String value that identifies what is to be returned for each element of the iteration. The possible values are: "key", "value", "key+value".
|
23.2 Set Objects
Set objects are collections of ECMAScript language values. A distinct value may only occur once as an element of a Set's collection. Distinct values are discriminated using the
Set objects must be implemented using either hash tables or other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The data structures used in this Set objects specification is only intended to describe the required observable semantics of Set objects. It is not intended to be a viable implementation model.
23.2.1 The Set Constructor
The Set
- is the intrinsic object %Set%.
- is the initial value of the
Setproperty of theglobal object . - creates and initializes a new Set object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value in an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedSetbehaviour must include asupercall to theSetconstructor to create and initialize the subclass instance with the internal state necessary to support theSet.prototypebuilt-in methods.
23.2.1.1 Set ( [ iterable ] )
When the Set function is called with optional argument iterable, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - Let set be ?
OrdinaryCreateFromConstructor (NewTarget,"%SetPrototype%", « [[SetData]] »). - Set set.[[SetData]] to a new empty
List . - If iterable is not present, let iterable be
undefined . - If iterable is either
undefined ornull , return set. - Let adder be ?
Get (set,"add"). - If
IsCallable (adder) isfalse , throw aTypeError exception. - Let iteratorRecord be ?
GetIterator (iterable). - Repeat,
- Let next be ?
IteratorStep (iteratorRecord). - If next is
false , return set. - Let nextValue be ?
IteratorValue (next). - Let status be
Call (adder, set, « nextValue.[[Value]] »). - If status is an
abrupt completion , return ?IteratorClose (iteratorRecord, status).
- Let next be ?
23.2.2 Properties of the Set Constructor
The Set
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
23.2.2.1 Set.prototype
The initial value of Set.prototype is the intrinsic
This property has the attributes { [[Writable]]:
23.2.2.2 get Set [ @@species ]
Set[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
Methods that create derived collection objects should call @@species to determine the
23.2.3 Properties of the Set Prototype Object
The Set prototype object:
- is the intrinsic object %SetPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[SetData]] internal slot.
23.2.3.1 Set.prototype.add ( value )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[SetData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is S.[[SetData]]. - For each e that is an element of entries, do
- If e is not
empty andSameValueZero (e, value) istrue , then- Return S.
- If e is not
- If value is
-0 , let value be+0 . - Append value as the last element of entries.
- Return S.
23.2.3.2 Set.prototype.clear ( )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[SetData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is S.[[SetData]]. - For each e that is an element of entries, do
- Replace the element of entries whose value is e with an element whose value is
empty .
- Replace the element of entries whose value is e with an element whose value is
- Return
undefined .
23.2.3.3 Set.prototype.constructor
The initial value of Set.prototype.constructor is the intrinsic object
23.2.3.4 Set.prototype.delete ( value )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[SetData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is S.[[SetData]]. - For each e that is an element of entries, do
- If e is not
empty andSameValueZero (e, value) istrue , then- Replace the element of entries whose value is e with an element whose value is
empty . - Return
true .
- Replace the element of entries whose value is e with an element whose value is
- If e is not
- Return
false .
The value
23.2.3.5 Set.prototype.entries ( )
The following steps are taken:
- Let S be the
this value. - Return ?
CreateSetIterator (S,"key+value").
For iteration purposes, a Set appears similar to a Map where each entry has the same value for its key and value.
23.2.3.6 Set.prototype.forEach ( callbackfn [ , thisArg ] )
When the forEach method is called with one or two arguments, the following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[SetData]] internal slot, throw a
TypeError exception. - If
IsCallable (callbackfn) isfalse , throw aTypeError exception. - If thisArg is present, let T be thisArg; else let T be
undefined . - Let entries be the
List that is S.[[SetData]]. - For each e that is an element of entries, in original insertion order, do
- If e is not
empty , then- Perform ?
Call (callbackfn, T, « e, e, S »).
- Perform ?
- If e is not
- Return
undefined .
callbackfn should be a function that accepts three arguments. forEach calls callbackfn once for each value present in the set object, in value insertion order. callbackfn is called only for values of the Set which actually exist; it is not called for keys that have been deleted from the set.
If a thisArg parameter is provided, it will be used as the
callbackfn is called with three arguments: the first two arguments are a value contained in the Set. The same value is passed for both arguments. The Set object being traversed is passed as the third argument.
The callbackfn is called with three arguments to be consistent with the call back functions used by forEach methods for Map and Array. For Sets, each item value is considered to be both the key and the value.
forEach does not directly mutate the object on which it is called but the object may be mutated by the calls to callbackfn.
Each value is normally visited only once. However, a value will be revisited if it is deleted after it has been visited and then re-added before the forEach call completes. Values that are deleted after the call to forEach begins and before being visited are not visited unless the value is added again before the forEach call completes. New values added after the call to forEach begins are visited.
23.2.3.7 Set.prototype.has ( value )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[SetData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is S.[[SetData]]. - For each e that is an element of entries, do
- If e is not
empty andSameValueZero (e, value) istrue , returntrue .
- If e is not
- Return
false .
23.2.3.8 Set.prototype.keys ( )
The initial value of the keys property is the same values property.
For iteration purposes, a Set appears similar to a Map where each entry has the same value for its key and value.
23.2.3.9 get Set.prototype.size
Set.prototype.size is an
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[SetData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is S.[[SetData]]. - Let count be 0.
- For each e that is an element of entries, do
- If e is not
empty , set count to count+1.
- If e is not
- Return count.
23.2.3.10 Set.prototype.values ( )
The following steps are taken:
- Let S be the
this value. - Return ?
CreateSetIterator (S,"value").
23.2.3.11 Set.prototype [ @@iterator ] ( )
The initial value of the @@iterator property is the same values property.
23.2.3.12 Set.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Set".
This property has the attributes { [[Writable]]:
23.2.4 Properties of Set Instances
Set instances are ordinary objects that inherit properties from the Set prototype. Set instances also have a [[SetData]] internal slot.
23.2.5 Set Iterator Objects
A Set Iterator is an ordinary object, with the structure defined below, that represents a specific iteration over some specific Set instance object. There is not a named
23.2.5.1 CreateSetIterator ( set, kind )
Several methods of Set objects return Iterator objects. The abstract operation CreateSetIterator with arguments set and kind is used to create such iterator objects. It performs the following steps:
- If
Type (set) is not Object, throw aTypeError exception. - If set does not have a [[SetData]] internal slot, throw a
TypeError exception. - Let iterator be
ObjectCreate (%SetIteratorPrototype% , « [[IteratedSet]], [[SetNextIndex]], [[SetIterationKind]] »). - Set iterator.[[IteratedSet]] to set.
- Set iterator.[[SetNextIndex]] to 0.
- Set iterator.[[SetIterationKind]] to kind.
- Return iterator.
23.2.5.2 The %SetIteratorPrototype% Object
The %SetIteratorPrototype% object:
- has properties that are inherited by all Set Iterator Objects.
- is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%IteratorPrototype% . - has the following properties:
23.2.5.2.1 %SetIteratorPrototype%.next ( )
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have all of the internal slots of a Set Iterator Instance (
23.2.5.3 ), throw aTypeError exception. - Let s be O.[[IteratedSet]].
- Let index be O.[[SetNextIndex]].
- Let itemKind be O.[[SetIterationKind]].
- If s is
undefined , returnCreateIterResultObject (undefined ,true ). Assert : s has a [[SetData]] internal slot.- Let entries be the
List that is s.[[SetData]]. - Let numEntries be the number of elements of entries.
- NOTE: numEntries must be redetermined each time this method is evaluated.
- Repeat, while index is less than numEntries,
- Let e be entries[index].
- Set index to index+1.
- Set O.[[SetNextIndex]] to index.
- If e is not
empty , then- If itemKind is
"key+value", then- Return
CreateIterResultObject (CreateArrayFromList (« e, e »),false ).
- Return
- Return
CreateIterResultObject (e,false ).
- If itemKind is
- Set O.[[IteratedSet]] to
undefined . - Return
CreateIterResultObject (undefined ,true ).
23.2.5.2.2 %SetIteratorPrototype% [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Set Iterator".
This property has the attributes { [[Writable]]:
23.2.5.3 Properties of Set Iterator Instances
Set Iterator instances are ordinary objects that inherit properties from the
| Internal Slot | Description |
|---|---|
| [[IteratedSet]] | The Set object that is being iterated. |
| [[SetNextIndex]] |
The |
| [[SetIterationKind]] |
A String value that identifies what is to be returned for each element of the iteration. The possible values are: "key", "value", "key+value". "key" and "value" have the same meaning.
|
23.3 WeakMap Objects
WeakMap objects are collections of key/value pairs where the keys are objects and values may be arbitrary ECMAScript language values. A WeakMap may be queried to see if it contains a key/value pair with a specific key, but no mechanism is provided for enumerating the objects it holds as keys. If an object that is being used as the key of a WeakMap key/value pair is only reachable by following a chain of references that start within that WeakMap, then that key/value pair is inaccessible and is automatically removed from the WeakMap. WeakMap implementations must detect and remove such key/value pairs and any associated resources.
An implementation may impose an arbitrarily determined latency between the time a key/value pair of a WeakMap becomes inaccessible and the time when the key/value pair is removed from the WeakMap. If this latency was observable to ECMAScript program, it would be a source of indeterminacy that could impact program execution. For that reason, an ECMAScript implementation must not provide any means to observe a key of a WeakMap that does not require the observer to present the observed key.
WeakMap objects must be implemented using either hash tables or other mechanisms that, on average, provide access times that are sublinear on the number of key/value pairs in the collection. The data structure used in this WeakMap objects specification are only intended to describe the required observable semantics of WeakMap objects. It is not intended to be a viable implementation model.
WeakMap and WeakSets are intended to provide mechanisms for dynamically associating state with an object in a manner that does not “leak” memory resources if, in the absence of the WeakMap or WeakSet, the object otherwise became inaccessible and subject to resource reclamation by the implementation's garbage collection mechanisms. This characteristic can be achieved by using an inverted per-object mapping of weak map instances to keys. Alternatively each weak map may internally store its key to value mappings but this approach requires coordination between the WeakMap or WeakSet implementation and the garbage collector. The following references describe mechanism that may be useful to implementations of WeakMap and WeakSets:
Barry Hayes. 1997. Ephemerons: a new finalization mechanism. In Proceedings of the 12th ACM SIGPLAN conference on Object-oriented programming, systems, languages, and applications (OOPSLA '97), A. Michael Berman (Ed.). ACM, New York, NY, USA, 176-183, http://doi.acm.org/10.1145/263698.263733.
Alexandra Barros, Roberto Ierusalimschy, Eliminating Cycles in Weak Tables. Journal of Universal Computer Science - J.UCS, vol. 14, no. 21, pp. 3481-3497, 2008, http://www.jucs.org/jucs_14_21/eliminating_cycles_in_weak
23.3.1 The WeakMap Constructor
The WeakMap
- is the intrinsic object %WeakMap%.
- is the initial value of the
WeakMapproperty of theglobal object . - creates and initializes a new WeakMap object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value in an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedWeakMapbehaviour must include asupercall to theWeakMapconstructor to create and initialize the subclass instance with the internal state necessary to support theWeakMap.prototypebuilt-in methods.
23.3.1.1 WeakMap ( [ iterable ] )
When the WeakMap function is called with optional argument iterable, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - Let map be ?
OrdinaryCreateFromConstructor (NewTarget,"%WeakMapPrototype%", « [[WeakMapData]] »). - Set map.[[WeakMapData]] to a new empty
List . - If iterable is not present, let iterable be
undefined . - If iterable is either
undefined ornull , return map. - Let adder be ?
Get (map,"set"). - If
IsCallable (adder) isfalse , throw aTypeError exception. - Let iteratorRecord be ?
GetIterator (iterable). - Repeat,
- Let next be ?
IteratorStep (iterRecord). - If next is
false , return map. - Let nextItem be ?
IteratorValue (next). - If
Type (nextItem) is not Object, then- Let error be
ThrowCompletion (a newly createdTypeError object). - Return ?
IteratorClose (iteratorRecord, error).
- Let error be
- Let k be
Get (nextItem,"0"). - If k is an
abrupt completion , return ?IteratorClose (iteratorRecord, k). - Let v be
Get (nextItem,"1"). - If v is an
abrupt completion , return ?IteratorClose (iteratorRecord, v). - Let status be
Call (adder, map, « k.[[Value]], v.[[Value]] »). - If status is an
abrupt completion , return ?IteratorClose (iteratorRecord, status).
- Let next be ?
If the parameter iterable is present, it is expected to be an object that implements an @@iterator method that returns an iterator object that produces a two element
23.3.2 Properties of the WeakMap Constructor
The WeakMap
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
23.3.2.1 WeakMap.prototype
The initial value of WeakMap.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
23.3.3 Properties of the WeakMap Prototype Object
The WeakMap prototype object:
- is the intrinsic object %WeakMapPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[WeakMapData]] internal slot.
23.3.3.1 WeakMap.prototype.constructor
The initial value of WeakMap.prototype.constructor is the intrinsic object
23.3.3.2 WeakMap.prototype.delete ( key )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[WeakMapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[WeakMapData]]. - If
Type (key) is not Object, returnfalse . - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValue (p.[[Key]], key) istrue , then- Set p.[[Key]] to
empty . - Set p.[[Value]] to
empty . - Return
true .
- Set p.[[Key]] to
- If p.[[Key]] is not
- Return
false .
The value
23.3.3.3 WeakMap.prototype.get ( key )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[WeakMapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[WeakMapData]]. - If
Type (key) is not Object, returnundefined . - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValue (p.[[Key]], key) istrue , return p.[[Value]].
- If p.[[Key]] is not
- Return
undefined .
23.3.3.4 WeakMap.prototype.has ( key )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[WeakMapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[WeakMapData]]. - If
Type (key) is not Object, returnfalse . - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValue (p.[[Key]], key) istrue , returntrue .
- If p.[[Key]] is not
- Return
false .
23.3.3.5 WeakMap.prototype.set ( key, value )
The following steps are taken:
- Let M be the
this value. - If
Type (M) is not Object, throw aTypeError exception. - If M does not have a [[WeakMapData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is M.[[WeakMapData]]. - If
Type (key) is not Object, throw aTypeError exception. - For each
Record { [[Key]], [[Value]] } p that is an element of entries, do- If p.[[Key]] is not
empty andSameValue (p.[[Key]], key) istrue , then- Set p.[[Value]] to value.
- Return M.
- If p.[[Key]] is not
- Let p be the
Record { [[Key]]: key, [[Value]]: value }. - Append p as the last element of entries.
- Return M.
23.3.3.6 WeakMap.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "WeakMap".
This property has the attributes { [[Writable]]:
23.3.4 Properties of WeakMap Instances
WeakMap instances are ordinary objects that inherit properties from the WeakMap prototype. WeakMap instances also have a [[WeakMapData]] internal slot.
23.4 WeakSet Objects
WeakSet objects are collections of objects. A distinct object may only occur once as an element of a WeakSet's collection. A WeakSet may be queried to see if it contains a specific object, but no mechanism is provided for enumerating the objects it holds. If an object that is contained by a WeakSet is only reachable by following a chain of references that start within that WeakSet, then that object is inaccessible and is automatically removed from the WeakSet. WeakSet implementations must detect and remove such objects and any associated resources.
An implementation may impose an arbitrarily determined latency between the time an object contained in a WeakSet becomes inaccessible and the time when the object is removed from the WeakSet. If this latency was observable to ECMAScript program, it would be a source of indeterminacy that could impact program execution. For that reason, an ECMAScript implementation must not provide any means to determine if a WeakSet contains a particular object that does not require the observer to present the observed object.
WeakSet objects must be implemented using either hash tables or other mechanisms that, on average, provide access times that are sublinear on the number of elements in the collection. The data structure used in this WeakSet objects specification is only intended to describe the required observable semantics of WeakSet objects. It is not intended to be a viable implementation model.
See the NOTE in
23.4.1 The WeakSet Constructor
The WeakSet
- is the intrinsic object %WeakSet%.
- is the initial value of the
WeakSetproperty of theglobal object . - creates and initializes a new WeakSet object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value in an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedWeakSetbehaviour must include asupercall to theWeakSetconstructor to create and initialize the subclass instance with the internal state necessary to support theWeakSet.prototypebuilt-in methods.
23.4.1.1 WeakSet ( [ iterable ] )
When the WeakSet function is called with optional argument iterable, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - Let set be ?
OrdinaryCreateFromConstructor (NewTarget,"%WeakSetPrototype%", « [[WeakSetData]] »). - Set set.[[WeakSetData]] to a new empty
List . - If iterable is not present, let iterable be
undefined . - If iterable is either
undefined ornull , return set. - Let adder be ?
Get (set,"add"). - If
IsCallable (adder) isfalse , throw aTypeError exception. - Let iteratorRecord be ?
GetIterator (iterable). - Repeat,
- Let next be ?
IteratorStep (iteratorRecord). - If next is
false , return set. - Let nextValue be ?
IteratorValue (next). - Let status be
Call (adder, set, « nextValue »). - If status is an
abrupt completion , return ?IteratorClose (iteratorRecord, status).
- Let next be ?
23.4.2 Properties of the WeakSet Constructor
The WeakSet
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
23.4.2.1 WeakSet.prototype
The initial value of WeakSet.prototype is the intrinsic
This property has the attributes { [[Writable]]:
23.4.3 Properties of the WeakSet Prototype Object
The WeakSet prototype object:
- is the intrinsic object %WeakSetPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[WeakSetData]] internal slot.
23.4.3.1 WeakSet.prototype.add ( value )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[WeakSetData]] internal slot, throw a
TypeError exception. - If
Type (value) is not Object, throw aTypeError exception. - Let entries be the
List that is S.[[WeakSetData]]. - For each e that is an element of entries, do
- If e is not
empty andSameValue (e, value) istrue , then- Return S.
- If e is not
- Append value as the last element of entries.
- Return S.
23.4.3.2 WeakSet.prototype.constructor
The initial value of WeakSet.prototype.constructor is the
23.4.3.3 WeakSet.prototype.delete ( value )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[WeakSetData]] internal slot, throw a
TypeError exception. - If
Type (value) is not Object, returnfalse . - Let entries be the
List that is S.[[WeakSetData]]. - For each e that is an element of entries, do
- If e is not
empty andSameValue (e, value) istrue , then- Replace the element of entries whose value is e with an element whose value is
empty . - Return
true .
- Replace the element of entries whose value is e with an element whose value is
- If e is not
- Return
false .
The value
23.4.3.4 WeakSet.prototype.has ( value )
The following steps are taken:
- Let S be the
this value. - If
Type (S) is not Object, throw aTypeError exception. - If S does not have a [[WeakSetData]] internal slot, throw a
TypeError exception. - Let entries be the
List that is S.[[WeakSetData]]. - If
Type (value) is not Object, returnfalse . - For each e that is an element of entries, do
- If e is not
empty andSameValue (e, value) istrue , returntrue .
- If e is not
- Return
false .
23.4.3.5 WeakSet.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "WeakSet".
This property has the attributes { [[Writable]]:
23.4.4 Properties of WeakSet Instances
WeakSet instances are ordinary objects that inherit properties from the WeakSet prototype. WeakSet instances also have a [[WeakSetData]] internal slot.
24 Structured Data
24.1 ArrayBuffer Objects
24.1.1 Abstract Operations For ArrayBuffer Objects
24.1.1.1 AllocateArrayBuffer ( constructor, byteLength )
The abstract operation AllocateArrayBuffer with arguments constructor and byteLength is used to create an ArrayBuffer object. It performs the following steps:
- Let obj be ?
OrdinaryCreateFromConstructor (constructor,"%ArrayBufferPrototype%", « [[ArrayBufferData]], [[ArrayBufferByteLength]] »). Assert : byteLength is aninteger value ≥ 0.- Let block be ?
CreateByteDataBlock (byteLength). - Set obj.[[ArrayBufferData]] to block.
- Set obj.[[ArrayBufferByteLength]] to byteLength.
- Return obj.
24.1.1.2 IsDetachedBuffer ( arrayBuffer )
The abstract operation IsDetachedBuffer with argument arrayBuffer performs the following steps:
24.1.1.3 DetachArrayBuffer ( arrayBuffer )
The abstract operation DetachArrayBuffer with argument arrayBuffer performs the following steps:
Assert :Type (arrayBuffer) is Object and it has [[ArrayBufferData]] and [[ArrayBufferByteLength]] internal slots.Assert :IsSharedArrayBuffer (arrayBuffer) isfalse .- Set arrayBuffer.[[ArrayBufferData]] to
null . - Set arrayBuffer.[[ArrayBufferByteLength]] to 0.
- Return
NormalCompletion (null ).
Detaching an ArrayBuffer instance disassociates the
24.1.1.4 CloneArrayBuffer ( srcBuffer, srcByteOffset, srcLength, cloneConstructor )
The abstract operation CloneArrayBuffer takes four parameters, an ArrayBuffer srcBuffer, an
Assert :Type (srcBuffer) is Object and it has an [[ArrayBufferData]] internal slot.Assert :IsConstructor (cloneConstructor) istrue .- Let targetBuffer be ?
AllocateArrayBuffer (cloneConstructor, srcLength). - If
IsDetachedBuffer (srcBuffer) istrue , throw aTypeError exception. - Let srcBlock be srcBuffer.[[ArrayBufferData]].
- Let targetBlock be targetBuffer.[[ArrayBufferData]].
- Perform
CopyDataBlockBytes (targetBlock, 0, srcBlock, srcByteOffset, srcLength). - Return targetBuffer.
24.1.1.5 RawBytesToNumber ( type, rawBytes, isLittleEndian )
The abstract operation RawBytesToNumber takes three parameters, a String type, a
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for Element Type type. - If isLittleEndian is
false , reverse the order of the elements of rawBytes. - If type is
"Float32", then- Let value be the byte elements of rawBytes concatenated and interpreted as a little-endian bit string encoding of an IEEE 754-2008 binary32 value.
- If value is an IEEE 754-2008 binary32 NaN value, return the
NaN Number value . - Return the
Number value that corresponds to value.
- If type is
"Float64", then- Let value be the byte elements of rawBytes concatenated and interpreted as a little-endian bit string encoding of an IEEE 754-2008 binary64 value.
- If value is an IEEE 754-2008 binary64 NaN value, return the
NaN Number value . - Return the
Number value that corresponds to value.
- If the first code unit of type is the code unit 0x0055 (LATIN CAPITAL LETTER U), then
- Let intValue be the byte elements of rawBytes concatenated and interpreted as a bit string encoding of an unsigned little-endian binary number.
- Else,
- Let intValue be the byte elements of rawBytes concatenated and interpreted as a bit string encoding of a binary little-endian 2's complement number of bit length elementSize × 8.
- Return the
Number value that corresponds to intValue.
24.1.1.6 GetValueFromBuffer ( arrayBuffer, byteIndex, type, isTypedArray, order [ , isLittleEndian ] )
The abstract operation GetValueFromBuffer takes six parameters, an ArrayBuffer or SharedArrayBuffer arrayBuffer, an
Assert :IsDetachedBuffer (arrayBuffer) isfalse .Assert : There are sufficient bytes in arrayBuffer starting at byteIndex to represent a value of type.Assert : byteIndex is aninteger value ≥ 0.- Let block be arrayBuffer.[[ArrayBufferData]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for Element Type type. - If
IsSharedArrayBuffer (arrayBuffer) istrue , then- Let execution be the [[CandidateExecution]] field of the
surrounding agent 'sAgent Record . - Let eventList be the [[EventList]] field of the element in execution.[[EventLists]] whose [[AgentSignifier]] is
AgentSignifier (). - If isTypedArray is
true and type is"Int8","Uint8","Int16","Uint16","Int32", or"Uint32", let noTear betrue ; otherwise let noTear befalse . - Let rawValue be a
List of length elementSize of nondeterministically chosen byte values. - NOTE: In implementations, rawValue is the result of a non-atomic or atomic read instruction on the underlying hardware. The nondeterminism is a semantic prescription of the
memory model to describe observable behaviour of hardware with weak consistency. - Let readEvent be
ReadSharedMemory { [[Order]]: order, [[NoTear]]: noTear, [[Block]]: block, [[ByteIndex]]: byteIndex, [[ElementSize]]: elementSize }. - Append readEvent to eventList.
- Append
Chosen Value Record { [[Event]]: readEvent, [[ChosenValue]]: rawValue } to execution.[[ChosenValues]].
- Let execution be the [[CandidateExecution]] field of the
- Else, let rawValue be a
List of elementSize containing, in order, the elementSize sequence of bytes starting with block[byteIndex]. - If isLittleEndian is not present, set isLittleEndian to the value of the [[LittleEndian]] field of the
surrounding agent 'sAgent Record . - Return
RawBytesToNumber (type, rawValue, isLittleEndian).
24.1.1.7 NumberToRawBytes ( type, value, isLittleEndian )
The abstract operation NumberToRawBytes takes three parameters, a String type, a Number value, and a Boolean isLittleEndian. This operation performs the following steps:
- If type is
"Float32", then- Let rawBytes be a
List containing the 4 bytes that are the result of converting value to IEEE 754-2008 binary32 format using “Round to nearest, ties to even” rounding mode. If isLittleEndian isfalse , the bytes are arranged in big endian order. Otherwise, the bytes are arranged in little endian order. If value isNaN , rawBytes may be set to any implementation chosen IEEE 754-2008 binary32 format Not-a-Number encoding. An implementation must always choose the same encoding for each implementation distinguishableNaN value.
- Let rawBytes be a
- Else if type is
"Float64", then- Let rawBytes be a
List containing the 8 bytes that are the IEEE 754-2008 binary64 format encoding of value. If isLittleEndian isfalse , the bytes are arranged in big endian order. Otherwise, the bytes are arranged in little endian order. If value isNaN , rawBytes may be set to any implementation chosen IEEE 754-2008 binary64 format Not-a-Number encoding. An implementation must always choose the same encoding for each implementation distinguishableNaN value.
- Let rawBytes be a
- Else,
- Let n be the
Number value of the Element Size specified inTable 56 for Element Type type. - Let convOp be the abstract operation named in the Conversion Operation column in
Table 56 for Element Type type. - Let intValue be convOp(value).
- If intValue ≥ 0, then
- Let rawBytes be a
List containing the n-byte binary encoding of intValue. If isLittleEndian isfalse , the bytes are ordered in big endian order. Otherwise, the bytes are ordered in little endian order.
- Let rawBytes be a
- Else,
- Let rawBytes be a
List containing the n-byte binary 2's complement encoding of intValue. If isLittleEndian isfalse , the bytes are ordered in big endian order. Otherwise, the bytes are ordered in little endian order.
- Let rawBytes be a
- Let n be the
- Return rawBytes.
24.1.1.8 SetValueInBuffer ( arrayBuffer, byteIndex, type, value, isTypedArray, order [ , isLittleEndian ] )
The abstract operation SetValueInBuffer takes seven parameters, an ArrayBuffer or SharedArrayBuffer arrayBuffer, an
Assert :IsDetachedBuffer (arrayBuffer) isfalse .Assert : There are sufficient bytes in arrayBuffer starting at byteIndex to represent a value of type.Assert : byteIndex is aninteger value ≥ 0.Assert :Type (value) is Number.- Let block be arrayBuffer.[[ArrayBufferData]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for Element Type type. - If isLittleEndian is not present, set isLittleEndian to the value of the [[LittleEndian]] field of the
surrounding agent 'sAgent Record . - Let rawBytes be
NumberToRawBytes (type, value, isLittleEndian). - If
IsSharedArrayBuffer (arrayBuffer) istrue , then- Let execution be the [[CandidateExecution]] field of the
surrounding agent 'sAgent Record . - Let eventList be the [[EventList]] field of the element in execution.[[EventLists]] whose [[AgentSignifier]] is
AgentSignifier (). - If isTypedArray is
true and type is"Int8","Uint8","Int16","Uint16","Int32", or"Uint32", let noTear betrue ; otherwise let noTear befalse . - Append
WriteSharedMemory { [[Order]]: order, [[NoTear]]: noTear, [[Block]]: block, [[ByteIndex]]: byteIndex, [[ElementSize]]: elementSize, [[Payload]]: rawBytes } to eventList.
- Let execution be the [[CandidateExecution]] field of the
- Else, store the individual bytes of rawBytes into block, in order, starting at block[byteIndex].
- Return
NormalCompletion (undefined ).
24.1.1.9 GetModifySetValueInBuffer ( arrayBuffer, byteIndex, type, value, op [ , isLittleEndian ] )
The abstract operation GetModifySetValueInBuffer takes six parameters, a SharedArrayBuffer arrayBuffer, a nonnegative
Assert :IsSharedArrayBuffer (arrayBuffer) istrue .Assert : There are sufficient bytes in arrayBuffer starting at byteIndex to represent a value of type.Assert : byteIndex is aninteger value ≥ 0.Assert :Type (value) is Number.- Let block be arrayBuffer.[[ArrayBufferData]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for Element Type type. - If isLittleEndian is not present, set isLittleEndian to the value of the [[LittleEndian]] field of the
surrounding agent 'sAgent Record . - Let rawBytes be
NumberToRawBytes (type, value, isLittleEndian). - Let execution be the [[CandidateExecution]] field of the
surrounding agent 'sAgent Record . - Let eventList be the [[EventList]] field of the element in execution.[[EventLists]] whose [[AgentSignifier]] is
AgentSignifier (). - Let rawBytesRead be a
List of length elementSize of nondeterministically chosen byte values. - NOTE: In implementations, rawBytesRead is the result of a load-link, of a load-exclusive, or of an operand of a read-modify-write instruction on the underlying hardware. The nondeterminism is a semantic prescription of the
memory model to describe observable behaviour of hardware with weak consistency. - Let rmwEvent be
ReadModifyWriteSharedMemory { [[Order]]:"SeqCst", [[NoTear]]:true , [[Block]]: block, [[ByteIndex]]: byteIndex, [[ElementSize]]: elementSize, [[Payload]]: rawBytes, [[ModifyOp]]: op }. - Append rmwEvent to eventList.
- Append
Chosen Value Record { [[Event]]: rmwEvent, [[ChosenValue]]: rawBytesRead } to execution.[[ChosenValues]]. - Return
RawBytesToNumber (type, rawBytesRead, isLittleEndian).
24.1.2 The ArrayBuffer Constructor
The ArrayBuffer
- is the intrinsic object %ArrayBuffer%.
- is the initial value of the
ArrayBufferproperty of theglobal object . - creates and initializes a new ArrayBuffer object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedArrayBufferbehaviour must include asupercall to theArrayBufferconstructor to create and initialize subclass instances with the internal state necessary to support theArrayBuffer.prototypebuilt-in methods.
24.1.2.1 ArrayBuffer ( length )
When the ArrayBuffer function is called with argument length, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - Let byteLength be ?
ToIndex (length). - Return ?
AllocateArrayBuffer (NewTarget, byteLength).
24.1.3 Properties of the ArrayBuffer Constructor
The ArrayBuffer
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
24.1.3.1 ArrayBuffer.isView ( arg )
The isView function takes one argument arg, and performs, the following steps are taken:
- If
Type (arg) is not Object, returnfalse . - If arg has a [[ViewedArrayBuffer]] internal slot, return
true . - Return
false .
24.1.3.2 ArrayBuffer.prototype
The initial value of ArrayBuffer.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
24.1.3.3 get ArrayBuffer [ @@species ]
ArrayBuffer[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
ArrayBuffer prototype methods normally use their this object's
24.1.4 Properties of the ArrayBuffer Prototype Object
The ArrayBuffer prototype object:
- is the intrinsic object %ArrayBufferPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have an [[ArrayBufferData]] or [[ArrayBufferByteLength]] internal slot.
24.1.4.1 get ArrayBuffer.prototype.byteLength
ArrayBuffer.prototype.byteLength is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - If
IsSharedArrayBuffer (O) istrue , throw aTypeError exception. - If
IsDetachedBuffer (O) istrue , throw aTypeError exception. - Let length be O.[[ArrayBufferByteLength]].
- Return length.
24.1.4.2 ArrayBuffer.prototype.constructor
The initial value of ArrayBuffer.prototype.constructor is the intrinsic object
24.1.4.3 ArrayBuffer.prototype.slice ( start, end )
The following steps are taken:
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - If
IsSharedArrayBuffer (O) istrue , throw aTypeError exception. - If
IsDetachedBuffer (O) istrue , throw aTypeError exception. - Let len be O.[[ArrayBufferByteLength]].
- Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let first be
max ((len + relativeStart), 0); else let first bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Let newLen be
max (final-first, 0). - Let ctor be ?
SpeciesConstructor (O,%ArrayBuffer% ). - Let new be ?
Construct (ctor, « newLen »). - If new does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - If
IsSharedArrayBuffer (new) istrue , throw aTypeError exception. - If
IsDetachedBuffer (new) istrue , throw aTypeError exception. - If
SameValue (new, O) istrue , throw aTypeError exception. - If new.[[ArrayBufferByteLength]] < newLen, throw a
TypeError exception. - NOTE: Side-effects of the above steps may have detached O.
- If
IsDetachedBuffer (O) istrue , throw aTypeError exception. - Let fromBuf be O.[[ArrayBufferData]].
- Let toBuf be new.[[ArrayBufferData]].
- Perform
CopyDataBlockBytes (toBuf, 0, fromBuf, first, newLen). - Return new.
24.1.4.4 ArrayBuffer.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "ArrayBuffer".
This property has the attributes { [[Writable]]:
24.1.5 Properties of ArrayBuffer Instances
ArrayBuffer instances inherit properties from the ArrayBuffer prototype object. ArrayBuffer instances each have an [[ArrayBufferData]] internal slot and an [[ArrayBufferByteLength]] internal slot.
ArrayBuffer instances whose [[ArrayBufferData]] is
24.2 SharedArrayBuffer Objects
24.2.1 Abstract Operations for SharedArrayBuffer Objects
24.2.1.1 AllocateSharedArrayBuffer ( constructor, byteLength )
The abstract operation AllocateSharedArrayBuffer with arguments constructor and byteLength is used to create a SharedArrayBuffer object. It performs the following steps:
- Let obj be ?
OrdinaryCreateFromConstructor (constructor,"%SharedArrayBufferPrototype%", « [[ArrayBufferData]], [[ArrayBufferByteLength]] »). Assert : byteLength is a nonnegativeinteger .- Let block be ?
CreateSharedByteDataBlock (byteLength). - Set obj.[[ArrayBufferData]] to block.
- Set obj.[[ArrayBufferByteLength]] to byteLength.
- Return obj.
24.2.1.2 IsSharedArrayBuffer ( obj )
IsSharedArrayBuffer tests whether an object is an ArrayBuffer, a SharedArrayBuffer, or a subtype of either. It performs the following steps:
Assert :Type (obj) is Object and it has an [[ArrayBufferData]] internal slot.- Let bufferData be obj.[[ArrayBufferData]].
- If bufferData is
null , returnfalse . - If bufferData is a
Data Block , returnfalse . Assert : bufferData is aShared Data Block .- Return
true .
24.2.2 The SharedArrayBuffer Constructor
The SharedArrayBuffer
- is the intrinsic object %SharedArrayBuffer%.
- is the initial value of the
SharedArrayBufferproperty of theglobal object . - creates and initializes a new SharedArrayBuffer object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedSharedArrayBufferbehaviour must include asupercall to theSharedArrayBufferconstructor to create and initialize subclass instances with the internal state necessary to support theSharedArrayBuffer.prototypebuilt-in methods.
Unlike an ArrayBuffer, a SharedArrayBuffer cannot become detached, and its internal [[ArrayBufferData]] slot is never
24.2.2.1 SharedArrayBuffer ( length )
When the SharedArrayBuffer function is called with optional argument length, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - Let byteLength be ?
ToIndex (length). - Return ?
AllocateSharedArrayBuffer (NewTarget, byteLength).
24.2.3 Properties of the SharedArrayBuffer Constructor
The SharedArrayBuffer
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
24.2.3.1 SharedArrayBuffer.prototype
The initial value of SharedArrayBuffer.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
24.2.3.2 get SharedArrayBuffer [ @@species ]
SharedArrayBuffer[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
24.2.4 Properties of the SharedArrayBuffer Prototype Object
The SharedArrayBuffer prototype object:
- is the intrinsic object %SharedArrayBufferPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have an [[ArrayBufferData]] or [[ArrayBufferByteLength]] internal slot.
24.2.4.1 get SharedArrayBuffer.prototype.byteLength
SharedArrayBuffer.prototype.byteLength is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - If
IsSharedArrayBuffer (O) isfalse , throw aTypeError exception. - Let length be O.[[ArrayBufferByteLength]].
- Return length.
24.2.4.2 SharedArrayBuffer.prototype.constructor
The initial value of SharedArrayBuffer.prototype.constructor is the intrinsic object
24.2.4.3 SharedArrayBuffer.prototype.slice ( start, end )
The following steps are taken:
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - If
IsSharedArrayBuffer (O) isfalse , throw aTypeError exception. - Let len be O.[[ArrayBufferByteLength]].
- Let relativeStart be ?
ToInteger (start). - If relativeStart < 0, let first be
max ((len + relativeStart), 0); else let first bemin (relativeStart, len). - If end is
undefined , let relativeEnd be len; else let relativeEnd be ?ToInteger (end). - If relativeEnd < 0, let final be
max ((len + relativeEnd), 0); else let final bemin (relativeEnd, len). - Let newLen be
max (final - first, 0). - Let ctor be ?
SpeciesConstructor (O,%SharedArrayBuffer% ). - Let new be ?
Construct (ctor, « newLen »). - If new does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - If
IsSharedArrayBuffer (new) isfalse , throw aTypeError exception. - If new.[[ArrayBufferData]] and O.[[ArrayBufferData]] are the same
Shared Data Block values, throw aTypeError exception. - If new.[[ArrayBufferByteLength]] < newLen, throw a
TypeError exception. - Let fromBuf be O.[[ArrayBufferData]].
- Let toBuf be new.[[ArrayBufferData]].
- Perform
CopyDataBlockBytes (toBuf, 0, fromBuf, first, newLen). - Return new.
24.2.4.4 SharedArrayBuffer.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "SharedArrayBuffer".
This property has the attributes { [[Writable]]:
24.2.5 Properties of SharedArrayBuffer Instances
SharedArrayBuffer instances inherit properties from the SharedArrayBuffer prototype object. SharedArrayBuffer instances each have an [[ArrayBufferData]] internal slot and an [[ArrayBufferByteLength]] internal slot.
SharedArrayBuffer instances, unlike ArrayBuffer instances, are never detached.
24.3 DataView Objects
24.3.1 Abstract Operations For DataView Objects
24.3.1.1 GetViewValue ( view, requestIndex, isLittleEndian, type )
The abstract operation GetViewValue with arguments view, requestIndex, isLittleEndian, and type is used by functions on DataView instances to retrieve values from the view's buffer. It performs the following steps:
- If
Type (view) is not Object, throw aTypeError exception. - If view does not have a [[DataView]] internal slot, throw a
TypeError exception. Assert : view has a [[ViewedArrayBuffer]] internal slot.- Let getIndex be ?
ToIndex (requestIndex). - Set isLittleEndian to
ToBoolean (isLittleEndian). - Let buffer be view.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let viewOffset be view.[[ByteOffset]].
- Let viewSize be view.[[ByteLength]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for Element Type type. - If getIndex + elementSize > viewSize, throw a
RangeError exception. - Let bufferIndex be getIndex + viewOffset.
- Return
GetValueFromBuffer (buffer, bufferIndex, type,false ,"Unordered", isLittleEndian).
24.3.1.2 SetViewValue ( view, requestIndex, isLittleEndian, type, value )
The abstract operation SetViewValue with arguments view, requestIndex, isLittleEndian, type, and value is used by functions on DataView instances to store values into the view's buffer. It performs the following steps:
- If
Type (view) is not Object, throw aTypeError exception. - If view does not have a [[DataView]] internal slot, throw a
TypeError exception. Assert : view has a [[ViewedArrayBuffer]] internal slot.- Let getIndex be ?
ToIndex (requestIndex). - Let numberValue be ?
ToNumber (value). - Set isLittleEndian to
ToBoolean (isLittleEndian). - Let buffer be view.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let viewOffset be view.[[ByteOffset]].
- Let viewSize be view.[[ByteLength]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for Element Type type. - If getIndex + elementSize > viewSize, throw a
RangeError exception. - Let bufferIndex be getIndex + viewOffset.
- Return
SetValueInBuffer (buffer, bufferIndex, type, numberValue,false ,"Unordered", isLittleEndian).
24.3.2 The DataView Constructor
The DataView
- is the intrinsic object %DataView%.
- is the initial value of the
DataViewproperty of theglobal object . - creates and initializes a new DataView object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedDataViewbehaviour must include asupercall to theDataViewconstructor to create and initialize subclass instances with the internal state necessary to support theDataView.prototypebuilt-in methods.
24.3.2.1 DataView ( buffer [ , byteOffset [ , byteLength ] ] )
When the DataView is called with at least one argument buffer, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - If
Type (buffer) is not Object, throw aTypeError exception. - If buffer does not have an [[ArrayBufferData]] internal slot, throw a
TypeError exception. - Let offset be ?
ToIndex (byteOffset). - If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let bufferByteLength be buffer.[[ArrayBufferByteLength]].
- If offset > bufferByteLength, throw a
RangeError exception. - If byteLength is either not present or
undefined , then- Let viewByteLength be bufferByteLength - offset.
- Else,
- Let viewByteLength be ?
ToIndex (byteLength). - If offset+viewByteLength > bufferByteLength, throw a
RangeError exception.
- Let viewByteLength be ?
- Let O be ?
OrdinaryCreateFromConstructor (NewTarget,"%DataViewPrototype%", « [[DataView]], [[ViewedArrayBuffer]], [[ByteLength]], [[ByteOffset]] »). - Set O.[[ViewedArrayBuffer]] to buffer.
- Set O.[[ByteLength]] to viewByteLength.
- Set O.[[ByteOffset]] to offset.
- Return O.
24.3.3 Properties of the DataView Constructor
The DataView
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
24.3.3.1 DataView.prototype
The initial value of DataView.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
24.3.4 Properties of the DataView Prototype Object
The DataView prototype object:
- is the intrinsic object %DataViewPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[DataView]], [[ViewedArrayBuffer]], [[ByteLength]], or [[ByteOffset]] internal slot.
24.3.4.1 get DataView.prototype.buffer
DataView.prototype.buffer is an
24.3.4.2 get DataView.prototype.byteLength
DataView.prototype.byteLength is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[DataView]] internal slot, throw a
TypeError exception. Assert : O has a [[ViewedArrayBuffer]] internal slot.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let size be O.[[ByteLength]].
- Return size.
24.3.4.3 get DataView.prototype.byteOffset
DataView.prototype.byteOffset is an
- Let O be the
this value. - If
Type (O) is not Object, throw aTypeError exception. - If O does not have a [[DataView]] internal slot, throw a
TypeError exception. Assert : O has a [[ViewedArrayBuffer]] internal slot.- Let buffer be O.[[ViewedArrayBuffer]].
- If
IsDetachedBuffer (buffer) istrue , throw aTypeError exception. - Let offset be O.[[ByteOffset]].
- Return offset.
24.3.4.4 DataView.prototype.constructor
The initial value of DataView.prototype.constructor is the intrinsic object
24.3.4.5 DataView.prototype.getFloat32 ( byteOffset [ , littleEndian ] )
When the getFloat32 method is called with argument byteOffset and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
GetViewValue (v, byteOffset, littleEndian,"Float32").
24.3.4.6 DataView.prototype.getFloat64 ( byteOffset [ , littleEndian ] )
When the getFloat64 method is called with argument byteOffset and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
GetViewValue (v, byteOffset, littleEndian,"Float64").
24.3.4.7 DataView.prototype.getInt8 ( byteOffset )
When the getInt8 method is called with argument byteOffset, the following steps are taken:
- Let v be the
this value. - Return ?
GetViewValue (v, byteOffset,true ,"Int8").
24.3.4.8 DataView.prototype.getInt16 ( byteOffset [ , littleEndian ] )
When the getInt16 method is called with argument byteOffset and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
GetViewValue (v, byteOffset, littleEndian,"Int16").
24.3.4.9 DataView.prototype.getInt32 ( byteOffset [ , littleEndian ] )
When the getInt32 method is called with argument byteOffset and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
GetViewValue (v, byteOffset, littleEndian,"Int32").
24.3.4.10 DataView.prototype.getUint8 ( byteOffset )
When the getUint8 method is called with argument byteOffset, the following steps are taken:
- Let v be the
this value. - Return ?
GetViewValue (v, byteOffset,true ,"Uint8").
24.3.4.11 DataView.prototype.getUint16 ( byteOffset [ , littleEndian ] )
When the getUint16 method is called with argument byteOffset and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
GetViewValue (v, byteOffset, littleEndian,"Uint16").
24.3.4.12 DataView.prototype.getUint32 ( byteOffset [ , littleEndian ] )
When the getUint32 method is called with argument byteOffset and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
GetViewValue (v, byteOffset, littleEndian,"Uint32").
24.3.4.13 DataView.prototype.setFloat32 ( byteOffset, value [ , littleEndian ] )
When the setFloat32 method is called with arguments byteOffset and value and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
SetViewValue (v, byteOffset, littleEndian,"Float32", value).
24.3.4.14 DataView.prototype.setFloat64 ( byteOffset, value [ , littleEndian ] )
When the setFloat64 method is called with arguments byteOffset and value and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
SetViewValue (v, byteOffset, littleEndian,"Float64", value).
24.3.4.15 DataView.prototype.setInt8 ( byteOffset, value )
When the setInt8 method is called with arguments byteOffset and value, the following steps are taken:
- Let v be the
this value. - Return ?
SetViewValue (v, byteOffset,true ,"Int8", value).
24.3.4.16 DataView.prototype.setInt16 ( byteOffset, value [ , littleEndian ] )
When the setInt16 method is called with arguments byteOffset and value and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
SetViewValue (v, byteOffset, littleEndian,"Int16", value).
24.3.4.17 DataView.prototype.setInt32 ( byteOffset, value [ , littleEndian ] )
When the setInt32 method is called with arguments byteOffset and value and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
SetViewValue (v, byteOffset, littleEndian,"Int32", value).
24.3.4.18 DataView.prototype.setUint8 ( byteOffset, value )
When the setUint8 method is called with arguments byteOffset and value, the following steps are taken:
- Let v be the
this value. - Return ?
SetViewValue (v, byteOffset,true ,"Uint8", value).
24.3.4.19 DataView.prototype.setUint16 ( byteOffset, value [ , littleEndian ] )
When the setUint16 method is called with arguments byteOffset and value and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
SetViewValue (v, byteOffset, littleEndian,"Uint16", value).
24.3.4.20 DataView.prototype.setUint32 ( byteOffset, value [ , littleEndian ] )
When the setUint32 method is called with arguments byteOffset and value and optional argument littleEndian, the following steps are taken:
- Let v be the
this value. - If littleEndian is not present, let littleEndian be
false . - Return ?
SetViewValue (v, byteOffset, littleEndian,"Uint32", value).
24.3.4.21 DataView.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "DataView".
This property has the attributes { [[Writable]]:
24.3.5 Properties of DataView Instances
DataView instances are ordinary objects that inherit properties from the DataView prototype object. DataView instances each have [[DataView]], [[ViewedArrayBuffer]], [[ByteLength]], and [[ByteOffset]] internal slots.
The value of the [[DataView]] internal slot is not used within this specification. The simple presence of that internal slot is used within the specification to identify objects created using the DataView
24.4 The Atomics Object
The Atomics object:
- is the intrinsic object %Atomics%.
- is the initial value of the
Atomicsproperty of theglobal object . - is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - does not have a [[Construct]] internal method; it cannot be used as a
constructor with thenewoperator. - does not have a [[Call]] internal method; it cannot be invoked as a function.
The Atomics object provides functions that operate indivisibly (atomically) on shared memory array cells as well as functions that let agents wait for and dispatch primitive events. When used with discipline, the Atomics functions allow multi-
For informative guidelines for programming and implementing shared memory in ECMAScript, please see the notes at the end of the
24.4.1 Abstract Operations for Atomics
24.4.1.1 ValidateSharedIntegerTypedArray ( typedArray [ , onlyInt32 ] )
The abstract operation ValidateSharedIntegerTypedArray takes one argument typedArray and an optional Boolean onlyInt32. It performs the following steps:
- If onlyInt32 is not present, set onlyInt32 to
false . - If
Type (typedArray) is not Object, throw aTypeError exception. - If typedArray does not have a [[TypedArrayName]] internal slot, throw a
TypeError exception. - Let typeName be typedArray.[[TypedArrayName]].
- If onlyInt32 is
true , then- If typeName is not
"Int32Array", throw aTypeError exception.
- If typeName is not
- Else,
- If typeName is not
"Int8Array","Uint8Array","Int16Array","Uint16Array","Int32Array", or"Uint32Array", throw aTypeError exception.
- If typeName is not
Assert : typedArray has a [[ViewedArrayBuffer]] internal slot.- Let buffer be typedArray.[[ViewedArrayBuffer]].
- If
IsSharedArrayBuffer (buffer) isfalse , throw aTypeError exception. - Return buffer.
24.4.1.2 ValidateAtomicAccess ( typedArray, requestIndex )
The abstract operation ValidateAtomicAccess takes two arguments, typedArray and requestIndex. It performs the following steps:
24.4.1.3 GetWaiterList ( block, i )
A WaiterList is a semantic object that contains an ordered list of those agents that are waiting on a location (block, i) in shared memory; block is a
The
Operations on a WaiterList -- adding and removing waiting agents, traversing the list of agents, suspending and waking agents on the list -- may only be performed by agents that have entered the WaiterList's critical section.
The abstract operation GetWaiterList takes two arguments, a
Assert : block is aShared Data Block .Assert : i and i+3 are valid byte offsets within the memory of block.Assert : i is divisible by 4.- Return the
WaiterList that is referenced by the pair (block, i).
24.4.1.4 EnterCriticalSection ( WL )
The abstract operation EnterCriticalSection takes one argument, a
Assert : The callingagent is not in thecritical section for anyWaiterList .- Wait until no
agent is in thecritical section for WL, then enter thecritical section for WL (without allowing any otheragent to enter).
24.4.1.5 LeaveCriticalSection ( WL )
The abstract operation LeaveCriticalSection takes one argument, a
Assert : The callingagent is in thecritical section for WL.- Leave the
critical section for WL.
24.4.1.6 AddWaiter ( WL, W )
The abstract operation AddWaiter takes two arguments, a
Assert : The callingagent is in thecritical section for WL.Assert : W is not on the list of waiters in anyWaiterList .- Add W to the end of the list of waiters in WL.
24.4.1.7 RemoveWaiter ( WL, W )
The abstract operation RemoveWaiter takes two arguments, a
Assert : The callingagent is in thecritical section for WL.Assert : W is on the list of waiters in WL.- Remove W from the list of waiters in WL.
24.4.1.8 RemoveWaiters ( WL, c )
The abstract operation RemoveWaiters takes two arguments, a
Assert : The callingagent is in thecritical section for WL.- Let L be a new empty
List . - Let S be a reference to the list of waiters in WL.
- Repeat, while c > 0 and S is not an empty
List ,- Let W be the first waiter in S.
- Add W to the end of L.
- Remove W from S.
- Subtract 1 from c.
- Return L.
24.4.1.9 Suspend ( WL, W, timeout )
The abstract operation Suspend takes three arguments, a
Assert : The callingagent is in thecritical section for WL.Assert : W is equal toAgentSignifier ().Assert : W is on the list of waiters in WL.Assert :AgentCanSuspend () istrue .- Perform
LeaveCriticalSection (WL) and suspend W for up to timeout milliseconds, performing the combined operation in such a way that a wakeup that arrives after thecritical section is exited but before the suspension takes effect is not lost. W can wake up either because the timeout expired or because it was woken explicitly by anotheragent callingWakeWaiter (WL, W), and not for any other reasons at all. - Perform
EnterCriticalSection (WL). - If W was woken explicitly by another
agent callingWakeWaiter (WL, W), returntrue . - Return
false .
24.4.1.10 WakeWaiter ( WL, W )
The abstract operation WakeWaiter takes two arguments, a
Assert : The callingagent is in thecritical section for WL.Assert : W is on the list of waiters in WL.- Wake the
agent W.
The embedding may delay waking W, e.g. for resource management reasons, but W must eventually be woken in order to guarantee forward progress.
24.4.1.11 AtomicReadModifyWrite ( typedArray, index, value, op )
The abstract operation AtomicReadModifyWrite takes four arguments, typedArray, index, value, and a pure combining operation op. The pure combining operation op takes two
- Let buffer be ?
ValidateSharedIntegerTypedArray (typedArray). - Let i be ?
ValidateAtomicAccess (typedArray, index). - Let v be ?
ToInteger (value). - Let arrayTypeName be typedArray.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for arrayTypeName. - Let elementType be the String value of the Element Type value in
Table 56 for arrayTypeName. - Let offset be typedArray.[[ByteOffset]].
- Let indexedPosition be (i × elementSize) + offset.
- Return
GetModifySetValueInBuffer (buffer, indexedPosition, elementType, v, op).
24.4.1.12 AtomicLoad ( typedArray, index )
The abstract operation AtomicLoad takes two arguments, typedArray, index. The operation atomically loads a value and returns the loaded value. It performs the following steps:
- Let buffer be ?
ValidateSharedIntegerTypedArray (typedArray). - Let i be ?
ValidateAtomicAccess (typedArray, index). - Let arrayTypeName be typedArray.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for arrayTypeName. - Let elementType be the String value of the Element Type value in
Table 56 for arrayTypeName. - Let offset be typedArray.[[ByteOffset]].
- Let indexedPosition be (i × elementSize) + offset.
- Return
GetValueFromBuffer (buffer, indexedPosition, elementType,true ,"SeqCst").
24.4.2 Atomics.add ( typedArray, index, value )
Let add denote a semantic function of two
The following steps are taken:
- Return ?
AtomicReadModifyWrite (typedArray, index, value,add).
24.4.3 Atomics.and ( typedArray, index, value )
Let and denote a semantic function of two
The following steps are taken:
- Return ?
AtomicReadModifyWrite (typedArray, index, value,and).
24.4.4 Atomics.compareExchange ( typedArray, index, expectedValue, replacementValue )
The following steps are taken:
- Let buffer be ?
ValidateSharedIntegerTypedArray (typedArray). - Let i be ?
ValidateAtomicAccess (typedArray, index). - Let expected be ?
ToInteger (expectedValue). - Let replacement be ?
ToInteger (replacementValue). - Let arrayTypeName be typedArray.[[TypedArrayName]].
- Let elementType be the String value of the Element Type value in
Table 56 for arrayTypeName. - Let isLittleEndian be the value of the [[LittleEndian]] field of the
surrounding agent 'sAgent Record . - Let expectedBytes be
NumberToRawBytes (elementType, expected, isLittleEndian). - Let elementSize be the
Number value of the Element Size value specified inTable 56 for arrayTypeName. - Let offset be typedArray.[[ByteOffset]].
- Let indexedPosition be (i × elementSize) + offset.
- Let
compareExchangedenote a semantic function of twoList of byte values arguments that returns the second argument if the first argument is element-wise equal to expectedBytes. - Return
GetModifySetValueInBuffer (buffer, indexedPosition, elementType, replacement,compareExchange).
24.4.5 Atomics.exchange ( typedArray, index, value )
Let second denote a semantic function of two
The following steps are taken:
- Return ?
AtomicReadModifyWrite (typedArray, index, value,second).
24.4.6 Atomics.isLockFree ( size )
The following steps are taken:
- Let n be ?
ToInteger (size). - Let AR be the
Agent Record of thesurrounding agent . - If n equals 1, return AR.[[IsLockFree1]].
- If n equals 2, return AR.[[IsLockFree2]].
- If n equals 4, return
true . - Return
false .
Atomics.isLockFree() is an optimization primitive. The intuition is that if the atomic step of an atomic primitive (compareExchange, load, store, add, sub, and, or, xor, or exchange) on a datum of size n bytes will be performed without the calling Atomics.isLockFree(n) will return
Atomics.isLockFree(4) always returns
24.4.7 Atomics.load ( typedArray, index )
The following steps are taken:
- Return ?
AtomicLoad (typedArray, index).
24.4.8 Atomics.or ( typedArray, index, value )
Let or denote a semantic function of two
The following steps are taken:
- Return ?
AtomicReadModifyWrite (typedArray, index, value,or).
24.4.9 Atomics.store ( typedArray, index, value )
The following steps are taken:
- Let buffer be ?
ValidateSharedIntegerTypedArray (typedArray). - Let i be ?
ValidateAtomicAccess (typedArray, index). - Let v be ?
ToInteger (value). - Let arrayTypeName be typedArray.[[TypedArrayName]].
- Let elementSize be the
Number value of the Element Size value specified inTable 56 for arrayTypeName. - Let elementType be the String value of the Element Type value in
Table 56 for arrayTypeName. - Let offset be typedArray.[[ByteOffset]].
- Let indexedPosition be (i × elementSize) + offset.
- Perform
SetValueInBuffer (buffer, indexedPosition, elementType, v,true ,"SeqCst"). - Return v.
24.4.10 Atomics.sub ( typedArray, index, value )
Let subtract denote a semantic function of two
The following steps are taken:
- Return ?
AtomicReadModifyWrite (typedArray, index, value,subtract).
24.4.11 Atomics.wait ( typedArray, index, value, timeout )
Atomics.wait puts the calling
- Let buffer be ?
ValidateSharedIntegerTypedArray (typedArray,true ). - Let i be ?
ValidateAtomicAccess (typedArray, index). - Let v be ?
ToInt32 (value). - Let q be ?
ToNumber (timeout). - If q is
NaN , let t be+∞ , else let t bemax (q, 0). - Let B be
AgentCanSuspend (). - If B is
false , throw aTypeError exception. - Let block be buffer.[[ArrayBufferData]].
- Let offset be typedArray.[[ByteOffset]].
- Let indexedPosition be (i × 4) + offset.
- Let WL be
GetWaiterList (block, indexedPosition). - Perform
EnterCriticalSection (WL). - Let w be !
AtomicLoad (typedArray, i). - If v is not equal to w, then
- Perform
LeaveCriticalSection (WL). - Return the String
"not-equal".
- Perform
- Let W be
AgentSignifier (). - Perform
AddWaiter (WL, W). - Let awoken be
Suspend (WL, W, t). - If awoken is
true , thenAssert : W is not on the list of waiters in WL.
- Else,
- Perform
RemoveWaiter (WL, W).
- Perform
- Perform
LeaveCriticalSection (WL). - If awoken is
true , return the String"ok". - Return the String
"timed-out".
24.4.12 Atomics.wake ( typedArray, index, count )
Atomics.wake wakes up some agents that are sleeping in the wait queue. The following steps are taken:
- Let buffer be ?
ValidateSharedIntegerTypedArray (typedArray,true ). - Let i be ?
ValidateAtomicAccess (typedArray, index). - If count is
undefined , let c be+∞ . - Else,
- Let block be buffer.[[ArrayBufferData]].
- Let offset be typedArray.[[ByteOffset]].
- Let indexedPosition be (i × 4) + offset.
- Let WL be
GetWaiterList (block, indexedPosition). - Let n be 0.
- Perform
EnterCriticalSection (WL). - Let S be
RemoveWaiters (WL, c). - Repeat, while S is not an empty
List ,- Let W be the first
agent in S. - Remove W from the front of S.
- Perform
WakeWaiter (WL, W). - Add 1 to n.
- Let W be the first
- Perform
LeaveCriticalSection (WL). - Return n.
24.4.13 Atomics.xor ( typedArray, index, value )
Let xor denote a semantic function of two
The following steps are taken:
- Return ?
AtomicReadModifyWrite (typedArray, index, value,xor).
24.4.14 Atomics [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Atomics".
This property has the attributes { [[Writable]]:
24.5 The JSON Object
The JSON object:
- is the intrinsic object %JSON%.
- is the initial value of the
JSONproperty of theglobal object . - is an ordinary object.
- contains two functions,
parseandstringify, that are used to parse and construct JSON texts. - has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - does not have a [[Construct]] internal method; it cannot be used as a
constructor with thenewoperator. - does not have a [[Call]] internal method; it cannot be invoked as a function.
The JSON Data Interchange Format is defined in ECMA-404. The JSON interchange format used in this specification is exactly that described by ECMA-404. Conforming implementations of JSON.parse and JSON.stringify must support the exact interchange format described in the ECMA-404 specification without any deletions or extensions to the format.
24.5.1 JSON.parse ( text [ , reviver ] )
The parse function parses a JSON text (a JSON-formatted String) and produces an ECMAScript value. The JSON format represents literals, arrays, and objects with a syntax similar to the syntax for ECMAScript literals, Array Initializers, and Object Initializers. After parsing, JSON objects are realized as ECMAScript objects. JSON arrays are realized as ECMAScript Array instances. JSON strings, numbers, booleans, and null are realized as ECMAScript Strings, Numbers, Booleans, and
The optional reviver parameter is a function that takes two parameters, key and value. It can filter and transform the results. It is called with each of the key/value pairs produced by the parse, and its return value is used instead of the original value. If it returns what it received, the structure is not modified. If it returns
- Let JText be ?
ToString (text). - Parse JText interpreted as UTF-16 encoded Unicode points (
6.1.4 ) as a JSON text as specified in ECMA-404. Throw aSyntaxError exception if JText is not a valid JSON text as defined in that specification. - Let scriptText be the
string-concatenation of"(", JText, and");". - Let completion be the result of parsing and evaluating scriptText as if it was the source text of an ECMAScript
Script , but using the alternative definition ofDoubleStringCharacter provided below. The extended PropertyDefinitionEvaluation semantics defined inB.3.1 must not be used during the evaluation. - Let unfiltered be completion.[[Value]].
Assert : unfiltered is either a String, Number, Boolean, Null, or an Object that is defined by either anArrayLiteral or anObjectLiteral .- If
IsCallable (reviver) istrue , then- Let root be
ObjectCreate (%ObjectPrototype% ). - Let rootName be the empty String.
- Let status be
CreateDataProperty (root, rootName, unfiltered). Assert : status istrue .- Return ?
InternalizeJSONProperty (root, rootName).
- Let root be
- Else,
- Return unfiltered.
This function is the %JSONParse% intrinsic object.
The length property of the parse function is 2.
JSON allows Unicode code units 0x2028 (LINE SEPARATOR) and 0x2029 (PARAGRAPH SEPARATOR) to directly appear in String literals without using an escape sequence. This is enabled by using the following alternative definition of
-
The SV of
DoubleStringCharacter :: SourceCharacter but not one of " or\ orU+0000 through U+001F UTF16Encoding of the code point value ofSourceCharacter .
Valid JSON text is a subset of the ECMAScript
24.5.1.1 Runtime Semantics: InternalizeJSONProperty ( holder, name )
The abstract operation InternalizeJSONProperty is a recursive abstract operation that takes two parameters: a holder object and the String name of a property in that object. InternalizeJSONProperty uses the value of reviver that was originally passed to the above parse function.
- Let val be ?
Get (holder, name). - If
Type (val) is Object, then- Let isArray be ?
IsArray (val). - If isArray is
true , then- Let I be 0.
- Let len be ?
ToLength (?Get (val,"length")). - Repeat, while I < len,
- Let newElement be ?
InternalizeJSONProperty (val, !ToString (I)). - If newElement is
undefined , then- Perform ? val.[[Delete]](!
ToString (I)).
- Perform ? val.[[Delete]](!
- Else,
- Perform ?
CreateDataProperty (val, !ToString (I), newElement). - NOTE: This algorithm intentionally does not throw an exception if
CreateDataProperty returnsfalse .
- Perform ?
- Add 1 to I.
- Let newElement be ?
- Else,
- Let keys be ?
EnumerableOwnPropertyNames (val,"key" ). - For each String P in keys, do
- Let newElement be ?
InternalizeJSONProperty (val, P). - If newElement is
undefined , then- Perform ? val.[[Delete]](P).
- Else,
- Perform ?
CreateDataProperty (val, P, newElement). - NOTE: This algorithm intentionally does not throw an exception if
CreateDataProperty returnsfalse .
- Perform ?
- Let newElement be ?
- Let keys be ?
- Let isArray be ?
- Return ?
Call (reviver, holder, « name, val »).
It is not permitted for a conforming implementation of JSON.parse to extend the JSON grammars. If an implementation wishes to support a modified or extended JSON interchange format it must do so by defining a different parse function.
In the case where there are duplicate name Strings within an object, lexically preceding values for the same key shall be overwritten.
24.5.2 JSON.stringify ( value [ , replacer [ , space ] ] )
The stringify function returns a String in UTF-16 encoded JSON format representing an ECMAScript value. It can take three parameters. The value parameter is an ECMAScript value, which is usually an object or array, although it can also be a String, Boolean, Number or
These are the steps in stringifying an object:
- Let stack be a new empty
List . - Let indent be the empty String.
- Let PropertyList and ReplacerFunction be
undefined . - If
Type (replacer) is Object, then- If
IsCallable (replacer) istrue , then- Let ReplacerFunction be replacer.
- Else,
- Let isArray be ?
IsArray (replacer). - If isArray is
true , then- Let PropertyList be a new empty
List . - Let len be ?
ToLength (?Get (replacer,"length")). - Let k be 0.
- Repeat, while k<len,
- Let v be ?
Get (replacer, !ToString (k)). - Let item be
undefined . - If
Type (v) is String, let item be v. - Else if
Type (v) is Number, let item be !ToString (v). - Else if
Type (v) is Object, then- If v has a [[StringData]] or [[NumberData]] internal slot, let item be ?
ToString (v).
- If v has a [[StringData]] or [[NumberData]] internal slot, let item be ?
- If item is not
undefined and item is not currently an element of PropertyList, then- Append item to the end of PropertyList.
- Let k be k+1.
- Let v be ?
- Let PropertyList be a new empty
- Let isArray be ?
- If
- If
Type (space) is Object, then - If
Type (space) is Number, then - Else if
Type (space) is String, then- If the length of space is 10 or less, set gap to space; otherwise set gap to the String value consisting of the first 10 elements of space.
- Else,
- Set gap to the empty String.
- Let wrapper be
ObjectCreate (%ObjectPrototype% ). - Let status be
CreateDataProperty (wrapper, the empty String, value). Assert : status istrue .- Return ?
SerializeJSONProperty (the empty String, wrapper).
The length property of the stringify function is 3.
JSON structures are allowed to be nested to any depth, but they must be acyclic. If value is or contains a cyclic structure, then the stringify function must throw a
a = [];
a[0] = a;
my_text = JSON.stringify(a); // This must throw a TypeError.Symbolic primitive values are rendered as follows:
-
The
null value is rendered in JSON text as the Stringnull. -
The
undefined value is not rendered. -
The
true value is rendered in JSON text as the Stringtrue. -
The
false value is rendered in JSON text as the Stringfalse.
String values are wrapped in QUOTATION MARK (") code units. The code units " and \ are escaped with \ prefixes. Control characters code units are replaced with escape sequences \uHHHH, or with the shorter forms, \b (BACKSPACE), \f (FORM FEED), \n (LINE FEED), \r (CARRIAGE RETURN), \t (CHARACTER TABULATION).
Finite numbers are stringified as if by calling null.
Values that do not have a JSON representation (such as null. In objects an unrepresentable value causes the property to be excluded from stringification.
An object is rendered as U+007B (LEFT CURLY BRACKET) followed by zero or more properties, separated with a U+002C (COMMA), closed with a U+007D (RIGHT CURLY BRACKET). A property is a quoted String representing the key or
24.5.2.1 Runtime Semantics: SerializeJSONProperty ( key, holder )
The abstract operation SerializeJSONProperty with arguments key, and holder has access to ReplacerFunction from the invocation of the stringify method. Its algorithm is as follows:
- Let value be ?
Get (holder, key). - If
Type (value) is Object, then- Let toJSON be ?
Get (value,"toJSON"). - If
IsCallable (toJSON) istrue , then- Set value to ?
Call (toJSON, value, « key »).
- Set value to ?
- Let toJSON be ?
- If ReplacerFunction is not
undefined , then- Set value to ?
Call (ReplacerFunction, holder, « key, value »).
- Set value to ?
- If
Type (value) is Object, then - If value is
null , return"null". - If value is
true , return"true". - If value is
false , return"false". - If
Type (value) is String, returnQuoteJSONString (value). - If
Type (value) is Number, then- If value is finite, return !
ToString (value). - Return
"null".
- If value is finite, return !
- If
Type (value) is Object andIsCallable (value) isfalse , then- Let isArray be ?
IsArray (value). - If isArray is
true , return ?SerializeJSONArray (value). - Return ?
SerializeJSONObject (value).
- Let isArray be ?
- Return
undefined .
24.5.2.2 Runtime Semantics: QuoteJSONString ( value )
The abstract operation QuoteJSONString with argument value wraps a String value in QUOTATION MARK code units and escapes certain other code units within it.
- Let product be the String value consisting solely of the code unit 0x0022 (QUOTATION MARK).
- For each code unit C in value, do
- If the numeric value of C is listed in the Code Unit Value column of
Table 59 , then- Set product to the
string-concatenation of product and the Escape Sequence for C as specified inTable 59 .
- Set product to the
- Else if C has a numeric value less than 0x0020 (SPACE), then
- Set product to the
string-concatenation of product andUnicodeEscape (C).
- Set product to the
- Else,
- Set product to the
string-concatenation of product and C.
- Set product to the
- If the numeric value of C is listed in the Code Unit Value column of
- Set product to the
string-concatenation of product and the code unit 0x0022 (QUOTATION MARK). - Return product.
| Code Unit Value | Unicode Character Name | Escape Sequence |
|---|---|---|
0x0008
|
BACKSPACE |
\b
|
0x0009
|
CHARACTER TABULATION |
\t
|
0x000A
|
LINE FEED (LF) |
\n
|
0x000C
|
FORM FEED (FF) |
\f
|
0x000D
|
CARRIAGE RETURN (CR) |
\r
|
0x0022
|
QUOTATION MARK |
\"
|
0x005C
|
REVERSE SOLIDUS |
\\
|
24.5.2.3 Runtime Semantics: UnicodeEscape ( C )
The abstract operation UnicodeEscape takes a code unit argument C and represents it as a Unicode escape sequence.
- Let n be the numeric value of C.
Assert : n ≤ 0xFFFF.- Return the
string-concatenation of:- the code unit 0x005C (REVERSE SOLIDUS)
"u"- the String representation of n, formatted as a four-digit lowercase hexadecimal number, padded to the left with zeroes if necessary
24.5.2.4 Runtime Semantics: SerializeJSONObject ( value )
The abstract operation SerializeJSONObject with argument value serializes an object. It has access to the stack, indent, gap, and PropertyList values of the current invocation of the stringify method.
- If stack contains value, throw a
TypeError exception because the structure is cyclical. - Append value to stack.
- Let stepback be indent.
- Set indent to the
string-concatenation of indent and gap. - If PropertyList is not
undefined , then- Let K be PropertyList.
- Else,
- Let K be ?
EnumerableOwnPropertyNames (value,"key" ).
- Let K be ?
- Let partial be a new empty
List . - For each element P of K, do
- Let strP be ?
SerializeJSONProperty (P, value). - If strP is not
undefined , then- Let member be
QuoteJSONString (P). - Set member to the
string-concatenation of member and":". - If gap is not the empty String, then
- Set member to the
string-concatenation of member and the code unit 0x0020 (SPACE).
- Set member to the
- Set member to the
string-concatenation of member and strP. - Append member to partial.
- Let member be
- Let strP be ?
- If partial is empty, then
- Let final be
"{}".
- Let final be
- Else,
- If gap is the empty String, then
- Let properties be the String value formed by concatenating all the element Strings of partial with each adjacent pair of Strings separated with the code unit 0x002C (COMMA). A comma is not inserted either before the first String or after the last String.
- Let final be the
string-concatenation of"{", properties, and"}".
- Else gap is not the empty String,
- Let separator be the
string-concatenation of the code unit 0x002C (COMMA), the code unit 0x000A (LINE FEED), and indent. - Let properties be the String value formed by concatenating all the element Strings of partial with each adjacent pair of Strings separated with separator. The separator String is not inserted either before the first String or after the last String.
- Let final be the
string-concatenation of"{", the code unit 0x000A (LINE FEED), indent, properties, the code unit 0x000A (LINE FEED), stepback, and"}".
- Let separator be the
- If gap is the empty String, then
- Remove the last element of stack.
- Set indent to stepback.
- Return final.
24.5.2.5 Runtime Semantics: SerializeJSONArray ( value )
The abstract operation SerializeJSONArray with argument value serializes an array. It has access to the stack, indent, and gap values of the current invocation of the stringify method.
- If stack contains value, throw a
TypeError exception because the structure is cyclical. - Append value to stack.
- Let stepback be indent.
- Set indent to the
string-concatenation of indent and gap. - Let partial be a new empty
List . - Let len be ?
ToLength (?Get (value,"length")). - Let index be 0.
- Repeat, while index < len
- Let strP be ?
SerializeJSONProperty (!ToString (index), value). - If strP is
undefined , then- Append
"null"to partial.
- Append
- Else,
- Append strP to partial.
- Increment index by 1.
- Let strP be ?
- If partial is empty, then
- Let final be
"[]".
- Let final be
- Else,
- If gap is the empty String, then
- Let properties be the String value formed by concatenating all the element Strings of partial with each adjacent pair of Strings separated with the code unit 0x002C (COMMA). A comma is not inserted either before the first String or after the last String.
- Let final be the
string-concatenation of"[", properties, and"]".
- Else,
- Let separator be the
string-concatenation of the code unit 0x002C (COMMA), the code unit 0x000A (LINE FEED), and indent. - Let properties be the String value formed by concatenating all the element Strings of partial with each adjacent pair of Strings separated with separator. The separator String is not inserted either before the first String or after the last String.
- Let final be the
string-concatenation of"[", the code unit 0x000A (LINE FEED), indent, properties, the code unit 0x000A (LINE FEED), stepback, and"]".
- Let separator be the
- If gap is the empty String, then
- Remove the last element of stack.
- Set indent to stepback.
- Return final.
The representation of arrays includes only the elements between zero and array.length - 1
24.5.3 JSON [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "JSON".
This property has the attributes { [[Writable]]:
25 Control Abstraction Objects
25.1 Iteration
25.1.1 Common Iteration Interfaces
An interface is a set of property keys whose associated values match a specific specification. Any object that provides all the properties as described by an interface's specification conforms to that interface. An interface is not represented by a distinct object. There may be many separately implemented objects that conform to any interface. An individual object may conform to multiple interfaces.
25.1.1.1 The Iterable Interface
The Iterable interface includes the property described in
| Property | Value | Requirements |
|---|---|---|
@@iterator
|
A function that returns an Iterator object. | The returned object must conform to the Iterator interface. |
25.1.1.2 The Iterator Interface
An object that implements the Iterator interface must include the property in
| Property | Value | Requirements |
|---|---|---|
next
|
A function that returns an IteratorResult object. |
The returned object must conform to the IteratorResult interface. If a previous call to the next method of an Iterator has returned an IteratorResult object whose done property is next method of that object should also return an IteratorResult object whose done property is |
Arguments may be passed to the next function but their interpretation and validity is dependent upon the target Iterator. The for-of statement and other common users of Iterators do not pass any arguments, so Iterator objects that expect to be used in such a manner must be prepared to deal with being called with no arguments.
| Property | Value | Requirements |
|---|---|---|
return
|
A function that returns an IteratorResult object. |
The returned object must conform to the IteratorResult interface. Invoking this method notifies the Iterator object that the caller does not intend to make any more next method calls to the Iterator. The returned IteratorResult object will typically have a done property whose value is value property with the value passed as the argument of the return method. However, this requirement is not enforced.
|
throw
|
A function that returns an IteratorResult object. |
The returned object must conform to the IteratorResult interface. Invoking this method notifies the Iterator object that the caller has detected an error condition. The argument may be used to identify the error condition and typically will be an exception object. A typical response is to throw the value passed as the argument. If the method does not throw, the returned IteratorResult object will typically have a done property whose value is |
Typically callers of these methods should check for their existence before invoking them. Certain ECMAScript language features including for-of, yield*, and array destructuring call these methods after performing an existence check. Most ECMAScript library functions that accept Iterable objects as arguments also conditionally call them.
25.1.1.3 The AsyncIterable Interface
The AsyncIterable interface includes the properties described in
| Property | Value | Requirements |
|---|---|---|
@@asyncIterator |
A function that returns an AsyncIterator object. | The returned object must conform to the AsyncIterator interface. |
25.1.1.4 The AsyncIterator Interface
An object that implements the AsyncIterator interface must include the properties in
| Property | Value | Requirements |
|---|---|---|
next |
A function that returns a promise for an IteratorResult object. |
The returned promise, when fulfilled, must fulfill with an object which conforms to the IteratorResult interface. If a previous call to the Additionally, the IteratorResult object that serves as a fulfillment value should have a |
Arguments may be passed to the next function but their interpretation and validity is dependent upon the target AsyncIterator. The for-await-of statement and other common users of AsyncIterators do not pass any arguments, so AsyncIterator objects that expect to be used in such a manner must be prepared to deal with being called with no arguments.
| Property | Value | Requirements |
|---|---|---|
return |
A function that returns a promise for an IteratorResult object. |
The returned promise, when fulfilled, must fulfill with an object which conforms to the IteratorResult interface. Invoking this method notifies the AsyncIterator object that the caller does not intend to make any more Additionally, the IteratorResult object that serves as a fulfillment value should have a |
throw |
A function that returns a promise for an IteratorResult object. |
The returned promise, when fulfilled, must fulfill with an object which conforms to the IteratorResult interface. Invoking this method notifies the AsyncIterator object that the caller has detected an error condition. The argument may be used to identify the error condition and typically will be an exception object. A typical response is to return a rejected promise which rejects with the value passed as the argument. If the returned promise is fulfilled, the IteratorResult fulfillment value will typically have a |
Typically callers of these methods should check for their existence before invoking them. Certain ECMAScript language features including for-await-of and yield* call these methods after performing an existence check.
25.1.1.5 The IteratorResult Interface
The IteratorResult interface includes the properties listed in
| Property | Value | Requirements |
|---|---|---|
done
|
Either |
This is the result status of an iterator next method call. If the end of the iterator was reached done is done is done property (either own or inherited) does not exist, it is consider to have the value |
value
|
Any |
If done is value is value property may be absent from the conforming object if it does not inherit an explicit value property.
|
25.1.2 The %IteratorPrototype% Object
The %IteratorPrototype% object:
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
All objects defined in this specification that implement the Iterator interface also inherit from %IteratorPrototype%. ECMAScript code may also define objects that inherit from %IteratorPrototype%.The %IteratorPrototype% object provides a place where additional methods that are applicable to all iterator objects may be added.
The following expression is one way that ECMAScript code can access the %IteratorPrototype% object:
Object.getPrototypeOf(Object.getPrototypeOf([][Symbol.iterator]()))25.1.2.1 %IteratorPrototype% [ @@iterator ] ( )
The following steps are taken:
- Return the
this value.
The value of the name property of this function is "[Symbol.iterator]".
25.1.3 The %AsyncIteratorPrototype% Object
The %AsyncIteratorPrototype% object:
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
All objects defined in this specification that implement the AsyncIterator interface also inherit from %AsyncIteratorPrototype%. ECMAScript code may also define objects that inherit from %AsyncIteratorPrototype%.The %AsyncIteratorPrototype% object provides a place where additional methods that are applicable to all async iterator objects may be added.
25.1.3.1 %AsyncIteratorPrototype% [ @@asyncIterator ] ( )
The following steps are taken:
- Return the
this value.
The value of the name property of this function is "[Symbol.asyncIterator]".
25.1.4 Async-from-Sync Iterator Objects
An Async-from-Sync Iterator object is an async iterator that adapts a specific synchronous iterator. There is not a named
25.1.4.1 CreateAsyncFromSyncIterator ( syncIteratorRecord )
The abstract operation CreateAsyncFromSyncIterator is used to create an async iterator
- Let asyncIterator be !
ObjectCreate (%AsyncFromSyncIteratorPrototype% , « [[SyncIteratorRecord]] »). - Set asyncIterator.[[SyncIteratorRecord]] to syncIteratorRecord.
- Return ?
GetIterator (asyncIterator,async ).
25.1.4.2 The %AsyncFromSyncIteratorPrototype% Object
The %AsyncFromSyncIteratorPrototype% object:
- has properties that are inherited by all Async-from-Sync Iterator Objects.
- is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%AsyncIteratorPrototype% . - has the following properties:
25.1.4.2.1 %AsyncFromSyncIteratorPrototype%.next ( value )
- Let O be the
this value. - Let promiseCapability be !
NewPromiseCapability (%Promise% ). - If
Type (O) is not Object, or if O does not have a [[SyncIteratorRecord]] internal slot, then- Let invalidIteratorError be a newly created
TypeError object. - Perform !
Call (promiseCapability.[[Reject]],undefined , « invalidIteratorError »). - Return promiseCapability.[[Promise]].
- Let invalidIteratorError be a newly created
- Let syncIteratorRecord be O.[[SyncIteratorRecord]].
- Let nextResult be
IteratorNext (syncIteratorRecord, value). IfAbruptRejectPromise (nextResult, promiseCapability).- Let nextDone be
IteratorComplete (nextResult). IfAbruptRejectPromise (nextDone, promiseCapability).- Let nextValue be
IteratorValue (nextResult). IfAbruptRejectPromise (nextValue, promiseCapability).- Let valueWrapperCapability be !
NewPromiseCapability (%Promise% ). - Perform !
Call (valueWrapperCapability.[[Resolve]],undefined , « nextValue »). - Let steps be the algorithm steps defined in
Async-from-Sync Iterator Value Unwrap Functions . - Let onFulfilled be
CreateBuiltinFunction (steps, « [[Done]] »). - Set onFulfilled.[[Done]] to nextDone.
- Perform !
PerformPromiseThen (valueWrapperCapability.[[Promise]], onFulfilled,undefined , promiseCapability). - Return promiseCapability.[[Promise]].
25.1.4.2.2 %AsyncFromSyncIteratorPrototype%.return ( value )
- Let O be the
this value. - Let promiseCapability be !
NewPromiseCapability (%Promise% ). - If
Type (O) is not Object, or if O does not have a [[SyncIteratorRecord]] internal slot, then- Let invalidIteratorError be a newly created
TypeError object. - Perform !
Call (promiseCapability.[[Reject]],undefined , « invalidIteratorError »). - Return promiseCapability.[[Promise]].
- Let invalidIteratorError be a newly created
- Let syncIterator be O.[[SyncIteratorRecord]].[[Iterator]].
- Let return be
GetMethod (syncIterator,"return"). IfAbruptRejectPromise (return, promiseCapability).- If return is
undefined , then- Let iterResult be !
CreateIterResultObject (value,true ). - Perform !
Call (promiseCapability.[[Resolve]],undefined , « iterResult »). - Return promiseCapability.[[Promise]].
- Let iterResult be !
- Let returnResult be
Call (return, syncIterator, « value »). IfAbruptRejectPromise (returnResult, promiseCapability).- If
Type (returnResult) is not Object, then- Perform !
Call (promiseCapability.[[Reject]],undefined , « a newly createdTypeError object »). - Return promiseCapability.[[Promise]].
- Perform !
- Let returnDone be
IteratorComplete (returnResult). IfAbruptRejectPromise (returnDone, promiseCapability).- Let returnValue be
IteratorValue (returnResult). IfAbruptRejectPromise (returnValue, promiseCapability).- Let valueWrapperCapability be !
NewPromiseCapability (%Promise% ). - Perform !
Call (valueWrapperCapability.[[Resolve]],undefined , « returnValue »). - Let steps be the algorithm steps defined in
Async-from-Sync Iterator Value Unwrap Functions . - Let onFulfilled be
CreateBuiltinFunction (steps, « [[Done]] »). - Set onFulfilled.[[Done]] to returnDone.
- Perform !
PerformPromiseThen (valueWrapperCapability.[[Promise]], onFulfilled,undefined , promiseCapability). - Return promiseCapability.[[Promise]].
25.1.4.2.3 %AsyncFromSyncIteratorPrototype%.throw ( value )
- Let O be the
this value. - Let promiseCapability be !
NewPromiseCapability (%Promise% ). - If
Type (O) is not Object, or if O does not have a [[SyncIteratorRecord]] internal slot, then- Let invalidIteratorError be a newly created
TypeError object. - Perform !
Call (promiseCapability.[[Reject]],undefined , « invalidIteratorError »). - Return promiseCapability.[[Promise]].
- Let invalidIteratorError be a newly created
- Let syncIterator be O.[[SyncIteratorRecord]].[[Iterator]].
- Let throw be
GetMethod (syncIterator,"throw"). IfAbruptRejectPromise (throw, promiseCapability).- If throw is
undefined , then- Perform !
Call (promiseCapability.[[Reject]],undefined , « value »). - Return promiseCapability.[[Promise]].
- Perform !
- Let throwResult be
Call (throw, syncIterator, « value »). IfAbruptRejectPromise (throwResult, promiseCapability).- If
Type (throwResult) is not Object, then- Perform !
Call (promiseCapability.[[Reject]],undefined , « a newly createdTypeError object »). - Return promiseCapability.[[Promise]].
- Perform !
- Let throwDone be
IteratorComplete (throwResult). IfAbruptRejectPromise (throwDone, promiseCapability).- Let throwValue be
IteratorValue (throwResult). IfAbruptRejectPromise (throwValue, promiseCapability).- Let valueWrapperCapability be !
NewPromiseCapability (%Promise% ). - Perform !
Call (valueWrapperCapability.[[Resolve]],undefined , « throwValue »). - Let steps be the algorithm steps defined in
Async-from-Sync Iterator Value Unwrap Functions . - Let onFulfilled be
CreateBuiltinFunction (steps, « [[Done]] »). - Set onFulfilled.[[Done]] to throwDone.
- Perform !
PerformPromiseThen (valueWrapperCapability.[[Promise]], onFulfilled,undefined , promiseCapability). - Return promiseCapability.[[Promise]].
25.1.4.2.4 %AsyncFromSyncIteratorPrototype% [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Async-from-Sync Iterator".
This property has the attributes { [[Writable]]:
25.1.4.2.5 Async-from-Sync Iterator Value Unwrap Functions
An async-from-sync iterator value unwrap function is an anonymous built-in function that is used by methods of value field of an IteratorResult object, in order to wait for its value if it is a promise and re-package the result in a new "unwrapped" IteratorResult object. Each async iterator value unwrap function has a [[Done]] internal slot.
When an async-from-sync iterator value unwrap function F is called with argument value, the following steps are taken:
- Return !
CreateIterResultObject (value, F.[[Done]]).
25.1.4.3 Properties of Async-from-Sync Iterator Instances
Async-from-Sync Iterator instances are ordinary objects that inherit properties from the
| Internal Slot | Description |
|---|---|
| [[SyncIteratorRecord]] |
A |
25.2 GeneratorFunction Objects
GeneratorFunction objects are functions that are usually created by evaluating
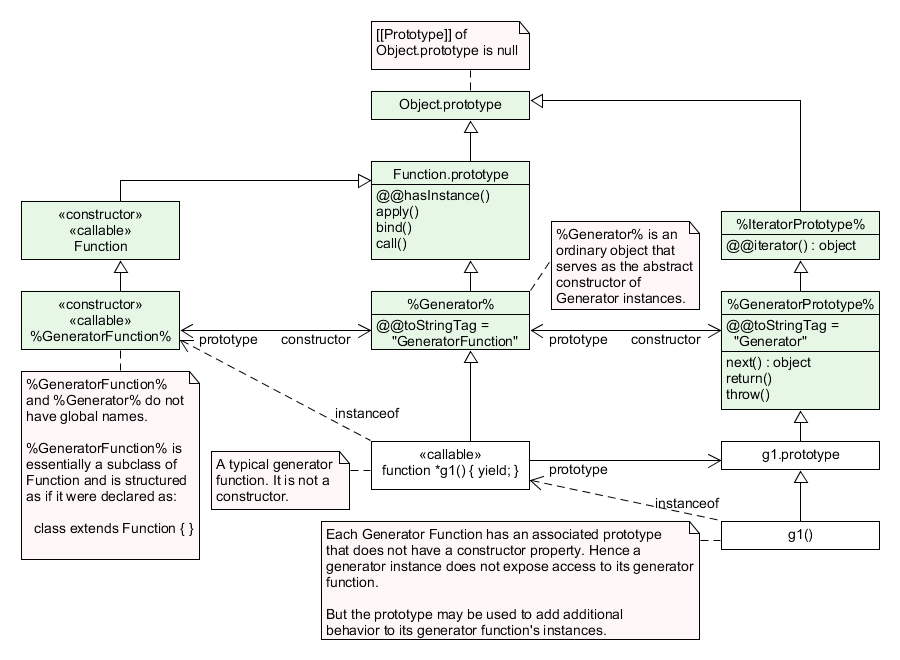
25.2.1 The GeneratorFunction Constructor
The GeneratorFunction
- is the intrinsic object %GeneratorFunction%.
- creates and initializes a new GeneratorFunction object when called as a function rather than as a
constructor . Thus the function callGeneratorFunction (…)is equivalent to the object creation expressionnew GeneratorFunction (…)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedGeneratorFunctionbehaviour must include asupercall to theGeneratorFunctionconstructor to create and initialize subclass instances with the internal slots necessary for built-in GeneratorFunction behaviour. All ECMAScript syntactic forms for defining generator function objects create direct instances ofGeneratorFunction. There is no syntactic means to create instances ofGeneratorFunctionsubclasses.
25.2.1.1 GeneratorFunction ( p1, p2, … , pn, body )
The last argument specifies the body (executable code) of a generator function; any preceding arguments specify formal parameters.
When the GeneratorFunction function is called with some arguments p1, p2, … , pn, body (where n might be 0, that is, there are no “p” arguments, and where body might also not be provided), the following steps are taken:
- Let C be the
active function object . - Let args be the argumentsList that was passed to this function by [[Call]] or [[Construct]].
- Return ?
CreateDynamicFunction (C, NewTarget,"generator", args).
See NOTE for
25.2.2 Properties of the GeneratorFunction Constructor
The GeneratorFunction
- is a standard built-in
function object that inherits from theFunctionconstructor . - has a [[Prototype]] internal slot whose value is the intrinsic object
%Function% . - has a
nameproperty whose value is"GeneratorFunction". - has the following properties:
25.2.2.1 GeneratorFunction.length
This is a
25.2.2.2 GeneratorFunction.prototype
The initial value of GeneratorFunction.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
25.2.3 Properties of the GeneratorFunction Prototype Object
The GeneratorFunction prototype object:
- is an ordinary object.
- is not a
function object and does not have an [[ECMAScriptCode]] internal slot or any other of the internal slots listed inTable 27 orTable 68 . - is the value of the
prototypeproperty of the intrinsic object%GeneratorFunction% . - is the intrinsic object %Generator% (see Figure 2).
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% .
25.2.3.1 GeneratorFunction.prototype.constructor
The initial value of GeneratorFunction.prototype.constructor is the intrinsic object
This property has the attributes { [[Writable]]:
25.2.3.2 GeneratorFunction.prototype.prototype
The value of GeneratorFunction.prototype.prototype is the
This property has the attributes { [[Writable]]:
25.2.3.3 GeneratorFunction.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "GeneratorFunction".
This property has the attributes { [[Writable]]:
25.2.4 GeneratorFunction Instances
Every GeneratorFunction instance is an ECMAScript "generator".
Each GeneratorFunction instance has the following own properties:
25.2.4.1 length
The specification for the length property of Function instances given in
25.2.4.2 name
The specification for the name property of Function instances given in
25.2.4.3 prototype
Whenever a GeneratorFunction instance is created another ordinary object is also created and is the initial value of the generator function's prototype property. The value of the prototype property is used to initialize the [[Prototype]] internal slot of a newly created Generator object when the generator
This property has the attributes { [[Writable]]:
Unlike Function instances, the object that is the value of the a GeneratorFunction's prototype property does not have a constructor property whose value is the GeneratorFunction instance.
25.3 AsyncGeneratorFunction Objects
AsyncGeneratorFunction objects are functions that are usually created by evaluating
25.3.1 The AsyncGeneratorFunction Constructor
The AsyncGeneratorFunction
- is the intrinsic object %AsyncGeneratorFunction%.
- creates and initializes a new AsyncGeneratorFunction object when called as a function rather than as a
constructor . Thus the function callAsyncGeneratorFunction (...)is equivalent to the object creation expressionnew AsyncGeneratorFunction (...)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedAsyncGeneratorFunctionbehaviour must include asupercall to theAsyncGeneratorFunctionconstructor to create and initialize subclass instances with the internal slots necessary for built-in AsyncGeneratorFunction behaviour. All ECMAScript syntactic forms for defining async generator function objects create direct instances ofAsyncGeneratorFunction. There is no syntactic means to create instances ofAsyncGeneratorFunctionsubclasses.
25.3.1.1 AsyncGeneratorFunction ( p1, p2, ..., pn, body )
The last argument specifies the body (executable code) of an async generator function; any preceding arguments specify formal parameters.
When the AsyncGeneratorFunction function is called with some arguments p1, p2, … , pn, body (where n might be 0, that is, there are no "p" arguments, and where body might also not be provided), the following steps are taken:
- Let C be the
active function object . - Let args be the argumentsList that was passed to this function by [[Call]] or [[Construct]].
- Return ?
CreateDynamicFunction (C, NewTarget,"async generator", args).
See NOTE for
25.3.2 Properties of the AsyncGeneratorFunction Constructor
The AsyncGeneratorFunction
- is a standard built-in
function object that inherits from theFunctionconstructor . - has a [[Prototype]] internal slot whose value is the intrinsic object
%Function% . - has a
nameproperty whose value is"AsyncGeneratorFunction". - has the following properties:
25.3.2.1 AsyncGeneratorFunction.length
This is a
25.3.2.2 AsyncGeneratorFunction.prototype
The initial value of AsyncGeneratorFunction.prototype is the intrinsic object %AsyncGenerator%.
This property has the attributes { [[Writable]]:
25.3.3 Properties of the AsyncGeneratorFunction Prototype Object
The AsyncGeneratorFunction prototype object:
- is an ordinary object.
- is not a
function object and does not have an [[ECMAScriptCode]] internal slot or any other of the internal slots listed inTable 27 orTable 69 . - is the value of the
prototypeproperty of the intrinsic object%AsyncGeneratorFunction% . - is the intrinsic object
%AsyncGenerator% . - has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% .
25.3.3.1 AsyncGeneratorFunction.prototype.constructor
The initial value of AsyncGeneratorFunction.prototype.constructor is the intrinsic object
This property has the attributes { [[Writable]]:
25.3.3.2 AsyncGeneratorFunction.prototype.prototype
The value of AsyncGeneratorFunction.prototype.prototype is the
This property has the attributes { [[Writable]]:
25.3.3.3 AsyncGeneratorFunction.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "AsyncGeneratorFunction".
This property has the attributes { [[Writable]]:
25.3.4 AsyncGeneratorFunction Instances
Every AsyncGeneratorFunction instance is an ECMAScript "generator".
Each AsyncGeneratorFunction instance has the following own properties:
25.3.4.1 length
The value of the length property is an length property depends on the function.
This property has the attributes { [[Writable]]:
25.3.4.2 name
The specification for the name property of Function instances given in
25.3.4.3 prototype
Whenever an AsyncGeneratorFunction instance is created another ordinary object is also created and is the initial value of the async generator function's prototype property. The value of the prototype property is used to initialize the [[Prototype]] internal slot of a newly created AsyncGenerator object when the generator
This property has the attributes { [[Writable]]:
Unlike function instances, the object that is the value of the an AsyncGeneratorFunction's prototype property does not have a constructor property whose value is the AsyncGeneratorFunction instance.
25.4 Generator Objects
A Generator object is an instance of a generator function and conforms to both the Iterator and Iterable interfaces.
Generator instances directly inherit properties from the object that is the value of the prototype property of the Generator function that created the instance. Generator instances indirectly inherit properties from the Generator Prototype intrinsic,
25.4.1 Properties of the Generator Prototype Object
The Generator prototype object:
- is the intrinsic object %GeneratorPrototype%.
- is the initial value of the
prototypeproperty of the intrinsic object%Generator% (the GeneratorFunction.prototype). - is an ordinary object.
- is not a Generator instance and does not have a [[GeneratorState]] internal slot.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%IteratorPrototype% . - has properties that are indirectly inherited by all Generator instances.
25.4.1.1 Generator.prototype.constructor
The initial value of Generator.prototype.constructor is the intrinsic object
This property has the attributes { [[Writable]]:
25.4.1.2 Generator.prototype.next ( value )
The next method performs the following steps:
- Let g be the
this value. - Return ?
GeneratorResume (g, value).
25.4.1.3 Generator.prototype.return ( value )
The return method performs the following steps:
- Let g be the
this value. - Let C be
Completion { [[Type]]:return , [[Value]]: value, [[Target]]:empty }. - Return ?
GeneratorResumeAbrupt (g, C).
25.4.1.4 Generator.prototype.throw ( exception )
The throw method performs the following steps:
- Let g be the
this value. - Let C be
ThrowCompletion (exception). - Return ?
GeneratorResumeAbrupt (g, C).
25.4.1.5 Generator.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Generator".
This property has the attributes { [[Writable]]:
25.4.2 Properties of Generator Instances
Generator instances are initially created with the internal slots described in
| Internal Slot | Description |
|---|---|
| [[GeneratorState]] |
The current execution state of the generator. The possible values are: "suspendedStart", "suspendedYield", "executing", and "completed".
|
| [[GeneratorContext]] |
The |
25.4.3 Generator Abstract Operations
25.4.3.1 GeneratorStart ( generator, generatorBody )
The abstract operation GeneratorStart with arguments generator and generatorBody performs the following steps:
Assert : The value of generator.[[GeneratorState]] isundefined .- Let genContext be the
running execution context . - Set the Generator component of genContext to generator.
- Set the code evaluation state of genContext such that when evaluation is resumed for that
execution context the following steps will be performed:- Let result be the result of evaluating generatorBody.
Assert : If we return here, the generator either threw an exception or performed either an implicit or explicit return.- Remove genContext from the
execution context stack and restore theexecution context that is at the top of theexecution context stack as therunning execution context . - Set generator.[[GeneratorState]] to
"completed". - Once a generator enters the
"completed"state it never leaves it and its associatedexecution context is never resumed. Any execution state associated with generator can be discarded at this point. - If result.[[Type]] is
normal , let resultValue beundefined . - Else if result.[[Type]] is
return , let resultValue be result.[[Value]]. - Else,
Assert : result.[[Type]] isthrow .- Return
Completion (result).
- Return
CreateIterResultObject (resultValue,true ).
- Set generator.[[GeneratorContext]] to genContext.
- Set generator.[[GeneratorState]] to
"suspendedStart". - Return
NormalCompletion (undefined ).
25.4.3.2 GeneratorValidate ( generator )
The abstract operation GeneratorValidate with argument generator performs the following steps:
- If
Type (generator) is not Object, throw aTypeError exception. - If generator does not have a [[GeneratorState]] internal slot, throw a
TypeError exception. Assert : generator also has a [[GeneratorContext]] internal slot.- Let state be generator.[[GeneratorState]].
- If state is
"executing", throw aTypeError exception. - Return state.
25.4.3.3 GeneratorResume ( generator, value )
The abstract operation GeneratorResume with arguments generator and value performs the following steps:
- Let state be ?
GeneratorValidate (generator). - If state is
"completed", returnCreateIterResultObject (undefined ,true ). Assert : state is either"suspendedStart"or"suspendedYield".- Let genContext be generator.[[GeneratorContext]].
- Let methodContext be the
running execution context . Suspend methodContext.- Set generator.[[GeneratorState]] to
"executing". - Push genContext onto the
execution context stack ; genContext is now therunning execution context . - Resume the suspended evaluation of genContext using
NormalCompletion (value) as the result of the operation that suspended it. Let result be the value returned by the resumed computation. Assert : When we return here, genContext has already been removed from theexecution context stack and methodContext is the currentlyrunning execution context .- Return
Completion (result).
25.4.3.4 GeneratorResumeAbrupt ( generator, abruptCompletion )
The abstract operation GeneratorResumeAbrupt with arguments generator and abruptCompletion performs the following steps:
- Let state be ?
GeneratorValidate (generator). - If state is
"suspendedStart", then- Set generator.[[GeneratorState]] to
"completed". - Once a generator enters the
"completed"state it never leaves it and its associatedexecution context is never resumed. Any execution state associated with generator can be discarded at this point. - Set state to
"completed".
- Set generator.[[GeneratorState]] to
- If state is
"completed", then- If abruptCompletion.[[Type]] is
return , then- Return
CreateIterResultObject (abruptCompletion.[[Value]],true ).
- Return
- Return
Completion (abruptCompletion).
- If abruptCompletion.[[Type]] is
Assert : state is"suspendedYield".- Let genContext be generator.[[GeneratorContext]].
- Let methodContext be the
running execution context . Suspend methodContext.- Set generator.[[GeneratorState]] to
"executing". - Push genContext onto the
execution context stack ; genContext is now therunning execution context . - Resume the suspended evaluation of genContext using abruptCompletion as the result of the operation that suspended it. Let result be the completion record returned by the resumed computation.
Assert : When we return here, genContext has already been removed from theexecution context stack and methodContext is the currentlyrunning execution context .- Return
Completion (result).
25.4.3.5 GetGeneratorKind ( )
- Let genContext be the
running execution context . - If genContext does not have a Generator component, return
non-generator . - Let generator be the Generator component of genContext.
- If generator has an [[AsyncGeneratorState]] internal slot, return
async . - Else, return
sync .
25.4.3.6 GeneratorYield ( iterNextObj )
The abstract operation GeneratorYield with argument iterNextObj performs the following steps:
Assert : iterNextObj is an Object that implements the IteratorResult interface.- Let genContext be the
running execution context . Assert : genContext is theexecution context of a generator.- Let generator be the value of the Generator component of genContext.
Assert :GetGeneratorKind () issync .- Set generator.[[GeneratorState]] to
"suspendedYield". - Remove genContext from the
execution context stack and restore theexecution context that is at the top of theexecution context stack as therunning execution context . - Set the code evaluation state of genContext such that when evaluation is resumed with a
Completion resumptionValue the following steps will be performed:- Return resumptionValue.
- NOTE: This returns to the evaluation of the
YieldExpression that originally called this abstract operation.
- Return
NormalCompletion (iterNextObj). - NOTE: This returns to the evaluation of the operation that had most previously resumed evaluation of genContext.
25.5 AsyncGenerator Objects
An AsyncGenerator object is an instance of an async generator function and conforms to both the AsyncIterator and AsyncIterable interfaces.
AsyncGenerator instances directly inherit properties from the object that is the value of the prototype property of the AsyncGenerator function that created the instance. AsyncGenerator instances indirectly inherit properties from the AsyncGenerator Prototype intrinsic,
25.5.1 Properties of the AsyncGenerator Prototype Object
The AsyncGenerator prototype object:
- is the intrinsic object %AsyncGeneratorPrototype%.
- is the initial value of the
prototypeproperty of the intrinsic object%AsyncGenerator% (the AsyncGeneratorFunction.prototype). - is an ordinary object.
- is not an AsyncGenerator instance and does not have an [[AsyncGeneratorState]] internal slot.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%AsyncIteratorPrototype% . - has properties that are indirectly inherited by all AsyncGenerator instances.
25.5.1.1 AsyncGenerator.prototype.constructor
The initial value of AsyncGenerator.prototype.constructor is the intrinsic object
This property has the attributes { [[Writable]]:
25.5.1.2 AsyncGenerator.prototype.next ( value )
- Let generator be the
this value. - Let completion be
NormalCompletion (value). - Return !
AsyncGeneratorEnqueue (generator, completion).
25.5.1.3 AsyncGenerator.prototype.return ( value )
- Let generator be the
this value. - Let completion be
Completion { [[Type]]:return , [[Value]]: value, [[Target]]:empty }. - Return !
AsyncGeneratorEnqueue (generator, completion).
25.5.1.4 AsyncGenerator.prototype.throw ( exception )
- Let generator be the
this value. - Let completion be
ThrowCompletion (exception). - Return !
AsyncGeneratorEnqueue (generator, completion).
25.5.1.5 AsyncGenerator.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "AsyncGenerator".
This property has the attributes { [[Writable]]:
25.5.2 Properties of AsyncGenerator Instances
AsyncGenerator instances are initially created with the internal slots described below:
| Internal Slot | Description |
|---|---|
| [[AsyncGeneratorState]] | The current execution state of the async generator. The possible values are: "suspendedStart", "suspendedYield", "executing", "awaiting-return", and "completed". |
| [[AsyncGeneratorContext]] | The |
| [[AsyncGeneratorQueue]] | A |
25.5.3 AsyncGenerator Abstract Operations
25.5.3.1 AsyncGeneratorRequest Records
The AsyncGeneratorRequest is a
They have the following fields:
| Field Name | Value | Meaning |
|---|---|---|
| [[Completion]] | A |
The completion which should be used to resume the async generator. |
| [[Capability]] | A PromiseCapability record | The promise capabilities associated with this request. |
25.5.3.2 AsyncGeneratorStart ( generator, generatorBody )
Assert : generator is an AsyncGenerator instance.Assert : generator.[[AsyncGeneratorState]] isundefined .- Let genContext be the
running execution context . - Set the Generator component of genContext to generator.
- Set the code evaluation state of genContext such that when evaluation is resumed for that
execution context the following steps will be performed:- Let result be the result of evaluating generatorBody.
Assert : If we return here, the async generator either threw an exception or performed either an implicit or explicit return.- Remove genContext from the
execution context stack and restore theexecution context that is at the top of theexecution context stack as therunning execution context . - Set generator.[[AsyncGeneratorState]] to
"completed". - If result is a normal completion, let resultValue be
undefined . - Else,
- Let resultValue be result.[[Value]].
- If result.[[Type]] is not
return , then- Return !
AsyncGeneratorReject (generator, resultValue).
- Return !
- Return !
AsyncGeneratorResolve (generator, resultValue,true ).
- Set generator.[[AsyncGeneratorContext]] to genContext.
- Set generator.[[AsyncGeneratorState]] to
"suspendedStart". - Set generator.[[AsyncGeneratorQueue]] to a new empty
List . - Return
undefined .
25.5.3.3 AsyncGeneratorResolve ( generator, value, done )
Assert : generator is an AsyncGenerator instance.- Let queue be generator.[[AsyncGeneratorQueue]].
Assert : queue is not an emptyList .- Remove the first element from queue and let next be the value of that element.
- Let promiseCapability be next.[[Capability]].
- Let iteratorResult be !
CreateIterResultObject (value, done). - Perform !
Call (promiseCapability.[[Resolve]],undefined , « iteratorResult »). - Perform !
AsyncGeneratorResumeNext (generator). - Return
undefined .
25.5.3.4 AsyncGeneratorReject ( generator, exception )
Assert : generator is an AsyncGenerator instance.- Let queue be generator.[[AsyncGeneratorQueue]].
Assert : queue is not an emptyList .- Remove the first element from queue and let next be the value of that element.
- Let promiseCapability be next.[[Capability]].
- Perform !
Call (promiseCapability.[[Reject]],undefined , « exception »). - Perform !
AsyncGeneratorResumeNext (generator). - Return
undefined .
25.5.3.5 AsyncGeneratorResumeNext ( generator )
Assert : generator is an AsyncGenerator instance.- Let state be generator.[[AsyncGeneratorState]].
Assert : state is not"executing".- If state is
"awaiting-return", returnundefined . - Let queue be generator.[[AsyncGeneratorQueue]].
- If queue is an empty
List , returnundefined . - Let next be the value of the first element of queue.
Assert : next is an AsyncGeneratorRequest record.- Let completion be next.[[Completion]].
- If completion is an
abrupt completion , then- If state is
"suspendedStart", then- Set generator.[[AsyncGeneratorState]] to
"completed". - Set state to
"completed".
- Set generator.[[AsyncGeneratorState]] to
- If state is
"completed", then- If completion.[[Type]] is
return , then- Set generator.[[AsyncGeneratorState]] to
"awaiting-return". - Let promiseCapability be !
NewPromiseCapability (%Promise% ). - Perform !
Call (promiseCapability.[[Resolve]],undefined , « completion.[[Value]] »). - Let stepsFulfilled be the algorithm steps defined in
AsyncGeneratorResumeNext Return Processor Fulfilled Functions . - Let onFulfilled be
CreateBuiltinFunction (stepsFulfilled, « [[Generator]] »). - Set onFulfilled.[[Generator]] to generator.
- Let stepsRejected be the algorithm steps defined in
AsyncGeneratorResumeNext Return Processor Rejected Functions . - Let onRejected be
CreateBuiltinFunction (stepsRejected, « [[Generator]] »). - Set onRejected.[[Generator]] to generator.
- Let throwawayCapability be !
NewPromiseCapability (%Promise% ). - Set throwawayCapability.[[Promise]].[[PromiseIsHandled]] to
true . - Perform !
PerformPromiseThen (promiseCapability.[[Promise]], onFulfilled, onRejected, throwawayCapability). - Return
undefined .
- Set generator.[[AsyncGeneratorState]] to
- Else,
Assert : completion.[[Type]] isthrow .- Perform !
AsyncGeneratorReject (generator, completion.[[Value]]). - Return
undefined .
- If completion.[[Type]] is
- If state is
- Else if state is
"completed", return !AsyncGeneratorResolve (generator,undefined ,true ). Assert : state is either"suspendedStart"or"suspendedYield".- Let genContext be generator.[[AsyncGeneratorContext]].
- Let callerContext be the
running execution context . Suspend callerContext.- Set generator.[[AsyncGeneratorState]] to
"executing". - Push genContext onto the
execution context stack ; genContext is now therunning execution context . - Resume the suspended evaluation of genContext using completion as the result of the operation that suspended it. Let result be the completion record returned by the resumed computation.
Assert : result is never anabrupt completion .Assert : When we return here, genContext has already been removed from theexecution context stack and callerContext is the currentlyrunning execution context .- Return
undefined .
25.5.3.5.1 AsyncGeneratorResumeNext Return Processor Fulfilled Functions
An
When an
- Set F.[[Generator]].[[AsyncGeneratorState]] to
"completed". - Return !
AsyncGeneratorResolve (F.[[Generator]], value,true ).
The length property of an
25.5.3.5.2 AsyncGeneratorResumeNext Return Processor Rejected Functions
An
When an
- Set F.[[Generator]].[[AsyncGeneratorState]] to
"completed". - Return !
AsyncGeneratorReject (F.[[Generator]], reason).
The length property of an
25.5.3.6 AsyncGeneratorEnqueue ( generator, completion )
Assert : completion is aCompletion Record .- Let promiseCapability be !
NewPromiseCapability (%Promise% ). - If
Type (generator) is not Object, or if generator does not have an [[AsyncGeneratorState]] internal slot, then- Let badGeneratorError be a newly created
TypeError object. - Perform !
Call (promiseCapability.[[Reject]],undefined , « badGeneratorError »). - Return promiseCapability.[[Promise]].
- Let badGeneratorError be a newly created
- Let queue be generator.[[AsyncGeneratorQueue]].
- Let request be AsyncGeneratorRequest { [[Completion]]: completion, [[Capability]]: promiseCapability }.
- Append request to the end of queue.
- Let state be generator.[[AsyncGeneratorState]].
- If state is not
"executing", then- Perform !
AsyncGeneratorResumeNext (generator).
- Perform !
- Return promiseCapability.[[Promise]].
25.5.3.7 AsyncGeneratorYield ( value )
The abstract operation AsyncGeneratorYield with argument value performs the following steps:
- Let genContext be the
running execution context . Assert : genContext is theexecution context of a generator.- Let generator be the value of the Generator component of genContext.
Assert :GetGeneratorKind () isasync .- Set value to ?
Await (value). - Set generator.[[AsyncGeneratorState]] to
"suspendedYield". - Remove genContext from the
execution context stack and restore theexecution context that is at the top of theexecution context stack as therunning execution context . - Set the code evaluation state of genContext such that when evaluation is resumed with a
Completion resumptionValue the following steps will be performed:- If resumptionValue.[[Type]] is not
return , returnCompletion (resumptionValue). - Let awaited be
Await (resumptionValue.[[Value]]). - If awaited.[[Type]] is
throw , returnCompletion (awaited). Assert : awaited.[[Type]] isnormal .- Return
Completion { [[Type]]:return , [[Value]]: awaited.[[Value]], [[Target]]:empty }. - NOTE: When one of the above steps returns, it returns to the evaluation of the
YieldExpression production that originally called this abstract operation.
- If resumptionValue.[[Type]] is not
- Return !
AsyncGeneratorResolve (generator, value,false ). - NOTE: This returns to the evaluation of the operation that had most previously resumed evaluation of genContext.
25.6 Promise Objects
A Promise is an object that is used as a placeholder for the eventual results of a deferred (and possibly asynchronous) computation.
Any Promise object is in one of three mutually exclusive states: fulfilled, rejected, and pending:
-
A promise
pis fulfilled ifp.then(f, r)will immediately enqueue aJob to call the functionf. -
A promise
pis rejected ifp.then(f, r)will immediately enqueue aJob to call the functionr. - A promise is pending if it is neither fulfilled nor rejected.
A promise is said to be settled if it is not pending, i.e. if it is either fulfilled or rejected.
A promise is resolved if it is settled or if it has been “locked in” to match the state of another promise. Attempting to resolve or reject a resolved promise has no effect. A promise is unresolved if it is not resolved. An unresolved promise is always in the pending state. A resolved promise may be pending, fulfilled or rejected.
25.6.1 Promise Abstract Operations
25.6.1.1 PromiseCapability Records
A PromiseCapability is a
PromiseCapability Records have the fields listed in
| Field Name | Value | Meaning |
|---|---|---|
| [[Promise]] | An object | An object that is usable as a promise. |
| [[Resolve]] |
A |
The function that is used to resolve the given promise object. |
| [[Reject]] |
A |
The function that is used to reject the given promise object. |
25.6.1.1.1 IfAbruptRejectPromise ( value, capability )
IfAbruptRejectPromise is a shorthand for a sequence of algorithm steps that use a PromiseCapability
IfAbruptRejectPromise (value, capability).
means the same thing as:
- If value is an
abrupt completion , then- Perform ?
Call (capability.[[Reject]],undefined , « value.[[Value]] »). - Return capability.[[Promise]].
- Perform ?
- Else if value is a
Completion Record , let value be value.[[Value]].
25.6.1.2 PromiseReaction Records
The PromiseReaction is a
PromiseReaction records have the fields listed in
| Field Name | Value | Meaning |
|---|---|---|
| [[Capability]] |
A PromiseCapability |
The capabilities of the promise for which this record provides a reaction handler. |
| [[Type]] |
Either "Fulfill" or "Reject".
|
The [[Type]] is used when [[Handler]] is |
| [[Handler]] |
A |
The function that should be applied to the incoming value, and whose return value will govern what happens to the derived promise. If [[Handler]] is |
25.6.1.3 CreateResolvingFunctions ( promise )
When CreateResolvingFunctions is performed with argument promise, the following steps are taken:
- Let alreadyResolved be a new
Record { [[Value]]:false }. - Let stepsResolve be the algorithm steps defined in Promise Resolve Functions (
25.6.1.3.2 ). - Let resolve be
CreateBuiltinFunction (stepsResolve, « [[Promise]], [[AlreadyResolved]] »). - Set resolve.[[Promise]] to promise.
- Set resolve.[[AlreadyResolved]] to alreadyResolved.
- Let stepsReject be the algorithm steps defined in Promise Reject Functions (
25.6.1.3.1 ). - Let reject be
CreateBuiltinFunction (stepsReject, « [[Promise]], [[AlreadyResolved]] »). - Set reject.[[Promise]] to promise.
- Set reject.[[AlreadyResolved]] to alreadyResolved.
- Return a new
Record { [[Resolve]]: resolve, [[Reject]]: reject }.
25.6.1.3.1 Promise Reject Functions
A promise reject function is an anonymous built-in function that has [[Promise]] and [[AlreadyResolved]] internal slots.
When a promise reject function F is called with argument reason, the following steps are taken:
Assert : F has a [[Promise]] internal slot whose value is an Object.- Let promise be F.[[Promise]].
- Let alreadyResolved be F.[[AlreadyResolved]].
- If alreadyResolved.[[Value]] is
true , returnundefined . - Set alreadyResolved.[[Value]] to
true . - Return
RejectPromise (promise, reason).
The length property of a promise reject function is 1.
25.6.1.3.2 Promise Resolve Functions
A promise resolve function is an anonymous built-in function that has [[Promise]] and [[AlreadyResolved]] internal slots.
When a promise resolve function F is called with argument resolution, the following steps are taken:
Assert : F has a [[Promise]] internal slot whose value is an Object.- Let promise be F.[[Promise]].
- Let alreadyResolved be F.[[AlreadyResolved]].
- If alreadyResolved.[[Value]] is
true , returnundefined . - Set alreadyResolved.[[Value]] to
true . - If
SameValue (resolution, promise) istrue , then- Let selfResolutionError be a newly created
TypeError object. - Return
RejectPromise (promise, selfResolutionError).
- Let selfResolutionError be a newly created
- If
Type (resolution) is not Object, then- Return
FulfillPromise (promise, resolution).
- Return
- Let then be
Get (resolution,"then"). - If then is an
abrupt completion , then- Return
RejectPromise (promise, then.[[Value]]).
- Return
- Let thenAction be then.[[Value]].
- If
IsCallable (thenAction) isfalse , then- Return
FulfillPromise (promise, resolution).
- Return
- Perform
EnqueueJob ("PromiseJobs",PromiseResolveThenableJob , « promise, resolution, thenAction »). - Return
undefined .
The length property of a promise resolve function is 1.
25.6.1.4 FulfillPromise ( promise, value )
When the FulfillPromise abstract operation is called with arguments promise and value, the following steps are taken:
Assert : The value of promise.[[PromiseState]] is"pending".- Let reactions be promise.[[PromiseFulfillReactions]].
- Set promise.[[PromiseResult]] to value.
- Set promise.[[PromiseFulfillReactions]] to
undefined . - Set promise.[[PromiseRejectReactions]] to
undefined . - Set promise.[[PromiseState]] to
"fulfilled". - Return
TriggerPromiseReactions (reactions, value).
25.6.1.5 NewPromiseCapability ( C )
The abstract operation NewPromiseCapability takes a Promise
- If
IsConstructor (C) isfalse , throw aTypeError exception. - NOTE: C is assumed to be a
constructor function that supports the parameter conventions of thePromiseconstructor (see25.6.3.1 ). - Let promiseCapability be a new PromiseCapability { [[Promise]]:
undefined , [[Resolve]]:undefined , [[Reject]]:undefined }. - Let steps be the algorithm steps defined in
GetCapabilitiesExecutor Functions . - Let executor be
CreateBuiltinFunction (steps, « [[Capability]] »). - Set executor.[[Capability]] to promiseCapability.
- Let promise be ?
Construct (C, « executor »). - If
IsCallable (promiseCapability.[[Resolve]]) isfalse , throw aTypeError exception. - If
IsCallable (promiseCapability.[[Reject]]) isfalse , throw aTypeError exception. - Set promiseCapability.[[Promise]] to promise.
- Return promiseCapability.
This abstract operation supports Promise subclassing, as it is generic on any
25.6.1.5.1 GetCapabilitiesExecutor Functions
A GetCapabilitiesExecutor function is an anonymous built-in function that has a [[Capability]] internal slot.
When a GetCapabilitiesExecutor function F is called with arguments resolve and reject, the following steps are taken:
Assert : F has a [[Capability]] internal slot whose value is a PromiseCapabilityRecord .- Let promiseCapability be F.[[Capability]].
- If promiseCapability.[[Resolve]] is not
undefined , throw aTypeError exception. - If promiseCapability.[[Reject]] is not
undefined , throw aTypeError exception. - Set promiseCapability.[[Resolve]] to resolve.
- Set promiseCapability.[[Reject]] to reject.
- Return
undefined .
The length property of a GetCapabilitiesExecutor function is 2.
25.6.1.6 IsPromise ( x )
The abstract operation IsPromise checks for the promise brand on an object.
- If
Type (x) is not Object, returnfalse . - If x does not have a [[PromiseState]] internal slot, return
false . - Return
true .
25.6.1.7 RejectPromise ( promise, reason )
When the RejectPromise abstract operation is called with arguments promise and reason, the following steps are taken:
Assert : The value of promise.[[PromiseState]] is"pending".- Let reactions be promise.[[PromiseRejectReactions]].
- Set promise.[[PromiseResult]] to reason.
- Set promise.[[PromiseFulfillReactions]] to
undefined . - Set promise.[[PromiseRejectReactions]] to
undefined . - Set promise.[[PromiseState]] to
"rejected". - If promise.[[PromiseIsHandled]] is
false , performHostPromiseRejectionTracker (promise,"reject"). - Return
TriggerPromiseReactions (reactions, reason).
25.6.1.8 TriggerPromiseReactions ( reactions, argument )
The abstract operation TriggerPromiseReactions takes a collection of PromiseReactionRecords and enqueues a new
- For each reaction in reactions, in original insertion order, do
- Perform
EnqueueJob ("PromiseJobs",PromiseReactionJob , « reaction, argument »).
- Perform
- Return
undefined .
25.6.1.9 HostPromiseRejectionTracker ( promise, operation )
HostPromiseRejectionTracker is an implementation-defined abstract operation that allows host environments to track promise rejections.
An implementation of HostPromiseRejectionTracker must complete normally in all cases. The default implementation of HostPromiseRejectionTracker is to unconditionally return an empty normal completion.
HostPromiseRejectionTracker is called in two scenarios:
- When a promise is rejected without any handlers, it is called with its operation argument set to
"reject". - When a handler is added to a rejected promise for the first time, it is called with its operation argument set to
"handle".
A typical implementation of HostPromiseRejectionTracker might try to notify developers of unhandled rejections, while also being careful to notify them if such previous notifications are later invalidated by new handlers being attached.
If operation is "handle", an implementation should not hold a reference to promise in a way that would interfere with garbage collection. An implementation may hold a reference to promise if operation is "reject", since it is expected that rejections will be rare and not on hot code paths.
25.6.2 Promise Jobs
25.6.2.1 PromiseReactionJob ( reaction, argument )
The job PromiseReactionJob with parameters reaction and argument applies the appropriate handler to the incoming value, and uses the handler's return value to resolve or reject the derived promise associated with that handler.
Assert : reaction is a PromiseReactionRecord .- Let promiseCapability be reaction.[[Capability]].
- Let type be reaction.[[Type]].
- Let handler be reaction.[[Handler]].
- If handler is
undefined , then- If type is
"Fulfill", let handlerResult beNormalCompletion (argument). - Else,
Assert : type is"Reject".- Let handlerResult be
ThrowCompletion (argument).
- If type is
- Else, let handlerResult be
Call (handler,undefined , « argument »). - If handlerResult is an
abrupt completion , then- Let status be
Call (promiseCapability.[[Reject]],undefined , « handlerResult.[[Value]] »).
- Let status be
- Else,
- Let status be
Call (promiseCapability.[[Resolve]],undefined , « handlerResult.[[Value]] »).
- Let status be
- Return
Completion (status).
25.6.2.2 PromiseResolveThenableJob ( promiseToResolve, thenable, then )
The job PromiseResolveThenableJob with parameters promiseToResolve, thenable, and then performs the following steps:
- Let resolvingFunctions be
CreateResolvingFunctions (promiseToResolve). - Let thenCallResult be
Call (then, thenable, « resolvingFunctions.[[Resolve]], resolvingFunctions.[[Reject]] »). - If thenCallResult is an
abrupt completion , then- Let status be
Call (resolvingFunctions.[[Reject]],undefined , « thenCallResult.[[Value]] »). - Return
Completion (status).
- Let status be
- Return
Completion (thenCallResult).
25.6.3 The Promise Constructor
The Promise
- is the intrinsic object %Promise%.
- is the initial value of the
Promiseproperty of theglobal object . - creates and initializes a new Promise object when called as a
constructor . - is not intended to be called as a function and will throw an exception when called in that manner.
- is designed to be subclassable. It may be used as the value in an
extendsclause of a class definition. Subclass constructors that intend to inherit the specifiedPromisebehaviour must include asupercall to thePromiseconstructor to create and initialize the subclass instance with the internal state necessary to support thePromiseandPromise.prototypebuilt-in methods.
25.6.3.1 Promise ( executor )
When the Promise function is called with argument executor, the following steps are taken:
- If NewTarget is
undefined , throw aTypeError exception. - If
IsCallable (executor) isfalse , throw aTypeError exception. - Let promise be ?
OrdinaryCreateFromConstructor (NewTarget,"%PromisePrototype%", « [[PromiseState]], [[PromiseResult]], [[PromiseFulfillReactions]], [[PromiseRejectReactions]], [[PromiseIsHandled]] »). - Set promise.[[PromiseState]] to
"pending". - Set promise.[[PromiseFulfillReactions]] to a new empty
List . - Set promise.[[PromiseRejectReactions]] to a new empty
List . - Set promise.[[PromiseIsHandled]] to
false . - Let resolvingFunctions be
CreateResolvingFunctions (promise). - Let completion be
Call (executor,undefined , « resolvingFunctions.[[Resolve]], resolvingFunctions.[[Reject]] »). - If completion is an
abrupt completion , then- Perform ?
Call (resolvingFunctions.[[Reject]],undefined , « completion.[[Value]] »).
- Perform ?
- Return promise.
The executor argument must be a
The resolve function that is passed to an executor function accepts a single argument. The executor code may eventually call the resolve function to indicate that it wishes to resolve the associated Promise object. The argument passed to the resolve function represents the eventual value of the deferred action and can be either the actual fulfillment value or another Promise object which will provide the value if it is fulfilled.
The reject function that is passed to an executor function accepts a single argument. The executor code may eventually call the reject function to indicate that the associated Promise is rejected and will never be fulfilled. The argument passed to the reject function is used as the rejection value of the promise. Typically it will be an Error object.
The resolve and reject functions passed to an executor function by the Promise
25.6.4 Properties of the Promise Constructor
The Promise
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - has the following properties:
25.6.4.1 Promise.all ( iterable )
The all function returns a new promise which is fulfilled with an array of fulfillment values for the passed promises, or rejects with the reason of the first passed promise that rejects. It resolves all elements of the passed iterable to promises as it runs this algorithm.
- Let C be the
this value. - If
Type (C) is not Object, throw aTypeError exception. - Let promiseCapability be ?
NewPromiseCapability (C). - Let iteratorRecord be
GetIterator (iterable). IfAbruptRejectPromise (iteratorRecord, promiseCapability).- Let result be
PerformPromiseAll (iteratorRecord, C, promiseCapability). - If result is an
abrupt completion , then- If iteratorRecord.[[Done]] is
false , let result beIteratorClose (iteratorRecord, result). IfAbruptRejectPromise (result, promiseCapability).
- If iteratorRecord.[[Done]] is
- Return
Completion (result).
This function is the %Promise_all% intrinsic object.
The all function requires its Promise
25.6.4.1.1 Runtime Semantics: PerformPromiseAll ( iteratorRecord, constructor, resultCapability )
When the PerformPromiseAll abstract operation is called with arguments iteratorRecord, constructor, and resultCapability, the following steps are taken:
Assert : constructor is aconstructor function.Assert : resultCapability is a PromiseCapabilityRecord .- Let values be a new empty
List . - Let remainingElementsCount be a new
Record { [[Value]]: 1 }. - Let index be 0.
- Repeat,
- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , then- Set iteratorRecord.[[Done]] to
true . - Set remainingElementsCount.[[Value]] to remainingElementsCount.[[Value]] - 1.
- If remainingElementsCount.[[Value]] is 0, then
- Let valuesArray be
CreateArrayFromList (values). - Perform ?
Call (resultCapability.[[Resolve]],undefined , « valuesArray »).
- Let valuesArray be
- Return resultCapability.[[Promise]].
- Set iteratorRecord.[[Done]] to
- Let nextValue be
IteratorValue (next). - If nextValue is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (nextValue).- Append
undefined to values. - Let nextPromise be ?
Invoke (constructor,"resolve", « nextValue »). - Let steps be the algorithm steps defined in
Promise.allResolve Element Functions - Let resolveElement be
CreateBuiltinFunction (steps, « [[AlreadyCalled]], [[Index]], [[Values]], [[Capability]], [[RemainingElements]] »). - Set resolveElement.[[AlreadyCalled]] to a new
Record { [[Value]]:false }. - Set resolveElement.[[Index]] to index.
- Set resolveElement.[[Values]] to values.
- Set resolveElement.[[Capability]] to resultCapability.
- Set resolveElement.[[RemainingElements]] to remainingElementsCount.
- Set remainingElementsCount.[[Value]] to remainingElementsCount.[[Value]] + 1.
- Perform ?
Invoke (nextPromise,"then", « resolveElement, resultCapability.[[Reject]] »). - Set index to index + 1.
- Let next be
25.6.4.1.2 Promise.all Resolve Element Functions
A Promise.all resolve element function is an anonymous built-in function that is used to resolve a specific Promise.all element. Each Promise.all resolve element function has [[Index]], [[Values]], [[Capability]], [[RemainingElements]], and [[AlreadyCalled]] internal slots.
When a Promise.all resolve element function F is called with argument x, the following steps are taken:
- Let alreadyCalled be F.[[AlreadyCalled]].
- If alreadyCalled.[[Value]] is
true , returnundefined . - Set alreadyCalled.[[Value]] to
true . - Let index be F.[[Index]].
- Let values be F.[[Values]].
- Let promiseCapability be F.[[Capability]].
- Let remainingElementsCount be F.[[RemainingElements]].
- Set values[index] to x.
- Set remainingElementsCount.[[Value]] to remainingElementsCount.[[Value]] - 1.
- If remainingElementsCount.[[Value]] is 0, then
- Let valuesArray be
CreateArrayFromList (values). - Return ?
Call (promiseCapability.[[Resolve]],undefined , « valuesArray »).
- Let valuesArray be
- Return
undefined .
The length property of a Promise.all resolve element function is 1.
25.6.4.2 Promise.prototype
The initial value of Promise.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
25.6.4.3 Promise.race ( iterable )
The race function returns a new promise which is settled in the same way as the first passed promise to settle. It resolves all elements of the passed iterable to promises as it runs this algorithm.
- Let C be the
this value. - If
Type (C) is not Object, throw aTypeError exception. - Let promiseCapability be ?
NewPromiseCapability (C). - Let iteratorRecord be
GetIterator (iterable). IfAbruptRejectPromise (iteratorRecord, promiseCapability).- Let result be
PerformPromiseRace (iteratorRecord, C, promiseCapability). - If result is an
abrupt completion , then- If iteratorRecord.[[Done]] is
false , let result beIteratorClose (iterator, result). IfAbruptRejectPromise (result, promiseCapability).
- If iteratorRecord.[[Done]] is
- Return
Completion (result).
If the iterable argument is empty or if none of the promises in iterable ever settle then the pending promise returned by this method will never be settled.
The race function expects its Promise resolve method.
25.6.4.3.1 Runtime Semantics: PerformPromiseRace ( iteratorRecord, constructor, resultCapability )
When the PerformPromiseRace abstract operation is called with arguments iteratorRecord, constructor, and resultCapability, the following steps are taken:
Assert : constructor is aconstructor function.Assert : resultCapability is a PromiseCapabilityRecord .- Repeat,
- Let next be
IteratorStep (iteratorRecord). - If next is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (next).- If next is
false , then- Set iteratorRecord.[[Done]] to
true . - Return resultCapability.[[Promise]].
- Set iteratorRecord.[[Done]] to
- Let nextValue be
IteratorValue (next). - If nextValue is an
abrupt completion , set iteratorRecord.[[Done]] totrue . ReturnIfAbrupt (nextValue).- Let nextPromise be ?
Invoke (constructor,"resolve", « nextValue »). - Perform ?
Invoke (nextPromise,"then", « resultCapability.[[Resolve]], resultCapability.[[Reject]] »).
- Let next be
25.6.4.4 Promise.reject ( r )
The reject function returns a new promise rejected with the passed argument.
- Let C be the
this value. - If
Type (C) is not Object, throw aTypeError exception. - Let promiseCapability be ?
NewPromiseCapability (C). - Perform ?
Call (promiseCapability.[[Reject]],undefined , « r »). - Return promiseCapability.[[Promise]].
This function is the %Promise_reject% intrinsic object.
The reject function expects its Promise
25.6.4.5 Promise.resolve ( x )
The resolve function returns either a new promise resolved with the passed argument, or the argument itself if the argument is a promise produced by this
- Let C be the
this value. - If
Type (C) is not Object, throw aTypeError exception. - Return ?
PromiseResolve (C, x).
This function is the %Promise_resolve% intrinsic object.
The resolve function expects its Promise
25.6.4.5.1 PromiseResolve ( C, x )
The abstract operation PromiseResolve, given a
25.6.4.6 get Promise [ @@species ]
Promise[@@species] is an
- Return the
this value.
The value of the name property of this function is "get [Symbol.species]".
Promise prototype methods normally use their this object's
25.6.5 Properties of the Promise Prototype Object
The Promise prototype object:
- is the intrinsic object %PromisePrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is an ordinary object.
- does not have a [[PromiseState]] internal slot or any of the other internal slots of Promise instances.
25.6.5.1 Promise.prototype.catch ( onRejected )
When the catch method is called with argument onRejected, the following steps are taken:
- Let promise be the
this value. - Return ?
Invoke (promise,"then", «undefined , onRejected »).
25.6.5.2 Promise.prototype.constructor
The initial value of Promise.prototype.constructor is the intrinsic object
25.6.5.3 Promise.prototype.finally ( onFinally )
When the finally method is called with argument onFinally, the following steps are taken:
- Let promise be the
this value. - If
Type (promise) is not Object, throw aTypeError exception. - Let C be ?
SpeciesConstructor (promise,%Promise% ). Assert :IsConstructor (C) istrue .- If
IsCallable (onFinally) isfalse , then- Let thenFinally be onFinally.
- Let catchFinally be onFinally.
- Else,
- Let stepsThenFinally be the algorithm steps defined in
Then Finally Functions . - Let thenFinally be
CreateBuiltinFunction (stepsThenFinally, « [[Constructor]], [[OnFinally]] »). - Set thenFinally.[[Constructor]] to C.
- Set thenFinally.[[OnFinally]] to onFinally.
- Let stepsCatchFinally be the algorithm steps defined in
Catch Finally Functions . - Let catchFinally be
CreateBuiltinFunction (stepsCatchFinally, « [[Constructor]], [[OnFinally]] »). - Set catchFinally.[[Constructor]] to C.
- Set catchFinally.[[OnFinally]] to onFinally.
- Let stepsThenFinally be the algorithm steps defined in
- Return ?
Invoke (promise,"then", « thenFinally, catchFinally »).
25.6.5.3.1 Then Finally Functions
A Then Finally function is an anonymous built-in function that has a [[Constructor]] and an [[OnFinally]] internal slot. The value of the [[Constructor]] internal slot is a Promise-like
When a Then Finally function F is called with argument value, the following steps are taken:
- Let onFinally be F.[[OnFinally]].
Assert :IsCallable (onFinally) istrue .- Let result be ?
Call (onFinally,undefined ). - Let C be F.[[Constructor]].
Assert :IsConstructor (C) istrue .- Let promise be ?
PromiseResolve (C, result). - Let valueThunk be equivalent to a function that returns value.
- Return ?
Invoke (promise,"then", « valueThunk »).
The length property of a Then Finally function is
25.6.5.3.2 Catch Finally Functions
A Catch Finally function is an anonymous built-in function that has a [[Constructor]] and an [[OnFinally]] internal slot. The value of the [[Constructor]] internal slot is a Promise-like
When a Catch Finally function F is called with argument reason, the following steps are taken:
- Let onFinally be F.[[OnFinally]].
Assert :IsCallable (onFinally) istrue .- Let result be ?
Call (onFinally,undefined ). - Let C be F.[[Constructor]].
Assert :IsConstructor (C) istrue .- Let promise be ?
PromiseResolve (C, result). - Let thrower be equivalent to a function that throws reason.
- Return ?
Invoke (promise,"then", « thrower »).
The length property of a Catch Finally function is
25.6.5.4 Promise.prototype.then ( onFulfilled, onRejected )
When the then method is called with arguments onFulfilled and onRejected, the following steps are taken:
- Let promise be the
this value. - If
IsPromise (promise) isfalse , throw aTypeError exception. - Let C be ?
SpeciesConstructor (promise,%Promise% ). - Let resultCapability be ?
NewPromiseCapability (C). - Return
PerformPromiseThen (promise, onFulfilled, onRejected, resultCapability).
This function is the %PromiseProto_then% intrinsic object.
25.6.5.4.1 PerformPromiseThen ( promise, onFulfilled, onRejected, resultCapability )
The abstract operation PerformPromiseThen performs the “then” operation on promise using onFulfilled and onRejected as its settlement actions. The result is resultCapability's promise.
Assert :IsPromise (promise) istrue .Assert : resultCapability is a PromiseCapabilityRecord .- If
IsCallable (onFulfilled) isfalse , then- Set onFulfilled to
undefined .
- Set onFulfilled to
- If
IsCallable (onRejected) isfalse , then- Set onRejected to
undefined .
- Set onRejected to
- Let fulfillReaction be the PromiseReaction { [[Capability]]: resultCapability, [[Type]]:
"Fulfill", [[Handler]]: onFulfilled }. - Let rejectReaction be the PromiseReaction { [[Capability]]: resultCapability, [[Type]]:
"Reject", [[Handler]]: onRejected }. - If promise.[[PromiseState]] is
"pending", then - Else if promise.[[PromiseState]] is
"fulfilled", then- Let value be promise.[[PromiseResult]].
- Perform
EnqueueJob ("PromiseJobs",PromiseReactionJob , « fulfillReaction, value »).
- Else,
Assert : The value of promise.[[PromiseState]] is"rejected".- Let reason be promise.[[PromiseResult]].
- If promise.[[PromiseIsHandled]] is
false , performHostPromiseRejectionTracker (promise,"handle"). - Perform
EnqueueJob ("PromiseJobs",PromiseReactionJob , « rejectReaction, reason »).
- Set promise.[[PromiseIsHandled]] to
true . - Return resultCapability.[[Promise]].
25.6.5.5 Promise.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the String value "Promise".
This property has the attributes { [[Writable]]:
25.6.6 Properties of Promise Instances
Promise instances are ordinary objects that inherit properties from the Promise prototype object (the intrinsic,
| Internal Slot | Description |
|---|---|
| [[PromiseState]] |
A String value that governs how a promise will react to incoming calls to its then method. The possible values are: "pending", "fulfilled", and "rejected".
|
| [[PromiseResult]] |
The value with which the promise has been fulfilled or rejected, if any. Only meaningful if [[PromiseState]] is not "pending".
|
| [[PromiseFulfillReactions]] |
A "pending" state to the "fulfilled" state.
|
| [[PromiseRejectReactions]] |
A "pending" state to the "rejected" state.
|
| [[PromiseIsHandled]] | A boolean indicating whether the promise has ever had a fulfillment or rejection handler; used in unhandled rejection tracking. |
25.7 AsyncFunction Objects
AsyncFunction objects are functions that are usually created by evaluating
25.7.1 The AsyncFunction Constructor
The AsyncFunction
- is the intrinsic object %AsyncFunction%.
- is a subclass of
Function. - creates and initializes a new AsyncFunction object when called as a function rather than as a
constructor . Thus the function callAsyncFunction(…)is equivalent to the object creation expressionnew AsyncFunction(…)with the same arguments. - is designed to be subclassable. It may be used as the value of an
extendsclause of a class definition. Subclass constructors that intend to inherit the specified AsyncFunction behaviour must include asupercall to theAsyncFunctionconstructor to create and initialize a subclass instance with the internal slots necessary for built-in async function behaviour.
25.7.1.1 AsyncFunction ( p1, p2, … , pn, body )
The last argument specifies the body (executable code) of an async function. Any preceding arguments specify formal parameters.
When the AsyncFunction function is called with some arguments p1, p2, …, pn, body (where n might be 0, that is, there are no p arguments, and where body might also not be provided), the following steps are taken:
- Let C be the
active function object . - Let args be the argumentsList that was passed to this function by [[Call]] or [[Construct]].
- Return
CreateDynamicFunction (C, NewTarget,"async", args).
25.7.2 Properties of the AsyncFunction Constructor
The AsyncFunction
- is a standard built-in
function object that inherits from theFunctionconstructor . - has a [[Prototype]] internal slot whose value is the intrinsic object
%Function% . - has a
nameproperty whose value is"AsyncFunction". - has the following properties:
25.7.2.1 AsyncFunction.length
This is a
25.7.2.2 AsyncFunction.prototype
The initial value of AsyncFunction.prototype is the intrinsic object
This property has the attributes { [[Writable]]:
25.7.3 Properties of the AsyncFunction Prototype Object
The AsyncFunction prototype object:
- is an ordinary object.
- is not a
function object and does not have an [[ECMAScriptCode]] internal slot or any other of the internal slots listed inTable 27 . - is the value of the
prototypeproperty of the intrinsic object%AsyncFunction% . - is the intrinsic object %AsyncFunctionPrototype%.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% .
25.7.3.1 AsyncFunction.prototype.constructor
The initial value of AsyncFunction.prototype.constructor is the intrinsic object
This property has the attributes { [[Writable]]:
25.7.3.2 AsyncFunction.prototype [ @@toStringTag ]
The initial value of the @@toStringTag property is the string value "AsyncFunction".
This property has the attributes { [[Writable]]:
25.7.4 AsyncFunction Instances
Every AsyncFunction instance is an ECMAScript "async". AsyncFunction instances are not constructors and do not have a [[Construct]] internal method. AsyncFunction instances do not have a prototype property as they are not constructable.
Each AsyncFunction instance has the following own properties:
25.7.4.1 length
The specification for the length property of Function instances given in
25.7.4.2 name
The specification for the name property of Function instances given in
25.7.5 Async Functions Abstract Operations
25.7.5.1 AsyncFunctionStart ( promiseCapability, asyncFunctionBody )
- Let runningContext be the
running execution context . - Let asyncContext be a copy of runningContext.
- Set the code evaluation state of asyncContext such that when evaluation is resumed for that
execution context the following steps will be performed:- Let result be the result of evaluating asyncFunctionBody.
Assert : If we return here, the async function either threw an exception or performed an implicit or explicit return; all awaiting is done.- Remove asyncContext from the
execution context stack and restore theexecution context that is at the top of theexecution context stack as therunning execution context . - If result.[[Type]] is
normal , then- Perform !
Call (promiseCapability.[[Resolve]],undefined , «undefined »).
- Perform !
- Else if result.[[Type]] is
return , then- Perform !
Call (promiseCapability.[[Resolve]],undefined , « result.[[Value]] »).
- Perform !
- Else,
- Return.
- Push asyncContext onto the
execution context stack ; asyncContext is now therunning execution context . - Resume the suspended evaluation of asyncContext. Let result be the value returned by the resumed computation.
Assert : When we return here, asyncContext has already been removed from theexecution context stack and runningContext is the currentlyrunning execution context .Assert : result is a normal completion with a value ofundefined . The possible sources of completion values areAwait or, if the async function doesn't await anything, the step 3.g above.- Return.
26 Reflection
26.1 The Reflect Object
The Reflect object:
- is the intrinsic object %Reflect%.
- is the initial value of the
Reflectproperty of theglobal object . - is an ordinary object.
- has a [[Prototype]] internal slot whose value is the intrinsic object
%ObjectPrototype% . - is not a
function object . - does not have a [[Construct]] internal method; it cannot be used as a
constructor with thenewoperator. - does not have a [[Call]] internal method; it cannot be invoked as a function.
26.1.1 Reflect.apply ( target, thisArgument, argumentsList )
When the apply function is called with arguments target, thisArgument, and argumentsList, the following steps are taken:
- If
IsCallable (target) isfalse , throw aTypeError exception. - Let args be ?
CreateListFromArrayLike (argumentsList). - Perform
PrepareForTailCall (). - Return ?
Call (target, thisArgument, args).
26.1.2 Reflect.construct ( target, argumentsList [ , newTarget ] )
When the construct function is called with arguments target, argumentsList, and newTarget, the following steps are taken:
- If
IsConstructor (target) isfalse , throw aTypeError exception. - If newTarget is not present, let newTarget be target.
- Else if
IsConstructor (newTarget) isfalse , throw aTypeError exception. - Let args be ?
CreateListFromArrayLike (argumentsList). - Return ?
Construct (target, args, newTarget).
26.1.3 Reflect.defineProperty ( target, propertyKey, attributes )
When the defineProperty function is called with arguments target, propertyKey, and attributes, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (propertyKey). - Let desc be ?
ToPropertyDescriptor (attributes). - Return ? target.[[DefineOwnProperty]](key, desc).
26.1.4 Reflect.deleteProperty ( target, propertyKey )
When the deleteProperty function is called with arguments target and propertyKey, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (propertyKey). - Return ? target.[[Delete]](key).
26.1.5 Reflect.get ( target, propertyKey [ , receiver ] )
When the get function is called with arguments target, propertyKey, and receiver, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (propertyKey). - If receiver is not present, then
- Let receiver be target.
- Return ? target.[[Get]](key, receiver).
26.1.6 Reflect.getOwnPropertyDescriptor ( target, propertyKey )
When the getOwnPropertyDescriptor function is called with arguments target and propertyKey, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (propertyKey). - Let desc be ? target.[[GetOwnProperty]](key).
- Return
FromPropertyDescriptor (desc).
26.1.7 Reflect.getPrototypeOf ( target )
When the getPrototypeOf function is called with argument target, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Return ? target.[[GetPrototypeOf]]().
26.1.8 Reflect.has ( target, propertyKey )
When the has function is called with arguments target and propertyKey, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (propertyKey). - Return ? target.[[HasProperty]](key).
26.1.9 Reflect.isExtensible ( target )
When the isExtensible function is called with argument target, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Return ? target.[[IsExtensible]]().
26.1.10 Reflect.ownKeys ( target )
When the ownKeys function is called with argument target, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let keys be ? target.[[OwnPropertyKeys]]().
- Return
CreateArrayFromList (keys).
26.1.11 Reflect.preventExtensions ( target )
When the preventExtensions function is called with argument target, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Return ? target.[[PreventExtensions]]().
26.1.12 Reflect.set ( target, propertyKey, V [ , receiver ] )
When the set function is called with arguments target, V, propertyKey, and receiver, the following steps are taken:
- If
Type (target) is not Object, throw aTypeError exception. - Let key be ?
ToPropertyKey (propertyKey). - If receiver is not present, then
- Let receiver be target.
- Return ? target.[[Set]](key, V, receiver).
26.1.13 Reflect.setPrototypeOf ( target, proto )
When the setPrototypeOf function is called with arguments target and proto, the following steps are taken:
26.2 Proxy Objects
26.2.1 The Proxy Constructor
The Proxy
- is the intrinsic object %Proxy%.
- is the initial value of the
Proxyproperty of theglobal object . - creates and initializes a new proxy
exotic object when called as aconstructor . - is not intended to be called as a function and will throw an exception when called in that manner.
26.2.1.1 Proxy ( target, handler )
When Proxy is called with arguments target and handler performs the following steps:
- If NewTarget is
undefined , throw aTypeError exception. - Return ?
ProxyCreate (target, handler).
26.2.2 Properties of the Proxy Constructor
The Proxy
- has a [[Prototype]] internal slot whose value is the intrinsic object
%FunctionPrototype% . - does not have a
prototypeproperty because proxy exotic objects do not have a [[Prototype]] internal slot that requires initialization. - has the following properties:
26.2.2.1 Proxy.revocable ( target, handler )
The Proxy.revocable function is used to create a revocable Proxy object. When Proxy.revocable is called with arguments target and handler, the following steps are taken:
- Let p be ?
ProxyCreate (target, handler). - Let steps be the algorithm steps defined in
Proxy Revocation Functions . - Let revoker be
CreateBuiltinFunction (steps, « [[RevocableProxy]] »). - Set revoker.[[RevocableProxy]] to p.
- Let result be
ObjectCreate (%ObjectPrototype% ). - Perform
CreateDataProperty (result,"proxy", p). - Perform
CreateDataProperty (result,"revoke", revoker). - Return result.
26.2.2.1.1 Proxy Revocation Functions
A Proxy revocation function is an anonymous function that has the ability to invalidate a specific Proxy object.
Each Proxy revocation function has a [[RevocableProxy]] internal slot.
When a Proxy revocation function, F, is called, the following steps are taken:
- Let p be F.[[RevocableProxy]].
- If p is
null , returnundefined . - Set F.[[RevocableProxy]] to
null . Assert : p is a Proxy object.- Set p.[[ProxyTarget]] to
null . - Set p.[[ProxyHandler]] to
null . - Return
undefined .
The length property of a Proxy revocation function is 0.
26.3 Module Namespace Objects
A Module Namespace Object is a module namespace
In addition to the properties specified in
26.3.1 @@toStringTag
The initial value of the @@toStringTag property is the String value "Module".
This property has the attributes { [[Writable]]:
27 Memory Model
The memory consistency model, or memory model, specifies the possible orderings of
The memory model is defined as relational constraints on events introduced by
This section provides an axiomatic model on events introduced by the
27.1 Memory Model Fundamentals
Shared memory accesses (reads and writes) are divided into two groups, atomic accesses and data accesses, defined below. Atomic accesses are sequentially consistent, i.e., there is a strict total ordering of events agreed upon by all agents in an
No orderings weaker than sequentially consistent and stronger than unordered, such as release-acquire, are supported.
A Shared Data Block event is either a ReadSharedMemory, WriteSharedMemory, or ReadModifyWriteSharedMemory
| Field Name | Value | Meaning |
|---|---|---|
| [[Order]] | "SeqCst" or "Unordered" |
The weakest ordering guaranteed by the |
| [[NoTear]] | A Boolean | Whether this event is allowed to read from multiple write events on equal range as this event. |
| [[Block]] | A |
The block the event operates on. |
| [[ByteIndex]] | A nonnegative |
The byte address of the read in [[Block]]. |
| [[ElementSize]] | A nonnegative |
The size of the read. |
| Field Name | Value | Meaning |
|---|---|---|
| [[Order]] | "SeqCst", "Unordered", or "Init" |
The weakest ordering guaranteed by the |
| [[NoTear]] | A Boolean | Whether this event is allowed to be read from multiple read events with equal range as this event. |
| [[Block]] | A |
The block the event operates on. |
| [[ByteIndex]] | A nonnegative |
The byte address of the write in [[Block]]. |
| [[ElementSize]] | A nonnegative |
The size of the write. |
| [[Payload]] | A |
The |
| Field Name | Value | Meaning |
|---|---|---|
| [[Order]] | "SeqCst" |
Read-modify-write events are always sequentially consistent. |
| [[NoTear]] | Read-modify-write events cannot tear. | |
| [[Block]] | A |
The block the event operates on. |
| [[ByteIndex]] | A nonnegative |
The byte address of the read-modify-write in [[Block]]. |
| [[ElementSize]] | A nonnegative |
The size of the read-modify-write. |
| [[Payload]] | A |
The |
| [[ModifyOp]] | A semantic function | A pure semantic function that returns a modified |
These events are introduced by
In addition to
Let the range of a ReadSharedMemory, WriteSharedMemory, or ReadModifyWriteSharedMemory event be the Set of contiguous integers from its [[ByteIndex]] to [[ByteIndex]]+[[ElementSize]]-1. Two events' ranges are equal when the events have the same [[Block]], and the ranges are element-wise equal. Two events' ranges are overlapping when the events have the same [[Block]], the ranges are not equal and their intersection is non-empty. Two events' ranges are disjoint when the events do not have the same [[Block]] or their ranges are neither equal nor overlapping.
Examples of host-specific synchronizing events that should be accounted for are: sending a SharedArrayBuffer from one postMessage in a browser), starting and stopping agents, and communicating within the
27.2 Agent Events Records
An Agent Events Record is a
| Field Name | Value | Meaning |
|---|---|---|
| [[AgentSignifier]] | A value that admits equality testing | The |
| [[EventList]] | A |
Events are appended to the list during evaluation. |
27.3 Chosen Value Records
A Chosen Value Record is a
| Field Name | Value | Meaning |
|---|---|---|
| [[Event]] | A |
The |
| [[ChosenValue]] | A |
The bytes that were nondeterministically chosen during evaluation. |
27.4 Candidate Executions
A candidate execution of the evaluation of an
| Field Name | Value | Meaning |
|---|---|---|
| [[EventLists]] | A |
Maps an |
| [[ChosenValues]] | A |
Maps |
| [[AgentOrder]] | An |
Defined below. |
| [[ReadsBytesFrom]] | A |
Defined below. |
| [[ReadsFrom]] | A |
Defined below. |
| [[HostSynchronizesWith]] | A |
Defined below. |
| [[SynchronizesWith]] | A |
Defined below. |
| [[HappensBefore]] | A |
Defined below. |
An empty candidate execution is a candidate execution
27.5 Abstract Operations for the Memory Model
27.5.1 EventSet ( execution )
The abstract operation EventSet takes one argument, a
- Let events be an empty Set.
- For each
Agent Events Record aer in execution.[[EventLists]], do- For each event E in aer.[[EventList]], do
- Add E to events.
- For each event E in aer.[[EventList]], do
- Return events.
27.5.2 SharedDataBlockEventSet ( execution )
The abstract operation SharedDataBlockEventSet takes one argument, a
- Let events be an empty Set.
- For each event E in
EventSet (execution), do- If E is a
ReadSharedMemory ,WriteSharedMemory , orReadModifyWriteSharedMemory event, add E to events.
- If E is a
- Return events.
27.5.3 HostEventSet ( execution )
The abstract operation HostEventSet takes one argument, a
- Let events be an empty Set.
- For each event E in
EventSet (execution), do- If E is not in
SharedDataBlockEventSet (execution), add E to events.
- If E is not in
- Return events.
27.5.4 ComposeWriteEventBytes ( execution, byteIndex, Ws )
The abstract operation ComposeWriteEventBytes takes four arguments, a
- Let byteLocation be byteIndex.
- Let bytesRead be a new empty
List . - For each element W of Ws in
List order, doAssert : W has byteLocation in its range.- Let payloadIndex be byteLocation - W.[[ByteIndex]].
- If W is a
WriteSharedMemory event, then- Let byte be W.[[Payload]][payloadIndex].
- Else,
Assert : W is aReadModifyWriteSharedMemory event.- Let bytes be
ValueOfReadEvent (execution, W). - Let bytesModified be W.[[ModifyOp]](bytes, W.[[Payload]]).
- Let byte be bytesModified[payloadIndex].
- Append byte to bytesRead.
- Increment byteLocation by 1.
- Return bytesRead.
The semantic function [[ModifyOp]] is given by the function properties on the Atomics object that introduce
This abstract operation composes a
27.5.5 ValueOfReadEvent ( execution, R )
The abstract operation ValueOfReadEvent takes two arguments, a
Assert : R is aReadSharedMemory orReadModifyWriteSharedMemory event.- Let Ws be execution.[[ReadsBytesFrom]](R).
Assert : Ws is aList ofWriteSharedMemory orReadModifyWriteSharedMemory events with length equal to R.[[ElementSize]].- Return
ComposeWriteEventBytes (execution, R.[[ByteIndex]], Ws).
27.6 Relations of Candidate Executions
27.6.1 agent-order
For a
- For each pair (E, D) in
EventSet (execution), (E, D) is in execution.[[AgentOrder]] if there is someAgent Events Record aer in execution.[[EventLists]] such that E and D are in aer.[[EventList]] and E is before D inList order of aer.[[EventList]].
Each
27.6.2 reads-bytes-from
For a
-
For each
ReadSharedMemory orReadModifyWriteSharedMemory event R inSharedDataBlockEventSet (execution), execution.[[ReadsBytesFrom]](R) is aList of length equal to R.[[ElementSize]] ofWriteSharedMemory orReadModifyWriteSharedMemory events Ws such that all of the following are true.- Each event W with index i in Ws has R.[[ByteIndex]]+i in its range.
- R is not in Ws.
27.6.3 reads-from
For a
- For each pair (R, W) in
SharedDataBlockEventSet (execution), (R, W) is in execution.[[ReadsFrom]] if W is in execution.[[ReadsBytesFrom]](R).
27.6.4 host-synchronizes-with
For a
- If (E, D) is in execution.[[HostSynchronizesWith]], E and D are in
HostEventSet (execution). - There is no cycle in the union of execution.[[HostSynchronizesWith]] and execution.[[AgentOrder]].
For two host-specific events E and D, E host-synchronizes-with D implies E
The host-synchronizes-with relation allows the host to provide additional synchronization mechanisms, such as postMessage between HTML workers.
27.6.5 synchronizes-with
For a
-
For each pair (R, W) in execution.[[ReadsFrom]], (W, R) is in execution.[[SynchronizesWith]] if all the following are true.
- R.[[Order]] is
"SeqCst". - W.[[Order]] is
"SeqCst"or"Init". - If W.[[Order]] is
"SeqCst", then R and W have equal ranges. - If W.[[Order]] is
"Init", then for each event V such that (R, V) is in execution.[[ReadsFrom]], V.[[Order]] is"Init".
- R.[[Order]] is
- For each pair (E, D) in execution.[[HostSynchronizesWith]], (E, D) is in execution.[[SynchronizesWith]].
Owing to convention, write events synchronizes-with read events, instead of read events synchronizes-with write events.
Not all "SeqCst" events related by
For an event R and an event W such that W synchronizes-with R, R may
27.6.6 happens-before
For a
- For each pair (E, D) in execution.[[AgentOrder]], (E, D) is in execution.[[HappensBefore]].
- For each pair (E, D) in execution.[[SynchronizesWith]], (E, D) is in execution.[[HappensBefore]].
- For each pair (E, D) in
SharedDataBlockEventSet (execution), (E, D) is in execution.[[HappensBefore]] if E.[[Order]] is"Init"and E and D have overlapping ranges. - For each pair (E, D) in
EventSet (execution), (E, D) is in execution.[[HappensBefore]] if there is an event F such that the pairs (E, F) and (F, D) are in execution.[[HappensBefore]].
Because happens-before is a superset of
27.7 Properties of Valid Executions
27.7.1 Valid Chosen Reads
A
- For each
ReadSharedMemory orReadModifyWriteSharedMemory event R inSharedDataBlockEventSet (execution), do- Let chosenValue be the element of execution.[[ChosenValues]] whose [[Event]] field is R.
- Let readValue be
ValueOfReadEvent (execution, R). - Let chosenLen be the number of elements of chosenValue.
- Let readLen be the number of elements of readValue.
- If chosenLen is not equal to readLen, then
- Return
false .
- Return
- If chosenValue[i] is not equal to readValue[i] for any
integer value i in the range 0 through chosenLen, exclusive, then- Return
false .
- Return
- Return
true .
27.7.2 Coherent Reads
A
- For each
ReadSharedMemory orReadModifyWriteSharedMemory event R inSharedDataBlockEventSet (execution), do- Let Ws be execution.[[ReadsBytesFrom]](R).
- Let byteLocation be R.[[ByteIndex]].
- For each element W of Ws in
List order, do- If (R, W) is in execution.[[HappensBefore]], then
- Return
false .
- Return
- If there is a
WriteSharedMemory orReadModifyWriteSharedMemory event V that has byteLocation in its range such that the pairs (W, V) and (V, R) are in execution.[[HappensBefore]], then- Return
false .
- Return
- Increment byteLocation by 1.
- If (R, W) is in execution.[[HappensBefore]], then
- Return
true .
27.7.3 Tear Free Reads
A
- For each
ReadSharedMemory orReadModifyWriteSharedMemory event R inSharedDataBlockEventSet (execution), do- If R.[[NoTear]] is
true , thenAssert : The remainder of dividing R.[[ByteIndex]] by R.[[ElementSize]] is 0.- For each event W such that (R, W) is in execution.[[ReadsFrom]] and W.[[NoTear]] is
true , do- If R and W have equal ranges, and there is an event V such that V and W have equal ranges, V.[[NoTear]] is
true , W is not V, and (R, V) is in execution.[[ReadsFrom]], then- Return
false .
- Return
- If R and W have equal ranges, and there is an event V such that V and W have equal ranges, V.[[NoTear]] is
- If R.[[NoTear]] is
- Return
true .
An event's [[NoTear]] field is
Intuitively, this requirement says when a memory range is accessed in an aligned fashion via an
27.7.4 Sequentially Consistent Atomics
For a
- For each pair (E, D) in execution.[[HappensBefore]], (E, D) is in memory-order.
-
For each pair (E, D) in execution.[[SynchronizesWith]], (E, D) is in memory-order if there is no
WriteSharedMemory orReadModifyWriteSharedMemory event W inSharedDataBlockEventSet (execution) with equal range as D such that W is not E, and the pairs (E, W) and (W, D) are in memory-order.Note 1 This clause additionally constrains
"SeqCst"events on equal ranges. -
For each
WriteSharedMemory orReadModifyWriteSharedMemory event W inSharedDataBlockEventSet (execution), if W.[[Order]] is"SeqCst", then it is not the case that there is an infinite number ofReadSharedMemory orReadModifyWriteSharedMemory events inSharedDataBlockEventSet (execution) with equal range that is memory-order before W.Note 2 This clause together with the forward progress guarantee on agents ensure the liveness condition that
"SeqCst"writes become visible to"SeqCst"reads with equal range in finite time.
A
While memory-order includes all events in
27.7.5 Valid Executions
A
- The host provides a
host-synchronizes-with Relation for execution.[[HostSynchronizesWith]]. - execution.[[HappensBefore]] is a
strict partial order . - execution has valid chosen reads.
- execution has coherent reads.
- execution has tear free reads.
- execution has sequentially consistent atomics.
All programs have at least one valid execution.
27.8 Races
For an execution execution, two events E and D in
- If E is not D, then
- If the pairs (E, D) and (D, E) are not in execution.[[HappensBefore]], then
- If E and D are both
WriteSharedMemory orReadModifyWriteSharedMemory events and E and D do not have disjoint ranges, then- Return
true .
- Return
- If either (E, D) or (D, E) is in execution.[[ReadsFrom]], then
- Return
true .
- Return
- If E and D are both
- If the pairs (E, D) and (D, E) are not in execution.[[HappensBefore]], then
- Return
false .
27.9 Data Races
For an execution execution, two events E and D in
- If E and D are in a race in execution, then
- If E.[[Order]] is not
"SeqCst"or D.[[Order]] is not"SeqCst", then- Return
true .
- Return
- If E and D have overlapping ranges, then
- Return
true .
- Return
- If E.[[Order]] is not
- Return
false .
27.10 Data Race Freedom
An execution execution is data race free if there are no two events in
A program is data race free if all its executions are data race free.
The
27.11 Shared Memory Guidelines
The following are guidelines for ECMAScript programmers working with shared memory.
We recommend programs be kept data race free, i.e., make it so that it is impossible for there to be concurrent non-atomic operations on the same memory location. Data race free programs have interleaving semantics where each step in the evaluation semantics of each
More generally, even if a program is not data race free it may have predictable behaviour, so long as atomic operations are not involved in any data races and the operations that race all have the same access size. The simplest way to arrange for atomics not to be involved in races is to ensure that different memory cells are used by atomic and non-atomic operations and that atomic accesses of different sizes are not used to access the same cells at the same time. Effectively, the program should treat shared memory as strongly typed as much as possible. One still cannot depend on the ordering and timing of non-atomic accesses that race, but if memory is treated as strongly typed the racing accesses will not "tear" (bits of their values will not be mixed).
The following are guidelines for ECMAScript implementers writing compiler transformations for programs using shared memory.
It is desirable to allow most program transformations that are valid in a single-
Let an agent-order slice be the subset of the
Let possible read values of a read event be the set of all values of
Any transformation of an agent-order slice that is valid in the absence of shared memory is valid in the presence of shared memory, with the following exceptions.
-
Atomics are carved in stone: Program transformations must not cause the
"SeqCst"events in an agent-order slice to be reordered with its"Unordered"operations, nor its"SeqCst"operations to be reordered with each other, nor may a program transformation remove a"SeqCst"operation from theagent-order .(In practice, the prohibition on reorderings forces a compiler to assume that every
"SeqCst"operation is a synchronization and included in the finalmemory-order , which it would usually have to assume anyway in the absence of inter-agent program analysis. It also forces the compiler to assume that every call where the callee's effects on thememory-order are unknown may contain"SeqCst"operations.) -
Reads must be stable: Any given shared memory read must only observe a single value in an execution.
(For example, if what is semantically a single read in the program is executed multiple times then the program is subsequently allowed to observe only one of the values read. A transformation known as rematerialization can violate this rule.)
-
Writes must be stable: All observable writes to shared memory must follow from program semantics in an execution.
(For example, a transformation may not introduce certain observable writes, such as by using read-modify-write operations on a larger location to write a smaller datum, writing a value to memory that the program could not have written, or writing a just-read value back to the location it was read from, if that location could have been overwritten by another
agent after the read.) -
Possible read values must be nonempty: Program transformations cannot cause the possible read values of a shared memory read to become empty.
(Counterintuitively, this rule in effect restricts transformations on writes, because writes have force in
memory model insofar as to be read by read events. For example, writes may be moved and coalesced and sometimes reordered between two"SeqCst"operations, but the transformation may not remove every write that updates a location; some write must be preserved.)
Examples of transformations that remain valid are: merging multiple non-atomic reads from the same location, reordering non-atomic reads, introducing speculative non-atomic reads, merging multiple non-atomic writes to the same location, reordering non-atomic writes to different locations, and hoisting non-atomic reads out of loops even if that affects termination. Note in general that aliased TypedArrays make it hard to prove that locations are different.
The following are guidelines for ECMAScript implementers generating machine code for shared memory accesses.
For architectures with memory models no weaker than those of ARM or Power, non-atomic stores and loads may be compiled to bare stores and loads on the target architecture. Atomic stores and loads may be compiled down to instructions that guarantee sequential consistency. If no such instructions exist, memory barriers are to be employed, such as placing barriers on both sides of a bare store or load. Read-modify-write operations may be compiled to read-modify-write instructions on the target architectrue, such as LOCK-prefixed instructions on x86, load-exclusive/store-exclusive instructions on ARM, and load-link/store-conditional instructions on Power.
Specifically, the
- Every atomic operation in the program is assumed to be necessary.
- Atomic operations are never rearranged with each other or with non-atomic operations.
- Functions are always assumed to perform atomic operations.
- Atomic operations are never implemented as read-modify-write operations on larger data, but as non-lock-free atomics if the platform does not have atomic operations of the appropriate size. (We already assume that every platform has normal memory access operations of every interesting size.)
Naive code generation uses these patterns:
- Regular loads and stores compile to single load and store instructions.
- Lock-free atomic loads and stores compile to a full (sequentially consistent) fence, a regular load or store, and a full fence.
- Lock-free atomic read-modify-write accesses compile to a full fence, an atomic read-modify-write instruction sequence, and a full fence.
- Non-lock-free atomics compile to a spinlock acquire, a full fence, a series of non-atomic load and store instructions, a full fence, and a spinlock release.
That mapping is correct so long as an atomic operation on an address range does not race with a non-atomic write or with an atomic operation of different size. However, that is all we need: the
A number of local improvements to those basic patterns are also intended to be legal:
- There are obvious platform-dependent improvements that remove redundant fences. For example, on x86 the fences around lock-free atomic loads and stores can always be omitted except for the fence following a store, and no fence is needed for lock-free read-modify-write instructions, as these all use LOCK-prefixed instructions. On many platforms there are fences of several strengths, and weaker fences can be used in certain contexts without destroying sequential consistency.
- Most modern platforms support lock-free atomics for all the data sizes required by ECMAScript atomics. Should non-lock-free atomics be needed, the fences surrounding the body of the atomic operation can usually be folded into the lock and unlock steps. The simplest solution for non-lock-free atomics is to have a single lock word per SharedArrayBuffer.
- There are also more complicated platform-dependent local improvements, requiring some code analysis. For example, two back-to-back fences often have the same effect as a single fence, so if code is generated for two atomic operations in sequence, only a single fence need separate them. On x86, even a single fence separating atomic stores can be omitted, as the fence following a store is only needed to separate the store from a subsequent load.
A Grammar Summary
A.1 Lexical Grammar
The following tokens are also considered to be
A.2 Expressions
When processing an instance of the production
When processing an instance of the production
In certain circumstances when processing an instance of the production
A.3 Statements
A.4 Functions and Classes
When the production
When the production
A.5 Scripts and Modules
A.6 Number Conversions
All grammar symbols not explicitly defined by the
A.7 Universal Resource Identifier Character Classes
A.8 Regular Expressions
Each \u u u \u
B Additional ECMAScript Features for Web Browsers
The ECMAScript language syntax and semantics defined in this annex are required when the ECMAScript host is a web browser. The content of this annex is normative but optional if the ECMAScript host is not a web browser.
This annex describes various legacy features and other characteristics of web browser based ECMAScript implementations. All of the language features and behaviours specified in this annex have one or more undesirable characteristics and in the absence of legacy usage would be removed from this specification. However, the usage of these features by large numbers of existing web pages means that web browsers must continue to support them. The specifications in this annex define the requirements for interoperable implementations of these legacy features.
These features are not considered part of the core ECMAScript language. Programmers should not use or assume the existence of these features and behaviours when writing new ECMAScript code. ECMAScript implementations are discouraged from implementing these features unless the implementation is part of a web browser or is required to run the same legacy ECMAScript code that web browsers encounter.
B.1 Additional Syntax
B.1.1 Numeric Literals
The syntax and semantics of
Syntax
B.1.1.1 Static Semantics
-
The MV of
LegacyOctalIntegerLiteral :: 0 OctalDigit OctalDigit . -
The MV of
LegacyOctalIntegerLiteral :: LegacyOctalIntegerLiteral OctalDigit LegacyOctalIntegerLiteral times 8) plus the MV ofOctalDigit . -
The MV of
DecimalIntegerLiteral :: NonOctalDecimalIntegerLiteral NonOctalDecimalIntegerLiteral . -
The MV of
NonOctalDecimalIntegerLiteral :: 0 NonOctalDigit NonOctalDigit . -
The MV of
NonOctalDecimalIntegerLiteral :: LegacyOctalLikeDecimalIntegerLiteral NonOctalDigit LegacyOctalLikeDecimalIntegerLiteral times 10) plus the MV ofNonOctalDigit . -
The MV of
NonOctalDecimalIntegerLiteral :: NonOctalDecimalIntegerLiteral DecimalDigit NonOctalDecimalIntegerLiteral times 10) plus the MV ofDecimalDigit . -
The MV of
LegacyOctalLikeDecimalIntegerLiteral :: 0 OctalDigit OctalDigit . -
The MV of
LegacyOctalLikeDecimalIntegerLiteral :: LegacyOctalLikeDecimalIntegerLiteral OctalDigit LegacyOctalLikeDecimalIntegerLiteral times 10) plus the MV ofOctalDigit . -
The MV of
NonOctalDigit :: 8 -
The MV of
NonOctalDigit :: 9
B.1.2 String Literals
The syntax and semantics of
Syntax
This definition of
B.1.2.1 Static Semantics
-
The SV of
EscapeSequence :: LegacyOctalEscapeSequence LegacyOctalEscapeSequence . -
The SV of
LegacyOctalEscapeSequence :: OctalDigit OctalDigit . -
The SV of
LegacyOctalEscapeSequence :: ZeroToThree OctalDigit ZeroToThree ) plus the MV of theOctalDigit . -
The SV of
LegacyOctalEscapeSequence :: FourToSeven OctalDigit FourToSeven ) plus the MV of theOctalDigit . -
The SV of
LegacyOctalEscapeSequence :: ZeroToThree OctalDigit OctalDigit ZeroToThree ) plus (8 times the MV of the firstOctalDigit ) plus the MV of the secondOctalDigit . -
The MV of
ZeroToThree :: 0 -
The MV of
ZeroToThree :: 1 -
The MV of
ZeroToThree :: 2 -
The MV of
ZeroToThree :: 3 -
The MV of
FourToSeven :: 4 -
The MV of
FourToSeven :: 5 -
The MV of
FourToSeven :: 6 -
The MV of
FourToSeven :: 7
B.1.3 HTML-like Comments
The syntax and semantics of
Syntax
Similar to a
B.1.4 Regular Expressions Patterns
The syntax of
This alternative pattern grammar and semantics only changes the syntax and semantics of BMP patterns. The following grammar extensions include productions parameterized with the [U] parameter. However, none of these extensions change the syntax of Unicode patterns recognized when parsing with the [U] parameter present on the
Syntax
When the same left hand sides occurs with both [+U] and [~U] guards it is to control the disambiguation priority.
B.1.4.1 Static Semantics: Early Errors
The semantics of
- It is a Syntax Error if any source text matches this rule.
-
It is a Syntax Error if IsCharacterClass of the first
ClassAtom istrue or IsCharacterClass of the secondClassAtom istrue and this production has a [U] parameter.
-
It is a Syntax Error if IsCharacterClass of
ClassAtomNoDash istrue or IsCharacterClass ofClassAtom istrue and this production has a [U] parameter.
B.1.4.2 Static Semantics: IsCharacterClass
The semantics of
- Return
false .
B.1.4.3 Static Semantics: CharacterValue
The semantics of
- Return the code point value of U+005C (REVERSE SOLIDUS).
- Let ch be the code point matched by
ClassControlLetter . - Let i be ch's code point value.
- Return the remainder of dividing i by 32.
- Evaluate the SV of the
LegacyOctalEscapeSequence (seeB.1.2 ) to obtain a code unit cu. - Return the numeric value of cu.
B.1.4.4 Pattern Semantics
The semantics of
Within
Term (
The production
The production
The production
Assertion (
The production
- Evaluate
QuantifiableAssertion to obtain a Matcher m. - Return m.
Assertion (
Atom (
The production
- Let A be the CharSet containing the single character
\U+005C (REVERSE SOLIDUS). - Call
CharacterSetMatcher (A,false ) and return its Matcher result.
The production
- Let ch be the character represented by
ExtendedPatternCharacter . - Let A be a one-element CharSet containing the character ch.
- Call
CharacterSetMatcher (A,false ) and return its Matcher result.
CharacterEscape (
The production
- Let cv be the CharacterValue of this
CharacterEscape . - Return the character whose character value is cv.
NonemptyClassRanges (
The production
- Evaluate the first
ClassAtom to obtain a CharSet A. - Evaluate the second
ClassAtom to obtain a CharSet B. - Evaluate
ClassRanges to obtain a CharSet C. - Call
CharacterRangeOrUnion (A, B) and let D be the resulting CharSet. - Return the union of CharSets D and C.
NonemptyClassRangesNoDash (
The production
- Evaluate
ClassAtomNoDash to obtain a CharSet A. - Evaluate
ClassAtom to obtain a CharSet B. - Evaluate
ClassRanges to obtain a CharSet C. - Call
CharacterRangeOrUnion (A, B) and let D be the resulting CharSet. - Return the union of CharSets D and C.
ClassEscape (
The production
- Let cv be the CharacterValue of this
ClassEscape . - Let c be the character whose character value is cv.
- Return the CharSet containing the single character c.
ClassAtomNoDash (
The production
- Return the CharSet containing the single character
\U+005C (REVERSE SOLIDUS).
\c within a character class where it is not followed by an acceptable control character.B.1.4.4.1 Runtime Semantics: CharacterRangeOrUnion ( A, B )
The abstract operation CharacterRangeOrUnion takes two CharSet parameters A and B and performs the following steps:
- If Unicode is
false , then- If A does not contain exactly one character or B does not contain exactly one character, then
- Let C be the CharSet containing the single character
-U+002D (HYPHEN-MINUS). - Return the union of CharSets A, B and C.
- Let C be the CharSet containing the single character
- If A does not contain exactly one character or B does not contain exactly one character, then
- Return
CharacterRange (A, B).
B.2 Additional Built-in Properties
When the ECMAScript host is a web browser the following additional properties of the standard built-in objects are defined.
B.2.1 Additional Properties of the Global Object
The entries in
| Intrinsic Name | Global Name | ECMAScript Language Association |
|---|---|---|
|
|
escape
|
The escape function ( |
|
|
unescape
|
The unescape function ( |
B.2.1.1 escape ( string )
The escape function is a property of the
For those code units being replaced whose value is 0x00FF or less, a two-digit escape sequence of the form %xx is used. For those characters being replaced whose code unit value is greater than 0x00FF, a four-digit escape sequence of the form %uxxxx is used.
The escape function is the %escape% intrinsic object. When the escape function is called with one argument string, the following steps are taken:
- Set string to ?
ToString (string). - Let length be the number of code units in string.
- Let R be the empty string.
- Let k be 0.
- Repeat, while k < length,
- Let char be the code unit (represented as a 16-bit unsigned
integer ) at index k within string. - If char is one of the code units in
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789@*_+-./", then- Let S be the String value containing the single code unit char.
- Else if char ≥ 256, then
- Let n be the numeric value of char.
- Let S be the
string-concatenation of:"%u"- the String representation of n, formatted as a four-digit uppercase hexadecimal number, padded to the left with zeroes if necessary
- Else char < 256,
- Let n be the numeric value of char.
- Let S be the
string-concatenation of:"%"- the String representation of n, formatted as a two-digit uppercase hexadecimal number, padded to the left with a zero if necessary
- Set R to the
string-concatenation of the previous value of R and S. - Increase k by 1.
- Let char be the code unit (represented as a 16-bit unsigned
- Return R.
The encoding is partly based on the encoding described in RFC 1738, but the entire encoding specified in this standard is described above without regard to the contents of RFC 1738. This encoding does not reflect changes to RFC 1738 made by RFC 3986.
B.2.1.2 unescape ( string )
The unescape function is a property of the escape function is replaced with the code unit that it represents.
The unescape function is the %unescape% intrinsic object. When the unescape function is called with one argument string, the following steps are taken:
- Set string to ?
ToString (string). - Let length be the number of code units in string.
- Let R be the empty String.
- Let k be 0.
- Repeat, while k ≠ length
- Let c be the code unit at index k within string.
- If c is the code unit 0x0025 (PERCENT SIGN), then
- If k ≤ length-6 and the code unit at index k+1 within string is the code unit 0x0075 (LATIN SMALL LETTER U) and the four code units at indices k+2, k+3, k+4, and k+5 within string are all hexadecimal digits, then
- Let c be the code unit whose value is the
integer represented by the four hexadecimal digits at indices k+2, k+3, k+4, and k+5 within string. - Increase k by 5.
- Let c be the code unit whose value is the
- Else if k ≤ length-3 and the two code units at indices k+1 and k+2 within string are both hexadecimal digits, then
- Let c be the code unit whose value is the
integer represented by two zeroes plus the two hexadecimal digits at indices k+1 and k+2 within string. - Increase k by 2.
- Let c be the code unit whose value is the
- If k ≤ length-6 and the code unit at index k+1 within string is the code unit 0x0075 (LATIN SMALL LETTER U) and the four code units at indices k+2, k+3, k+4, and k+5 within string are all hexadecimal digits, then
- Set R to the
string-concatenation of the previous value of R and c. - Increase k by 1.
- Return R.
B.2.2 Additional Properties of the Object.prototype Object
B.2.2.1 Object.prototype.__proto__
Object.prototype.__proto__ is an
B.2.2.1.1 get Object.prototype.__proto__
The value of the [[Get]] attribute is a built-in function that requires no arguments. It performs the following steps:
- Let O be ?
ToObject (this value). - Return ? O.[[GetPrototypeOf]]().
B.2.2.1.2 set Object.prototype.__proto__
The value of the [[Set]] attribute is a built-in function that takes an argument proto. It performs the following steps:
- Let O be ?
RequireObjectCoercible (this value). - If
Type (proto) is neither Object nor Null, returnundefined . - If
Type (O) is not Object, returnundefined . - Let status be ? O.[[SetPrototypeOf]](proto).
- If status is
false , throw aTypeError exception. - Return
undefined .
B.2.2.2 Object.prototype.__defineGetter__ ( P, getter )
When the __defineGetter__ method is called with arguments P and getter, the following steps are taken:
- Let O be ?
ToObject (this value). - If
IsCallable (getter) isfalse , throw aTypeError exception. - Let desc be PropertyDescriptor { [[Get]]: getter, [[Enumerable]]:
true , [[Configurable]]:true }. - Let key be ?
ToPropertyKey (P). - Perform ?
DefinePropertyOrThrow (O, key, desc). - Return
undefined .
B.2.2.3 Object.prototype.__defineSetter__ ( P, setter )
When the __defineSetter__ method is called with arguments P and setter, the following steps are taken:
- Let O be ?
ToObject (this value). - If
IsCallable (setter) isfalse , throw aTypeError exception. - Let desc be PropertyDescriptor { [[Set]]: setter, [[Enumerable]]:
true , [[Configurable]]:true }. - Let key be ?
ToPropertyKey (P). - Perform ?
DefinePropertyOrThrow (O, key, desc). - Return
undefined .
B.2.2.4 Object.prototype.__lookupGetter__ ( P )
When the __lookupGetter__ method is called with argument P, the following steps are taken:
- Let O be ?
ToObject (this value). - Let key be ?
ToPropertyKey (P). - Repeat,
- Let desc be ? O.[[GetOwnProperty]](key).
- If desc is not
undefined , then- If
IsAccessorDescriptor (desc) istrue , return desc.[[Get]]. - Return
undefined .
- If
- Set O to ? O.[[GetPrototypeOf]]().
- If O is
null , returnundefined .
B.2.2.5 Object.prototype.__lookupSetter__ ( P )
When the __lookupSetter__ method is called with argument P, the following steps are taken:
- Let O be ?
ToObject (this value). - Let key be ?
ToPropertyKey (P). - Repeat,
- Let desc be ? O.[[GetOwnProperty]](key).
- If desc is not
undefined , then- If
IsAccessorDescriptor (desc) istrue , return desc.[[Set]]. - Return
undefined .
- If
- Set O to ? O.[[GetPrototypeOf]]().
- If O is
null , returnundefined .
B.2.3 Additional Properties of the String.prototype Object
B.2.3.1 String.prototype.substr ( start, length )
The substr method takes two arguments, start and length, and returns a substring of the result of converting the
- Let O be ?
RequireObjectCoercible (this value). - Let S be ?
ToString (O). - Let intStart be ?
ToInteger (start). - If length is
undefined , let end be+∞ ; otherwise let end be ?ToInteger (length). - Let size be the number of code units in S.
- If intStart < 0, let intStart be
max (size + intStart, 0). - Let resultLength be
min (max (end, 0), size - intStart). - If resultLength ≤ 0, return the empty String
"". - Return the String value containing resultLength consecutive code units from S beginning with the code unit at index intStart.
The substr function is intentionally generic; it does not require that its
B.2.3.2 String.prototype.anchor ( name )
When the anchor method is called with argument name, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"a","name", name).
B.2.3.2.1 Runtime Semantics: CreateHTML ( string, tag, attribute, value )
The abstract operation CreateHTML is called with arguments string, tag, attribute, and value. The arguments tag and attribute must be String values. The following steps are taken:
- Let str be ?
RequireObjectCoercible (string). - Let S be ?
ToString (str). - Let p1 be the
string-concatenation of"<"and tag. - If attribute is not the empty String, then
- Let V be ?
ToString (value). - Let escapedV be the String value that is the same as V except that each occurrence of the code unit 0x0022 (QUOTATION MARK) in V has been replaced with the six code unit sequence
""". - Set p1 to the
string-concatenation of:- p1
- the code unit 0x0020 (SPACE)
- attribute
- the code unit 0x003D (EQUALS SIGN)
- the code unit 0x0022 (QUOTATION MARK)
- escapedV
- the code unit 0x0022 (QUOTATION MARK)
- Let V be ?
- Let p2 be the
string-concatenation of p1 and">". - Let p3 be the
string-concatenation of p2 and S. - Let p4 be the
string-concatenation of p3,"</", tag, and">". - Return p4.
B.2.3.3 String.prototype.big ( )
When the big method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"big","","").
B.2.3.4 String.prototype.blink ( )
When the blink method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"blink","","").
B.2.3.5 String.prototype.bold ( )
When the bold method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"b","","").
B.2.3.6 String.prototype.fixed ( )
When the fixed method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"tt","","").
B.2.3.7 String.prototype.fontcolor ( color )
When the fontcolor method is called with argument color, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"font","color", color).
B.2.3.8 String.prototype.fontsize ( size )
When the fontsize method is called with argument size, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"font","size", size).
B.2.3.9 String.prototype.italics ( )
When the italics method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"i","","").
B.2.3.10 String.prototype.link ( url )
When the link method is called with argument url, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"a","href", url).
B.2.3.11 String.prototype.small ( )
When the small method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"small","","").
B.2.3.12 String.prototype.strike ( )
When the strike method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"strike","","").
B.2.3.13 String.prototype.sub ( )
When the sub method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"sub","","").
B.2.3.14 String.prototype.sup ( )
When the sup method is called with no arguments, the following steps are taken:
- Let S be the
this value. - Return ?
CreateHTML (S,"sup","","").
B.2.4 Additional Properties of the Date.prototype Object
B.2.4.1 Date.prototype.getYear ( )
The getFullYear method is preferred for nearly all purposes, because it avoids the “year 2000 problem.”
When the getYear method is called with no arguments, the following steps are taken:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , returnNaN . - Return
YearFromTime (LocalTime (t)) - 1900.
B.2.4.2 Date.prototype.setYear ( year )
The setFullYear method is preferred for nearly all purposes, because it avoids the “year 2000 problem.”
When the setYear method is called with one argument year, the following steps are taken:
- Let t be ?
thisTimeValue (this value). - If t is
NaN , let t be+0 ; otherwise, let t beLocalTime (t). - Let y be ?
ToNumber (year). - If y is
NaN , set the [[DateValue]] internal slot ofthis Date object toNaN and returnNaN . - If 0 ≤
ToInteger (y) ≤ 99, let yyyy beToInteger (y) + 1900. - Else, let yyyy be y.
- Let d be
MakeDay (yyyy,MonthFromTime (t),DateFromTime (t)). - Let date be
UTC (MakeDate (d,TimeWithinDay (t))). - Set the [[DateValue]] internal slot of
this Date object toTimeClip (date). - Return the value of the [[DateValue]] internal slot of
this Date object .
B.2.4.3 Date.prototype.toGMTString ( )
The property toUTCString is preferred. The toGMTString property is provided principally for compatibility with old code. It is recommended that the toUTCString property be used in new ECMAScript code.
The Date.prototype.toGMTString is the same Date.prototype.toUTCString.
B.2.5 Additional Properties of the RegExp.prototype Object
B.2.5.1 RegExp.prototype.compile ( pattern, flags )
When the compile method is called with arguments pattern and flags, the following steps are taken:
- Let O be the
this value. - If
Type (O) is not Object orType (O) is Object and O does not have a [[RegExpMatcher]] internal slot, then- Throw a
TypeError exception.
- Throw a
- If
Type (pattern) is Object and pattern has a [[RegExpMatcher]] internal slot, then- If flags is not
undefined , throw aTypeError exception. - Let P be pattern.[[OriginalSource]].
- Let F be pattern.[[OriginalFlags]].
- If flags is not
- Else,
- Let P be pattern.
- Let F be flags.
- Return ?
RegExpInitialize (O, P, F).
The compile method completely reinitializes the
B.3 Other Additional Features
B.3.1 __proto__ Property Names in Object Initializers
The following Early Error rule is added to those in
-
It is a Syntax Error if PropertyNameList of
PropertyDefinitionList contains any duplicate entries for"__proto__"and at least two of those entries were obtained from productions of the formPropertyDefinition : PropertyName : AssignmentExpression
The
In
is replaced with the following definition:
- Let propKey be the result of evaluating
PropertyName . ReturnIfAbrupt (propKey).- Let exprValueRef be the result of evaluating
AssignmentExpression . - Let propValue be ?
GetValue (exprValueRef). - If propKey is the String value
"__proto__"and if IsComputedPropertyKey(PropertyName ) isfalse , then- If
Type (propValue) is either Object or Null, then- Return object.[[SetPrototypeOf]](propValue).
- Return
NormalCompletion (empty ).
- If
- If
IsAnonymousFunctionDefinition (AssignmentExpression ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (propValue,"name"). - If hasNameProperty is
false , performSetFunctionName (propValue, propKey).
- Let hasNameProperty be ?
Assert : enumerable istrue .- Return
CreateDataPropertyOrThrow (object, propKey, propValue).
B.3.2 Labelled Function Declarations
Prior to ECMAScript 2015, the specification of
- It is a Syntax Error if any strict mode source code matches this rule.
The
B.3.3 Block-Level Function Declarations Web Legacy Compatibility Semantics
Prior to ECMAScript 2015, the ECMAScript specification did not define the occurrence of a
-
A function is declared and only referenced within a single block
-
One or more
FunctionDeclaration s whoseBindingIdentifier is the name f occur within the function code of an enclosing function g and that declaration is nested within aBlock . -
No other declaration of f that is not a
vardeclaration occurs within the function code of g -
All occurrences of f as an
IdentifierReference are within theStatementList of theBlock containing the declaration of f.
-
One or more
-
A function is declared and possibly used within a single
Block but also referenced by an inner function definition that is not contained within that sameBlock .-
One or more
FunctionDeclaration s whoseBindingIdentifier is the name f occur within the function code of an enclosing function g and that declaration is nested within aBlock . -
No other declaration of f that is not a
vardeclaration occurs within the function code of g -
There may be occurrences of f as an
IdentifierReference within theStatementList of theBlock containing the declaration of f. -
There is at least one occurrence of f as an
IdentifierReference within another function h that is nested within g and no other declaration of f shadows the references to f from within h. - All invocations of h occur after the declaration of f has been evaluated.
-
One or more
-
A function is declared and possibly used within a single block but also referenced within subsequent blocks.
-
One or more
FunctionDeclaration whoseBindingIdentifier is the name f occur within the function code of an enclosing function g and that declaration is nested within aBlock . -
No other declaration of f that is not a
vardeclaration occurs within the function code of g -
There may be occurrences of f as an
IdentifierReference within theStatementList of theBlock containing the declaration of f. -
There is at least one occurrence of f as an
IdentifierReference within the function code of g that lexically follows theBlock containing the declaration of f.
-
One or more
The first use case is interoperable with the semantics of
ECMAScript 2015 interoperability for the second and third use cases requires the following extensions to the clause
If an ECMAScript implementation has a mechanism for reporting diagnostic warning messages, a warning should be produced when code contains a
B.3.3.1 Changes to FunctionDeclarationInstantiation
During
- If strict is
false , then- For each
FunctionDeclaration f that is directly contained in theStatementList of aBlock ,CaseClause , orDefaultClause , do- Let F be StringValue of the
BindingIdentifier ofFunctionDeclaration f. - If replacing the
FunctionDeclaration f with aVariableStatement that has F as aBindingIdentifier would not produce any Early Errors for func and F is not an element of parameterNames, then- NOTE: A var binding for F is only instantiated here if it is neither a VarDeclaredName, the name of a formal parameter, or another
FunctionDeclaration . - If initializedBindings does not contain F and F is not
"arguments", then- Perform ! varEnvRec.CreateMutableBinding(F,
false ). - Perform varEnvRec.InitializeBinding(F,
undefined ). - Append F to instantiatedVarNames.
- Perform ! varEnvRec.CreateMutableBinding(F,
- When the
FunctionDeclaration f is evaluated, perform the following steps in place of theFunctionDeclaration Evaluation algorithm provided in14.1.21 :- Let fenv be the
running execution context 's VariableEnvironment. - Let fenvRec be fenv's
EnvironmentRecord . - Let benv be the
running execution context 's LexicalEnvironment. - Let benvRec be benv's
EnvironmentRecord . - Let fobj be ! benvRec.GetBindingValue(F,
false ). - Perform ! fenvRec.SetMutableBinding(F, fobj,
false ). - Return
NormalCompletion (empty ).
- Let fenv be the
- NOTE: A var binding for F is only instantiated here if it is neither a VarDeclaredName, the name of a formal parameter, or another
- Let F be StringValue of the
- For each
B.3.3.2 Changes to GlobalDeclarationInstantiation
During
- Let strict be IsStrict of script.
- If strict is
false , then- Let declaredFunctionOrVarNames be a new empty
List . - Append to declaredFunctionOrVarNames the elements of declaredFunctionNames.
- Append to declaredFunctionOrVarNames the elements of declaredVarNames.
- For each
FunctionDeclaration f that is directly contained in theStatementList of aBlock ,CaseClause , orDefaultClause Contained within script, do- Let F be StringValue of the
BindingIdentifier ofFunctionDeclaration f. - If replacing the
FunctionDeclaration f with aVariableStatement that has F as aBindingIdentifier would not produce any Early Errors for script, then- If envRec.HasLexicalDeclaration(F) is
false , then- Let fnDefinable be ? envRec.CanDeclareGlobalFunction(F).
- If fnDefinable is
true , then- NOTE: A var binding for F is only instantiated here if it is neither a VarDeclaredName nor the name of another
FunctionDeclaration . - If declaredFunctionOrVarNames does not contain F, then
- Perform ? envRec.CreateGlobalFunctionBinding(F,
undefined ,false ). - Append F to declaredFunctionOrVarNames.
- Perform ? envRec.CreateGlobalFunctionBinding(F,
- When the
FunctionDeclaration f is evaluated, perform the following steps in place of theFunctionDeclaration Evaluation algorithm provided in14.1.21 :- Let genv be the
running execution context 's VariableEnvironment. - Let genvRec be genv's
EnvironmentRecord . - Let benv be the
running execution context 's LexicalEnvironment. - Let benvRec be benv's
EnvironmentRecord . - Let fobj be ! benvRec.GetBindingValue(F,
false ). - Perform ? genvRec.SetMutableBinding(F, fobj,
false ). - Return
NormalCompletion (empty ).
- Let genv be the
- NOTE: A var binding for F is only instantiated here if it is neither a VarDeclaredName nor the name of another
- If envRec.HasLexicalDeclaration(F) is
- Let F be StringValue of the
- Let declaredFunctionOrVarNames be a new empty
B.3.3.3 Changes to EvalDeclarationInstantiation
During
- If strict is
false , then- Let declaredFunctionOrVarNames be a new empty
List . - Append to declaredFunctionOrVarNames the elements of declaredFunctionNames.
- Append to declaredFunctionOrVarNames the elements of declaredVarNames.
- For each
FunctionDeclaration f that is directly contained in theStatementList of aBlock ,CaseClause , orDefaultClause Contained within body, do- Let F be StringValue of the
BindingIdentifier ofFunctionDeclaration f. - If replacing the
FunctionDeclaration f with aVariableStatement that has F as aBindingIdentifier would not produce any Early Errors for body, then- Let bindingExists be
false . - Let thisLex be lexEnv.
Assert : The following loop will terminate.- Repeat, while thisLex is not the same as varEnv,
- Let thisEnvRec be thisLex's
EnvironmentRecord . - If thisEnvRec is not an object
Environment Record , then- If thisEnvRec.HasBinding(F) is
true , then- Let bindingExists be
true .
- Let bindingExists be
- If thisEnvRec.HasBinding(F) is
- Let thisLex be thisLex's outer environment reference.
- Let thisEnvRec be thisLex's
- If bindingExists is
false and varEnvRec is a globalEnvironment Record , then- If varEnvRec.HasLexicalDeclaration(F) is
false , then- Let fnDefinable be ? varEnvRec.CanDeclareGlobalFunction(F).
- Else,
- Let fnDefinable be
false .
- Let fnDefinable be
- If varEnvRec.HasLexicalDeclaration(F) is
- Else,
- Let fnDefinable be
true .
- Let fnDefinable be
- If bindingExists is
false and fnDefinable istrue , then- If declaredFunctionOrVarNames does not contain F, then
- If varEnvRec is a global
Environment Record , then- Perform ? varEnvRec.CreateGlobalFunctionBinding(F,
undefined ,true ).
- Perform ? varEnvRec.CreateGlobalFunctionBinding(F,
- Else,
- Let bindingExists be varEnvRec.HasBinding(F).
- If bindingExists is
false , then- Perform ! varEnvRec.CreateMutableBinding(F,
true ). - Perform ! varEnvRec.InitializeBinding(F,
undefined ).
- Perform ! varEnvRec.CreateMutableBinding(F,
- Append F to declaredFunctionOrVarNames.
- If varEnvRec is a global
- When the
FunctionDeclaration f is evaluated, perform the following steps in place of theFunctionDeclaration Evaluation algorithm provided in14.1.21 :- Let genv be the
running execution context 's VariableEnvironment. - Let genvRec be genv's
EnvironmentRecord . - Let benv be the
running execution context 's LexicalEnvironment. - Let benvRec be benv's
EnvironmentRecord . - Let fobj be ! benvRec.GetBindingValue(F,
false ). - Perform ? genvRec.SetMutableBinding(F, fobj,
false ). - Return
NormalCompletion (empty ).
- Let genv be the
- If declaredFunctionOrVarNames does not contain F, then
- Let bindingExists be
- Let F be StringValue of the
- Let declaredFunctionOrVarNames be a new empty
B.3.3.4 Changes to Block Static Semantics: Early Errors
For web browser compatibility, that rule is modified with the addition of the highlighted text:
-
It is a Syntax Error if the LexicallyDeclaredNames of
StatementList contains any duplicate entries, unless the source code matching this production is notstrict mode code and the duplicate entries are only bound by FunctionDeclarations.
B.3.3.5 Changes to switch Statement Static Semantics: Early Errors
For web browser compatibility, that rule is modified with the addition of the highlighted text:
-
It is a Syntax Error if the LexicallyDeclaredNames of
CaseBlock contains any duplicate entries, unless the source code matching this production is notstrict mode code and the duplicate entries are only bound by FunctionDeclarations.
B.3.3.6 Changes to BlockDeclarationInstantiation
During
- If envRec.HasBinding(dn) is
false , then- Perform ! envRec.CreateMutableBinding(dn,
false ).
- Perform ! envRec.CreateMutableBinding(dn,
During
- If envRec.HasBinding(fn) is
false , then- Perform envRec.InitializeBinding(fn, fo).
- Else,
Assert : d is aFunctionDeclaration .- Perform envRec.SetMutableBinding(fn, fo,
false ).
B.3.4 FunctionDeclarations in IfStatement Statement Clauses
The following augments the
This production only applies when parsing
B.3.5 VariableStatements in Catch Blocks
The content of subclause
-
It is a Syntax Error if BoundNames of
CatchParameter contains any duplicate elements. -
It is a Syntax Error if any element of the BoundNames of
CatchParameter also occurs in the LexicallyDeclaredNames ofBlock . -
It is a Syntax Error if any element of the BoundNames of
CatchParameter also occurs in the VarDeclaredNames ofBlock unlessCatchParameter isCatchParameter : BindingIdentifier VariableStatement , theVariableDeclarationList of a for statement, theForBinding of a for-in statement, or theBindingIdentifier of a for-in statement.
The var declarations that bind a name that is also bound by the var declarations will assign to the corresponding catch parameter rather than the var binding. The relaxation of the normal static semantic rule does not apply to names only bound by for-of statements.
This modified behaviour also applies to var and function declarations introduced by
Step 5.d.ii.2.a.i is replaced by:
- If thisEnvRec is not the
Environment Record for aCatch clause, throw aSyntaxError exception. - If name is bound by any syntactic form other than a
FunctionDeclaration , aVariableStatement , theVariableDeclarationList of a for statement, theForBinding of a for-in statement, or theBindingIdentifier of a for-in statement, throw aSyntaxError exception.
Step 9.d.ii.4.b.i.i is replaced by:
- If thisEnvRec is not the
Environment Record for aCatch clause, let bindingExists betrue .
B.3.6 Initializers in ForIn Statement Heads
The following augments the
This production only applies when parsing
The
- Return ContainsDuplicateLabels of
Statement with argument labelSet.
The
- Return ContainsUndefinedBreakTarget of
Statement with argument labelSet.
The
- Return ContainsUndefinedContinueTarget of
Statement with arguments iterationSet and « ».
The
- Return
false .
The
- Let names be the BoundNames of
BindingIdentifier . - Append to names the elements of the VarDeclaredNames of
Statement . - Return names.
The
- Let declarations be a
List containingBindingIdentifier . - Append to declarations the elements of the VarScopedDeclarations of
Statement . - Return declarations.
The
- Let bindingId be StringValue of
BindingIdentifier . - Let lhs be ?
ResolveBinding (bindingId). - Let rhs be the result of evaluating
Initializer . - Let value be ?
GetValue (rhs). - If
IsAnonymousFunctionDefinition (Initializer ) istrue , then- Let hasNameProperty be ?
HasOwnProperty (value,"name"). - If hasNameProperty is
false , performSetFunctionName (value, bindingId).
- Let hasNameProperty be ?
- Perform ?
PutValue (lhs, value). - Let keyResult be ?
ForIn/OfHeadEvaluation (« »,Expression ,enumerate ). - Return ?
ForIn/OfBodyEvaluation (BindingIdentifier ,Statement , keyResult,enumerate ,varBinding , labelSet).
B.3.7 The [[IsHTMLDDA]] Internal Slot
An [[IsHTMLDDA]] internal slot may exist on implementation-defined objects. Objects with an [[IsHTMLDDA]] internal slot behave like typeof operator
Objects with an [[IsHTMLDDA]] internal slot are never created by this specification. However, the document.all object in web browsers is a host-created document.all.
B.3.7.1 Changes to ToBoolean
The result column in
- If argument has an
[[IsHTMLDDA]] internal slot , returnfalse . - Return
true .
B.3.7.2 Changes to Abstract Equality Comparison
The following steps are inserted after step 3 of the
- If
Type (x) is Object and x has an[[IsHTMLDDA]] internal slot and y is eithernull orundefined , returntrue . - If x is either
null orundefined andType (y) is Object and y has an[[IsHTMLDDA]] internal slot , returntrue .
B.3.7.3 Changes to the typeof Operator
The following table entry is inserted into
typeof| Type of val | Result |
|---|---|
|
Object (has an |
"undefined"
|
C The Strict Mode of ECMAScript
The strict mode restriction and exceptions
-
implements,interface,let,package,private,protected,public,static, andyieldare reserved words withinstrict mode code . (11.6.2 ). -
A conforming implementation, when processing
strict mode code , must not extend, as described inB.1.1 , the syntax ofNumericLiteral to includeLegacyOctalIntegerLiteral , nor extend the syntax ofDecimalIntegerLiteral to includeNonOctalDecimalIntegerLiteral . -
A conforming implementation, when processing
strict mode code , may not extend the syntax ofEscapeSequence to includeLegacyOctalEscapeSequence as described inB.1.2 . -
Assignment to an undeclared identifier or otherwise unresolvable reference does not create a property in the
global object . When a simple assignment occurs withinstrict mode code , itsLeftHandSideExpression must not evaluate to an unresolvableReference . If it does aReferenceError exception is thrown (6.2.4.9 ). TheLeftHandSideExpression also may not be a reference to adata property with the attribute value { [[Writable]]:false }, to anaccessor property with the attribute value { [[Set]]:undefined }, nor to a non-existent property of an object whose [[Extensible]] internal slot has the valuefalse . In these cases aTypeErrorexception is thrown (12.15 ). -
An
IdentifierReference with the StringValue"eval"or"arguments"may not appear as theLeftHandSideExpression of an Assignment operator (12.15 ) or of anUpdateExpression (12.4 ) or as theUnaryExpression operated upon by a Prefix Increment (12.4.6 ) or a Prefix Decrement (12.4.7 ) operator. -
Arguments objects for strict functions define a non-configurable
accessor property "callee"which throws aTypeError exception on access (9.4.4.6 ). -
Arguments objects for strict functions do not dynamically share their
array-indexed property values with the corresponding formal parameter bindings of their functions. (9.4.4 ). -
For strict functions, if an arguments object is created the binding of the local identifier
argumentsto the arguments object is immutable and hence may not be the target of an assignment expression. (9.2.15 ). -
It is a
SyntaxError if the StringValue of aBindingIdentifier is"eval"or"arguments"withinstrict mode code (12.1.1 ). -
Strict mode eval code cannot instantiate variables or functions in the variable environment of the caller to eval. Instead, a new variable environment is created and that environment is used for declaration binding instantiation for the eval code (
18.2.1 ). -
If
this is evaluated withinstrict mode code , then thethis value is not coerced to an object. Athis value ofundefined ornull is not converted to theglobal object and primitive values are not converted to wrapper objects. Thethis value passed via a function call (including calls made usingFunction.prototype.applyandFunction.prototype.call) do not coerce the passed this value to an object (9.2.1.2 ,19.2.3.1 ,19.2.3.3 ). -
When a
deleteoperator occurs withinstrict mode code , aSyntaxError is thrown if itsUnaryExpression is a direct reference to a variable, function argument, or function name (12.5.3.1 ). -
When a
deleteoperator occurs withinstrict mode code , aTypeError is thrown if the property to be deleted has the attribute { [[Configurable]]:false } (12.5.3.2 ). -
Strict mode code may not include aWithStatement . The occurrence of aWithStatement in such a context is aSyntaxError (13.11.1 ). -
It is a
SyntaxError if aCatchParameter occurs withinstrict mode code and BoundNames ofCatchParameter contains eitherevalorarguments(13.15.1 ). -
It is a
SyntaxError if the sameBindingIdentifier appears more than once in theFormalParameters of astrict function . An attempt to create such a function using aFunction,Generator, orAsyncFunctionconstructor is aSyntaxError (14.1.2 ,19.2.1.1.1 ). -
An implementation may not extend, beyond that defined in this specification, the meanings within strict functions of properties named
callerorargumentsof function instances.
D Corrections and Clarifications in ECMAScript 2015 with Possible Compatibility Impact
"z".
"Invalid Date".
source property of a RegExp instance must be expressed using an escape sequence. Edition 5.1 only required the escaping of "/".
String.prototype.match and String.prototype.replace was incorrect for cases where the pattern argument was a RegExp value whose global is flag set. The previous specifications stated that for each attempt to match the pattern, if lastIndex did not change it should be incremented by 1. The correct behaviour is that lastIndex should be incremented by one only if the pattern matched the empty string.
Array.prototype.sort. ECMAScript 2015 specifies that such as value is treated as if
E Additions and Changes That Introduce Incompatibilities with Prior Editions
let followed by the token [ is the start of a
( token of a for statement is immediately followed by the token sequence let [ then the let is treated as the start of a
let [ then the let is treated as the start of a
in
var declaration for the same
eval whose eval code includes a var or FunctionDeclaration declaration that binds the same
prototype own property. In the previous edition, they were constructors and had a prototype property.
Object.freeze is not an object it is treated as if it was a non-extensible ordinary object with no own properties. In the previous edition, a non-object argument always causes a
Object.getOwnPropertyDescriptor is not an object an attempt is made to coerce the argument using
Object.getOwnPropertyNames is not an object an attempt is made to coerce the argument using
Object.getPrototypeOf is not an object an attempt is made to coerce the argument using
Object.isExtensible is not an object it is treated as if it was a non-extensible ordinary object with no own properties. In the previous edition, a non-object argument always causes a
Object.isFrozen is not an object it is treated as if it was a non-extensible ordinary object with no own properties. In the previous edition, a non-object argument always causes a
Object.isSealed is not an object it is treated as if it was a non-extensible ordinary object with no own properties. In the previous edition, a non-object argument always causes a
Object.keys is not an object an attempt is made to coerce the argument using
Object.preventExtensions is not an object it is treated as if it was a non-extensible ordinary object with no own properties. In the previous edition, a non-object argument always causes a
Object.seal is not an object it is treated as if it was a non-extensible ordinary object with no own properties. In the previous edition, a non-object argument always causes a
length property of function instances is configurable. In previous editions it was non-configurable.
String.prototype.localeCompare function must treat Strings that are canonically equivalent according to the Unicode standard as being identical. In previous editions implementations were permitted to ignore canonical equivalence and could instead use a bit-wise comparison.
String.prototype.trim method is defined to recognize white space code points that may exists outside of the Unicode BMP. However, as of Unicode 7 no such code points are defined. In previous editions such code points would not have been recognized as white space.
source, global, ignoreCase, and multiline are accessor properties defined on the RegExp prototype object. In previous editions they were data properties defined on RegExp instances.
F Colophon
This specification is authored on GitHub in a plaintext source format called Ecmarkup. Ecmarkup is an HTML and Markdown dialect that provides a framework and toolset for authoring ECMAScript specifications in plaintext and processing the specification into a full-featured HTML rendering that follows the editorial conventions for this document. Ecmarkup builds on and integrates a number of other formats and technologies including Grammarkdown for defining syntax and Ecmarkdown for authoring algorithm steps. PDF renderings of this specification are produced by printing the HTML rendering to a PDF.
Prior editions of this specification were authored using Word—the Ecmarkup source text that formed the basis of this edition was produced by converting the ECMAScript 2015 Word document to Ecmarkup using an automated conversion tool.
G Bibliography
- IEEE Std 754-2008: IEEE Standard for Floating-Point Arithmetic. Institute of Electrical and Electronic Engineers, New York (2008)
- The Unicode Standard, available at <https://unicode.org/versions/latest>
- Unicode Technical Note #5: Canonical Equivalence in Applications, available at <https://unicode.org/notes/tn5/>
- Unicode Technical Standard #10: Unicode Collation Algorithm, available at <https://unicode.org/reports/tr10/>
- Unicode Standard Annex #15, Unicode Normalization Forms, available at <https://unicode.org/reports/tr15/>
- Unicode Standard Annex #18: Unicode Regular Expressions, available at <https://unicode.org/reports/tr18/>
-
Unicode Standard Annex #24: Unicode
ScriptProperty, available at <https://unicode.org/reports/tr24/> - Unicode Standard Annex #31, Unicode Identifiers and Pattern Syntax, available at <https://unicode.org/reports/tr31/>
- Unicode Standard Annex #44: Unicode Character Database, available at <https://unicode.org/reports/tr44/>
- Unicode Technical Standard #51: Unicode Emoji, available at <https://unicode.org/reports/tr51/>
- IANA Time Zone Database, available at <https://www.iana.org/time-zones>
- ISO 8601:2004(E) Data elements and interchange formats – Information interchange — Representation of dates and times
- RFC 1738 “Uniform Resource Locators (URL)”, available at <https://tools.ietf.org/html/rfc1738>
- RFC 2396 “Uniform Resource Identifiers (URI): Generic Syntax”, available at <https://tools.ietf.org/html/rfc2396>
- RFC 3629 “UTF-8, a transformation format of ISO 10646”, available at <https://tools.ietf.org/html/rfc3629>
H Copyright & Software License
Ecma International
Rue du Rhone 114
CH-1204 Geneva
Tel: +41 22 849 6000
Fax: +41 22 849 6001
Web: https://ecma-international.org/
Copyright Notice
© 2023 Ecma International
This document may be copied, published and distributed to others, and certain derivative works of it may be prepared, copied, published, and distributed, in whole or in part, provided that the above copyright notice and this Copyright License and Disclaimer are included on all such copies and derivative works. The only derivative works that are permissible under this Copyright License and Disclaimer are:
(i) works which incorporate all or portion of this document for the purpose of providing commentary or explanation (such as an annotated version of the document),
(ii) works which incorporate all or portion of this document for the purpose of incorporating features that provide accessibility,
(iii) translations of this document into languages other than English and into different formats and
(iv) works by making use of this specification in standard conformant products by implementing (e.g. by copy and paste wholly or partly) the functionality therein.
However, the content of this document itself may not be modified in any way, including by removing the copyright notice or references to Ecma International, except as required to translate it into languages other than English or into a different format.
The official version of an Ecma International document is the English language version on the Ecma International website. In the event of discrepancies between a translated version and the official version, the official version shall govern.
The limited permissions granted above are perpetual and will not be revoked by Ecma International or its successors or assigns.
This document and the information contained herein is provided on an "AS IS" basis and ECMA INTERNATIONAL DISCLAIMS ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTY THAT THE USE OF THE INFORMATION HEREIN WILL NOT INFRINGE ANY OWNERSHIP RIGHTS OR ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE.
Software License
All Software contained in this document ("Software") is protected by copyright and is being made available under the "BSD License", included below. This Software may be subject to third party rights (rights from parties other than Ecma International), including patent rights, and no licenses under such third party rights are granted under this license even if the third party concerned is a member of Ecma International. SEE THE ECMA CODE OF CONDUCT IN PATENT MATTERS AVAILABLE AT https://ecma-international.org/memento/codeofconduct.htm FOR INFORMATION REGARDING THE LICENSING OF PATENT CLAIMS THAT ARE REQUIRED TO IMPLEMENT ECMA INTERNATIONAL STANDARDS.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
- Neither the name of the authors nor Ecma International may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE ECMA INTERNATIONAL "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL ECMA INTERNATIONAL BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.